欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/146094976
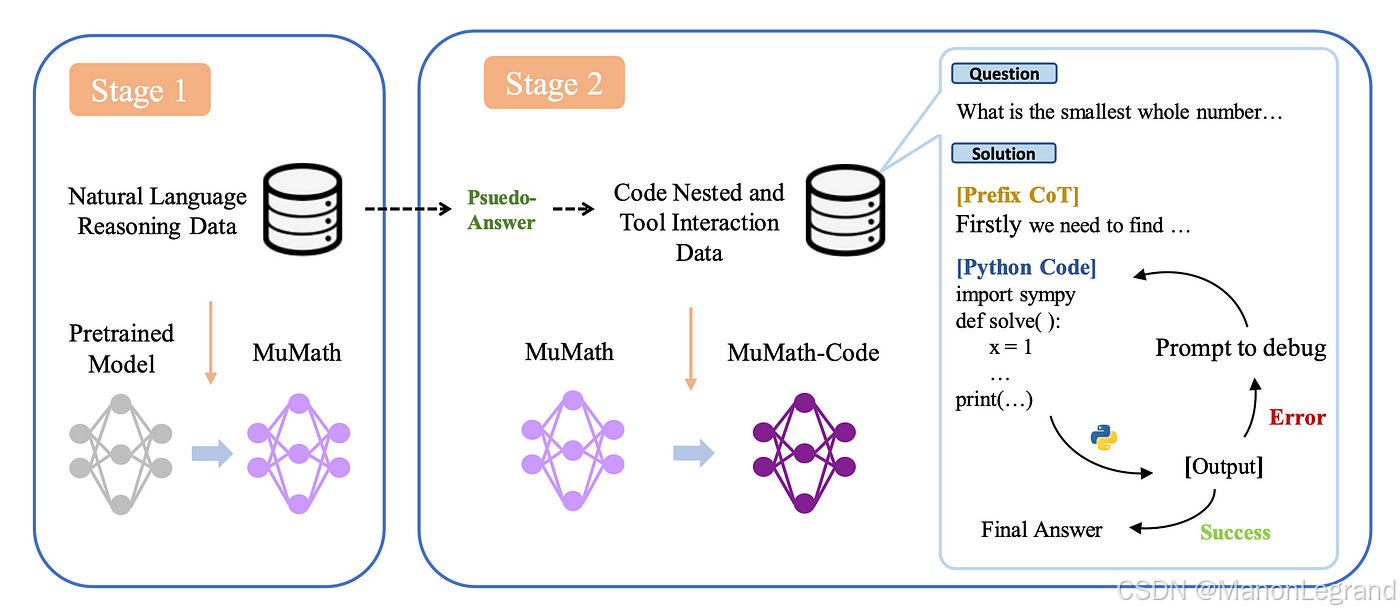
使用蒸馏的推理(Reasoning)数据集,进行模型微调(SFT),即使不使用强化学习(RL),也可以提升大模型的效果。因此,构建合适的推理数据集,就可以训练不同的高性能推理模型。
Open R1: https://github.com/huggingface/open-r1
- 参考 Open R1 开源的 OpenR1-Math-220K 数据集