1、环境变量
1.1 环境变量是指在操作系级中用来指定操作系统运行的一些参数:换句话说,操作系统通过环境变量来找到运行时的些资源。
例如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
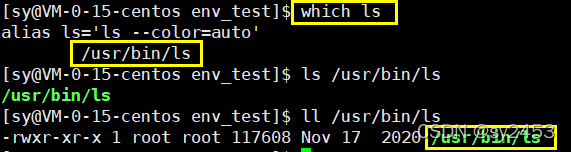
执行命令的时候,帮助用户找到该命令在哪一个位置,例如Is。
1.2 常见的一 些环境变量:
1.2.1 PATH:
指定可执行程序的搜索路径, 程序员执行的命令之所以能找到,这个环境变量起到的作用(汗马功劳)。
![]()

例如:当我们在命令行中输入ls的时候,就会通过环境变量PATH去查找当前操作系统当中是否有ls这个可执行程序的路径,依次往下去找,如果找到了就执行该程序,如果在所有路径下都没有找到,就会报错,command not find。
查找ls可执行程序的路径:which ls
1.2.2 HOME:
登录到linux操作系统的用户家目录。

1.2.3 SHELL:
当前的命令行解释器, 默认 是“/bin/ bash"。
![]()

1.3 查看环境变量方法
env
>1.系统当中的环境变量是有多个的;
>2.每个环境变量的组织方式都是 key(环境变量名称)=value(环境变量的值),一个环境变量可以拥有多个值,每个值之间都用“:”进行间隔。
echo $[环境变量名称]

unset: 清除环境变量
set: 显示本地定义的shell变量和环境变量
1.4、环境变量对应的文件
系统级文件:针对于各个用户都起作用(root用户修改),强烈不推荐修改系统级的环境变量文件,因为会影响其他用户。/etc/bashrc
用户级别环境变量文件:推荐大家修改这两个文件,只对自己用户的环境变量做出修改,影响自己
~/.bashrc
~/.bash profile
~/. bash_profile 包含~/. bashrc 包含/etc/bashrc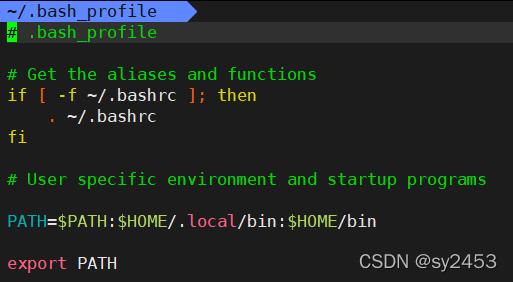
1.5.修改环境变量
命令范式: export 环境变量名称=[$环境变量名称]:[新添加的环境变量的内容]
命令行当中直接修改: (特点:临时生效)
如果是新增,可以不要[$环境变量名称],即export 环境变量名称=[新添加的环境变量的内容]

>1.在当前终端内生效,如果新打开终端,是找不到该环境变量的;>2.当前命令行中添加的环境变量,生命周期跟随当前终端,当前终端退出了,环境变量旧没有了。
如果是修改旧的:必须加上[$环境变量名称],否则之前的环境变量的值就找不到了.
不加$环境变量名称,结果如下:

加上之后:

文件当中修改:(特点:修改完毕之后,不会立即生效,需要配合source [环境变量文件名称],永久生效)
新增:在文件末尾直接添加: export环境变量名称= [新添加的环境变量的内容]
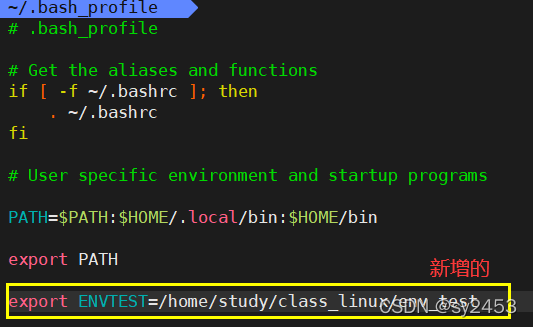

如果修改旧的:在老的后面添加":[新添加的环境变量的内容]"


echo $[变量] 表示打印变量中的内容
扩展: 如何让自己的程序,不需要加./直接使用程序名称就可以运行昵?
>1.把可执行程序放到/usr/bin下,需要用root用户(不推荐)。
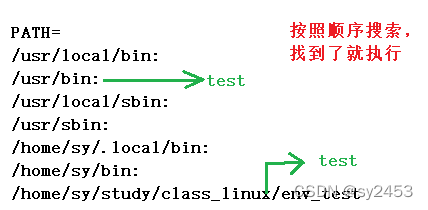
>2.设置环境变量,在PATH环境变量中增加可执行程序路径。
在PATH环境变量里找可执行程序的路径时,按照顺序从前往后找,找到了就执行,不会再往后搜索了。
1.6、环境变量的组织方式
环境变量是以字符指针数组的方式进行组织的,最后的元素以NULL结尾.(当程序拿到环境变量的时候,读取到NULL,就知道读取完毕了)(图解)

char* env[ ] :本质上是一个数组,数组的元素是char*,每个char*都指向一个环境变量(key=value)。
1.7、代码获取环境变量:
1.7.1. main函数的参数
main(int argc, char* argv[], char* env[])
#include <stdio.h>
/*通过main函数的参数获取环境变量
**/
int main(int argc,char* argv[],char* env[]){
for(int i=0;env[i]!=NULL;i++){
printf("%s\n",env[i]);
}
return 0;
}
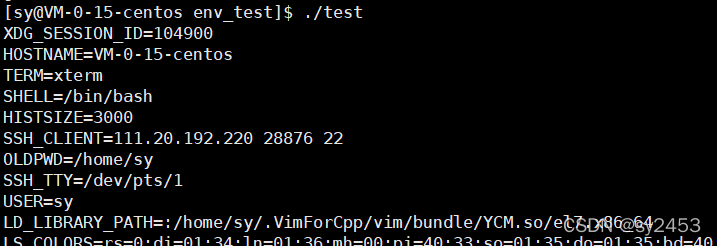
扩展的知识:命令行参数
自己写的程序也可以接收命令行参数,通过main函数的第一,第二个参数来接收。
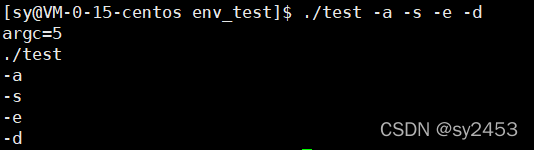
命令行参数的个数是计算程序本身的,例如:
![]()
其命令行参数个数为3;
#include <stdio.h>
int main(int argc,char* argv[],char* env[]){
printf("argc=%d\n",argc);//获取命令行参数个数
for(int i=0;i<argc;i++){
printf("%s\n",argv[i]);
}
return 0;
}
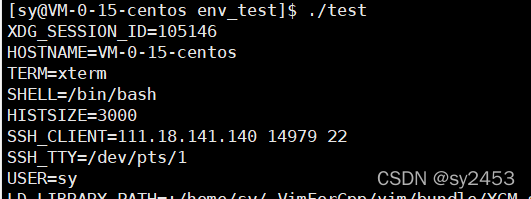
1.7.2. environ
extern char **environ; 这个是全局的外部变量,在libc.so当中定义,使用的时候, 需要用extren关键字
#include <stdio.h>
int main(){
extern char** environ;
for(int i=0;environ[i]!=NULL;i++){
printf("%s\n",environ[i]);
}
return 0;
}
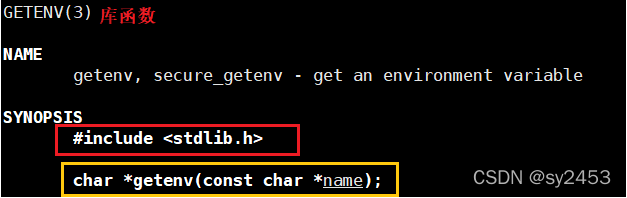
1.7.3. getenv
#include <stdlib. h>
char *getenv (const char *name)
参数:环境变量名称
返回值:环境变量的值,没找到返回NULL.
#include <stdio.h>
#include <stdlib.h>
int main(){
printf("PATH=%s\n",getenv("PATH"));
return 0;
}
![]()
2、程序地址空间
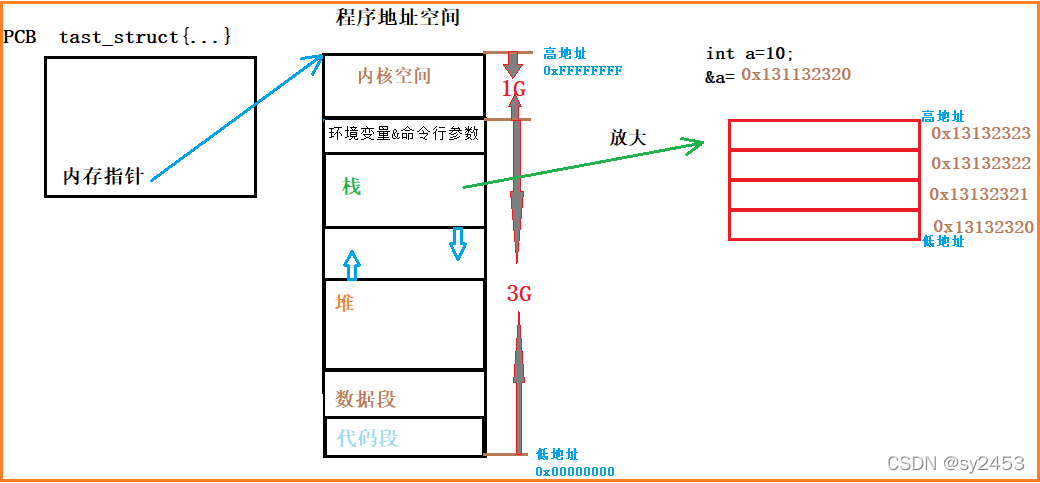
2.1C语言当中的程序地址空间(32位操作系统为例)
扩展:深刻理解,一个内存地址,对应一个字节:
inta = 10: a占用4字节,a其实拿到是第一个字节(低地址的字节),由于int是4字节,所以在访问的时候, 默认往后在访问3字节。
2.2
创建子进程之后,父子进程都打印全局变量的地址。(打印的地址是一样的)
#include <stdio.h>
#include <unistd.h>
int g_num=25;
int main(){
pid_t ret=fork();
if(ret<0){
return -1;
}
else if(ret == 0){
//子进程执行
printf("i am child,g_num=%d,&g_num=%p\n",g_num,&g_num);
}
else{
//父进程执行
printf("i am father,g_num=%d,&g_num=%p\n",g_num,&g_num);
}
return 0;
}

如果一个进程修改了全局变量的值,父子进程再分别打印地址,以及变量的值。(打印的地址还是一样的)。
#include <stdio.h>
#include <unistd.h>
int g_num=25;
int main(){
pid_t ret=fork();
if(ret<0){
return -1;
}
else if(ret == 0){
//子进程执行
g_num=100;
printf("i am child,g_num=%d,&g_num=%p\n",g_num,&g_num);
}
else{
//父进程执行
sleep(1);
printf("i am father,g_num=%d,&g_num=%p\n",g_num,&g_num);
}
return 0;
}
和之前的理解的矛盾点:变量内容不一样,所以父子进程输出的变量绝对不是同一个变量,但地址值是一样的,说明,该地址绝对不是物理地址,在Linux地址下,这种地址叫做虚拟地址。
2.3.虚拟地址
我们在用C/C+语言所看到的地址,全部都是虚拟地址! 物理地址,用户一概看不到, 由0S统一管理,OS负责将程序当中的虚拟地址,转化为物理地址。
2.4.进程虚拟地址空间
操作系统为每一个进程虚拟出来一个4G的虚拟地址空间(32位操作系统),程序在访问内存的时候,使用的是虚拟地址进行访问。既然是操作系统虚拟出来的地址,所以并不能直接存储数据, 存储数据还是在真实的物理内存当中。
所以OS需要将虚拟地址转化为物理地址进行访问(页表)
扩展:为什么操作系统需要给每一个进程都虚拟出来一个进程地址空间呢?为啥不直接让进程访问物理内存,这样不是更加快一点?
因为各个进程访问同一个物理地址空间,就会造成不可控。在有限的内存空间中,进程是不清楚哪一个内存被其他进程使用,那些内存是空闲的,没有办法知道。所以,这种场景下,冒昧的使用,一足会导致多个进程在访问物理内存的时候,出现混乱,所以,内存由操作系统统一管理起来,但是又不能采用预先直接分配内存的方式给进程。
因为OS也不清楚进程能使用多少内存,使用多久。所以,就虚拟给每一个进程分配L了4G的地址(虚拟地址),当进程真正要保存数据,或者申请内存的时候,操作虚拟地址,让操作系统再给进程进行分配。这样就比较合理(同时也会节省很多空间,毕竟谁用才分配真正的物理内存),每一个进程都无感的使用拿到的虚拟地址,背后就是OS进行了转换(就是后面说到的页表映射)。
为什么32位操作系统,给进程分配的是4G的虚拟地址空间?
因为32为操作系统总共有32根地址线,每个地址线能模拟的数字为0/1,所以,最小就是0x0000000,最大就是0xFFFFFFFF(64位同理)。
2.5页表
虚拟地址=页号+页内偏移 ;页号=虚拟地址/页的天小 ;页内偏移=虚拟地址%页的大小
分页式
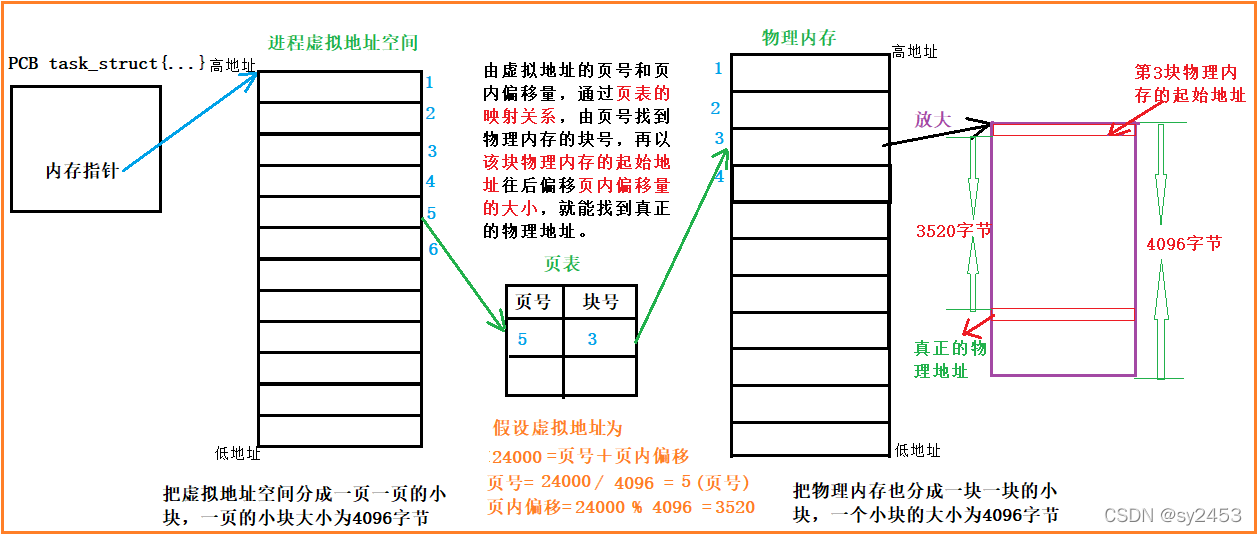
> fork创建子进程的时候,会不会拷贝页表?
答案是会,每个进程都有自己的页表,子进程最初的页表映射的内容就是来自于父进程,后面子进程在运行的时候,可能就会有不同的映射关系写到自己的页表当中。
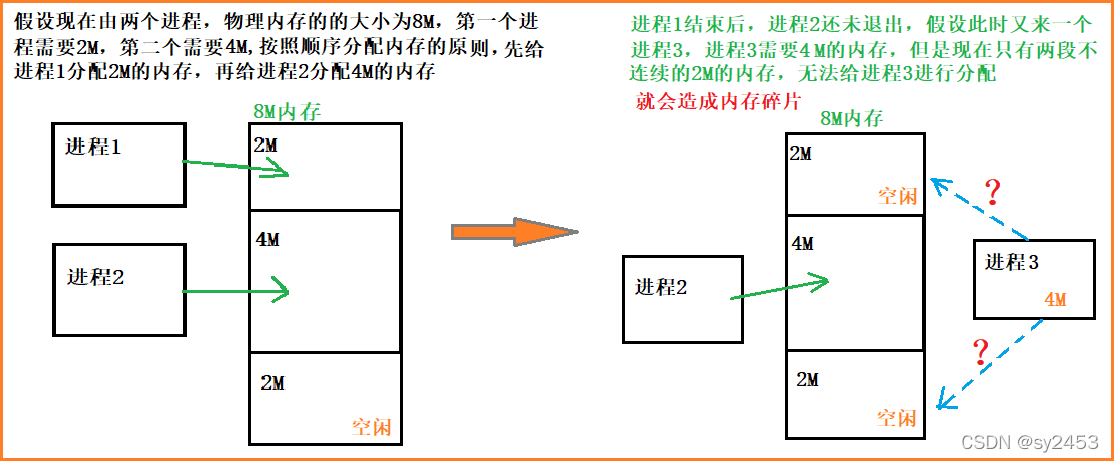
>为什么内存分配的时候,不采用连续分配的方式,而是一页一页离散分配的方式。防止内存碎片。
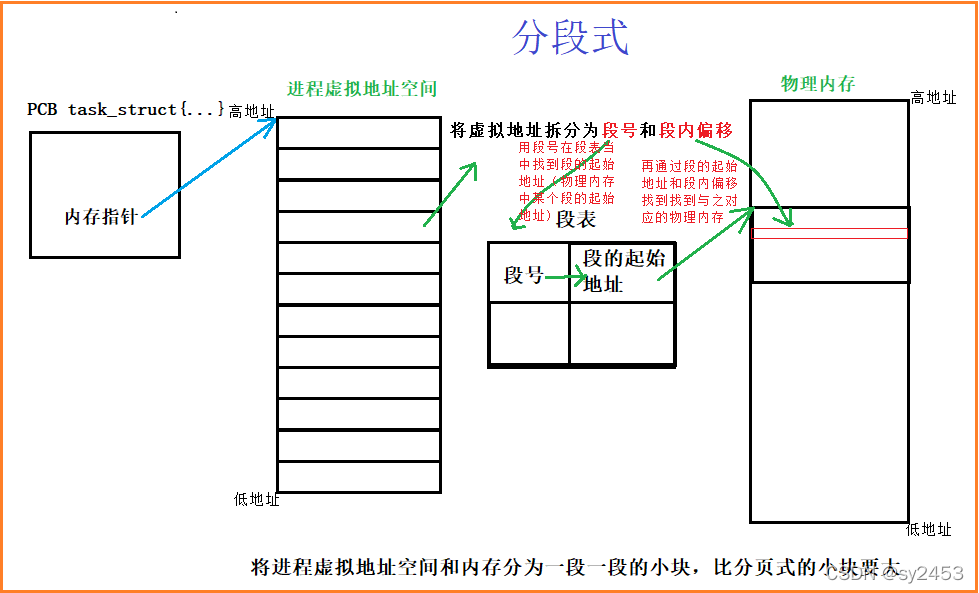
分段式
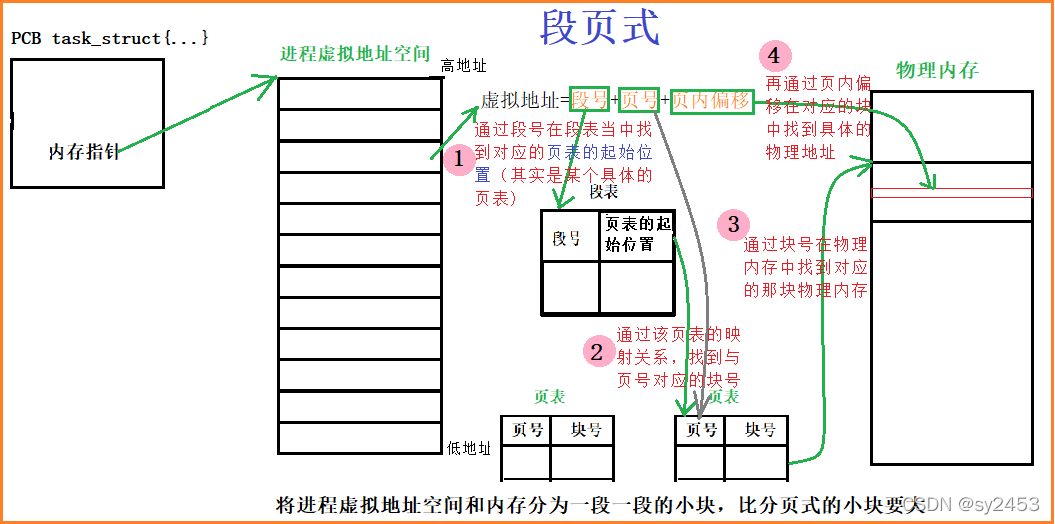
段页式
2.6、进程优先级
cpu资源分配的先后顺序,就是指进程的优先权(priority)。优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
top命令

UID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。
NI就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。
PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice,这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行所以,调整进程优先级,在Linux下,就是调整进程nice值nice其取值范围是-20至19,一共40个级别。优先级的解释权归操作系统所有。
用top命令更改已存在进程的nice:(需要root用户)
top
进入top后按“r”–>输入进程PID–>输入nice值