文章目录
什么是计算机系统的性能指标
-
计算机系统的性能指标是用来衡量计算机系统在各种操作和任务中的工作效率、执行速度以及处理能力的标准。
-
计算机系统的性能指标可以帮助人们评估计算机系统的整体表现,从而更好地了解系统在不同方面的优势和限制。
由于计算机系统由硬件系统和软件系统共同组成,因此计算机系统的性能与软件和硬件的性能都有关系。
计算机系统的性能指标涵盖了硬件和软件两个层面,它们之间密切相关。优化硬件可以提供更强大的计算和传输能力,而优化软件可以更有效地利用这些硬件资源,从而共同实现更好的系统性能。正确的硬件选择可以为软件提供更好的执行环境,反之亦然。
硬件与计算机系统性能的关系
-
硬件是构建计算机系统的物理组件(例如CPU、内存、外部设备等)。硬件对于计算机系统的性能有着重要影响,因为它决定了系统的计算能力、数据传输速率和存储容量
-
CPU的时钟频率决定了CPU每秒钟可以执行的指令数量。
-
内存带宽会影响数据的读写速率。
软件与计算机系统性的关系
-
软件包括用于控制、管理、应用计算机系统的各类系统软件和应用软件。软件的优化可以显著影响计算机系统的性能,因为合理的算法和代码实现可以更有效地利用硬件资源。
-
操作系统的调度算法会影响多任务处理的效率,从而影响系统的响应时间。
-
在图像处理任务中,优化的软件算法可以减轻 CPU 和内存的负担,提高图形处理速度。
-
软件层面的并行计算可以更好地利用多核处理器提高吞吐量。
计算机硬件的相关性能指标
![![[计算机硬件的相关性能指标.png]]](https://i-blog.csdnimg.cn/direct/afba4a5e13bb4c54a69ea4e80650eb18.png)
衡量计算机系统性能是一项比较复杂的任务,很难仅凭借单一指标进行精确衡量。上述一些衡量计算机性能的指标之间也不是完全独立的,改变其中一项指标可能会影响到其他指标。
基本性能指标
机器字长
机器字长是指 CPU 一次能够处理的二进制数据的位数(计算机进行一次定点整数运算所能处理的二进制数据的位数),也就是构成二进制数据的比特(bit,简写为b)数量。通常所说的“某 16 位或 32 位机器”,其中的 16、32 指的是机器字长。
- 机器字长与 CPU 内部用于整数运算的ALU的位数以及通用寄存器(现代CPU会包含通用寄存器组)的宽度相等。
机器字长对计算机系统性能的主要影响如下
-
字长越长,数的表示范围就越大、精度也越高,计算精度也越高。
-
字长还会影响计算速度
计算机字长通常选定为字节(8位)的整数倍。随着硬件技术的发展,计算机的字长已经从早期的 8 位逐渐增加到 16 位、32 位、64 位甚至更高。
数据通路带宽
各个子系统通过数据总线连接形成的数据传送路径称为数据通路。
数据通路带宽是指数据总线一次所能并行传送信息的位数。这里所说的数据通路宽度是指外部数据总线的宽度,它与 CPU 内部的数据总线宽度(内部寄存器的大小)有可能不同。
主存容量
主存容量是指主存储器(内存)能够存储的最大信息量,通常以字节来衡量,也可用 字数 × 字长 字数\times字长 字数×字长(如 512 K × 16 512K\times16 512K×16 位)来表示存储容量。
假设主存包含 M 个存储单元,每个存储单元可存储 N 个二进制位,可以通过下式计算主存容量: 主存容量 = N × M ( 位或 b ) 主存容量 = N\times M(位或b) 主存容量=N×M(位或b)
![![[计算主存容量.png]]](https://i-blog.csdnimg.cn/direct/ea578bb6306349be917fd8972f32d820.png)
MAR 的位数反映了存储单元的个数,MDR 的位数反映了存储单元的字长。如果知道 MAR的位数(长度)与 MDR的位数(存储字长),也可以计算出主存容量: 主存容量 = 2 M A R 的位数(长度) × M D R 的位数(存储字长) 主存容量 = 2 ^{MAR的位数(长度)}\times MDR的位数(存储字长) 主存容量=2MAR的位数(长度)×MDR的位数(存储字长)
增加主存(内存)容量可以减少程序运行期间对辅存(外存)的访问,由于访问内存的速度远大于访问外存的速度,因此可以提高程序的执行速度,进而提高计算机系统的性能。
吞吐量
吞吐量是指计算机系统在单位时间内能够处理的信息量
影响吞吐量的主要因素如下:
-
CPU的处理能力。
-
内存(主存)的访问速度。
-
外存(辅存,例如硬盘)的访问速度。
几乎每步都关系到主存储器,因此系统吞吐量主要取决于主存储器的存取周期。
响应时间
响应时间是指从向计算机系统提交作业开始,到系统完成作业为止所需要的时间,或者说从用户向计算机发送一个请求,到系统对该请求做出响应并获得所需结果的等待时间。
通常包括 CPU 时间(运行一个程序所花费的时间)与 等待时间(用于磁盘访问、存储器访问、I/O 操作、操作系统开销等的时间)。
![![[响应时间.png]]](https://i-blog.csdnimg.cn/direct/88ed172ae47449e18a3ee11f68edb03e.png)
由于很难精确区分一个程序执行过程中的 CPU 执行时间和系统 CPU 时间,在没有特别说明的情况下,基于 CPU 执行时间进行计算机性能评价。
与运算速度相关的性能指标
CPU时钟频率和时钟周期
计算机执行一条指令的过程:取指 → 分析 → 执行
-
上述过程涉及多个步骤,每个步骤都需要特定的控制信号进行控制。
-
控制信号的发出时机、持续时间等都需要相应的定时信号来调控。
CPU 时钟信号是一个基本定时信号,它是一种固定频率的脉冲信号,用于驱动计算机内部各组件协调工作。这种脉冲信号的频率被称为 CPU时钟频率(Clock Rate,主频),基本单位为赫兹(Hz)。
CPU时钟周期(Clock Cycle 或 Clock Tick,也可简称为 clock 或 tick)是 CPU 时钟频率的倒数,基本单位为秒(s)。它是机器内部主时钟脉冲信号的宽度,是 CPU 工作的最小时间单位。
- 时钟脉冲信号由机器脉冲源发出的脉冲信号经整形和分频后形成。
- 时钟周期以相邻状态单元间组合逻辑电路的最大延迟为基准确定。
- 时钟周期也以指令流水线的每个流水段的最大延迟时间确定。
对于同类型的计算机,同一指令执行所需的CPU时钟周期的数量是一样的,因此 CPU 的时钟频率越高,该指令的执行速度就越快。主频最直观的理解就是每秒有多少个时钟周期。
![![[CPU时钟频率和时钟周期.png]]](https://i-blog.csdnimg.cn/direct/e63ec0639a604e7c9ac4145beb88b5f1.png)
在实际应用中,CPU 时钟频率远远超过本例
![![[实际应用的CPU 时钟频率.png]]](https://i-blog.csdnimg.cn/direct/82d5a595ae9b47aa9b5d4922157f2640.png)
C P U 时钟周期 = 1 主频 CPU 时钟周期 =\frac{1}{主频} CPU时钟周期=主频1,主频通常以 Hz(赫兹)为单位,10Hz表示每秒 10 次。
频率单位与周期单位的换算如下:
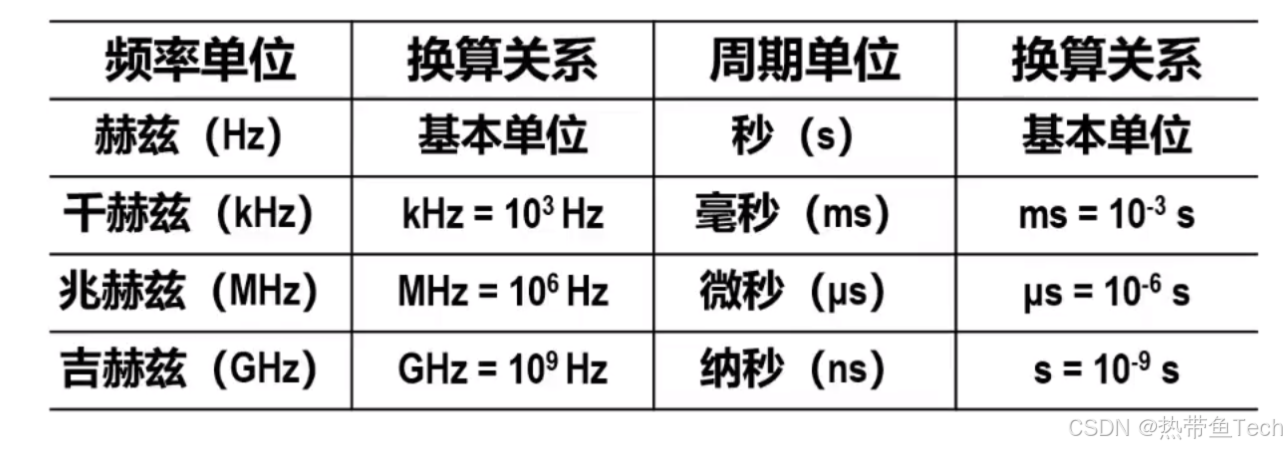
CPI
CPI(Cycles Per Instruction)的意思是执行一条指令所需要的时钟周期数量。由于不同指令的功能不同,即使功能相同的指令还可能有不同的寻址方式,因此每条指令执行所需的时钟周期数量也可能不同。
针对一条指令、一类指令、一个程序,它们各自 CPI 的含义如下:
-
一条指令的CPI:该指令执行所需要的时钟周期数量。
-
一类指令(例如算术运算类指令)CPI:构成该类指令的所有指令执行所需要时钟周期数量的平均值。
-
一个程序的CPI:构成该程序的所有指令执行所需要时钟周期数量的平均值。
CPI 的计算公式: C P I = 程序执行所需时钟周期数量 ÷ 程序所包含的指令数量 CPI = 程序执行所需时钟周期数量 \div 程序所包含的指令数量 CPI=程序执行所需时钟周期数量÷程序所包含的指令数量
-
若程序仅包含一条指令,则 CPI 就是这条指令的 CPI
-
若程序仅包含一类指令,则 CPI 就是这类指令的 CPI
如果知道某个程序中共有 n n n 类不同类型的指令、每类指令的 CPI (用 C P I i CPI_i CPIi表示)、
含的指令数量中所占的比例(用 P i P_i Pi表示),则该程序的 CPI 可用下式计算: C P I = ∑ i = 1 n ( C P I i × P i ) CPI = \sum_{i=1}^n(CPI_i \times P_i) CPI=i=1∑n(CPIi×Pi)
CPI 计算实例:
![![[CPI计算实例.png]]](https://i-blog.csdnimg.cn/direct/ac8d05dcb51540799e7093edf9875e7e.png)
IPS(Instructions Per Second):每秒执行多少条指令(指令执行速度), I P S = 主频 平均 C P I IPS= \frac{主频}{平均 CPI} IPS=平均CPI主频
CPU执行时间
CPU 执行时间是指真正用于用户程序的执行时间,而不包括为执行用户程序而花费在操作系统、访问主存(内存)、访问辅存(外存)、访问外部设备上的时间。
CPU 执行时间的计算公式为: C P U 执行时间 = 程序执行所需时钟周期数量 × 时钟周期 = 程序执行所需时钟周期数量 ÷ 时钟频率 \begin{equation*} \begin{split} CPU 执行时间 = 程序执行所需时钟周期数量 \times 时钟周期 \\ = 程序执行所需时钟周期数量 \div 时钟频率 \end{split} \end{equation*} CPU执行时间=程序执行所需时钟周期数量×时钟周期=程序执行所需时钟周期数量÷时钟频率
通过 CPI 来计算 CPU 执行时间的计算公式: C P U 执行时间 = ( C P I × 程序所包含的指令数量 ) × 时钟周期 = ( C P I × 程序所包含的指令数量 ) ÷ 时钟频率 \begin{equation*} \begin{split} CPU 执行时间 = (CPI \times 程序所包含的指令数量) \times 时钟周期 \\ = (CPI \times 程序所包含的指令数量) \div 时钟频率 \end{split} \end{equation*} CPU执行时间=(CPI×程序所包含的指令数量)×时钟周期=(CPI×程序所包含的指令数量)÷时钟频率
计算 CPU 执行时间的示例:
![![[CPU 执行时间示例1.png]]](https://i-blog.csdnimg.cn/direct/1298b2c754d24f748381d217684ed334.png)
![![[CPI计算实例2.png]]](https://i-blog.csdnimg.cn/direct/ecdfca943ced4fce95e8fee4444936e6.png)
根据本例可以看出:仅仅通过计算机编译后目标代码中包含的指令数量来评估计算机性能是不准确的。
在本例中,尽管 S2 包含的指令数量(4+1+1=6)比 S1 的(2+1+2=5)多,但是由于 S2 中 CPI 小的指令(即 CPI 为 1 的 A 类指令)所占比例( 4 6 \frac{4}{6} 64),比 S1 中 CPI 小的指令(即 CPI 为 1 的 A 类指令)所占比例( 2 5 \frac{2}{5} 52)高,因此指令数量更多的 S2 实际上比指令数量较少的 S1 执行速度更快。
CPU 的性能(CPU执行时间)取决于三个要素:主频、CPI 和指令条数。主频、CPI 和指令条数是相互制约的。例如,更改指令集可以减少程序所含的指令条数,但同时可能引起 CPU 结构的调整,从而可能会增加时钟周期的宽度(降低主频)。
IPC
IPC(Instructions Per cycle)的意思是每个时钟周期能够执行的指令数量
-
IPC 是 CPI 的倒数,它与CPU架构、指令集、指令流水线技术等密切相关,
-
由于指令流水线技术以及多核技术的发展,目前
IPC的值已经可以大于 1
MIPS
MIPS(Milion Instructions Per Second)的意思是每秒执行多少百万条指令
MIPS 的计算公式为: M I P S = ( 程序所包含的指令数量 ÷ C P U 执行时间 ) ÷ 1 0 6 MIPS=(程序所包含的指令数量\div CPU执行时间)\div 10^6 MIPS=(程序所包含的指令数量÷CPU执行时间)÷106
通过 CPI 计算 MIPS 的公式: M I P S = ( 时钟频率 ÷ C P I ) ÷ 1 0 6 = ( 1 时钟周期 ÷ C P I ) ÷ 1 0 6 \begin{equation*} \begin{split} MIPS = (时钟频率 \div CPI) \div 10^6 \\ = (\frac{1}{时钟周期} \div CPI) \div 10^6 \end{split} \end{equation*} MIPS=(时钟频率÷CPI)÷106=(时钟周期1÷CPI)÷106
用 MIPS 对不同的机器进行性能比较有时是不准确的:
-
在某种机器上的某一条指令的功能,不同机器的指令集不同,并且指令的功能也不同,可能在另一种机器上需要用多条指令来实现。
-
不同机器的
CPI和时钟周期也不同,因而同一条指令在不同机器上所用的时间也不同
计算 MIPS 的示例
![![[计算 MIPS 的示例.png]]](https://i-blog.csdnimg.cn/direct/53012a25b40f4f1d8cc4288b98944a14.png)
MFLOPS
MFLOPS(Milion Floating-Point Operations Per Second)的意思是每秒执行多少百万次浮点运算
FLOPS(Floating-Point Operations Per Second):每秒执行多少次浮点运算。
MFLOPS 计算公式: M F L O P S = ( 浮点运算次数 ÷ 测试程序的执行时间 ) ÷ 1 0 6 MFLOPS = (浮点运算次数 \div 测试程序的执行时间) \div 10^6 MFLOPS=(浮点运算次数÷测试程序的执行时间)÷106
相较于 MFLOPS,衡量每秒执行浮点运算的次数还有以下单位,以此递增 1 0 3 10^3 103:
-
GFLOPS(GigaFLOPS):每秒执行多少十亿( 1 0 9 10^9 109)次浮点运算。 -
TFLOPS(TeraFLOPS):每秒执行多少万亿( 1 0 12 10^{12} 1012)次浮点运算。 -
PFLOPS(PetaFLOPS):每秒执行多少千万亿( 1 0 15 10^{15} 1015)次浮点运算。 -
EFLOPS(ExaFLOPS):每秒执行多少百亿亿( 1 0 18 10^{18} 1018)(百京,1京=1亿亿= 1 0 16 10^{16} 1016)次浮点运算。 -
ZFLOPS(ZettaFLOPS):每秒执行多少十万亿亿( 1 0 21 10^{21} 1021,十万京)次浮点运算。
MFLOPS 不能全面反映计算机系统的性能。MFLOPS 仅反映浮点运算速度,其值与所使用的测试程序相关。不同测试程序中包含的浮点运算量不同,测试得到的结果也不相同。
在描述存储容量、文件大小等时,
K、M、G、T通常用 2 的幂次表示,如 1 K b = 2 10 1Kb=2^{10} 1Kb=210b在描述速率、频率等时,
k、M、G、T通常用 10 的幂次表示,如 1 k b / s = 1 0 3 1kb/s=10^3 1kb/s=103b/s。通常前者用大写的 K,后者用小写的 k,但其他前缀均为大写,表示的含义取决于所用的场景。
使用基准程序进行性能评估
基准程序(Benchmark)是一组特定的程序,专门用于评测计算机的性能。这些程序能够有效地模拟计算机在处理实际任务时的表现。
-
通过比较各计算机运行基准程序的时间,从而在不同计算机上运行同样的基准程序,评测它们各自的性能。
-
不同基准程序的评测重点不同,例如
CPU性能、图形性能、存储性能、浮点数计算性能、并行计算性能等。 -
目前国际上流行的基准程序主要有
SPE、Linpack、Dhrystone、Whetstone、NPB等