欢迎阅读 OSCHINA 编辑部出品的开源日报,每天更新一期。
# 2024.4.8
今日要点
通义千问开源 320 亿参数模型
此次开源的 320 亿参数模型,将在性能、效率和内存占用之间实现更理想的平衡,例如,相比 14B 模型,32B 在智能体场景下能力更强;相比 72B,32B 的推理成本更低。通义千问团队希望 32B 开源模型能为下游应用提供更好的解决方案。

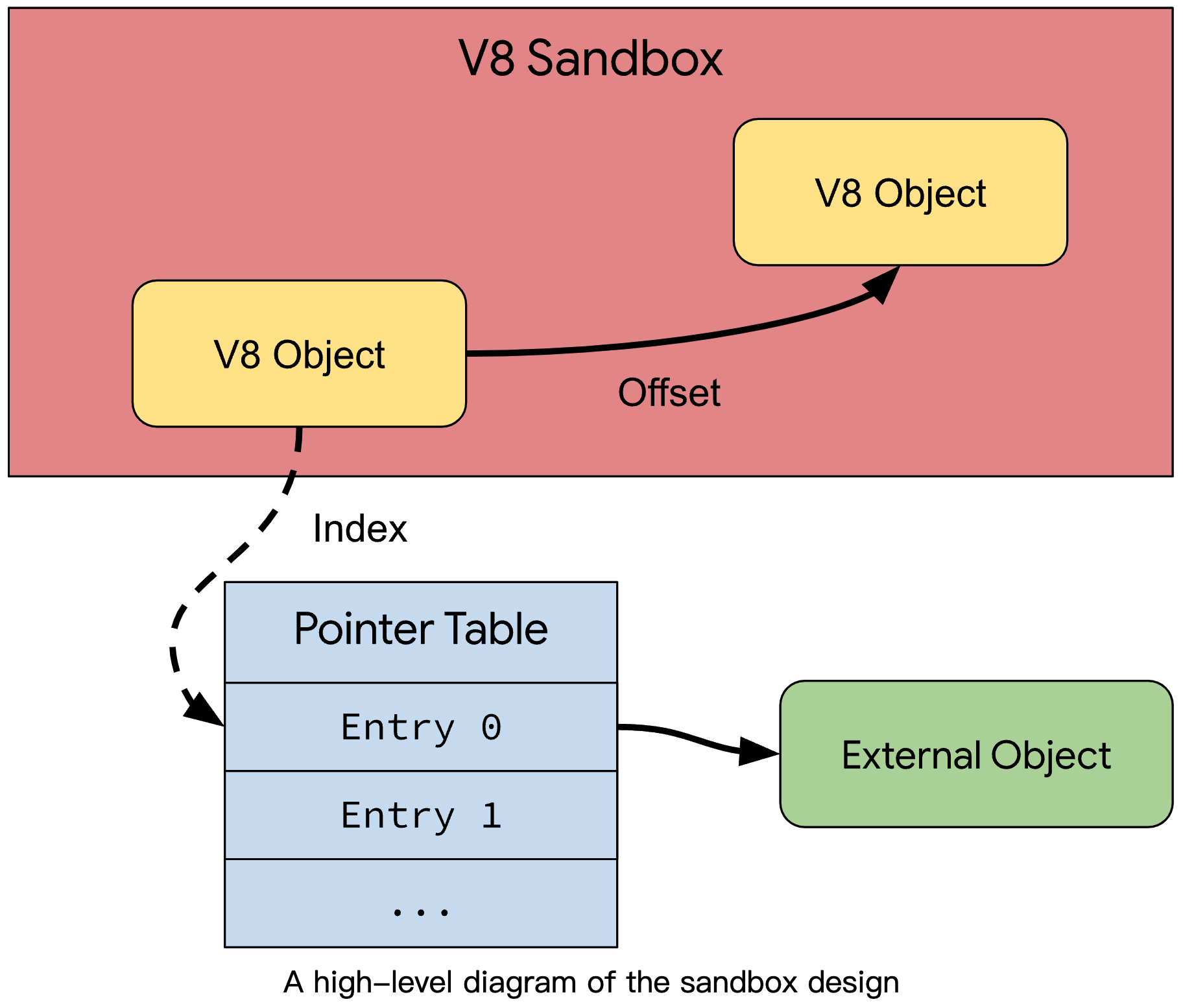
JavaScript 引擎 V8 的内存沙盒 (V8 Sandbox) 开始测试
在 V8 中发现和利用的几乎所有漏洞都有一个共同点:最终的内存损坏必然发生在 V8 堆内存,因为编译器和运行时(几乎)专门在 V8HeapObject 实例上运行。基于此,V8 团队设计了沙盒机制。V8 沙盒的设计思想是隔离 V8 堆内存,这样任何内存损坏都不能 “传播” 到进程内存的其他部分。
Zabbix 7.0 变更开源协议,从 GPLv2 转为 AGPLv3

今日观察
社交观察
「抱抱脸Open了OpenAI的秘密武器」
OpenAI的秘密武器、ChatGPT背后功臣RLHF,被开源了。
来自Hugging Face、加拿大蒙特利尔Mila研究所、网易伏羲AI Lab的研究人员从零开始复现了OpenAI的RLHF pipeline,罗列了25个关键实施细节。
- 微博 量子位
「 一个月时间面试了差不多30个iOS开发」
面试了差不多30个iOS开发,一个月时间,最后结论奉劝改行吧。


「转行夕阳产业,还是非科班 C++ 这种极难找工作的技术栈 」

- 微博 BugOS技术组
媒体观察
「AI产业的灰色暗面:OpenAI、谷歌、META如何搞训练语料」
种种迹象显示,目前站在全世界AI领域潮头浪尖的这些公司,早在几年前就已经陷入对训练语料的“绝望”追逐中——为此他们不惜修改政策条款、无视互联网信息的使用规则,只为了让自家的产品更加先进一些。
《纽约时报》在本周末刊发的调查报道中,揭露了OpenAI、谷歌、Meta等公司为了获取训练语料所采取的一些“走捷径”措施,同时也展现了整个行业迫在眉睫的困境。
- 财联社
「华盛顿邮报:证词显示特斯拉自动驾驶编程存在缺陷 」
据华盛顿邮报报道,在特斯拉的营销材料中,该公司的自动驾驶仪驾驶员辅助系统被描绘成一个技术奇迹,它使用先进的摄像头、传感器和计算能力来自动驾驶、加速和制动——甚至可以改变车道。
然而,特斯拉工程师阿克谢·法塔克(Akshay Phatak)去年作证时表示称该软件至少在一个方面相当基础:它的自行驾驶方式。
2023 年 7 月,法塔克在接受质询时表示:如果有明确标记的车道线,系统就会沿着车道线行驶。他说,特斯拉的开创性系统只是设计为沿着绘制的车道线行驶。
- 鞭牛士
「Llama提速500%!谷歌美女程序员手搓矩阵乘法内核」
近日,天才程序员Justine Tunney发推表示自己更新了Llamafile的代码,通过手搓84个新的矩阵乘法内核,将Llama的推理速度提高了500%!
项目地址:github.com/Mozilla-Ocho/llamafile/releases
其中,ARMv8.2+(如RPI 5)、Intel(如Alderlake)和AVX512(如Zen 4)计算机的改进最为显著。另外,对于适合L2缓存的矩阵,新的内核比MKL快2倍!
Justine Tunney表示:负责MKL的大家,你们有事做了!毕竟,由微软,英特尔,TI,AMD,HPE,Oracle,Huawei,Facebook,ARM和National Science Foundation资助的BLIS,作为最强大的开源BLAS,输了就太没面子了!
「阿里刚开源32B大模型,我们立马测试了“弱智吧”」
Qwen 1.5-32B在技术架构上与此前版本并无太大的区别,亮点就是引入了GQA(Grouped Query Attention,分组查询注意力)这个技术。这也正是它能够在相对较小的体量之下,能够做到性能较优且快速部署的关键。
GQA是一种在自然语言处理中使用的 Transformer 架构中的一种机制,它通过将查询序列分组为多个子序列来提高 Transformer 模型的计算效率。这种方法可以有效地减少计算复杂度,同时保留 Transformer 模型的表示能力。
「Perplexity要搞竞价排名了,大模型的尽头……就还是广告?」
对于现在的Perplexity来说,将广告纳入未来产品计划,需要有足够大的用户基数吸引营销商兴趣,同时确保客户赞助的问题与主题相关,不干扰平台的核心使用流程——显然目前的1000万月活用户还有很大提升空间,而一边做好平台体验吸引更多用户,一边招揽金主爸爸投广告,各方面来说都算是不小的挑战。
无论如何,AI公司商业化都是不可逆的大势所趋。如何找到其中的平衡,将是所有企业走得更远需要面对的共同课题。
今日推荐
开源项目
guillaumechereau/goxel
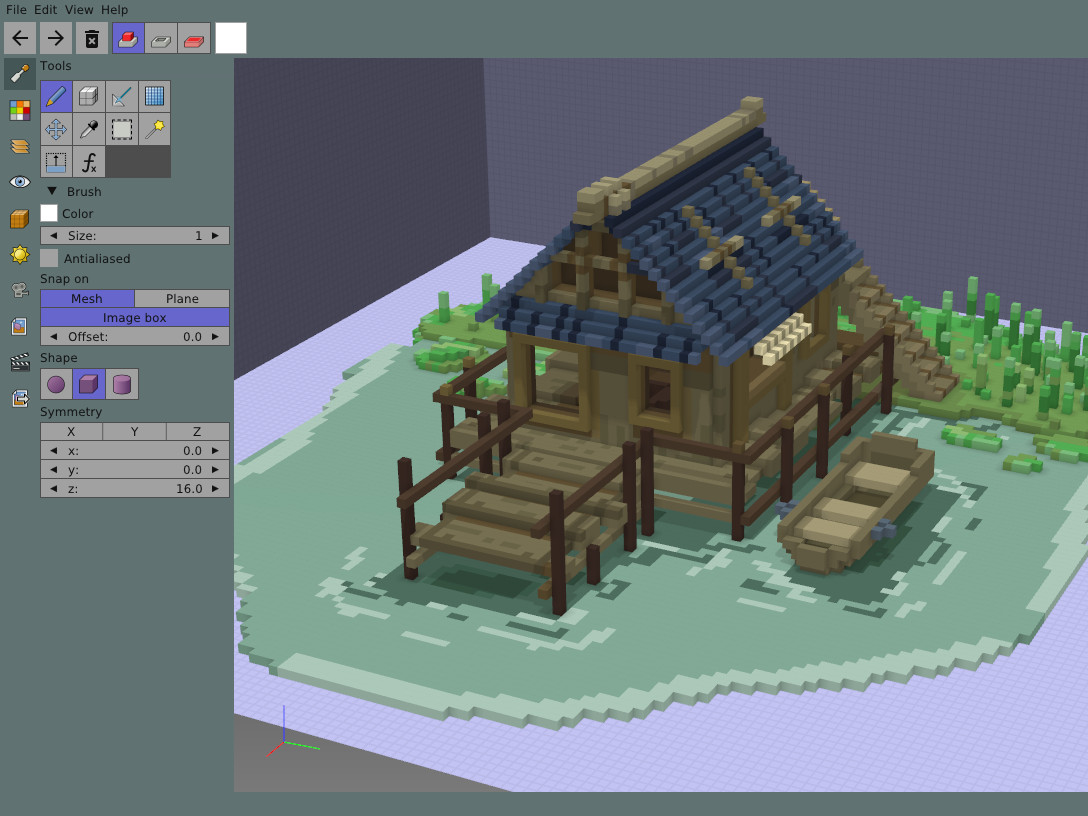
https://github.com/guillaumechereau/goxel
Goxel 是一款免费开源的 3D 体素编辑器,用于创建体素图形(由立方体形成的 3D 图像)。它适用于 Linux、BSD、Windows、macOS、iOS 和 Android。
推荐理由
Goxel 是一个功能强大、易于使用的 3D 体素编辑器。具有跨平台兼容性,允许用户创建任意大小的体素图像,并具有层支持和丰富的导出格式。此外,它提供 24 位 RGB 颜色支持和无限制的撤销缓冲区,使编辑体验更加灵活。
每日一博
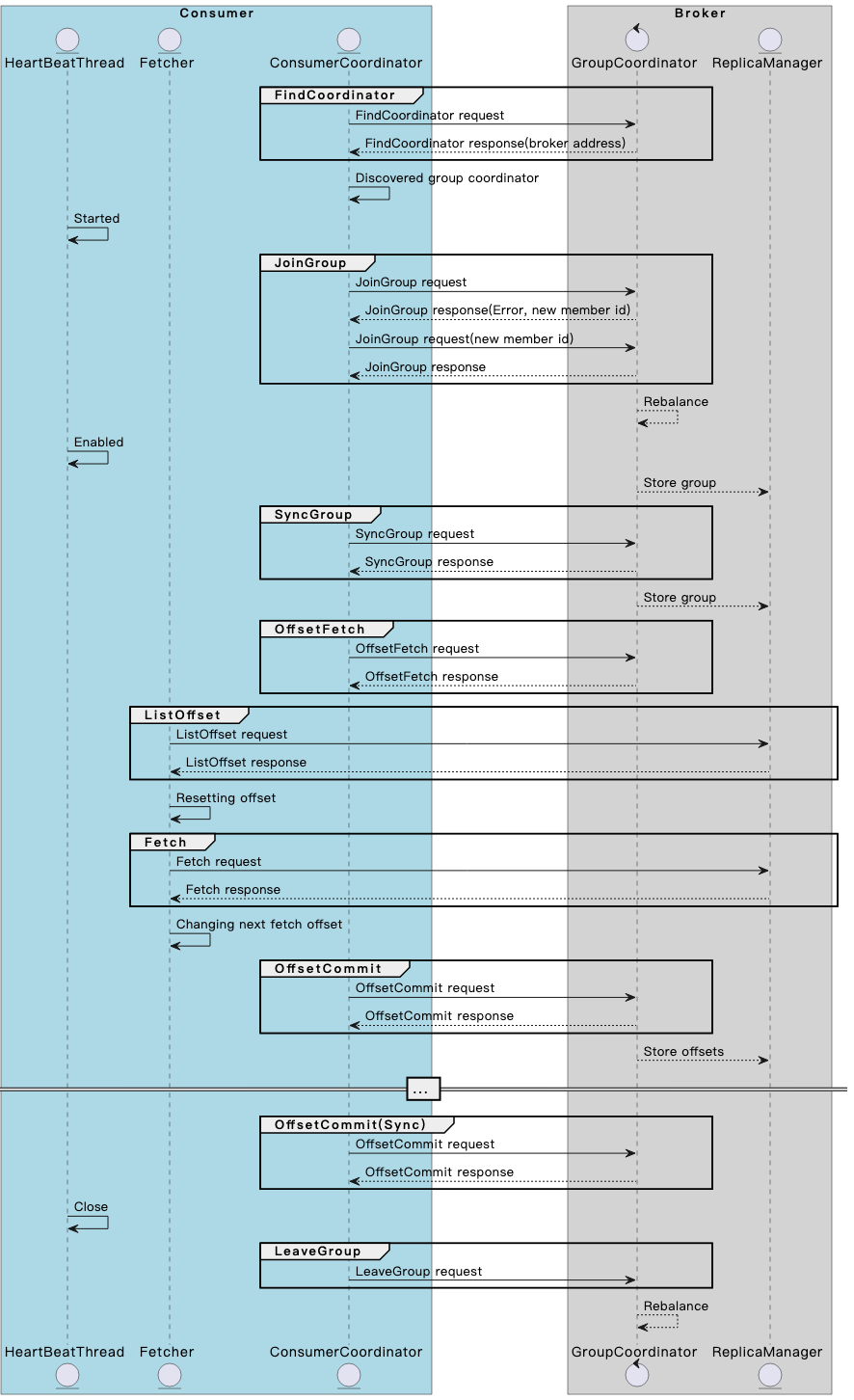
一文搞懂 Kafka consumer 与 broker 交互机制与原理
Kafka Consumer 是 Kafka 事件(消息)的消费端客户端,它是 Kafka 的关键组件之一。为了确保 Kafka 集群的高效运行,Kafka 的客户端被设计为富客户端,例如,消费者组中的分区分配就是在客户端完成的。无论你是 Kafka 的用户还是开发者,都有必要了解 Kafka Consumer 的基本工作原理。
事件点评
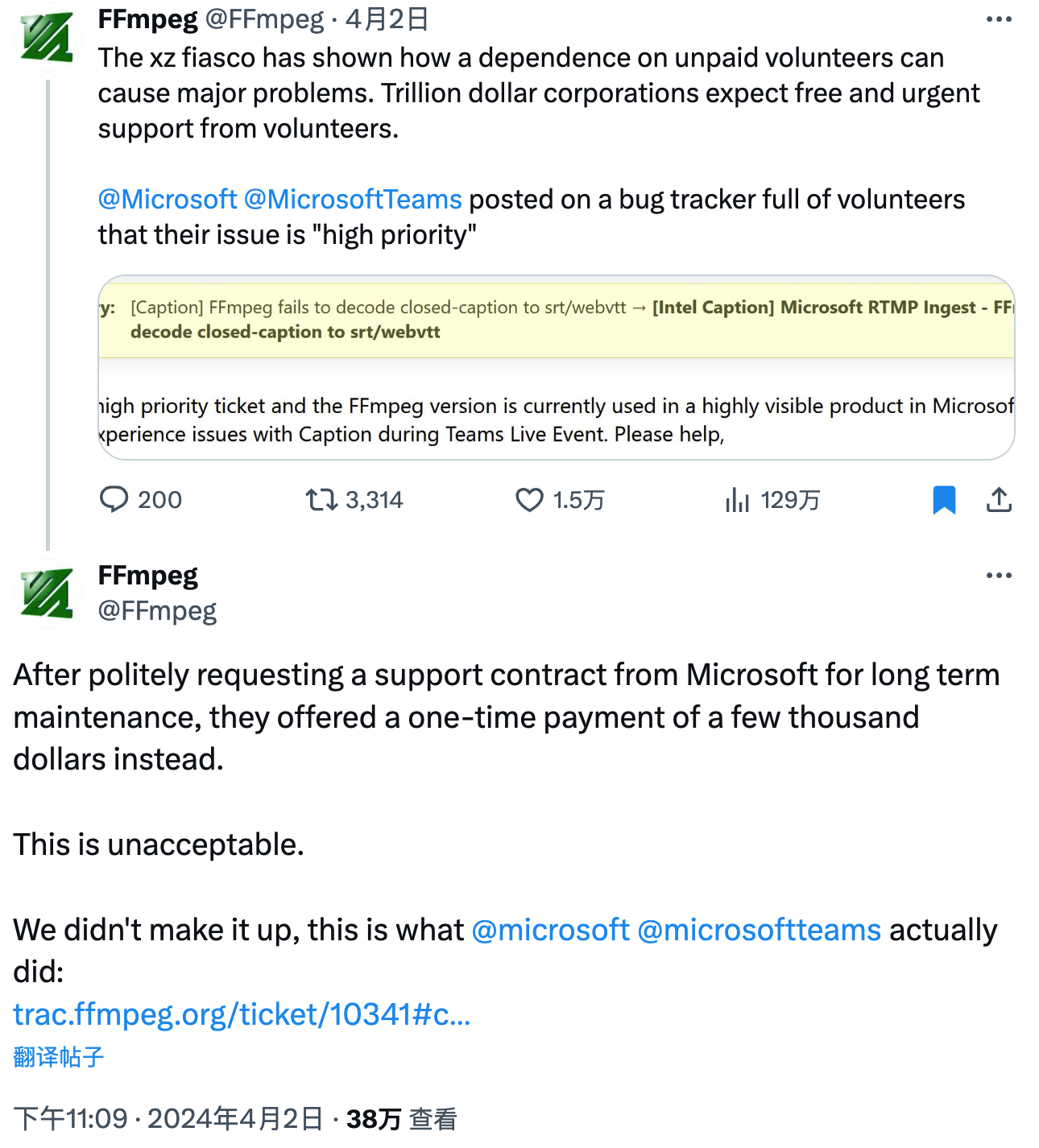
微软都打算付钱了,为何还是被骂 “白嫖” 开源?
微软最近在开源社区被 “围攻” 了,起因是该公司工程师希望一次性支付数千美元,让开源多媒体框架 FFmpeg 优先解决自己的问题,结果被指责 “白嫖” 开源项目。
FFmpeg 开发者认为如果微软产品依赖于 FFmpeg,那么应该签订一个长期支持合同。其他微软工程师指出,在微软签订合同相当繁琐,而微软内部有一个选择开源项目一次性资助数千美元的投票,急于修复代码的微软工程师可能认为后者更方便。
对于微软的高优先级错误,FFmpeg 社区的热心开发者帮助修复了这个问题。不过最终并没有看到微软对 FFmpeg 的捐款。
点评
微软与 FFmpeg 的事件不仅是一个技术问题,更是一个社会和文化问题,它涉及到开源社区的价值观、公司社会责任、项目治理和经济模式等多个方面。这一事件对于推动开源社区和商业公司之间的合作与理解,以及制定更明确的行业标准,具有重要的启示意义。特别是对于那些依赖于开源项目的商业公司而言,如何合理地回馈开源社区成为了一个重要议题。
Zabbix 7.0 变更开源协议,从 GPLv2 转为 AGPLv3
Zabbix 官方于日前宣布,Zabbix 7.0(即将发布的 LTS 版本)将在 AGPL v3 协议下发布。Zabbix 是一个企业级分布式开源监控解决方案,自 2001 年以来的所有主要和次要版本均在 GPLv2 许可下发布。
开源是 Zabbix 商业模式的核心,迁移到 AGPLv3 是确保修改其软件的任何人都可以将其提供给所有人的最佳方式。即将发布的 7.0 版本就是实施的最佳时机,可以实现一箭双雕 —— “我们可以确保没有商业实体在绕过强制性许可证要求的同时窃取我们的产品,并且我们还可以确保任何修改我们代码的人都将他们的修改向所有人公开。”
值得一提的是,此次协议变更不影响任何旧版本的 Zabbix。
点评
这一变更对开源社区和商业用户都产生了重要影响。AGPLv3 协议要求如果用户修改源代码并通过分发或网络提供给他人,则必须共享新的源代码。这意味着任何修改 Zabbix 代码的人都必须公开他们的修改,从而增加了代码的透明度和可追溯性。
对于商业用户来说,这意味着如果他们使用或修改了 Zabbix 代码,他们需要遵守新的协议要求。虽然这可能带来一些额外的合规性挑战,但它也确保了商业实体的任何改进都将回馈给整个社区,从而促进了一个更加健康和可持续的开源生态系统。
总的来说,Zabbix 7.0 版本的开源协议变更是一个重要的发展,它不仅保护了 Zabbix 项目的商业利益,也促进了开源社区的创新和协作。这一事件表明,开源项目可以通过选择合适的许可协议来平衡商业利益和社区贡献,同时保持项目的开放性和透明度。
通义千问开源 320 亿参数模型
阿里云通义千问开源 320 亿参数模型 Qwen1.5-32B,可最大限度兼顾性能、效率和内存占用的平衡,为企业和开发者提供更高性价比的模型选择。
目前,通义千问共开源了 7 款大语言模型,在海内外开源社区累计下载量突破 300 万。
点评
这一模型的开源对于企业和开发者来说,提供了一个在性能、效率和内存占用之间实现更理想平衡的选择。不仅为开发者和企业提供了更高的性价比,而且也是对开源社区的积极贡献。
此外,这一事件也反映了当前AI和机器学习领域的一个趋势,即大模型的发展和开源化。总的来说,阿里云的这一举措不仅对自身具有重大意义,也为整个AI和机器学习领域带来了新的机遇和挑战。它预示着大模型在开源领域的发展,有望推动行业创新和协作的新高峰。
开源之声
媒体观点
北京师范大学科学教育研究院院长、教育部基础教育教学指导委员会委员郑永和在研讨会上提到:冷战时期,美国为应对苏联率先实现载人航天带来的竞争压力而专门通过立法,以10年为周期在中小学开展STEM教育,效果直到近20年后才逐渐体现出来。这为20世纪80年代美国信息技术、电子通信、生物制造等新一轮科技产业革命做了一定的人才准备。
“因此,我们今天加强科学教育,是十分紧迫的任务,但不要流于表面。要持之以恒,以长期主义的精神推动科学教育向更高的水平迈进。”郑永和说。
- 中国青年报
可能没多少人能想到,仅仅短短两周的时间,AI绘画神器Stable Diffusion的开发商AI初创公司Stability AI,就已经走到了树倒猢狲散的边缘。先是在3月末,Stable Diffusion数位核心开发者离职,紧接着该公司创始人、首席执行官Emad Mostaque宣布卸任相关职务,并表示未来将专注开发去中心化AI。如今更是有消息称,据Stability AI内部文件和数十位知情人士透露,该公司的现金储备已经枯竭。
- 三易菌
5款大模型,马斯克的grok1竟是一个复读机?
虽然每家都在鼓吹自家的大模型,但是实际评测下来后,还是有很多意想不到的问题出现。比起高大上的测试,我们在实际使用中需要大模型反复生成多次,才能得到想要的结果。
所以,以目前的AI智能程度来说,并不会出现想象中AI完全取代人类颠覆生产生活的程度。
并且,大模型的使用其实和人本身的知识水平,创造力、想象力有很大的关系。如果你并没有具体的想法,你想要让大模型随便说点什么(say something),可能大模型只会给你回复一个——
huh?(啊?)
- 酷玩实验室
Kimi“颠儿了”以后:国产大模型危机感重重
有了阿里的支持,Kimi不用再担心因为算力不足而宕机。该人士也表示,扩容并非一步到位。一下子扩容太多,容易造成算力闲置和浪费,需要一定的策略。比如,Kimi也会对用户的使用情况进行预测。
自从2022年11月ChatGPT发布以来,国内AI大模型已超200个,且还在持续增加。Kimi的问世,唤醒了行业巨头的危机意识。
但Kimi也并非这场技术竞赛的终点。
- AI新智能
用户观点
微软都打算付钱了,为何还是被骂“白嫖”开源?
- 观点 1:把功能需求当bug提给社区来解决
- 观点 2:相当多的开源项目都接受企业捐赠,代价无非就是优先响应捐赠人的请求,总好过单纯用爱发电。
- 观点 3:不如罗永浩
- 观点 4:问题来了,微软为何不自己fork一份,修复了,再提交pull request
- 观点 5:微软是想收购吧,这就是个托
- 观点 6:美式外包
- 观点 7:几千美金打发乞丐吗
- 观点 8:为什么不学习苹果呢。 让curl 作者帮忙回复用户问题,还分文不付。
腾讯云后台崩了:大量服务报错、控制台登入后无数据
- 观点 1:这个看起来又是裁到哪个大动脉了?
- 观点 2:赔钱
- 观点 3:云厂商自己的可用性都这么差,客户怎能放心?
通义千问开源 320 亿参数模型
- 观点 1:个人体验 qwen 是最好的国产开源大模型, 期待 qwen2 (希望会有), 但是很奇怪, 有些问题32B 回答的 72B 还要好
java 没有能打的 ORM?国产 ORM 框架 sqltoy-orm 5.6.4 发版
- 观点 1:搞多个版本吧,一上来就介绍多牛逼,想用这么牛逼的功能学习曲线又陡,实际我根本用不到。我就想用基本功能。
- 观点 2:sqltoy的策略就是用不到你就当不存在即可,只是一个jar包而已,多余的功能又不会产生干扰性的配置要求
- 观点 3:提个建议,多把用例和文档交给大模型(比如Copilot、通义灵码等)学学,现在mybatis几乎可以完美解答,这个orm还不行,资料太少,未来AI编程要多于人工
程序员梗图
- 十年前,无忧无虑地编程,人生顶级享受
“羡慕了,我对代码从来都没有任何热情,只是单纯为了糊口罢了”
---END---