

- 作者:Akhil Perincherry, Jacob Krantz, Stefan Lee
- 单位:俄亥俄州立大学
- 论文标题:Do Visual Imaginations Improve Vision-and-Language Navigation Agents?
- 论文链接:https://arxiv.org/abs/2503.16394
- 项目主页:https://www.akhilperincherry.com/VLN-Imagine-website/
主要贡献
- 论文使用文本到图像的扩散模型从导航指令中生成视觉想象,以增强导航智能体的性能。
- 提出了模型无关的方法,将视觉想象集成到现有的视觉语言导航智能体中,展示了在多个模型和数据集上的性能提升。
- 引入辅助损失函数,用于对齐视觉想象与指令中的名词短语,以提高视觉理解的准确性。
- 通过实验验证,证明了视觉想象在导航任务中的有效性,显示出在成功率和路径长度加权成功率上的显著提升。
研究背景
研究问题
- 论文研究了视觉想象模块是否能提高视觉语言导航智能体的性能。
- 具体来说,研究了在自然语言导航指令中,通过文本到图像的扩散模型生成的视觉表示(即视觉想象模块)是否可以作为导航线索,从而提高导航的成功率和路径长度加权成功率(SPL)。
研究难点
该问题的研究难点包括:
- 如何有效地从导航指令中生成与视觉地标相关的视觉图像,
- 如何在现有视觉语言导航模型中集成这些想象模块,
- 以及如何在训练过程中保持模型的泛化能力。
相关工作
-
视觉语言导航(VLN):
- VLN智能体能够在未知环境中使用自然语言指令进行导航。该领域的发展得益于逼真的模拟器和大规模的语言-动作数据集,如Room-2-Room(R2R)和REVERIE。
- 该问题的研究进展包括架构改进和数据扩展技术,例如从循环网络到Transformer架构的演变,以及通过环境扩展和增加场景来提高数据规模。
-
图像生成在VLN中的应用:
- 研究了使用生成模型预测未来视觉观察或整个环境的多种技术。例如,Pathdreamer使用GAN预测导航后的全景观察,而PanoGen使用扩散模型生成具有匹配语义的全景观察。
- 论文提出的方法与这些技术不同,因为它利用文本到图像模型生成指令中提到的视觉地标,并将其作为导航智能体的输入。
-
机器人控制中的图像生成:
- 讨论了在机器人控制中使用文本条件生成技术提供目标规格的方法,特别是在桌面物体重新排列任务中。
- 这些技术通常在受限空间内操作,与论文的方法不同,后者关注在更广泛的环境中进行导航。
- 论文还提到了ADAPT和LAD,这些工作通过不同的方式增强VLN智能体,但论文的方法在方法的一般性、序列想象和早期融合方面有所不同。
方法
视觉想象生成

问题定义
- 在标准的VLN任务中,智能体根据视觉观察和自然语言指令执行一系列动作来导航。
- 指令被表示为一个L词的序列 W = ( w 1 , w 2 , ⋯ , w L ) W = (w_1, w_2, \cdots, w_L) W=(w1,w2,⋯,wL),而时间步t的视觉观察是一个由K个单视图图像组成的全景观察 O t = ( I 1 t , ⋯ , I K t ) O_t = (I_1^t, \cdots, I_K^t) Ot=(I1t,⋯,IKt)。
视觉想象生成流程
- 指令分段:使用FG-R2R工具对指令进行分段,得到中间导航步骤的子指令。每个指令平均分为3.66个子指令。
- 子指令过滤:过滤掉不包含视觉地标参考的子指令。首先使用Spacy忽略没有名词短语的子指令,然后通过手动黑名单进一步过滤,排除非视觉术语。
- 生成视觉想象:将过滤后的子指令输入到一个文本条件扩散模型(如SDXL)中,生成与子指令相关的视觉想象。生成的图像用于强化下游任务训练中的视觉基础。
- 生成的视觉想象集合表示为 Z = { Z i ∣ S i ∈ S ′ } \mathcal{Z} = \{Z_i \mid S_i \in \mathcal{S}'\} Z={ Zi∣Si∈S′},其中 S ′ \mathcal{S}' S′ 是过滤后的子指令集合。
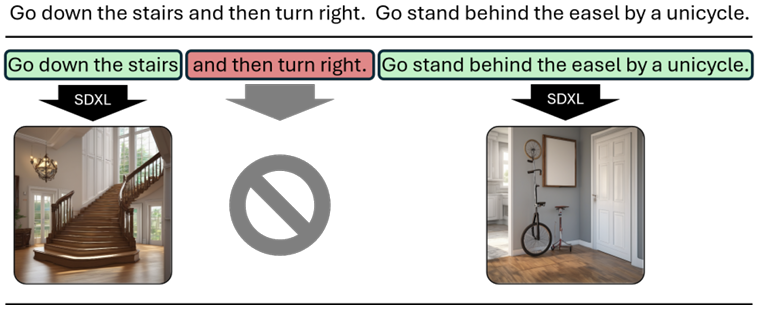
R2R-Imagine数据集
- 为整个R2R数据集生成视觉想象,形成R2R-Imagine数据集。
- 包含超过41,558个合成的视觉想象,平均每个指令2.96个想象。
集成现有模型
想象编码器
- 使用预训练的视觉变换器(ViT)对每个视觉想象进行编码,生成一个嵌入向量。
- 这些嵌入向量通过一个多层感知机(MLP)进行变换,并与文本编码连接起来。
h i = MLP ( ViT ( Z i ) + t I m ) h_i = \operatorname{MLP}(\operatorname{ViT}(Z_i) + t_{Im}) hi=MLP(ViT(Zi)+tIm)
其中, t I m t_{Im} tIm 是想象模态的类型嵌入。
辅助对齐损失
- 引入了辅助损失函数,用于对齐视觉想象与其对应子指令的名词短语。
- 通过计算想象嵌入和名词短语嵌入之间的余弦相似度损失来实现对齐。
L c o s = 1 N I m ∑ ( Z i , S i ) ∈ B ( 1 − h i ⋅ S ˉ i ∥ h i ∥ ∥ S ˉ i ∥ ) \mathcal{L}_{cos} = \frac{1}{N_{Im}} \sum_{\left(Z_i, S_i\right) \in B} \left(1 - \frac{h_i \cdot \bar{S}_i}{\left\|h_i\right\| \left\|\bar{S}_i\right\|}\right) Lcos=NIm1(Zi,Si)∈B∑(1−∥hi∥ Sˉi hi⋅Sˉi)
其中 S ˉ i \bar{S}_i Sˉi 是子指令 S i S_i Si 中名词短语的平均嵌入向量。
微调方案
- 使用三个阶段的微调方案来训练智能体。
- 首先单独训练想象编码器的MLP,
- 然后联合训练所有模块,
- 最后以共同的低学习率训练所有参数。
实验
实验设置
数据集
- R2R数据集:使用Matterport3D模拟器构建的R2R数据集,包含90个室内环境和10,567个全景图像。数据集分为训练集、val-seen、val-unseen和test集。
- R2R-Imagine数据集:为R2R数据集生成的视觉想象,用于实验中生成视觉想象的评估。
- REVERIE数据集:使用Matterport3D构建的高层次目标数据集,指令通常传达目标对象及其位置。REVERIE数据集用于评估方法在细粒度指令设置下的泛化能力。
评估指标
- 使用标准的VLN指标进行评估,包括成功率(SR)、路径长度加权成功率(SPL)、导航误差(NE)和轨迹长度(TL)。
- REVERIE数据集还使用远程定位成功率(RGS)和按路径长度惩罚RGS(RGSPL)作为评估指标。
基线模型
- 应用方法到两个基线模型:HAMT和DUET。
- HAMT是基于Transformer的层次模型,
- DUET使用拓扑地图和双尺度交叉模态注意力机制。
实现细节
- 使用预训练的ViT-B/16编码视觉想象,并在三个阶段进行微调。
- 微调过程在Tesla V100 GPU上进行,批量大小为8,每个智能体的微调大约需要1.5天。
结果
成功率提升
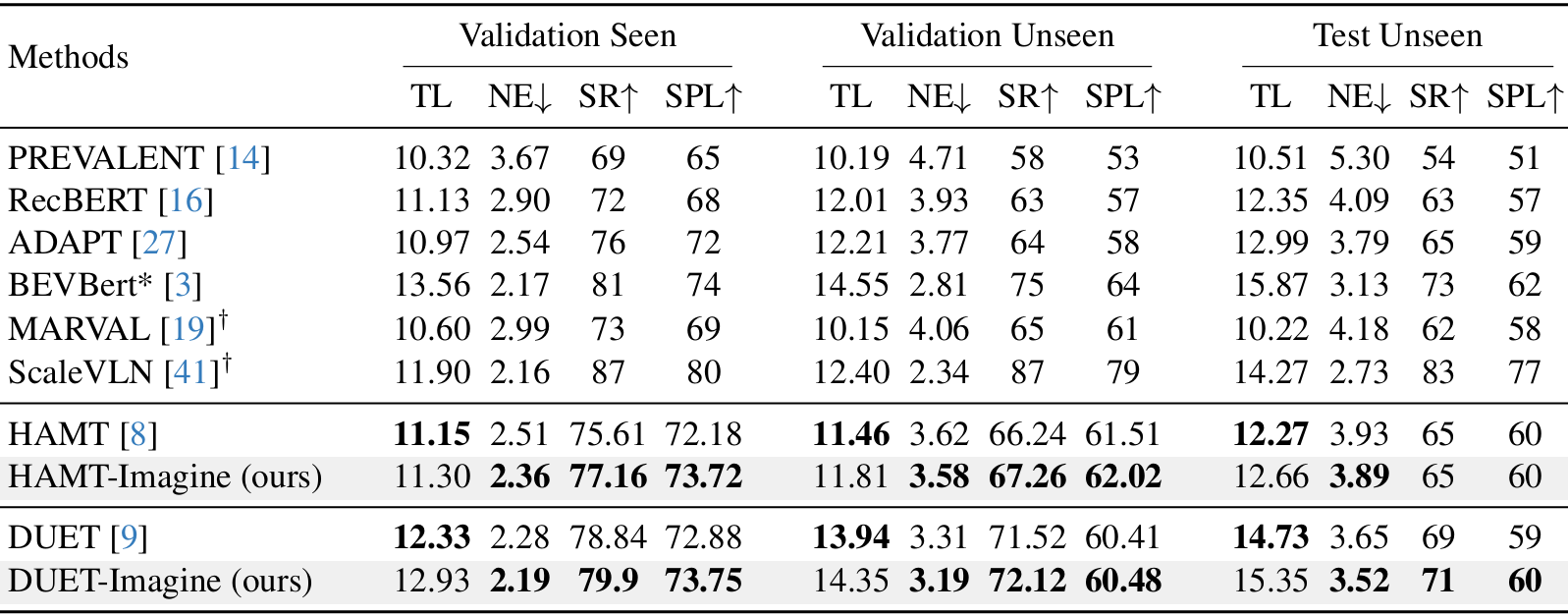
- 实验结果表明,配备视觉想象的VLN智能体在R2R val-unseen上的成功率提高了0.6-1.0,SPL提高了多达0.5。
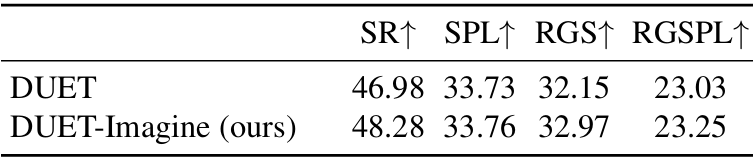
- 在REVERIE数据集上,导航性能提高了1.3,定位性能提高了0.82。
消融研究
- 想象模块训练与推理:在测试时取消想象模块,智能体仍然优于基线,但幅度较小。这表明想象模块训练对智能体有正则化效应。
- 顺序想象与目标想象:顺序想象(生成多个子指令的想象)优于仅生成最终子指令的目标想象。
- 视觉编码器比较:使用预训练的ViT和微调的ViT进行编码,发现预训练的ViT表现更好。
- 损失函数消融:使用余弦损失和InfoNCE损失进行比较,发现两者之间没有显著差异。

定性分析
- 提供了定性可视化,展示了想象模块如何在语言标记和视觉观察之间起到桥梁作用。
- 通过注意力模式分析,展示了想象模块如何帮助智能体在环境中进行更好的决策。
总结
- 论文展示了视觉想象模块在训练卓越的视觉语言导航智能体方面的附加作用。
- 通过生成描述子指令地标的视觉想象模块,并将其集成到现有的VLN智能体中,观察到性能提升了约1个成功率点和0.5个SPL点。
- 尽管生成和编码想象模块增加了运行VLN智能体的计算成本,但这种方法为未来的研究提供了新的方向,如探索想象在模拟到现实(Sim2Real)差距中的作用以及通过图像推理解锁VLN世界模型的性能。
