一、引言:
在前面的博客中,我们对ijkplayer整个jni的流程及消息机制都详细的分析了一遍,分析流程机制有助于我们对整个架构有一个大致的了解,便于后续对音视频解码与输出渲染的分析,消息机制的分析有助于我们理解FFmpeg是如何处理输入输出buffer的。接下来,我们先梳理下read_thread这个线程,然后再分析音频是如何解码和输出的。
二、read_thread分析:
read_thread函数非常长,我们只罗列出重点代码:
static int read_thread(void *arg)
{
...
/* 1.申请formate上下文 */
ic = avformat_alloc_context();
...
/* 2.找到输入流类型 */
if (ffp->iformat_name)
is->iformat = av_find_input_format(ffp->iformat_name);
...
/* 3.打开输入流文件并发送消息 */
err = avformat_open_input(&ic, is->filename, is->iformat, &ffp->format_opts);
if (err < 0) {
print_error(is->filename, err);
ret = -1;
goto fail;
}
ffp_notify_msg1(ffp, FFP_MSG_OPEN_INPUT);
...
/* 4.FFmpeg原生接口,我也没怎么用过 */
av_format_inject_global_side_data(ic);
...
/* 5.找到码流信息并发送消息 */
if (ffp->find_stream_info) {
AVDictionary **opts = setup_find_stream_info_opts(ic, ffp->codec_opts);
int orig_nb_streams = ic->nb_streams;
do {
...
err = avformat_find_stream_info(ic, opts);
} while(0);
ffp_notify_msg1(ffp, FFP_MSG_FIND_STREAM_INFO);
...
/* 6.FFmpeg原生接口 */
av_dump_format(ic, 0, is->filename, 0);
...
/* 7.确认是否找到a/v/s的流原始数据 */
if (!ffp->video_disable)
st_index[AVMEDIA_TYPE_VIDEO] =
av_find_best_stream(ic, AVMEDIA_TYPE_VIDEO,
st_index[AVMEDIA_TYPE_VIDEO], -1, NULL, 0);
if (!ffp->audio_disable)
st_index[AVMEDIA_TYPE_AUDIO] =
av_find_best_stream(ic, AVMEDIA_TYPE_AUDIO,
st_index[AVMEDIA_TYPE_AUDIO],
st_index[AVMEDIA_TYPE_VIDEO],
NULL, 0);
if (!ffp->video_disable && !ffp->subtitle_disable)
st_index[AVMEDIA_TYPE_SUBTITLE] =
av_find_best_stream(ic, AVMEDIA_TYPE_SUBTITLE,
st_index[AVMEDIA_TYPE_SUBTITLE],
(st_index[AVMEDIA_TYPE_AUDIO] >= 0 ?
st_index[AVMEDIA_TYPE_AUDIO] :
st_index[AVMEDIA_TYPE_VIDEO]),
NULL, 0);
...
/* 8.打开a/v/s的流并配置好对应解码器(重要) */
/* open the streams */
if (st_index[AVMEDIA_TYPE_AUDIO] >= 0) {
stream_component_open(ffp, st_index[AVMEDIA_TYPE_AUDIO]);
} else {
ffp->av_sync_type = AV_SYNC_VIDEO_MASTER;
is->av_sync_type = ffp->av_sync_type;
}
ret = -1;
if (st_index[AVMEDIA_TYPE_VIDEO] >= 0) {
ret = stream_component_open(ffp, st_index[AVMEDIA_TYPE_VIDEO]);
}
if (is->show_mode == SHOW_MODE_NONE)
is->show_mode = ret >= 0 ? SHOW_MODE_VIDEO : SHOW_MODE_RDFT;
if (st_index[AVMEDIA_TYPE_SUBTITLE] >= 0) {
stream_component_open(ffp, st_index[AVMEDIA_TYPE_SUBTITLE]);
}
ffp_notify_msg1(ffp, FFP_MSG_COMPONENT_OPEN);
...
/* 9.FFmpeg准备工作完毕并通知上层 */
ffp->prepared = true;
ffp_notify_msg1(ffp, FFP_MSG_PREPARED);
...
/* 10.for循环,开始读取待解码数据 */
for (;;) {
/* 读取a/v/s数据 */
...
}
...
}
实际上,整个read_thread基本都是照搬的FFmpeg,只是添加了一些辅助代码,比如ijkplayer维护的消息机制等。接下来先分析音频解码和输出的创建。
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
三、音频解码线程分析:
FFmpeg将解码和输出两个模块的代码合在一起穿插写的。我们进入stream_component_open函数,这个函数很长,尽量压缩下:
/* open a given stream. Return 0 if OK */
static int stream_component_open(FFPlayer *ffp, int stream_index)
{
VideoState *is = ffp->is;
AVFormatContext *ic = is->ic;
AVCodecContext *avctx;
AVCodec *codec = NULL;
const char *forced_codec_name = NULL;
AVDictionary *opts = NULL;
AVDictionaryEntry *t = NULL;
int sample_rate, nb_channels;
int64_t channel_layout;
int ret = 0;
int stream_lowres = ffp->lowres;
if (stream_index < 0 || stream_index >= ic->nb_streams)
return -1;
avctx = avcodec_alloc_context3(NULL);
if (!avctx)
return AVERROR(ENOMEM);
ret = avcodec_parameters_to_context(avctx, ic->streams[stream_index]->codecpar);
if (ret < 0)
goto fail;
av_codec_set_pkt_timebase(avctx, ic->streams[stream_index]->time_base);
/* 通过codec_id找到对应解码器 */
codec = avcodec_find_decoder(avctx->codec_id);
switch (avctx->codec_type) {
case AVMEDIA_TYPE_AUDIO : is->last_audio_stream = stream_index; forced_codec_name = ffp->audio_codec_name; break;
case AVMEDIA_TYPE_SUBTITLE: is->last_subtitle_stream = stream_index; forced_codec_name = ffp->subtitle_codec_name; break;
case AVMEDIA_TYPE_VIDEO : is->last_video_stream = stream_index; forced_codec_name = ffp->video_codec_name; break;
default: break;
}
/* 通过codec_name找到解码器 */
if (forced_codec_name)
codec = avcodec_find_decoder_by_name(forced_codec_name);
if (!codec) {
if (forced_codec_name) av_log(NULL, AV_LOG_WARNING,
"No codec could be found with name '%s'\n", forced_codec_name);
else av_log(NULL, AV_LOG_WARNING,
"No codec could be found with id %d\n", avctx->codec_id);
ret = AVERROR(EINVAL);
goto fail;
}
avctx->codec_id = codec->id;
...
is->eof = 0;
ic->streams[stream_index]->discard = AVDISCARD_DEFAULT;
switch (avctx->codec_type) {
case AVMEDIA_TYPE_AUDIO:
...
sample_rate = avctx->sample_rate;
nb_channels = avctx->channels;
channel_layout = avctx->channel_layout;
...
/* prepare audio output */
/* 1.准备音频输出 */
if ((ret = audio_open(ffp, channel_layout, nb_channels, sample_rate, &is->audio_tgt)) < 0)
goto fail;
ffp_set_audio_codec_info(ffp, AVCODEC_MODULE_NAME, avcodec_get_name(avctx->codec_id));
is->audio_hw_buf_size = ret;
is->audio_src = is->audio_tgt;
is->audio_buf_size = 0;
is->audio_buf_index = 0;
/* init averaging filter */
is->audio_diff_avg_coef = exp(log(0.01) / AUDIO_DIFF_AVG_NB);
is->audio_diff_avg_count = 0;
/* since we do not have a precise anough audio FIFO fullness,
we correct audio sync only if larger than this threshold */
is->audio_diff_threshold = 2.0 * is->audio_hw_buf_size / is->audio_tgt.bytes_per_sec;
is->audio_stream = stream_index;
is->audio_st = ic->streams[stream_index];
/* 2.初始化解码器 */
decoder_init(&is->auddec, avctx, &is->audioq, is->continue_read_thread);
if ((is->ic->iformat->flags & (AVFMT_NOBINSEARCH | AVFMT_NOGENSEARCH | AVFMT_NO_BYTE_SEEK)) && !is->ic->iformat->read_seek) {
is->auddec.start_pts = is->audio_st->start_time;
is->auddec.start_pts_tb = is->audio_st->time_base;
}
/* 3.开启解码器 */
if ((ret = decoder_start(&is->auddec, audio_thread, ffp, "ff_audio_dec")) < 0)
goto out;
SDL_AoutPauseAudio(ffp->aout, 0);
break;
case AVMEDIA_TYPE_VIDEO:
...
case AVMEDIA_TYPE_SUBTITLE:
...
}
...
}
audio/video/subtitle均共享调用stream_component_open这个函数来确定解码和输出相关内容。
我们先看注释二:
decoder_init(&is->auddec, avctx, &is->audioq, is->continue_read_thread);
static void decoder_init(Decoder *d, AVCodecContext *avctx, PacketQueue *queue, SDL_cond *empty_queue_cond) {
memset(d, 0, sizeof(Decoder));
d->avctx = avctx;
d->queue = queue;
d->empty_queue_cond = empty_queue_cond;
d->start_pts = AV_NOPTS_VALUE;
d->first_frame_decoded_time = SDL_GetTickHR();
d->first_frame_decoded = 0;
SDL_ProfilerReset(&d->decode_profiler, -1);
}
在read_thread中我们已经确定了decoder是什么了,所以这里其实是将is->audioq绑定到解码器decoder中。
注释三:
if ((ret = decoder_start(&is->auddec, audio_thread, ffp, "ff_audio_dec")) < 0)
goto out;进入decoder_start:
static int decoder_start(Decoder *d, int (*fn)(void *), void *arg, const char *name)
{
/* packet队列开始处理packet */
packet_queue_start(d->queue);
d->decoder_tid = SDL_CreateThreadEx(&d->_decoder_tid, fn, arg, name);
if (!d->decoder_tid) {
av_log(NULL, AV_LOG_ERROR, "SDL_CreateThread(): %s\n", SDL_GetError());
return AVERROR(ENOMEM);
}
return 0;
}
这个函数中最重要的就是packet_queue_start:
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
static void packet_queue_start(PacketQueue *q)
{
SDL_LockMutex(q->mutex);
/* 开始接收数据 */
q->abort_request = 0;
packet_queue_put_private(q, &flush_pkt);
SDL_UnlockMutex(q->mutex);
}
abort_request这个变量我们已经在消息机制的介绍中多次看到了,其值为0表示队列开始转起来了,开启解码。
既然队列开启了解码,那么我们立马就会联想到一个问题,待解码数据是从哪里写入到队列的呢?还记得read_thread中最后的for循环吗?答案就在那里,下面分析下for循环看看是如何填充输入buffer的:
for (;;) {
...
/* 前面是seek相关的,我们不重点关注 */
/* if the queue are full, no need to read more */
/* 如果解码太慢了,packet已经读取满了,则睡眠10ms */
if (ffp->infinite_buffer<1 && !is->seek_req &&
#ifdef FFP_MERGE
(is->audioq.size + is->videoq.size + is->subtitleq.size > MAX_QUEUE_SIZE
#else
(is->audioq.size + is->videoq.size + is->subtitleq.size > ffp->dcc.max_buffer_size
#endif
|| ( stream_has_enough_packets(is->audio_st, is->audio_stream, &is->audioq, MIN_FRAMES)
&& stream_has_enough_packets(is->video_st, is->video_stream, &is->videoq, MIN_FRAMES)
&& stream_has_enough_packets(is->subtitle_st, is->subtitle_stream, &is->subtitleq, MIN_FRAMES)))) {
if (!is->eof) {
ffp_toggle_buffering(ffp, 0);
}
/* wait 10 ms */
SDL_LockMutex(wait_mutex);
SDL_CondWaitTimeout(is->continue_read_thread, wait_mutex, 10);
SDL_UnlockMutex(wait_mutex);
continue;
}
...
pkt->flags = 0;
/* 1.读取packet数据 */
ret = av_read_frame(ic, pkt);
/* 下面是一些eof或者错误处理,不重点关注 */
...
/* 根据pkt中获取的id将原始数据推入到packet队列中 */
/* check if packet is in play range specified by user, then queue, otherwise discard */
stream_start_time = ic->streams[pkt->stream_index]->start_time;
pkt_ts = pkt->pts == AV_NOPTS_VALUE ? pkt->dts : pkt->pts;
pkt_in_play_range = ffp->duration == AV_NOPTS_VALUE ||
(pkt_ts - (stream_start_time != AV_NOPTS_VALUE ? stream_start_time : 0)) *
av_q2d(ic->streams[pkt->stream_index]->time_base) -
(double)(ffp->start_time != AV_NOPTS_VALUE ? ffp->start_time : 0) / 1000000
<= ((double)ffp->duration / 1000000);
if (pkt->stream_index == is->audio_stream && pkt_in_play_range) {
packet_queue_put(&is->audioq, pkt);
} else if (pkt->stream_index == is->video_stream && pkt_in_play_range
&& !(is->video_st && (is->video_st->disposition & AV_DISPOSITION_ATTACHED_PIC))) {
packet_queue_put(&is->videoq, pkt);
} else if (pkt->stream_index == is->subtitle_stream && pkt_in_play_range) {
packet_queue_put(&is->subtitleq, pkt);
} else {
av_packet_unref(pkt);
}
}
原始数据的填充我们看明白了,packet队列的开启也看到了在decoder_start中,下面就是看解码器如果从packet中拿去数据了,回到decoder_start创建的那个线程audio_thread:
static int audio_thread(void *arg)
{
do {
ffp_audio_statistic_l(ffp);
/* 1.将packet中的数据送去解码 */
if ((got_frame = decoder_decode_frame(ffp, &is->auddec, frame, NULL)) < 0)
goto the_end;
if (got_frame) {
...
/* 拿到数据之后的处理 */
if (!(af = frame_queue_peek_writable(&is->sampq)))
goto the_end;
af->pts = (frame->pts == AV_NOPTS_VALUE) ? NAN : frame->pts * av_q2d(tb);
af->pos = frame->pkt_pos;
af->serial = is->auddec.pkt_serial;
af->duration = av_q2d((AVRational){frame->nb_samples, frame->sample_rate});
av_frame_move_ref(af->frame, frame);
frame_queue_push(&is->sampq)
}
} while (ret >= 0 || ret == AVERROR(EAGAIN) || ret == AVERROR_EOF);
}
整个音频解码线程就是由一个do…while构成的,其运行原理就是不停地调用FFmpeg的解码接口,将输入buffer送给FFmpeg,如果有获取到帧,则将解码完成后的pcm数据推入到帧队列中。
先看注释一:
static int decoder_decode_frame(FFPlayer *ffp, Decoder *d, AVFrame *frame, AVSubtitle *sub) {
int ret = AVERROR(EAGAIN);
for (;;) {
AVPacket pkt;
if (d->queue->serial == d->pkt_serial) {
do {
/* 如果queue还未开启解码,则返回错误 */
if (d->queue->abort_request)
return -1;
switch (d->avctx->codec_type) {
/* 视频处理 */
case AVMEDIA_TYPE_VIDEO:
....
break;
/* 音频处理 */
case AVMEDIA_TYPE_AUDIO:
/* 获取解码后的数据 */
ret = avcodec_receive_frame(d->avctx, frame);
if (ret >= 0) {
AVRational tb = (AVRational){1, frame->sample_rate};
if (frame->pts != AV_NOPTS_VALUE)
frame->pts = av_rescale_q(frame->pts, av_codec_get_pkt_timebase(d->avctx), tb);
else if (d->next_pts != AV_NOPTS_VALUE)
frame->pts = av_rescale_q(d->next_pts, d->next_pts_tb, tb);
if (frame->pts != AV_NOPTS_VALUE) {
d->next_pts = frame->pts + frame->nb_samples;
d->next_pts_tb = tb;
}
}
break;
default:
break;
}
if (ret == AVERROR_EOF) {
d->finished = d->pkt_serial;
avcodec_flush_buffers(d->avctx);
return 0;
}
if (ret >= 0)
return 1;
} while (ret != AVERROR(EAGAIN));
/* 通过do...while来读取数据 */
do {
/* 如果数据不足,则等待 */
if (d->queue->nb_packets == 0)
SDL_CondSignal(d->empty_queue_cond);
if (d->packet_pending) {
av_packet_move_ref(&pkt, &d->pkt);
d->packet_pending = 0;
} else {
/* 否则从packet序列中读取一包数据 */
if (packet_queue_get_or_buffering(ffp, d->queue, &pkt, &d->pkt_serial, &d->finished) < 0)
return -1;
}
} while (d->queue->serial != d->pkt_serial);
}
if (pkt.data == flush_pkt.data) {
...
} else {
/* 如果读取到的数据是字幕的处理 */
if (d->avctx->codec_type == AVMEDIA_TYPE_SUBTITLE) {
...
} else {
/* 将读取出来的数据送入到decodeer */
if (avcodec_send_packet(d->avctx, &pkt) == AVERROR(EAGAIN)) {
av_log(d->avctx, AV_LOG_ERROR, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
d->packet_pending = 1;
av_packet_move_ref(&d->pkt, &pkt);
}
}
/* 释放packet */
av_packet_unref(&pkt);
}
}
}
函数的逻辑其实也很好理解,在进入这个函数之前,已经分别调用decoder_init和decoder_start将packet所在的queue绑定到了解码器并且开启了队列的运转(q->abort_request = 0),重点已经注释在了代码中,函数对音频的处理就是从queue中取出一包数据,然后送往解码器进行解码。
接下来看数据是如何收帧的,就在该函数的avcodec_receive_frame:
int attribute_align_arg avcodec_receive_frame(AVCodecContext *avctx, AVFrame *frame)
{
int ret;
av_frame_unref(frame);
if (!avcodec_is_open(avctx) || !av_codec_is_decoder(avctx->codec))
return AVERROR(EINVAL);
if (avctx->codec->receive_frame) {
if (avctx->internal->draining && !(avctx->codec->capabilities & AV_CODEC_CAP_DELAY))
return AVERROR_EOF;
/* 调用decoder的receive_frame函数获取帧 */
ret = avctx->codec->receive_frame(avctx, frame);
if (ret >= 0) {
if (av_frame_get_best_effort_timestamp(frame) == AV_NOPTS_VALUE) {
av_frame_set_best_effort_timestamp(frame,
guess_correct_pts(avctx, frame->pts, frame->pkt_dts));
}
}
return ret;
}
...
if (!avctx->internal->buffer_frame->buf[0])
return avctx->internal->draining ? AVERROR_EOF : AVERROR(EAGAIN);
av_frame_move_ref(frame, avctx->internal->buffer_frame);
return 0;
}
总结下decoder_decode_frame,执行的操作就两个,一个是从packet序列中取出源数据送往解码器,二是从decoder中拿到解码完后的pcm数据。既然已经拿到了pcm数据,接下来就需要看看,代码中是如何将pcm数据送至aout进行输出的了。
四、aout输出分析:
我们回到stream_component_open的注释一:
if ((ret = audio_open(ffp, channel_layout, nb_channels, sample_rate, &is->audio_tgt)) < 0)
goto fail;
进入audio_open:
static int audio_open(FFPlayer *opaque, int64_t wanted_channel_layout, int wanted_nb_channels, int wanted_sample_rate, struct AudioParams *audio_hw_params)
{
FFPlayer *ffp = opaque;
VideoState *is = ffp->is;
/* 注意这个结构体 */
SDL_AudioSpec wanted_spec, spec;
const char *env;
static const int next_nb_channels[] = {0, 0, 1, 6, 2, 6, 4, 6};
#ifdef FFP_MERGE
static const int next_sample_rates[] = {0, 44100, 48000, 96000, 192000};
#endif
static const int next_sample_rates[] = {0, 44100, 48000};
int next_sample_rate_idx = FF_ARRAY_ELEMS(next_sample_rates) - 1;
env = SDL_getenv("SDL_AUDIO_CHANNELS");
if (env) {
wanted_nb_channels = atoi(env);
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
}
if (!wanted_channel_layout || wanted_nb_channels != av_get_channel_layout_nb_channels(wanted_channel_layout)) {
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
wanted_channel_layout &= ~AV_CH_LAYOUT_STEREO_DOWNMIX;
}
wanted_nb_channels = av_get_channel_layout_nb_channels(wanted_channel_layout);
wanted_spec.channels = wanted_nb_channels;
wanted_spec.freq = wanted_sample_rate;
if (wanted_spec.freq <= 0 || wanted_spec.channels <= 0) {
av_log(NULL, AV_LOG_ERROR, "Invalid sample rate or channel count!\n");
return -1;
}
while (next_sample_rate_idx && next_sample_rates[next_sample_rate_idx] >= wanted_spec.freq)
next_sample_rate_idx--;
wanted_spec.format = AUDIO_S16SYS;
wanted_spec.silence = 0;
wanted_spec.samples = FFMAX(SDL_AUDIO_MIN_BUFFER_SIZE, 2 << av_log2(wanted_spec.freq / SDL_AoutGetAudioPerSecondCallBacks(ffp->aout)));
/* 1.确定aout回调函数 */
wanted_spec.callback = sdl_audio_callback;
/* 2.确定pcm数据来源 */
wanted_spec.userdata = opaque;
/* 3.通过while循环来不停地将数据从FFmpeg写入到aout */
while (SDL_AoutOpenAudio(ffp->aout, &wanted_spec, &spec) < 0) {
/* avoid infinity loop on exit. --by bbcallen */
if (is->abort_request)
return -1;
av_log(NULL, AV_LOG_WARNING, "SDL_OpenAudio (%d channels, %d Hz): %s\n",
wanted_spec.channels, wanted_spec.freq, SDL_GetError());
wanted_spec.channels = next_nb_channels[FFMIN(7, wanted_spec.channels)];
if (!wanted_spec.channels) {
wanted_spec.freq = next_sample_rates[next_sample_rate_idx--];
wanted_spec.channels = wanted_nb_channels;
if (!wanted_spec.freq) {
av_log(NULL, AV_LOG_ERROR,
"No more combinations to try, audio open failed\n");
return -1;
}
}
wanted_channel_layout = av_get_default_channel_layout(wanted_spec.channels);
}
if (spec.format != AUDIO_S16SYS) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised audio format %d is not supported!\n", spec.format);
return -1;
}
if (spec.channels != wanted_spec.channels) {
wanted_channel_layout = av_get_default_channel_layout(spec.channels);
if (!wanted_channel_layout) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised channel count %d is not supported!\n", spec.channels);
return -1;
}
}
audio_hw_params->fmt = AV_SAMPLE_FMT_S16;
audio_hw_params->freq = spec.freq;
audio_hw_params->channel_layout = wanted_channel_layout;
audio_hw_params->channels = spec.channels;
audio_hw_params->frame_size = av_samples_get_buffer_size(NULL, audio_hw_params->channels, 1, audio_hw_params->fmt, 1);
audio_hw_params->bytes_per_sec = av_samples_get_buffer_size(NULL, audio_hw_params->channels, audio_hw_params->freq, audio_hw_params->fmt, 1);
if (audio_hw_params->bytes_per_sec <= 0 || audio_hw_params->frame_size <= 0) {
av_log(NULL, AV_LOG_ERROR, "av_samples_get_buffer_size failed\n");
return -1;
}
/* 设置latency,蓝牙场景使用率较高 */
SDL_AoutSetDefaultLatencySeconds(ffp->aout, ((double)(2 * spec.size)) / audio_hw_params->bytes_per_sec);
return spec.size;
}
函数看起来有点复杂,但是理解起来还好,我们首先需要注意函数进来时的局部变量SDL_AudioSpec,看一下这个结构体的定义:
typedef struct SDL_AudioSpec
{
int freq; /**< DSP frequency -- samples per second */
SDL_AudioFormat format; /**< Audio data format */
Uint8 channels; /**< Number of channels: 1 mono, 2 stereo */
Uint8 silence; /**< Audio buffer silence value (calculated) */
Uint16 samples; /**< Audio buffer size in samples (power of 2) */
Uint16 padding; /**< NOT USED. Necessary for some compile environments */
Uint32 size; /**< Audio buffer size in bytes (calculated) */
SDL_AudioCallback callback;
void *userdata;
} SDL_AudioSpec;
最重要的两个变量却没有注释,callback是aout调用的回调函数,其作用是将FFmpeg解码出来的数据拷贝到aout,我们在前面的博客中分析过,ijkplayer会使用Android原生的AudioTrack或者openSLES来进行输出。userdata则是FFmpeg解码出来的pcm数据,总的来说,其机制就是将userdata中的数据写入到callback中aout的输出buffer中。可以看到代码中是将sdl_audio_callback赋值给了wanted_spec.callback,这个函数位于ff_ffplay.c中。opaque赋值给了userdata,是因为opaque的结构体类型是FFPlayer,里面包含了输入和输出buffer。
下面看一下while循环的SDL_AoutOpenAudio是怎么做的:
int SDL_AoutOpenAudio(SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
if (aout && desired && aout->open_audio)
return aout->open_audio(aout, desired, obtained);
return -1;
}
可以看到,这里是去调用aout的open_audio函数指针,我们需要明确其指针指向的函数是什么?如何确认呢?我们先要明确aout是在哪里创建的,翻看一下前面的ijkplayer创建流程,我们找到在_prepareAsync阶段,ijkplayer.c会调入到ff_ffplay.c中的ffp_prepare_async_l,这里回去创建aout:
if (!ffp->aout) {
ffp->aout = ffpipeline_open_audio_output(ffp->pipeline, ffp);
if (!ffp->aout)
return -1;
}
跟踪下ffpipeline_open_audio_output:
SDL_Aout *ffpipeline_open_audio_output(IJKFF_Pipeline *pipeline, FFPlayer *ffp)
{
return pipeline->func_open_audio_output(pipeline, ffp);
}
这里又是一个函数指针,还需要确认pipeline是什么时候创建的:
IJKFF_Pipeline *ffpipeline_create_from_android(FFPlayer *ffp)
{
...
pipeline->func_open_audio_output = func_open_audio_output;
...
}
最终找到了出处:
static SDL_Aout *func_open_audio_output(IJKFF_Pipeline *pipeline, FFPlayer *ffp)
{
SDL_Aout *aout = NULL;
if (ffp->opensles) {
aout = SDL_AoutAndroid_CreateForOpenSLES();
} else {
aout = SDL_AoutAndroid_CreateForAudioTrack();
}
if (aout)
SDL_AoutSetStereoVolume(aout, pipeline->opaque->left_volume, pipeline->opaque->right_volume);
return aout;
}
也就是说,走AudioTrack还是OpenSLES其实是由上层apk通过opt来设置的。代码中我是采用AudioTrack的,自然aout->open_audio也要走对应的函数aout_open_audio:
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
static int aout_open_audio(SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
// SDL_Aout_Opaque *opaque = aout->opaque;
JNIEnv *env = NULL;
if (JNI_OK != SDL_JNI_SetupThreadEnv(&env)) {
ALOGE("aout_open_audio: AttachCurrentThread: failed");
return -1;
}
return aout_open_audio_n(env, aout, desired, obtained);
}
继续跟踪aout_open_audio_n:
static int aout_open_audio_n(JNIEnv *env, SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
assert(desired);
SDL_Aout_Opaque *opaque = aout->opaque;
opaque->spec = *desired;
/* 1.通过jni层反射到java层去创建audiotrack */
opaque->atrack = SDL_Android_AudioTrack_new_from_sdl_spec(env, desired);
if (!opaque->atrack) {
ALOGE("aout_open_audio_n: failed to new AudioTrcak()");
return -1;
}
/* 2.获取最小buffersize */
opaque->buffer_size = SDL_Android_AudioTrack_get_min_buffer_size(opaque->atrack);
if (opaque->buffer_size <= 0) {
ALOGE("aout_open_audio_n: failed to getMinBufferSize()");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
/* 3.申请native层buffer */
opaque->buffer = malloc(opaque->buffer_size);
if (!opaque->buffer) {
ALOGE("aout_open_audio_n: failed to allocate buffer");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
if (obtained) {
SDL_Android_AudioTrack_get_target_spec(opaque->atrack, obtained);
SDLTRACE("audio target format fmt:0x%x, channel:0x%x", (int)obtained->format, (int)obtained->channels);
}
opaque->audio_session_id = SDL_Android_AudioTrack_getAudioSessionId(env, opaque->atrack);
ALOGI("audio_session_id = %d\n", opaque->audio_session_id);
opaque->pause_on = 1;
opaque->abort_request = 0;
/* 4.创建aout线程 */
opaque->audio_tid = SDL_CreateThreadEx(&opaque->_audio_tid, aout_thread, aout, "ff_aout_android");
if (!opaque->audio_tid) {
ALOGE("aout_open_audio_n: failed to create audio thread");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
return 0;
}
注释一主要是jni层回调java方法来创建audiotrack,在获取了audiotrack的最小buffersize之后,还将在jni层申请一个一样大小的buffer,用于将FFmpeg中解码出来的pcm数据拷贝到这个native层的buffer中,然后再将buffer中的数据写入到audiotrack。具体怎么写的,需要看aout_thread这个线程,跟进一下:
static int aout_thread(void *arg)
{
SDL_Aout *aout = arg;
// SDL_Aout_Opaque *opaque = aout->opaque;
JNIEnv *env = NULL;
if (JNI_OK != SDL_JNI_SetupThreadEnv(&env)) {
ALOGE("aout_thread: SDL_AndroidJni_SetupEnv: failed");
return -1;
}
return aout_thread_n(env, aout);
}
static int aout_thread_n(JNIEnv *env, SDL_Aout *aout)
{
SDL_Aout_Opaque *opaque = aout->opaque;
SDL_Android_AudioTrack *atrack = opaque->atrack;
SDL_AudioCallback audio_cblk = opaque->spec.callback;
void *userdata = opaque->spec.userdata;
uint8_t *buffer = opaque->buffer;
/* 注意每次copy的数据量256 */
int copy_size = 256;
assert(atrack);
assert(buffer);
SDL_SetThreadPriority(SDL_THREAD_PRIORITY_HIGH);
if (!opaque->abort_request && !opaque->pause_on)
SDL_Android_AudioTrack_play(env, atrack);
while (!opaque->abort_request) {
SDL_LockMutex(opaque->wakeup_mutex);
if (!opaque->abort_request && opaque->pause_on) {
SDL_Android_AudioTrack_pause(env, atrack);
while (!opaque->abort_request && opaque->pause_on) {
SDL_CondWaitTimeout(opaque->wakeup_cond, opaque->wakeup_mutex, 1000);
}
if (!opaque->abort_request && !opaque->pause_on) {
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
}
SDL_Android_AudioTrack_play(env, atrack);
}
}
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
}
if (opaque->need_set_volume) {
opaque->need_set_volume = 0;
SDL_Android_AudioTrack_set_volume(env, atrack, opaque->left_volume, opaque->right_volume);
}
if (opaque->speed_changed) {
opaque->speed_changed = 0;
SDL_Android_AudioTrack_setSpeed(env, atrack, opaque->speed);
}
SDL_UnlockMutex(opaque->wakeup_mutex);
/* 1.调用回调函数先往native层的buffer中写数据 */
audio_cblk(userdata, buffer, copy_size);
if (opaque->need_flush) {
SDL_Android_AudioTrack_flush(env, atrack);
opaque->need_flush = false;
}
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
} else {
/* 2.将native层的buffer数据写入到audiotrack中 */
int written = SDL_Android_AudioTrack_write(env, atrack, buffer, copy_size);
if (written != copy_size) {
ALOGW("AudioTrack: not all data copied %d/%d", (int)written, (int)copy_size);
}
}
// TODO: 1 if callback return -1 or 0
}
SDL_Android_AudioTrack_free(env, atrack);
return 0;
}
可以看到每次写数据的时候,每次的copy量是256字节,先看下audio_cblk,这个函数我们在之前已经分析了,是ff_play.c中的sdl_audio_callback:
/* prepare a new audio buffer */
static void sdl_audio_callback(void *opaque, Uint8 *stream, int len)
{
FFPlayer *ffp = opaque;
VideoState *is = ffp->is;
int audio_size, len1;
if (!ffp || !is) {
memset(stream, 0, len);
return;
}
ffp->audio_callback_time = av_gettime_relative();
...
while (len > 0) {
/* audio_buf_index相当于写指针位置 */
if (is->audio_buf_index >= is->audio_buf_size) {
/* 从FrameQueue中获取待播放的frame,返回值audio_size则为当前帧的大小 */
audio_size = audio_decode_frame(ffp);
if (audio_size < 0) {
/* if error, just output silence */
is->audio_buf = NULL;
is->audio_buf_size = SDL_AUDIO_MIN_BUFFER_SIZE / is->audio_tgt.frame_size * is->audio_tgt.frame_size;
} else {
if (is->show_mode != SHOW_MODE_VIDEO)
update_sample_display(is, (int16_t *)is->audio_buf, audio_size);
is->audio_buf_size = audio_size;
}
is->audio_buf_index = 0;
}
if (is->auddec.pkt_serial != is->audioq.serial) {
is->audio_buf_index = is->audio_buf_size;
memset(stream, 0, len);
// stream += len;
// len = 0;
SDL_AoutFlushAudio(ffp->aout);
break;
}
/* 计算并更新本帧还可以写入的数据 */
len1 = is->audio_buf_size - is->audio_buf_index;
if (len1 > len)
len1 = len;
if (!is->muted && is->audio_buf && is->audio_volume == SDL_MIX_MAXVOLUME)
/* copy数据 */
memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);
else {
memset(stream, 0, len1);
if (!is->muted && is->audio_buf)
SDL_MixAudio(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1, is->audio_volume);
}
/* 更新相关的值 */
len -= len1;
stream += len1;
is->audio_buf_index += len1;
}
is->audio_write_buf_size = is->audio_buf_size - is->audio_buf_index;
/* Let's assume the audio driver that is used by SDL has two periods. */
if (!isnan(is->audio_clock)) {
set_clock_at(&is->audclk, is->audio_clock - (double)(is->audio_write_buf_size) / is->audio_tgt.bytes_per_sec - SDL_AoutGetLatencySeconds(ffp->aout), is->audio_clock_serial, ffp->audio_callback_time / 1000000.0);
sync_clock_to_slave(&is->extclk, &is->audclk);
}
if (!ffp->first_audio_frame_rendered) {
ffp->first_audio_frame_rendered = 1;
ffp_notify_msg1(ffp, FFP_MSG_AUDIO_RENDERING_START);
}
if (is->latest_audio_seek_load_serial == is->audio_clock_serial) {
int latest_audio_seek_load_serial = __atomic_exchange_n(&(is->latest_audio_seek_load_serial), -1, memory_order_seq_cst);
if (latest_audio_seek_load_serial == is->audio_clock_serial) {
if (ffp->av_sync_type == AV_SYNC_AUDIO_MASTER) {
ffp_notify_msg2(ffp, FFP_MSG_AUDIO_SEEK_RENDERING_START, 1);
} else {
ffp_notify_msg2(ffp, FFP_MSG_AUDIO_SEEK_RENDERING_START, 0);
}
}
}
if (ffp->render_wait_start && !ffp->start_on_prepared && is->pause_req) {
while (is->pause_req && !is->abort_request) {
SDL_Delay(20);
}
}
}
整个函数还是比较好理解,就是从FFmpeg中将数据捞上来写入到native层开的buffer中,简单分析下audio_decode_frame是如何捞数据的:
static int audio_decode_frame(FFPlayer *ffp)
...
/* 1.从FrameQueue中dequeue一帧数据 */
if (!(af = frame_queue_peek_readable(&is->sampq)))
return -1;
frame_queue_next(&is->sampq);
} while (af->serial != is->audioq.serial);
/* 计算这一帧数据的大小 */
data_size = av_samples_get_buffer_size(NULL, af->frame->channels,
af->frame->nb_samples,
af->frame->format, 1);
...
/* 是否需要重采样 */
/* 是否需要重采样 */
if (is->swr_ctx) {
...
}else {
/* 无需重采样则进行变量的赋值 */
is->audio_buf = af->frame->data[0];
resampled_data_size = data_size;
}
...
/* 返回值为当前帧的数据大小 */
return resampled_data_size;
}
整个aout的流程就分析完了。
五、总结:
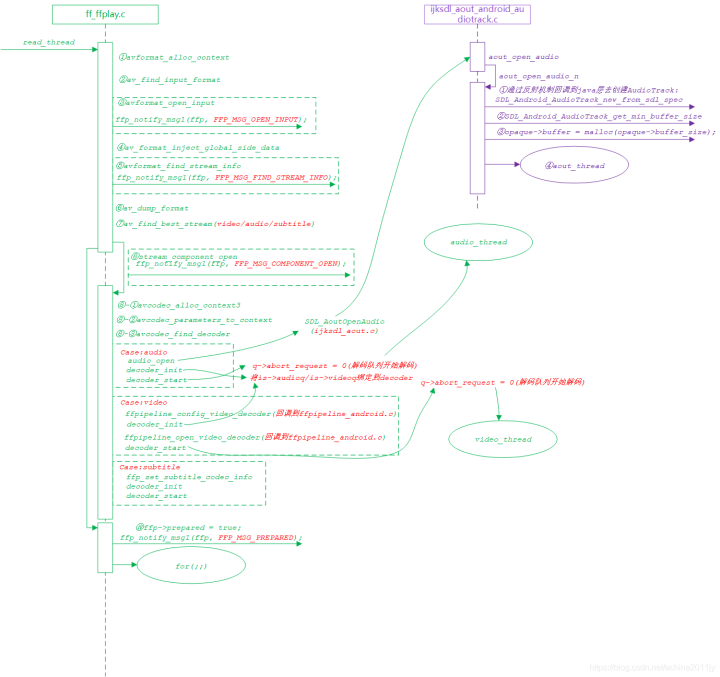
分析的内容有点多,建议结合逻辑图来加深理解:
如果你对音视频开发感兴趣,觉得文章对您有帮助,别忘了点赞、收藏哦!或者对本文的一些阐述有自己的看法,有任何问题,欢迎在下方评论区讨论!
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓