LLMs之RL之TAO:《TAO: Using test-time compute to train efficient LLMs without labeled data》翻译与解读
导读:这篇Databricks博客文章介绍了TAO (Test-time Adaptive Optimization),一种无需标记数据即可提升大型语言模型 (LLM) 性能的方法。TAO 是一种突破性的 LLM 调优方法,它通过巧妙地结合测试时间计算和强化学习,解决了企业级 LLM 应用中缺乏标记数据的难题。TAO 仅需利用现有未标记的 LLM 使用数据,即可显著提升模型性能,并降低成本,其性能甚至超越了传统的微调方法。 TAO 的可扩展性和多任务学习能力使其成为一种极具潜力的技术,有望在未来的 AI 应用中发挥重要作用。 Databricks 将 TAO 集成到其产品中,进一步推动了其在企业领域的应用。
>> 背景痛点:
● 数据标注成本高昂:传统的 LLM 微调方法需要大量高质量的人工标注数据,这对于大多数企业任务来说成本高昂且难以获取。
● 提示工程效果有限:仅依靠提示工程来调整 LLM 的性能,效果有限且容易出错。
● 难以适应企业级任务:现有的方法难以有效地将大型语言模型适配到具体的企业级任务中。
>> 具体的解决方案:TAO 是一种新的模型调优方法,它利用测试时间计算和强化学习来改进 LLM,无需任何人工标注的输出数据。
>> 核心思路步骤:TAO 的工作流程包含四个主要阶段:
● 响应生成 (Response Generation):收集任务的示例输入(提示或查询),并使用多种策略生成多个候选响应。
● 响应评分 (Response Scoring):使用各种方法(例如奖励建模、基于偏好的评分或自定义规则)对生成的响应进行评估,量化其质量和与标准的一致性。
● 强化学习 (RL) 训练 (Reinforcement Learning (RL) Training):使用强化学习算法更新 LLM,使其生成更接近高分响应的输出。
● 持续改进 (Continuous Improvement):TAO 只需要 LLM 的输入数据,这些数据会随着 LLM 的使用而自然产生,从而实现持续的模型改进。
>> 优势:
● 无需标记数据:TAO 只需要未标记的 LLM 使用数据,大大降低了数据获取成本。
● 成本效益高:TAO 将测试时间计算用于模型训练,而不是推理,因此最终模型的推理成本与原始模型相同,显著低于其他测试时间计算模型。
● 性能优越:TAO 的性能在多个基准测试中都超过了传统的微调方法,甚至使廉价的开源模型达到了与昂贵专有模型相媲美的水平。
● 可扩展性:通过增加调优过程中的计算预算,可以进一步提高模型质量,而推理成本保持不变。
● 易于定制:TAO 可以根据特定任务进行定制,以获得最佳性能。
>> 结论和观点:
● TAO 是一种高效且灵活的 LLM 调优方法,它解决了企业级 LLM 应用中数据标注成本高昂的问题。
● TAO 证明了测试时间计算在专门的 AI 开发中的强大能力。
● TAO 为开发者提供了一种强大且简单的工具,可以与提示工程和微调结合使用,以实现更好的 LLM 性能。
● TAO 在特定企业任务和多任务场景下都取得了显著的性能提升。
● Databricks 正在将其生产环境中的 TAO 集成到其即将推出的 AI 产品中。
目录
《TAO: Using test-time compute to train efficient LLMs without labeled data》翻译与解读
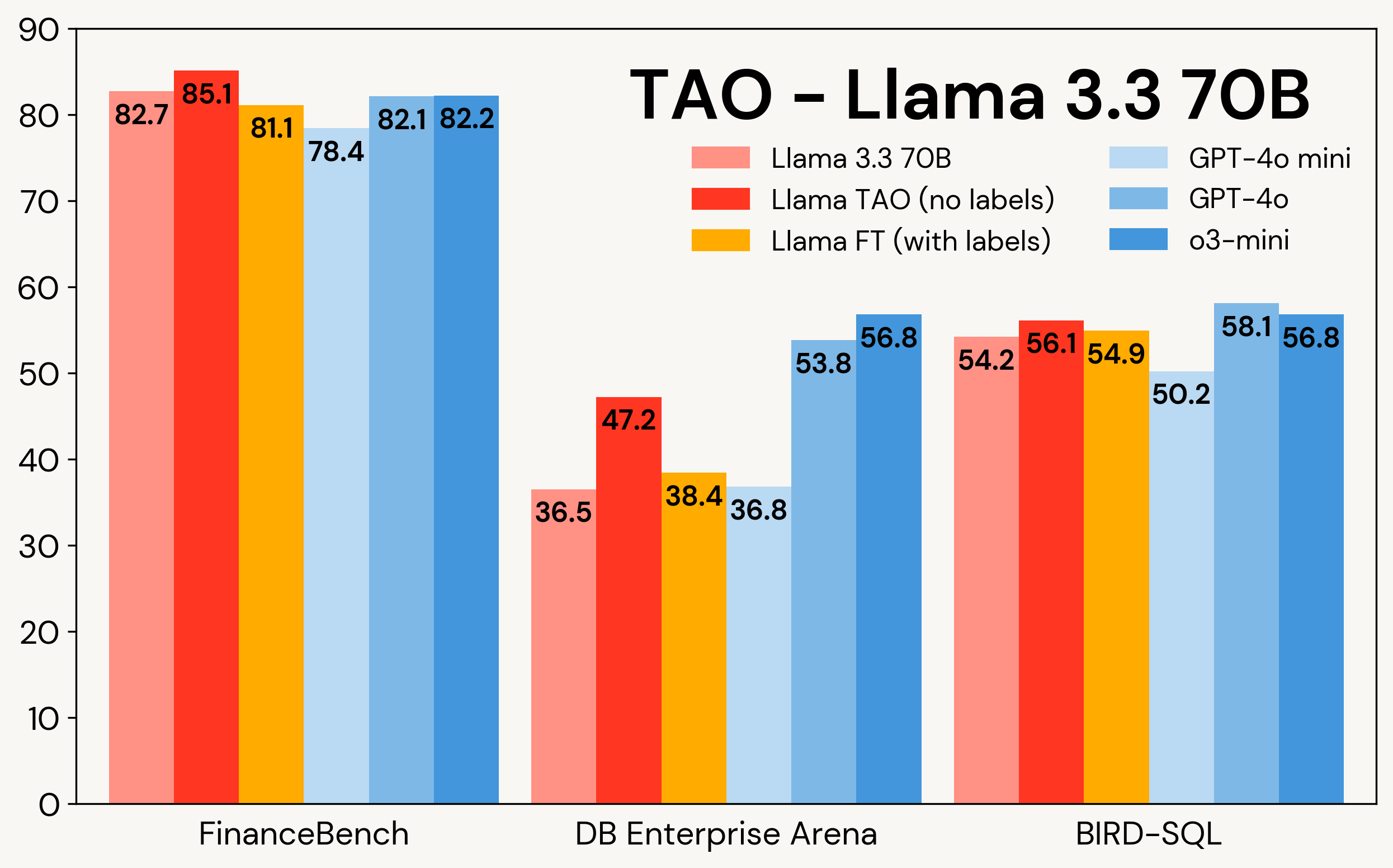
图 1:TAO 在 Llama 3.1 8B 和 Llama 3.3 70B 上针对三个企业基准测试的结果。TAO 在质量方面带来了显著提升,优于微调方法,并且能够挑战昂贵的专有大型语言模型。
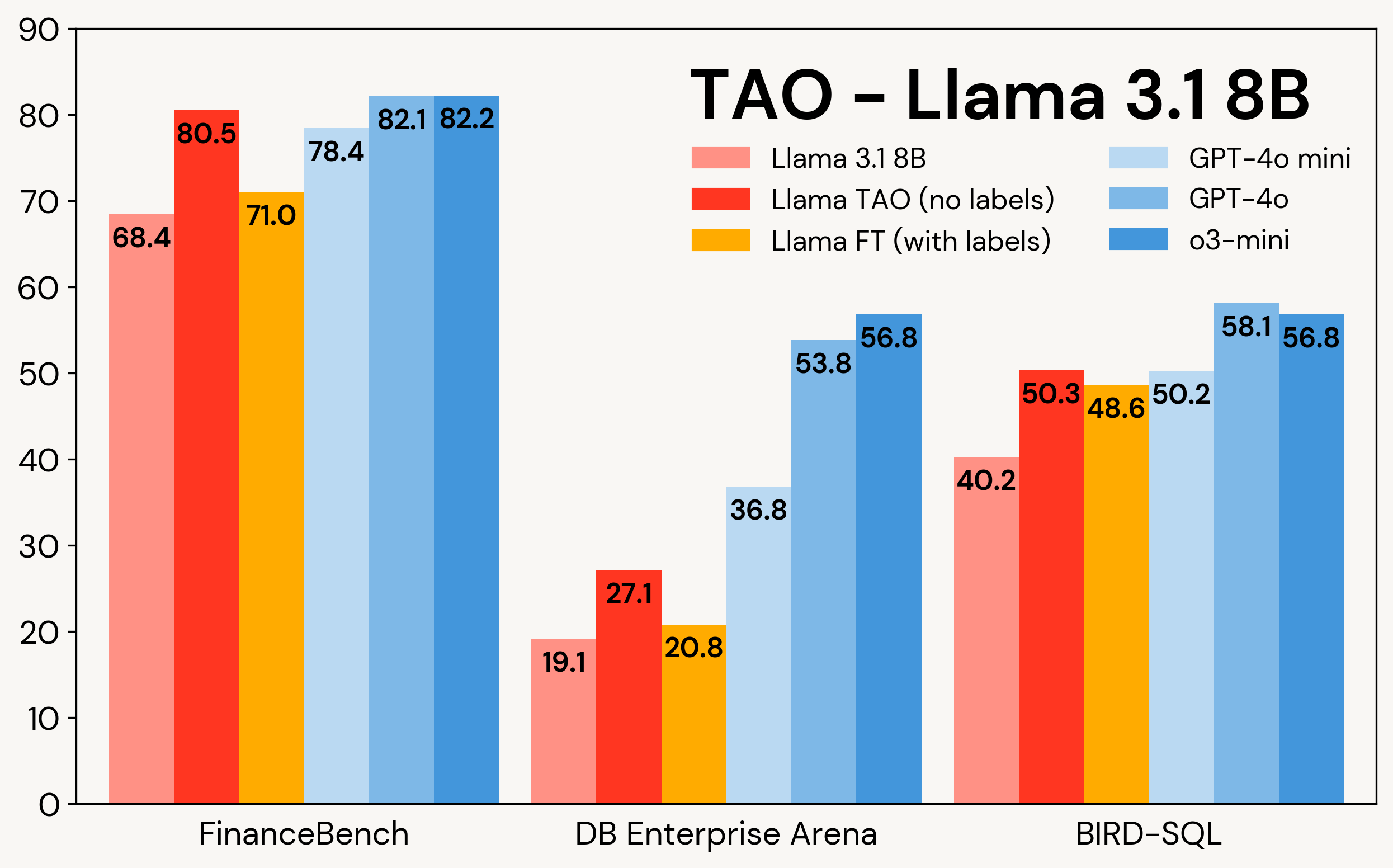
表3:在三个企业基准测试中,Llama 3.1 8B和Llama 3.3 70B上的TAO。
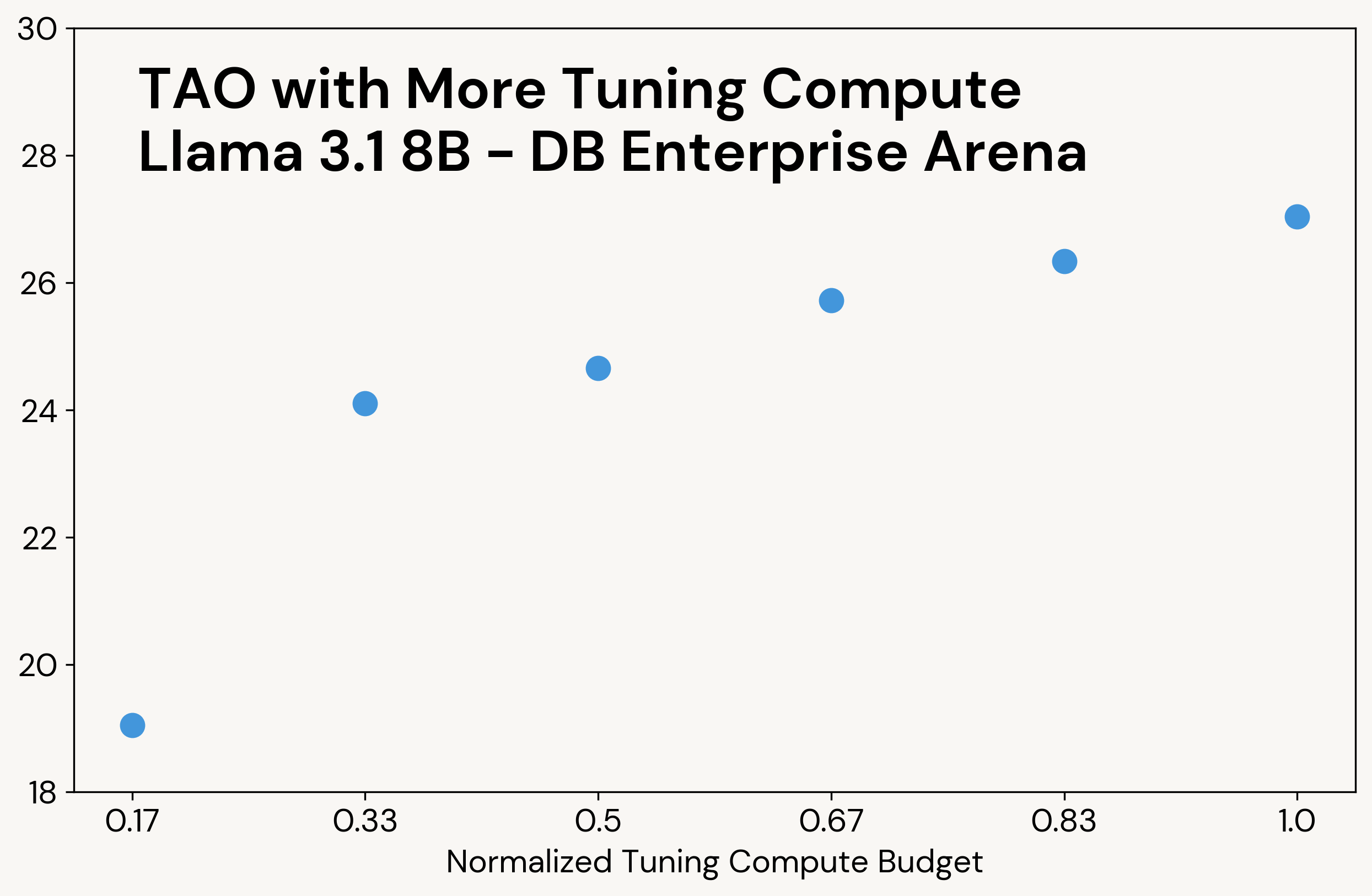
图3:TAO随调优过程中使用的测试时间计算量而变化。使用所得LLM的推理成本与原始LLM相同。
《TAO: Using test-time compute to train efficient LLMs without labeled data》翻译与解读
| 地址 |
论文地址:TAO: Using test-time compute to train efficient LLMs without labeled data | Databricks Blog |
| 时间 |
2025年3月25日 |
| 作者 |
Mosaic Research Team |
一、引言:TAO 的核心目标和优势
TAO 提出了一种创新的模型调优方法,它解决了企业级 LLM 应用中缺乏标记数据的难题,并通过高效利用计算资源来提升模型性能,降低成本。
-
核心目标: 解决大型语言模型难以适应新的企业任务的问题。传统的微调方法需要大量人工标注数据,而大多数企业任务都缺乏此类数据。TAO旨在利用现有未标记的使用数据来提高模型质量和降低成本。
-
核心优势: TAO 使用测试时间计算和强化学习,仅需LLM使用数据(未标记数据),即可超越在数千个标记示例上进行的传统微调,并使廉价的开源模型性能逼近昂贵的专有模型。模型质量可以通过增加调优计算预算来提高,而最终模型的推理成本不变。
图 1:TAO 在 Llama 3.1 8B 和 Llama 3.3 70B 上针对三个企业基准测试的结果。TAO 在质量方面带来了显著提升,优于微调方法,并且能够挑战昂贵的专有大型语言模型。
二、TAO 的工作机制:测试时间计算和强化学习
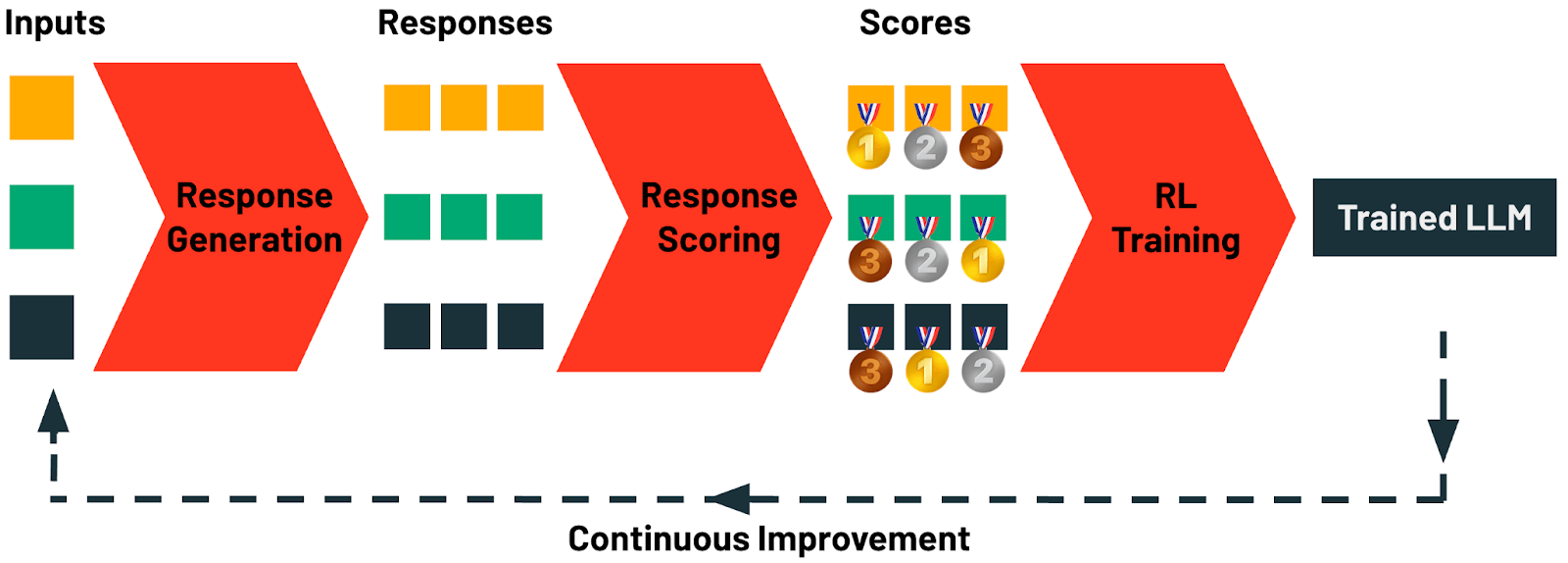
TAO 通过四个阶段的流程,巧妙地结合测试时间计算和强化学习,实现了在无需标记数据的情况下有效地调优 LLM 模型,并保持较低的推理成本。
-
核心思想: 利用测试时间计算让模型探索任务的各种可能响应,然后使用强化学习根据对这些响应的评估来更新LLM。这种流程可以通过测试时间计算来扩展,而不是依赖昂贵的人工努力。
-
四个阶段:
- 响应生成 (Response Generation): 收集任务的示例输入提示或查询,并生成多个候选响应。
- 响应评分 (Response Scoring): 系统地评估生成的响应,使用奖励建模、基于偏好的评分或使用LLM评判或自定义规则进行任务特定验证。
- 强化学习 (RL) 训练 (Reinforcement Learning (RL) Training): 使用基于 RL 的方法更新 LLM,引导模型生成与高分响应紧密相关的输出。
- 持续改进 (Continuous Improvement): TAO 只需要示例 LLM 输入作为数据,这些数据可以通过用户与 LLM 的交互自然产生。模型会随着使用量的增加而不断改进。
-
关键优势: TAO 在训练阶段使用测试时间计算,最终模型的推理成本与原始模型相同,远低于 o1、o3 和 R1 等测试时间计算模型。
图 2:TAO 管道。
三、TAO 的性能评估:在特定企业任务上的表现
实验结果充分证明了 TAO 在特定企业任务上的有效性,它在无需标记数据的情况下,显著提升了开源模型的性能,并达到了与昂贵专有模型相媲美的效果。
-
实验设置: 在三个具有代表性的基准测试(FinanceBench、DB Enterprise Arena 和 BIRD-SQL)上评估了 TAO 的性能,并与直接使用开源 Llama 模型、在 Llama 上进行微调以及使用高质量专有 LLM (GPT 4o-mini、GPT 4o 和 o3-mini) 的方法进行了比较。
-
结果: TAO 在所有三个基准测试和两个 Llama 模型上都显著提高了基线 Llama 的性能,甚至超过了微调的结果。TAO 将廉价的开源模型的质量提升到与昂贵的专有模型相当的水平。
-
可扩展性: TAO 的结果表明,增加调优过程中的计算预算可以提高模型质量,而推理成本保持不变。
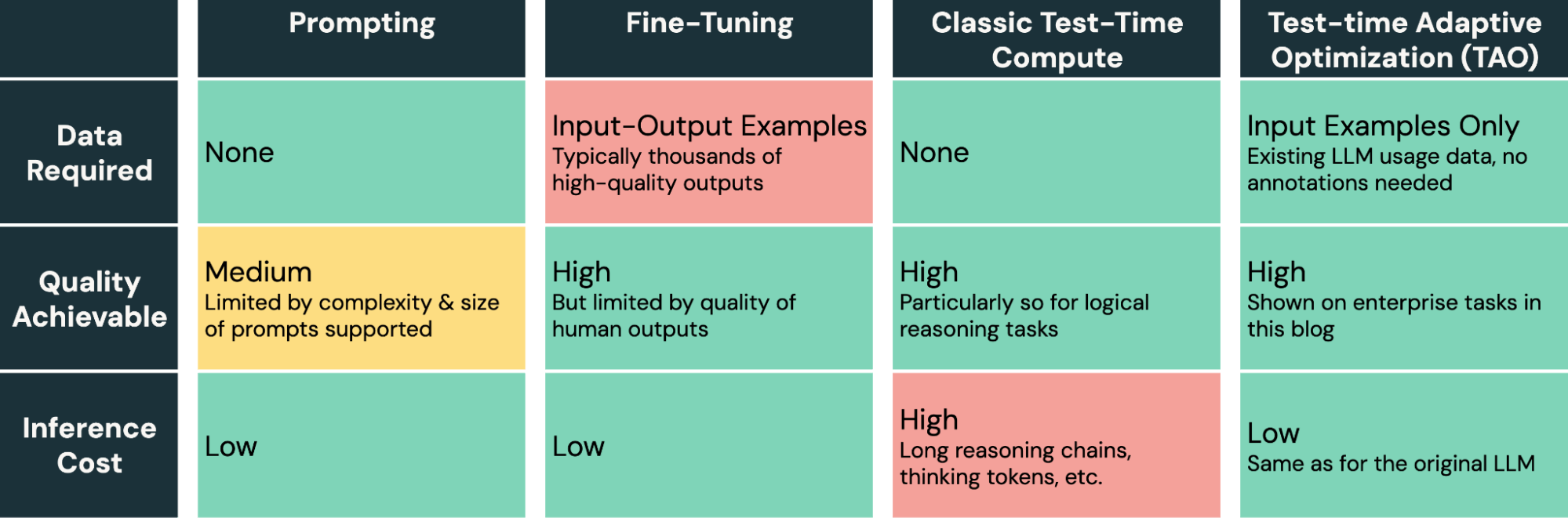
表1:LLM调优方法的比较。
四、TAO 的多任务智能提升
TAO 不仅能提升单一任务的性能,也能有效地提高 LLM 在多个企业任务上的整体性能,展现了其在多任务学习方面的潜力。
-
实验设置: 在 175,000 个涵盖多种企业任务的提示上运行 TAO,然后在一套企业相关的任务上测试性能。
-
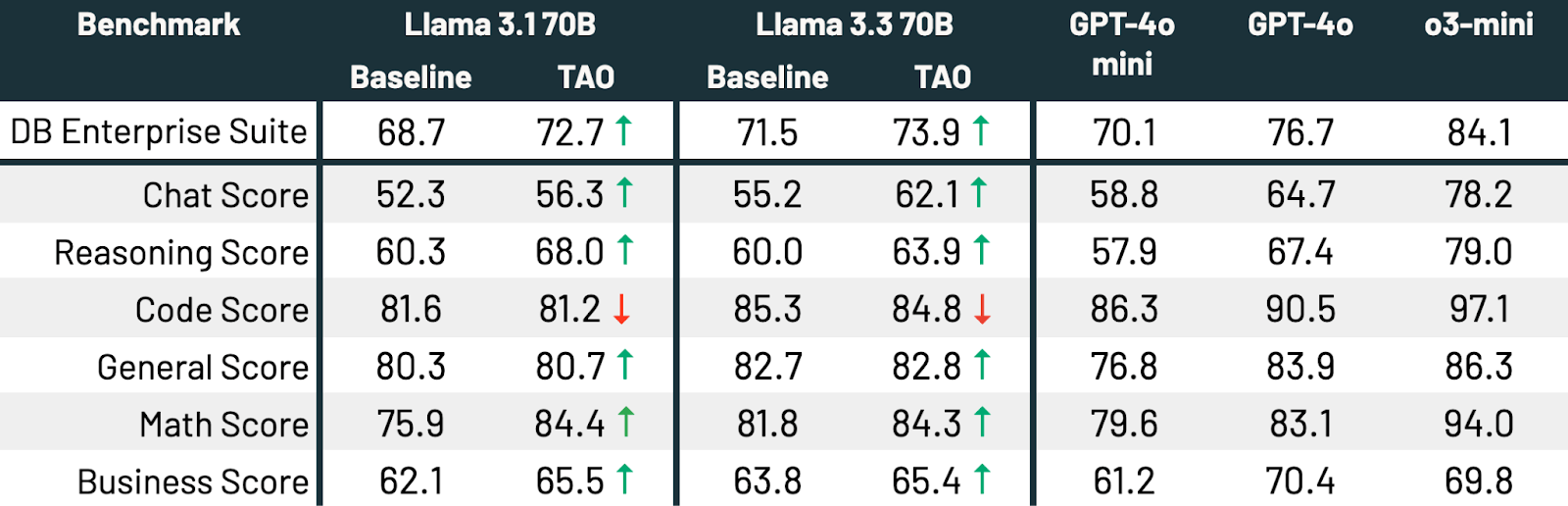
结果: TAO 有效地提高了 Llama 3.1 70B 和 Llama 3.3 70B 的性能,在多个子分数上取得了改进,将 Llama 3.3 70B 的性能显著提升,使其更接近 GPT-4o。所有这些都无需人工标注成本。
表2:本文中使用的基准测试概述。

表3:在三个企业基准测试中,Llama 3.1 8B和Llama 3.3 70B上的TAO。

图3:TAO随调优过程中使用的测试时间计算量而变化。使用所得LLM的推理成本与原始LLM相同。
五、TAO 的实际应用和最佳实践
文章提供了 TAO 的实际应用指南和最佳实践,强调了数据收集和评分方法的重要性,并建议建立数据飞轮以持续改进模型。
-
必要条件: 足够的示例输入数据(数千个)、足够准确的评分方法(例如 Databricks 的自定义奖励模型 DBRM)。
-
最佳实践: 创建 AI 应用的数据飞轮,收集输入、模型输出和其他事件,以便持续改进模型。
表4:利用TAO提高多任务企业智能
六、结论
TAO 作为一种高效、灵活的模型调优技术,为 AI 开发人员提供了一种强大的新工具,可以与提示工程和微调相结合使用。
-
核心贡献: TAO 提供了一种无需标记数据即可实现高质量模型调优的强大方法,解决了企业客户面临的缺乏标记数据的关键挑战。
-
未来展望: TAO 将被整合到 Databricks 的许多即将推出的 AI 产品更新和发布中。