CeresDB 是一款高性能、分布式的云原生时序数据库,采用 Rust 编写。其开发团队近日宣布:经过近一年的开源研发工作,时序数据库 CeresDB 1.0 正式发布,达到生产可用标准。
CeresDB 1.0 官方中文文档:https://docs.ceresdb.io/cn/
CeresDB 1.0 核心特性介绍
存储引擎
-
支持列式混合存储
-
高效 XOR 过滤器
云原生分布式
-
实现了计算存储分离(支持 OSS 作为数据存储,WAL 实现支持 OBKV、Kafka)
-
支持 HASH 分区表
部署与运维
-
支持单机部署
-
支持分布式集群部署
-
支持 Prometheus + Grafana 搭建自监控
读写协议
-
支持 SQL 查询与写入
-
实现了 CeresDB 内置高性能读写协议,提供多语言 SDK
-
支持 Prometheus,可以作为 Prometheus 的 remote storage 进行使用
多语言读写 SDK
- 实现了四种语言的客户端SDK:Java、Python、Go、Rust
CeresDB 架构介绍
CeresDB 是一个时序数据库,与经典时序数据库相比,CeresDB 的目标是能够同时处理时序型和分析型两种模式的数据,并提供高效的读写。
在经典的时序数据库中,Tag列(InfluxDB称之为Tag,Prometheus称之为Label)通常会对其生成倒排索引,但在实际使用中,Tag的基数在不同的场景中是不一样的 ———— 在某些场景下,Tag的基数非常高(这种场景下的数据,我们称之为分析型数据),而基于倒排索引的读写要为此付出很高的代价。而另一方面,分析型数据库常用的扫描 + 剪枝方法,可以比较高效地处理这样的分析型数据。
因此 CeresDB 的基本设计理念是采用混合存储格式和相应的查询方法,从而达到能够同时高效处理时序型数据和分析型数据。
下图展示了 CeresDB 单机版本的架构
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
性能优化与实验结果
CeresDB 组合使用了列式混合存储、数据分区、剪枝、高效扫描等技术,解决海量时间线(high cardinality)下写入查询性能变差的问题。
写入优化
CeresDB 采用类 LSM(Log-structured merge-tree)写入模型,无需在写入时处理复杂的倒排索引,因此写入性能上较好。
查询优化
主要采用以下技术手段提高查询性能:
剪枝:
-
min/max 剪枝:构建代价比较低,在特定场景,性能较好
-
XOR 过滤器:提高对 parquet 文件中的 row group 的筛选精度
高效扫描:
-
多个 SST 间并发:同时扫描多个 SST 文件
-
单个 SST 内部并发:支持 Parquet 层并行拉取多个 row group
-
合并小 IO:针对 OSS 上的文件,合并小 IO 请求,提高拉取效率
-
本地 cache:缓存 OSS 拉取文件,支持内存和磁盘缓存
性能测试结果
采用 TSBS 进行性能测试。压测参数如下:
-
10个 Tag
-
10 个 Field
-
时间线(Tags 组合数)100w 量级
压测机器配置:24c90g
InfluxDB 版本:1.8.5
CeresDB 版本:1.0.0
写入性能对比
InfluxDB 写入性能随着时间下降较多。CeresDB 在写入稳定后,写入速率趋于平稳,并且总体写入性能表现为 InfluxDB 的 1.5 倍以上(一段时间后可达 2 倍以上差距)
下图中,单行 row 包含 10 个 Field。
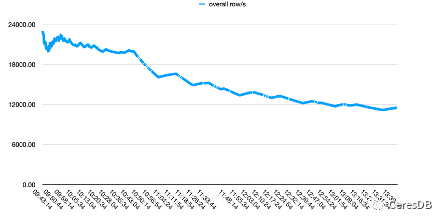
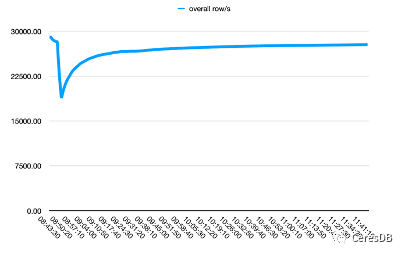
上图为Influxdb,下图为CeresDB
查询性能对比
低筛选度条件(条件:os=Ubuntu15.10),CeresDB 比 InfluxDB 快 26 倍,具体数据如下:
-
CeresDB 查询耗时:15s
-
InfluxDB 查询耗时:6m43s
高筛选度条件(命中的数据较少,条件:hostname=[8个],此时理论上传统倒排索引会更有效),这是 InfluxDB 更有优势的场景,此时在预热完成条件下,CeresDB 比 InfluxDB 慢 5 倍。
-
CeresDB:85ms
-
InfluxDB:15ms
2023 年 roadmap
开发团队表示,2023 年,在 CeresDB 1.0 发布之后,他们大部分工作将聚焦在性能、分布式与周边生态方面的工作。尤其周边生态的对接支持工作,希望能让各种不同的用户更加简单的用上 CeresDB:
周边生态
-
生态兼容,包括 PromQL、InfluxdbQL、OpenTSDB 等常用时序数据库协议兼容
-
运维工具支持,包括 k8s 支持、CeresDB 运维系统、自监控等
-
开发者工具,包括数据导入导出等
性能
-
探索新的存储格式
-
增强不同类型索引,强化 CeresDB 在不同工作负载下的表现
分布式
-
自动负载均衡
-
提高可用性、可靠性