面试官:今天来聊聊JVM的内存结构吧?
候选者:嗯,好的
候选者:前几次面试的时候也提到了:class文件会被类加载器装载至JVM中,并且JVM会负责程序「运行时」的「内存管理」
候选者:而JVM的内存结构,往往指的就是JVM定义的「运行时数据区域」
候选者:简单来说就分为了5大块:方法区、堆、程序计数器、虚拟机栈、本地方法栈
候选者:要值得注意的是:这是JVM「规范」的分区概念,到具体的实现落地,不同的厂商实现可能是有所区别的。

面试官:嗯,顺便讲下你这图上每个区域的内容吧。
候选者:好的,那我就先从「程序计数器」开始讲起吧。
候选者:Java是多线程的语言,我们知道假设线程数大于CPU数,就很有可能有「线程切换」现象,切换意味着「中断」和「恢复」,那自然就需要有一块区域来保存「当前线程的执行信息」
候选者:所以,程序计数器就是用于记录各个线程执行的字节码的地址(分支、循环、跳转、异常、线程恢复等都依赖于计数器)
面试官:好的,理解了。
候选者:那接下来我就说下「虚拟机栈」吧
候选者:每个线程在创建的时候都会创建一个「虚拟机栈」,每次方法调用都会创建一个「栈帧」。每个「栈帧」会包含几块内容:局部变量表、操作数栈、动态连接和返回地址

候选者:了解了「虚拟机栈」的组成后,也不难猜出它的作用了:它保存方法了局部变量、部分变量的计算并参与了方法的调用和返回。
面试官:ok,了解了
候选者:下面就说下「本地方法栈」吧
候选者:本地方法栈跟虚拟机栈的功能类似,虚拟机栈用于管理 Java 函数的调用,而本地方法栈则用于管理本地方法的调用。这里的「本地方法」指的是「非Java方法」,一般本地方法是使用C语言实现的。
面试官:嗯…
候选者:嗯,说完了「本地方法栈」、「虚拟机栈」和「程序计数器」,哦,下面还有「方法区」和「堆」
候选者:那我先说「方法区」吧
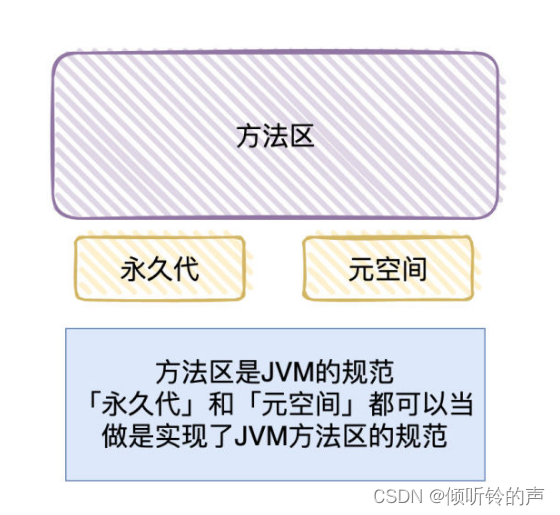
候选者:前面提到了运行时数据区这个「分区」是JVM的「规范」,具体的落地实现,不同的虚拟机厂商可能是不一样的
候选者:所以「方法区」也只是 JVM 中规范的一部分而已。
候选者:在HotSpot虚拟机,就会常常提到「永久代」这个词。HotSpot虚拟机在「JDK8前」用「永久代」实现了「方法区」,而很多其他厂商的虚拟机其实是没有「永久代」的概念的。
候选者:我们下面的内容就都用HotSpot虚拟机来说明好了。
候选者:在JDK8中,已经用「元空间」来替代了「永久代」作为「方法区」的实现了
面试官:嗯…
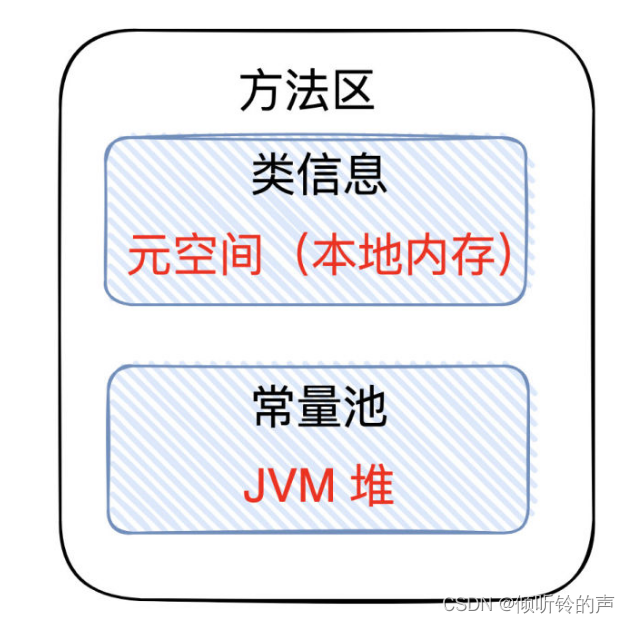
候选者:方法区主要是用来存放已被虚拟机加载的「类相关信息」:包括类信息、常量池
候选者:类信息又包括了类的版本、字段、方法、接口和父类等信息。
候选者:常量池又可以分「静态常量池」和「运行时常量池」
候选者:静态常量池主要存储的是「字面量」以及「符号引用」等信息,静态常量池也包括了我们说的「字符串常量池」。
候选者:「运行时常量池」存储的是「类加载」时生成的「直接引用」等信息。

面试官:嗯…
候选者:又值得注意的是:从「逻辑分区」的角度而言「常量池」是属于「方法区」的
候选者:但自从在「JDK7」以后,就已经把「运行时常量池」和「静态常量池」转移到了「堆」内存中进行存储(对于「物理分区」来说「运行时常量池」和「静态常量池』就属于堆)
面试官:嗯,这信息量有点多
面试官:我想问下,你说从「JDK8」已经把「方法区」的实现从「永久代」变成「元空间」,有什么区别?
候选者:最主要的区别就是:「元空间」存储不在虚拟机中,而是使用本地内存,JVM 不会再出现方法区的内存溢出,以往「永久代」经常因为内存不够用导致跑出OOM异常。
候选者:按JDK8版本,总结起来其实就相当于:「类信息」是存储在「元空间」的(也有人把「类信息」这块叫做「类信息常量池」,主要是叫法不同,意思到位就好)
候选者:而「常量池」用JDK7开始,从「物理存储」角度上就在「堆中」,这是没有变化的。
面试官:嗯,我听懂了
面试官:最后来讲讲「堆」这块区域吧
候选者:嗯,「堆」是线程共享的区域,几乎类的实例和数组分配的内存都来自于它
候选者:「堆」被划分为「新生代」和「老年代」,「新生代」又被进一步划分为 Eden 和 Survivor 区,最后 Survivor 由 From Survivor 和 To Survivor 组成
候选者:不多BB,我也画图吧

候选者:将「堆内存」分开了几块区域,主要跟「内存回收」有关(垃圾回收机制)
面试官:那垃圾回收这块等下次吧,这个延伸下去又很多东西了
面试官:你要不先讲讲JVM内存结构和Java内存模型有啥区别吧?
候选者:他们俩没有啥直接关联,其实两次面试过后,应该你就有感觉了
候选者:Java内存模型是跟「并发」相关的,它是为了屏蔽底层细节而提出的规范,希望在上层(Java层面上)在操作内存时在不同的平台上也有相同的效果
候选者:Java内存结构(又称为运行时数据区域),它描述着当我们的class文件加载至虚拟机后,各个分区的「逻辑结构」是如何的,每个分区承担着什么作用。
面试官:了解了
今日总结:JVM内存结构组成(JVM内存结构又称为「运行时数据区域」。主要有五部分组成:虚拟机栈、本地方法栈、程序计数器、方法区和堆。其中方法区和堆是线程共享的。虚拟机栈、本地方法栈以及程序计数器是线程隔离的)

不会有人刷到这还想白嫖吧?不会吧?点赞对真的我很重要!要不加个关注? @Java3y
面试官:我还记得上次你讲到JVM内存结构(运行时数据区域)提到了「堆」,然后你说是分了几块区域嘛
面试官:当时感觉再讲下去那我可能就得加班了
面试官:今天有点空了,继续聊聊「堆」那块吧
候选者:嗯,前面提到了堆分了「新生代」和「老年代」,「新生代」又分为「Eden」和「Survivor」区,「survivor」区又分为「From Survivor」和「To Survivor」区

候选者:说到这里,我就想聊聊Java的垃圾回收机制了
面试官:那你开始你的表演吧
候选者:我们使用Java的时候,会创建很多对象,但我们未曾「手动」将这些对象进行清除
候选者:而如果用C/C++语言的时候,用完是需要自己free(释放)掉的
候选者:那为什么在写Java的时候不用我们自己手动释放”垃圾”呢?原因很简单,JVM帮我们做了(自动回收垃圾)
面试官:嗯…
候选者:我个人对垃圾的定义:只要对象不再被使用了,那我们就认为该对象就是垃圾,对象所占用的空间就可以被回收

面试官:那是怎么判断对象不再被使用的呢?
候选者:常用的算法有两个「引用计数法」和「可达性分析法」
候选者:引用计数法思路很简单:当对象被引用则+1,但对象引用失败则-1。当计数器为0时,说明对象不再被引用,可以被可回收
候选者:引用计数法最明显的缺点就是:如果对象存在循环依赖,那就无法定位该对象是否应该被回收(A依赖B,B依赖A)
面试官:嗯…
候选者:另一种就是可达性分析法:它从「GC Roots」开始向下搜索,当对象到「GC Roots」都没有任何引用相连时,说明对象是不可用的,可以被回收

候选者:「GC Roots」是一组必须「活跃」的引用。从「GC Root」出发,程序通过直接引用或者间接引用,能够找到可能正在被使用的对象
面试官:还是不太懂,那「GC Roots」一般是什么?你说它是一组活跃的引用,能不能举个例子,太抽象了。
候选者:比如我们上次不是聊到JVM内存结构中的虚拟机栈吗,虚拟机栈里不是有栈帧吗,栈帧不是有局部变量吗?局部变量不就存储着引用嘛。
候选者:那如果栈帧位于虚拟机栈的栈顶,是不是就可以说明这个栈帧是活跃的(换言之,是线程正在被调用的)
候选者:既然是线程正在调用的,那栈帧里的指向「堆」的对象引用,是不是一定是「活跃」的引用?
候选者:所以,当前活跃的栈帧指向堆里的对象引用就可以是「GC Roots」
面试官:嗯…
候选者:当然了,能作为「GC Roots」也不单单只有上面那一小块
候选者:比如类的静态变量引用是「GC Roots」,被「Java本地方法」所引用的对象也是「GC Roots」等等…

候选者:回到理解的重点:「GC Roots」是一组必须「活跃」的「引用」,只要跟「GC Roots」没有直接或者间接引用相连,那就是垃圾
候选者:JVM用的就是「可达性分析算法」来判断对象是否垃圾
面试官:懂了
候选者:垃圾回收的第一步就是「标记」,标记哪些没有被「GC Roots」引用的对象

候选者:标记完之后,我们就可以选择直接「清除」,只要不被「GC Roots」关联的,都可以干掉
候选者:过程非常简单粗暴,但也存在很明显的问题
候选者:直接清除会有「内存碎片」的问题:可能我有10M的空余内存,但程序申请9M内存空间却申请不下来(10M的内存空间是垃圾清除后的,不连续的)

候选者:那解决「内存碎片」的问题也比较简单粗暴,「标记」完,不直接「清除」。
候选者:我把「标记」存活的对象「复制」到另一块空间,复制完了之后,直接把原有的整块空间给干掉!这样就没有内存碎片的问题了
候选者:这种做法缺点又很明显:内存利用率低,得有一块新的区域给我复制(移动)过去
面试官:嗯…
候选者:还有一种「折中」的办法,我未必要有一块「大的完整空间」才能解决内存碎片的问题,我只要能在「当前区域」内进行移动
候选者:把存活的对象移到一边,把垃圾移到一边,那再将垃圾一起删除掉,不就没有内存碎片了嘛
候选者:这种专业的术语就叫做「整理」

候选者:扯了这么久,我们把思维再次回到「堆」中吧
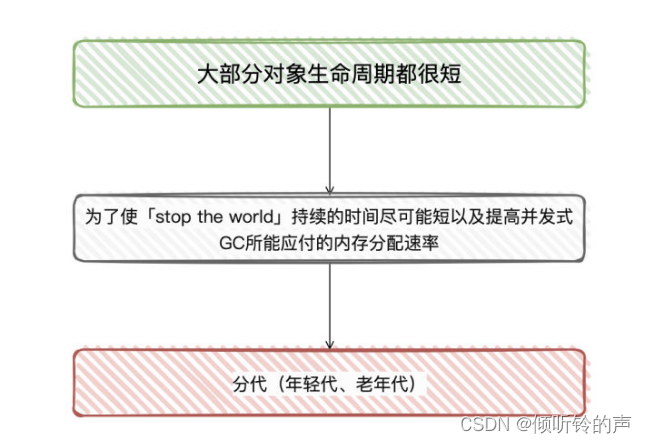
候选者:经过研究表明:大部分对象的生命周期都很短,而只有少部分对象可能会存活很长时间
候选者:又由于「垃圾回收」是会导致「stop the world」(应用停止访问)
候选者:理解「stop the world」应该很简单吧:回收垃圾的时候,程序是有短暂的时间不能正常继续运作啊。不然JVM在回收的时候,用户线程还继续分配修改引用,JVM怎么搞(:
候选者:为了使「stop the world」持续的时间尽可能短以及提高并发式GC所能应付的内存分配速率
候选者:在很多的垃圾收集器上都会在「物理」或者「逻辑」上,把这两类对象进行区分,死得快的对象所占的区域叫做「年轻代」,活得久的对象所占的区域叫做「老年代」
候选者:但也不是所有的「垃圾收集器」都会有,只不过我们现在线上用的可能都是JDK8,JDK8及以下所使用到的垃圾收集器都是有「分代」概念的。
候选者:所以,你可以看到我的「堆」是画了「年轻代」和「老年代」
候选者:要值得注意的是,高版本所使用的垃圾收集器的ZGC是没有分代的概念的(:
候选者:只不过我为了好说明现状,ZGC的话有空我们再聊
面试官:嗯…好吧
候选者:在前面更前面提到了垃圾回收的过程,其实就对应着几种「垃圾回收算法」,分别是:
候选者:标记清除算法、标记复制算法和标记整理算法【「标记」「清除」「复制」「整理」】
候选者:经过上面的铺垫之后,这几种算法应该还是比较好理解的

候选者:「分代」和「垃圾回收算法」都搞明白了之后,我们就可以看下在JDK8生产环境及以下常见的垃圾回收器了
候选者:「年轻代」的垃圾收集器有:Seria、Parallel Scavenge、ParNew
候选者:「老年代」的垃圾收集器有:Serial Old、Parallel Old、CMS
候选者:看着垃圾收集器有很多,其实还是非常好理解的。Serial是单线程的,Parallel是多线程
候选者:这些垃圾收集器实际上就是「实现了」垃圾回收算法(标记复制、标记整理以及标记清除算法)
候选者:CMS是「JDK8之前」是比较新的垃圾收集器,它的特点是能够尽可能减少「stop the world」时间。在垃圾回收时让用户线程和 GC 线程能够并发执行!

候选者:又可以发现的是,「年轻代」的垃圾收集器使用的都是「标记复制算法」
候选者:所以在「堆内存」划分中,将年轻代划分出Survivor区(Survivor From 和Survivor To),目的就是为了有一块完整的内存空间供垃圾回收器进行拷贝(移动)
候选者:而新的对象则放入Eden区
候选者:我下面重新画下「堆内存」的图,因为它们的大小是有默认的比例的

候选者:图我已经画好了,应该就不用我再说明了
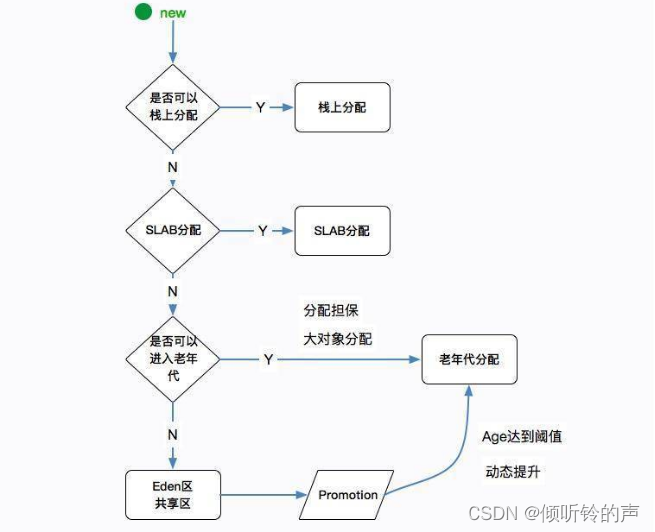
面试官:我还想问问,就是,新创建的对象一般是在「新生代」嘛,那在什么时候会到「老年代」中呢?
候选者:嗯,我认为简单可以分为两种情况:
候选者:1. 如果对象太大了,就会直接进入老年代(对象创建时就很大 || Survivor区没办法存下该对象)
候选者:2. 如果对象太老了,那就会晋升至老年代(每发生一次Minor GC ,存活的对象年龄+1,达到默认值15则晋升老年代 || 动态对象年龄判定 可以进入老年代)
面试官:既然你又提到了Minor GC,那Minor GC 什么时候会触发呢?
候选者:当Eden区空间不足时,就会触发Minor GC
面试官:Minor GC 在我的理解就是「年轻代」的GC,你前面又提到了「GC Roots」嘛
面试官:那在「年轻代」GC的时候,从GC Roots出发,那不也会扫描到「老年代」的对象吗?那那那..不就相当于全堆扫描吗?
候选者:这JVM里也有解决办法的。
候选者:HotSpot 虚拟机「老的GC」(G1以下)是要求整个GC堆在连续的地址空间上。
候选者:所以会有一条分界线(一侧是老年代,另一侧是年轻代),所以可以通过「地址」就可以判断对象在哪个分代上
候选者:当做Minor GC的时候,从GC Roots出发,如果发现「老年代」的对象,那就不往下走了(Minor GC对老年代的区域毫无兴趣)

面试官:但又有个问题,那如果「年轻代」的对象被「老年代」引用了呢?(老年代对象持有年轻代对象的引用),那时候肯定是不能回收掉「年轻代」的对象的。
候选者:HotSpot虚拟机下 有「card table」(卡表)来避免全局扫描「老年代」对象
候选者:「堆内存」的每一小块区域形成「卡页」,卡表实际上就是卡页的集合。当判断一个卡页中有存在对象的跨代引用时,将这个页标记为「脏页」
候选者:那知道了「卡表」之后,就很好办了。每次Minor GC 的时候只需要去「卡表」找到「脏页」,找到后加入至GC Root,而不用去遍历整个「老年代」的对象了。

面试官:嗯嗯嗯,还可以的啊,要不继续聊聊CMS?
候选者:这面试快一个小时了吧,我图也画了这么多了。下次?下次吧?有点儿累了
本文总结:
- 什么是垃圾:只要对象不再被使用,那即是垃圾
- 如何判断为垃圾:可达性分析算法和引用计算算法,JVM使用的是可达性分析算法
- 什么是GC Roots:GC Roots是一组必须活跃的引用,跟GC Roots无关联的引用即是垃圾,可被回收
- 常见的垃圾回收算法:标记清除、标记复制、标记整理
- 为什么需要分代:大部分对象都死得早,只有少部分对象会存活很长时间。在堆内存上都会在物理或逻辑上进行分代,为了使「stop the world」持续的时间尽可能短以及提高并发式GC所能应付的内存分配速率。
- Minor GC:当Eden区满了则触发,从GC Roots往下遍历,年轻代GC不关心老年代对象
- 什么是card table【卡表】:空间换时间(类似bitmap),能够避免扫描老年代的所有对应进而顺利进行Minor GC (案例:老年代对象持有年轻代对象引用)
- 堆内存占比:年轻代占堆内存1/3,老年代占堆内存2/3。Eden区占年轻代8/10,Survivor区占年轻代2/10(其中From 和To 各站1/10)

面试官:今天还是来聊聊CMS垃圾收集器呗?
候选者:嗯啊…
候选者:如果用Seria和Parallel系列的垃圾收集器:在垃圾回收的时,用户线程都会完全停止,直至垃圾回收结束!
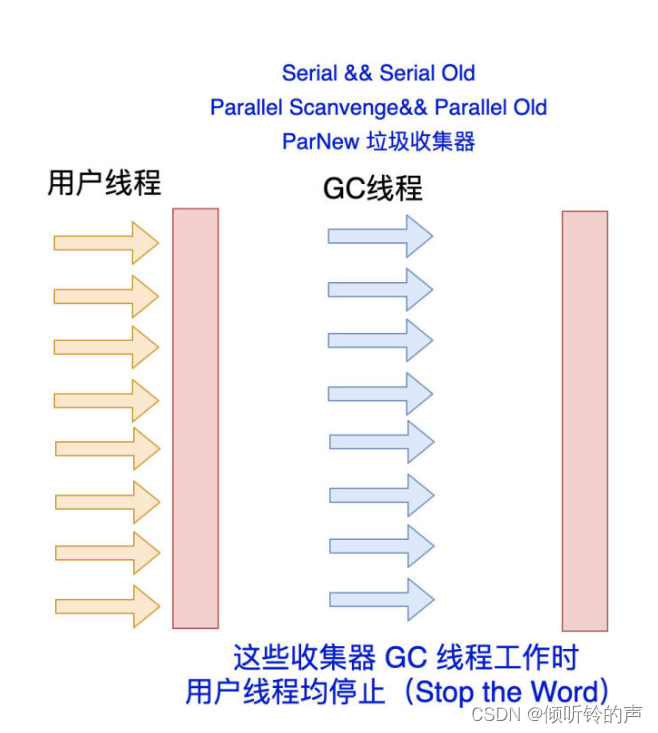
候选者:CMS的全称:Concurrent Mark Sweep,翻译过来是「并发标记清除」
候选者:用CMS对比上面的垃圾收集器(Seria和Parallel和parNew):它最大的不同点就是「并发」:在GC线程工作的时候,用户线程「不会完全停止」,用户线程在「部分场景下」与GC线程一起并发执行。
候选者:但是,要理解的是,无论是什么垃圾收集器,Stop The World是一定无法避免的!
候选者:CMS只是在「部分」的GC场景下可以让GC线程与用户线程并发执行
候选者:CMS的设计目标是为了避免「老年代 GC」出现「长时间」的卡顿(Stop The World)

面试官:那你清楚CMS的工作流程吗?
候选者:只了解一点点,不能多了。
候选者:CMS可以简单分为5个步骤:初始标记、并发标记、并发预清理、重新标记以及并发清除
候选者:从步骤就不难看出,CMS主要是实现了「标记清除」垃圾回收算法
面试官:嗯…是的
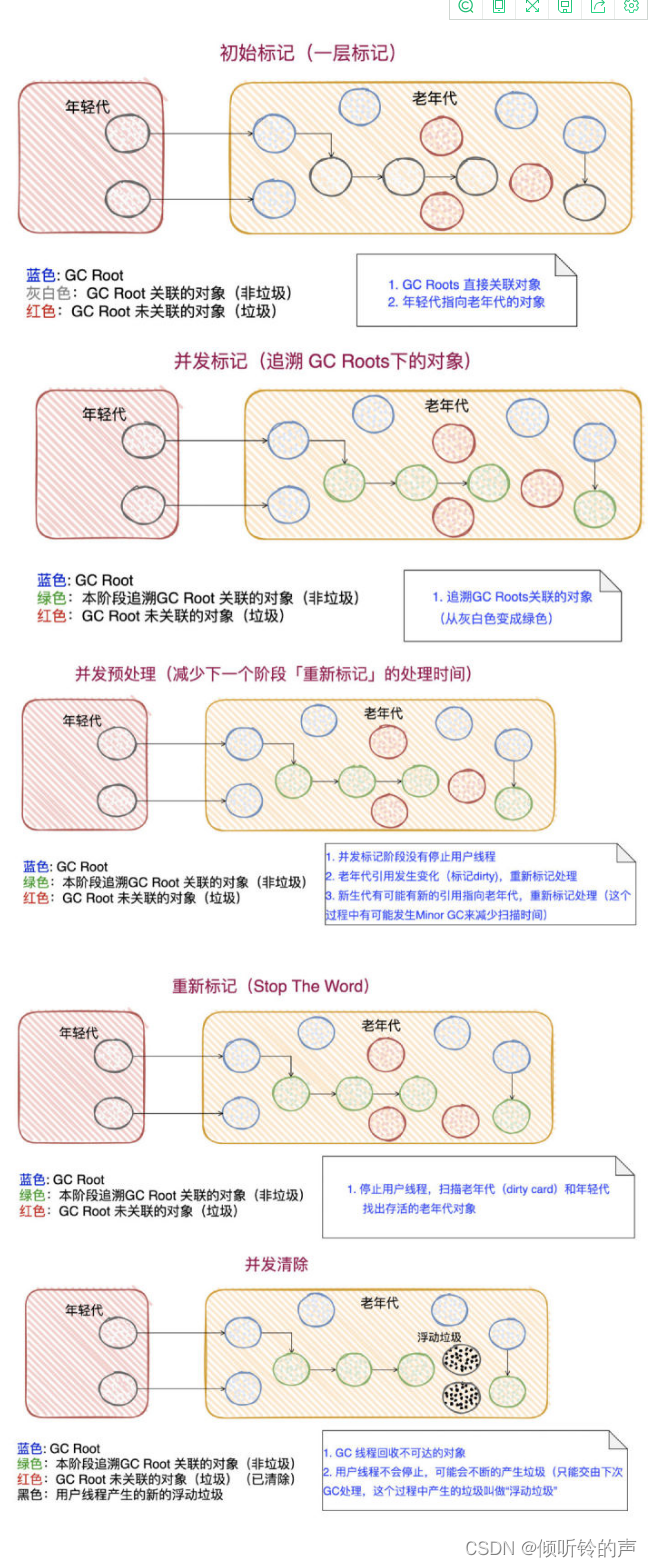
候选者:我就从「初始标记」来开始吧
候选者:「初始标记」会标记GCRoots「直接关联」的对象以及「年轻代」指向「老年代」的对象
候选者:「初始标记」这个过程是会发生Stop The World的。但这个阶段的速度算是很快的,因为没有「向下追溯」(只标记一层)

候选者:在「初始标记」完了之后,就进入了「并发标记」阶段啦
候选者:「并发标记」这个过程是不会停止用户线程的(不会发生 Stop The World)。这一阶段主要是从GC Roots向下「追溯」,标记所有可达的对象。
候选者:「并发标记」在GC的角度而言,是比较耗费时间的(需要追溯)
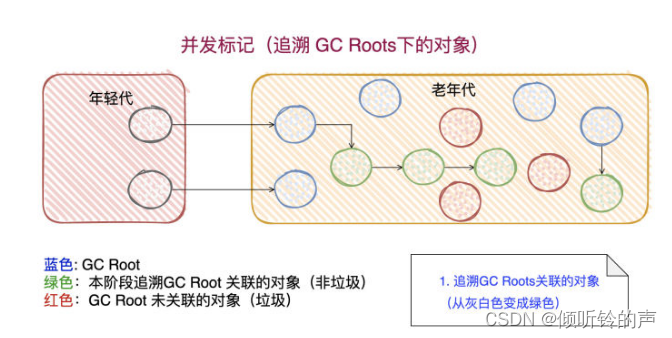
候选者:「并发标记」这个阶段完成之后,就到了「并发预处理」阶段啦
候选者:「并发预处理」这个阶段主要想干的事情:希望能减少下一个阶段「重新标记」所消耗的时间
候选者:因为下一个阶段「重新标记」是需要Stop The World的
面试官:嗯…
候选者:「并发标记」这个阶段由于用户线程是没有被挂起的,所以对象是有可能发生变化的
候选者: 可能有些对象,从新生代晋升到了老年代。可能有些对象,直接分配到了老年代(大对象)。可能老年代或者新生代的对象引用发生了变化…
面试官:那这个问题,怎么解决呢?
候选者:针对老年代的对象,其实还是可以借助类card table的存储(将老年代对象发生变化所对应的卡页标记为dirty)
候选者:所以「并发预处理」这个阶段会扫描可能由于「并发标记」时导致老年代发生变化的对象,会再扫描一遍标记为dirty的卡页
面试官:嗯…
候选者:对于新生代的对象,我们还是得遍历新生代来看看在「并发标记」过程中有没有对象引用了老年代..
候选者:不过JVM里给我们提供了很多「参数」,有可能在这个过程中会触发一次 minor GC(触发了minor GC 是意味着就可以更少地遍历新生代的对象)

候选者:「并发预处理」这个阶段阶段结束后,就到了「重新标记」阶段
候选者:「重新标记」阶段会Stop The World,这个过程的停顿时间其实很大程度上取决于上面「并发预处理」阶段(可以发现,这是一个追赶的过程:一边在标记存活对象,一边用户线程在执行产生垃圾)

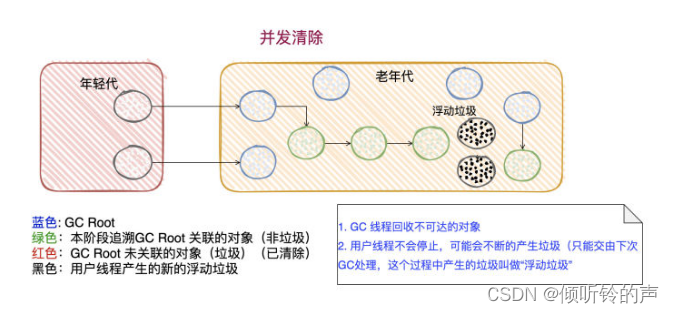
候选者:最后就是「并发清除」阶段,不会Stop The World
候选者:一边用户线程在执行,一边GC线程在回收不可达的对象
候选者:这个过程,还是有可能用户线程在不断产生垃圾,但只能留到下一次GC 进行处理了,产生的这些垃圾被叫做“浮动垃圾”
候选者:完了以后会重置 CMS 算法相关的内部数据,为下一次 GC 循环做准备
面试官:嗯,CMS的回收过程,我了解了
面试官:听下来,其实就是把垃圾回收的过程给”细分”了,然后在某些阶段可以不停止用户线程,一边回收垃圾,一边处理请求,来减少每次垃圾回收时 Stop The World的时间
面试官:当然啦,中间也做了很多的优化(dirty card标记、可能中途触发minor gc等等,在我理解下,这些应该都提供了CMS的相关参数配置)
面试官:不过,我看现在很多企业都在用G1了,那你觉得CMS有什么缺点呢?
候选者:1.空间需要预留:CMS垃圾收集器可以一边回收垃圾,一边处理用户线程,那需要在这个过程中保证有充足的内存空间供用户使用。
候选者:如果CMS运行过程中预留的空间不够用了,会报错(Concurrent Mode Failure),这时会启动 Serial Old垃圾收集器进行老年代的垃圾回收,会导致停顿的时间很长。
候选者:显然啦,空间预留多少,肯定是有参数配置的
候选者:2. 内存碎片问题:CMS本质上是实现了「标记清除算法」的收集器(从过程就可以看得出),这会意味着会产生内存碎片
候选者:由于碎片太多,又可能会导致内存空间不足所触发full GC,CMS一般会在触发full GC这个过程对碎片进行整理
候选者:整理涉及到「移动」/「标记」,那这个过程肯定会Stop The World的,如果内存足够大(意味着可能装载的对象足够多),那这个过程卡顿也是需要一定的时间的。
面试官:嗯…

候选者:使用CMS的弊端好像就是一个死循环:
候选者:1. 内存碎片过多,导致空间利用率减低。
候选者:2. 空间本身就需要预留给用户线程使用,现在碎片内存又加剧了空间的问题,导致有可能垃圾收集器降级为Serial Old,卡顿时间更长。
候选者:3. 要处理内存碎片的问题(整理),同样会卡顿
候选者:不过,技术实现就是一种trade-off(权衡),不可能你把所有的事情都做得很完美
候选者:了解这个过程,是非常有趣的
面试官:那G1垃圾收集器你了解吗
候选者:只了解一点点,不能多了
候选者:不过,留到下次吧,先让你消化下,不然怕你顶不住了。
本文总结:
- CMS垃圾回收器设计目的:为了避免「老年代 GC」出现「长时间」的卡顿(Stop The World)
- CMS垃圾回收器回收过程:初始标记、并发标记、并发预处理、重新标记和并发清除。初始标记以及重新标记这两个阶段会Stop The World
- CMS垃圾回收器的弊端:会产生内存碎片&&需要空间预留:停顿时间是不可预知的

面试官:要不这次来聊聊G1垃圾收集器?
候选者:嗯嗯,好的呀
候选者:上次我记得说过,CMS垃圾收集器的弊端:会产生内存碎片&&空间需要预留
候选者:这俩个问题在处理的时候,很有可能会导致停顿时间过长,说白了就是CMS的停顿时间是「不可预知的」
候选者:而G1又可以理解为在CMS垃圾收集器上进行”升级”
候选者:G1 垃圾收集器可以给你设定一个你希望Stop The Word 停顿时间,G1垃圾收集器会根据这个时间尽量满足你
候选者:在前面我在介绍JVM堆的时候,是画了一张图的。堆的内存分布是以「物理」空间进行隔离

候选者:在G1垃圾收集器的世界上,堆的划分不再是「物理」形式,而是以「逻辑」的形式进行划分
候选者:不过,像之前说过的「分代」概念在G1垃圾收集器的世界还是一样奏效的
候选者:比如说:新对象一般会分配到Eden区、经过默认15次的Minor GC新生代的对象如果还存活,会移交到老年代等等…
候选者:我来画下G1垃圾收集器世界的「堆」空间分布吧

候选者:从图上就可以发现,堆被划分了多个同等份的区域,在G1里每个区域叫做Region
候选者:老年代、新生代、Survivor这些应该就不用我多说了吧?规则是跟CMS一样的
候选者:G1中,还有一种叫 Humongous(大对象)区域,其实就是用来存储特别大的对象(大于Region内存的一半)
候选者:一旦发现没有引用指向大对象,就可直接在年轻代的Minor GC中被回收掉
面试官:嗯…
候选者:其实稍微想一下,也能理解为什么要将「堆空间」进行「细分」多个小的区域
候选者:像以前的垃圾收集器都是对堆进行「物理」划分
候选者:如果堆空间(内存)大的时候,每次进行「垃圾回收」都需要对一整块大的区域进行回收,那收集的时间是不好控制的
候选者:而划分多个小区域之后,那对这些「小区域」回收就容易控制它的「收集时间」了

面试官:嗯…
面试官:那我大概了解了。那要不你讲讲它的GC过程呗?
候选者:嗯,在G1收集器中,可以主要分为有Minor GC(Young GC)和Mixed GC,也有些特殊场景可能会发生Full GC
候选者:那我就直接说Minor GC先咯?
面试官:嗯,开始吧
候选者:G1的Minor GC其实触发时机跟前面提到过的垃圾收集器都是一样的
候选者:等到Eden区满了之后,会触发Minor GC。Minor GC同样也是会发生Stop The World的
候选者:要补充说明的是:在G1的世界里,新生代和老年代所占堆的空间是没那么固定的(会动态根据「最大停顿时间」进行调整)
候选者:这块要知道会给我们提供参数进行配置就好了
候选者:所以,动态地改变年轻代Region的个数可以「控制」Minor GC的开销

面试官:嗯,那Minor GC它的回收过程呢?可以稍微详细补充一下吗
候选者:Minor GC我认为可以简单分为为三个步骤:根扫描、更新&&处理 RSet、复制对象
候选者:第一步应该很好理解,因为这跟之前CMS是类似的,可以理解为初始标记的过程
候选者:第二步涉及到「Rset」的概念
面试官:嗯…
候选者:从上一次我们聊CMS回收过程的时候,同样讲到了Minor GC,它是通过「卡表」(cart table)来避免全表扫描老年代的对象
候选者:因为Minor GC 是回收年轻代的对象,但如果老年代有对象引用着年轻代,那这些被老年代引用的对象也不能回收掉
候选者:同样的,在G1也有这种问题(毕竟是Minor GC)。CMS是卡表,而G1解决「跨代引用」的问题的存储一般叫做RSet
候选者:只要记住,RSet这种存储在每个Region都会有,它记录着「其他Region引用了当前Region的对象关系」
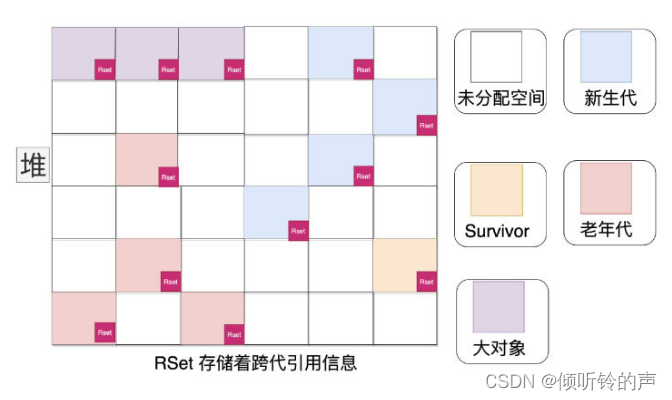
候选者:对于年轻代的Region,它的RSet 只保存了来自老年代的引用(因为年轻代的没必要存储啊,自己都要做Minor GC了)
候选者:而对于老年代的 Region 来说,它的 RSet 也只会保存老年代对它的引用(在G1垃圾收集器,老年代回收之前,都会先对年轻代进行回收,所以没必要保存年轻代的引用)
面试官:嗯…
候选者:那第二步看完RSet的概念,应该也好理解了吧?
候选者:无非就是处理RSet的信息并且扫描,将老年代对象持有年轻代对象的相关引用都加入到GC Roots下,避免被回收掉
候选者:到了第三步也挺好理解的:把扫描之后存活的对象往「空的Survivor区」或者「老年代」存放,其他的Eden区进行清除

候选者:这里要提下的是,在G1还有另一个名词,叫做CSet。
候选者:它的全称是 Collection Set,保存了一次GC中「将执行垃圾回收」的Region。CSet中的所有存活对象都会被转移到别的可用Region上
候选者:在Minor GC 的最后,会处理下软引用、弱引用、JNI Weak等引用,结束收集

面试官:嗯,了解了,不难
面试官:我记得你前面提到了Mixed GC ,要不来聊下这个过程呗?
候选者:好,没问题的。
候选者:当堆空间的占用率达到一定阈值后会触发Mixed GC(默认45%,由参数决定)
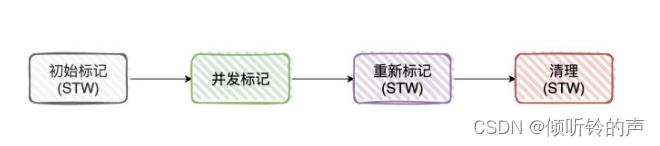
候选者:Mixed GC 依赖「全局并发标记」统计后的Region数据
候选者:「全局并发标记」它的过程跟CMS非常类型,步骤大概是:初始标记(STW)、并发标记、最终标记(STW)以及清理(STW)
面试官:确实很像啊,你继续来聊聊具体的过程呗?
候选者:嗯嗯,还是想说明下:Mixed GC它一定会回收年轻代,并会采集部分老年代的Region进行回收的,所以它是一个“混合”GC。
候选者:首先是「初始标记」,这个过程是「共用」了Minor GC的 Stop The World(Mixed GC 一定会发生 Minor GC),复用了「扫描GC Roots」的操作。
候选者:在这个过程中,老年代和新生代都会扫
候选者:总的来说,「初始标记」这个过程还是比较快的,毕竟没有追溯遍历嘛
面试官:…
候选者:接下来就到了「并发标记」,这个阶段不会Stop The World
候选者:GC线程与用户线程一起执行,GC线程负责收集各个 Region 的存活对象信息
候选者:从GC Roots往下追溯,查找整个堆存活的对象,比较耗时
面试官:嗯…
候选者:接下来就到「重新标记」阶段,跟CMS又一样,标记那些在「并发标记」阶段发生变化的对象
候选者:是不是很简单?
面试官:且慢
面试官:CMS在「重新标记」阶段,应该会重新扫描所有的线程栈和整个年轻代作为root
面试官:据我了解,G1好像不是这样的,这块你了解吗?
候选者:嗯,G1 确实不是这样的,在G1中解决「并发标记」阶段导致引用变更的问题,使用的是SATB算法
候选者:可以简单理解为:在GC 开始的时候,它为存活的对象做了一次「快照」
候选者:在「并发阶段」时,把每一次发生引用关系变化时旧的引用值给记下来
候选者:然后在「重新标记」阶段只扫描着块「发生过变化」的引用,看有没有对象还是存活的,加入到「GC Roots」上

候选者:不过SATB算法有个小的问题,就是:如果在开始时,G1就认为它是活的,那就在此次GC中不会对它回收,即便可能在「并发阶段」上对象已经变为了垃圾。
候选者:所以,G1也有可能会存在「浮动垃圾」的问题
候选者:但是总的来说,对于G1而言,问题不大(毕竟它不是追求一次把所有的垃圾都清除掉,而是注重 Stop The World时间)
面试官:嗯…
候选者:最后一个阶段就是「清理」,这个阶段也是会Stop The World的,主要清点和重置标记状态
候选者:会根据「停顿预测模型」(其实就是设定的停顿时间),来决定本次GC回收多少Region
候选者:一般来说,Mixed GC会选定所有的年轻代Region,部分「回收价值高」的老年代Region(回收价值高其实就是垃圾多)进行采集
候选者:最后Mixed GC 进行清除还是通过「拷贝」的方式去干的
候选者:所以,一次回收未必是将所有的垃圾进行回收的,G1会依据停顿时间做出选择Region数量(:

面试官:嗯,过程我大致是了解了
面试官:那G1会什么时候发生full GC?
候选者:如果在Mixed GC中无法跟上用户线程分配内存的速度,导致老年代填满无法继续进行Mixed GC,就又会降级到serial old GC来收集整个GC heap
候选者:不过这个场景相较于CMS还是很少的,毕竟G1没有CMS内存碎片这种问题(:
本文总结(G1垃圾收集器特点):
- 从原来的「物理」分代,变成现在的「逻辑」分代,将堆内存「逻辑」划分为多个Region
- 使用CSet来存储可回收Region的集合
- 使用RSet来处理跨代引用的问题(注意:RSet不保留 年轻代相关的引用关系)
- G1可简单分为:Minor GC 和Mixed GC以及Full GC
- 【Eden区满则触发】Minor GC 回收过程可简单分为:(STW) 扫描 GC Roots、更新&&处理Rset、复制清除
- 【整堆空间占一定比例则触发】Mixed GC 依赖「全局并发标记」,得到CSet(可回收Region),就进行「复制清除」
- R大描述G1原理的时候,从宏观的角度看G1其实就是「全局并发标记」和「拷贝存活对象」
- 使用SATB算法来处理「并发标记」阶段对象引用可能会修改的问题
- 提供可停顿时间参数供用户设置(G1会尽量满足该停顿时间来调整 GC时回收Region的数量)

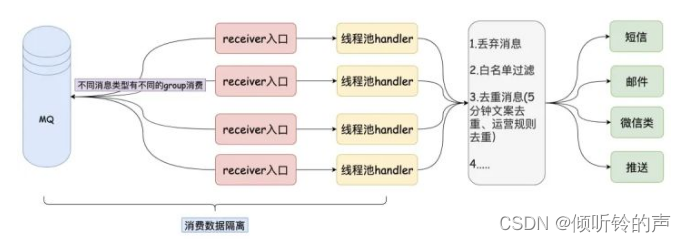
【Java开源】消息推送平台
我推荐一个拥有从零开始的文档的项目,既能用于毕设又可以在面试的时候大放异彩。
该项目业务极容易理解,代码结构还算是比较清晰,最可怕的是几乎每个方法和每个类都带有中文注释
拥有非常全的文档,作者从零搭建的过程一一都有记录,项目使用了蛮多的可靠和稳定的中间件的,包括并不限于SpringBoot、SpringDataJPA、MySQL、Docker、docker-compose、Kafka、Redis、Apollo、prometheus、Grafana、GrayLog、xxl-job等等。在使用每一个技术栈之前都讲述了为什么要使用,以及它的业务背景。我看过,他所说的场景是完全贴合线上环境的。
跟着README文档的部署使用姿势就能跑起来,一步一步debug挺有意思的,作者还搞了个前端后台管理系统就让整个系统变得更好理解了。并且在GitHub或者Gitee提的Issue几乎都会有回复,也非常乐于合并开发者们的pull request,会让人参与感贼强。
我相信在校、工作一年左右或常年做内网CRUD后台的同学去看看肯定会有所启发,作者会经常在群里回答该项目相关的问题和代码设计思路。
目前这个项目GitHub和Gitee加起来已经4K stars了,我相信破万是迟早的事情。 嗯,没错。这个项目叫做austin,是我写的
消息推送平台-Austin就是奔着真实互联网线上项目去设计和实现的,将项目克隆下来把中间件换成目前公司在用的,完善下基础建设它就能成为线上项目

austin项目核心功能:统一的接口发送各种类型消息,对消息生命周期全链路追踪
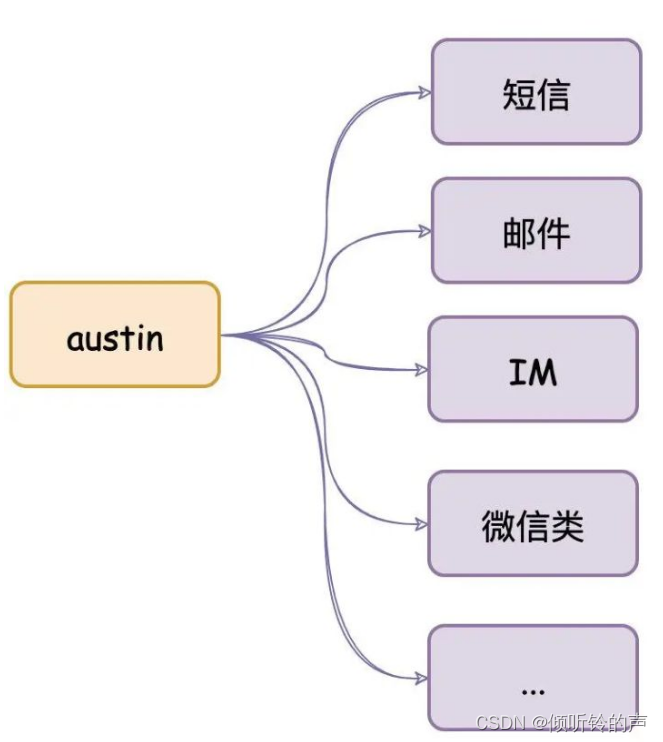
项目出现意义:只要公司内有发送消息的需求,都应该要有类似austin的项目,对各类消息进行统一发送处理。这有利于对功能的收拢,以及提高业务需求开发的效率
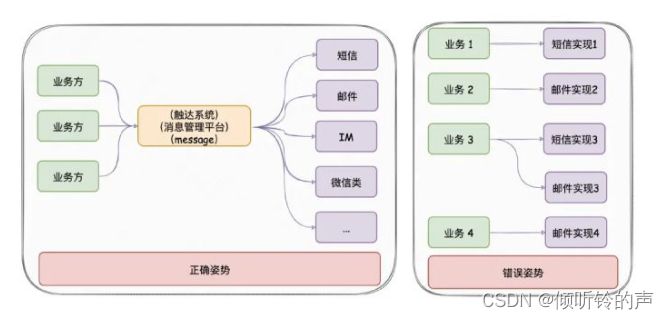
austin项目核心流程:austin-api接收到发送消息请求,直接将请求进MQ。austin-handler消费MQ消息后由各类消息的Handler进行发送处理