服务发布

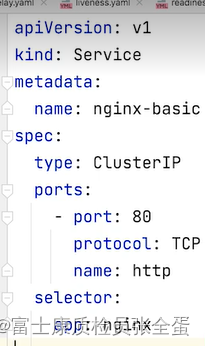
type是有多种类型的service(我有一堆pod运行在那里了,我要通过service对象来把这一组pod所提供的服务对外发布出来),这个service是cluster ip类型的,其次是端口,还有service提供什么协议的服务是tcp还是udp,服务要从哪个端口上面发布出去。
最后通过标签查询出一组pod,并且为这组pod提供服务,这个服务的端口在80上面,是TCP协议。
ClusterIp:为一组pod提供虚拟ip,是访问后端pod的统一的入口,端口就是定义的80端口,通过一定的技术配置负载均衡策略。
NodePort:就是在节点上面开一个端口,因为clusterip只能在集群内部访问,集群外部怎么访问呢?
集群外部可能能够访问到节点,能不能在节点上面开一个端口?这个端口上面接收到的所有请求,我也转到后端这组pod上面。
LoadBanlance:无论是公司自建的lb还是采购的,针对这些lb我可以去做service controller,比如你是openstack的话,它就会去调用openstack的lvs接口,去配置你的负载均衡,每家厂商都提供了自己servcie controller,就是你建立service的时候,它就去负载均衡帮你做负载均衡的配置,这就需要有各个厂商的service controller去配合,去配置外部的这种负载均衡设备,然后最后将状态写回回来。
所以这种类型的service要和外部的设备去做交互的,需要特定的controller去支持。
如果要去发布服务不可能将一组pod的IP发布出去,因为pod的ip会发生变化,每次pod重建ip就变了,所以pod的ip是不可靠的,怎么提供更加静态的访问入口呢?
这就是提供service,无论是给它的cluster ip也好,给它一个端口也好,还是负载均衡的ip也好,那么这些都是固定的,一旦固定下来就基本上不变。
要发布服务首先要将service发布出去。
很多时候是web应用,你发布到网上就是不安全的,所有的传输都是明文的,通常安全的网站都是需要去做加密的,安全的部分,通过七层的代理在外面去配置。
grpc协议,它是基于HTTP2的,本身是面向连接的协议,基于传统的tcp udp的数据包转发没有办法去做真正的负载均衡,一旦一个连接建立了,那么这个连接就永远保持,那么一个客户端的请求就会到同一个server端,它其实是没有真正的负载均衡的,这种高级的协议应用层的负载均衡怎么做,也是我们的挑战。
DNS需求与上下游服务关系等等。这些都是我们需要去考虑的问题。
服务的发布与挑战

基于dns我可以去发布服务,你可以将简单的将dns理解为基于域名的负载均衡,因为它的a记录可以有多条,你配置一个域名,这个域名可以映射到多个地址去,dns会去通过轮询的方式返回地址。
比如客户端不断查询的时候,比如说你有a b两个地址的时候,它就 ab ab这样返回给你,但是dns本身不是负载均衡器,它只是提供域名服务的,客户端在做域名查询的时候会去域名服务器会去问说这个域名的地址是什么,然后dns告诉你地址之后,同时告诉你一个ttl,说在多少秒之内,你不要再来问我了,这个东西就是可信的,通常来说客户端就会认这个ttl,比如60s之内,所有的数据包转发就直接连接ip和域名没有关系,域名服务器类似于电话黄页的这样一个册子,你查完了打电话就和它没有关系了,你客户端可能能够记住这个事情,你查了一次黄页,你已经知道这个映射关系了,你下次就不需要再问它了,你下次就直接打电话,但是很有可能后面这个电话出现问题了,域名服务器这边知道,但是客户端这边不知道,你还在往出了问题的ip地址上发数据,那么这样就会出现问题,这里面就是dns的ttl1问题。
客户端往往都会去缓存上一次查询的域名结果,即使后端服务器的ip地址发生了变化,你客户端缓存了,并且信任上司查询的结果,你也是不知道这个变化的,因为你不是每次的连接都会第二次查询一遍,这样会导致后端的服务器已经变了,但是你还在往错误的地址发数据包。
通常我们不会完全依赖dns去做域名的查询,通常域名后面指向的地址都是真实的静态物理地址。
servcie是由kube-proxy配置的,kube-proxy会去配置iptables和ipvs规则,iptables和ipvs本身会有规模的限制,service本身不支持grpc协议,service本身是通过系统内核去做的,基于四层的负载均衡配置,往往我们需要更多的接入需求,更加高级的需求需要ingress去承担的,但是ingress本身也有其问题。
跨地域部署

微服务架构下的高可用挑战
服务发现

A服务访问B服务的时候,那么我怎么知道B服务的真实地址呢?那么请求如何转到这些不同的后端呢?
后端有健康和不健康,它怎么及时的更新自己的状态呢?把自己从转发列表当中剔除呢?每一个后端的实例。
那每一个后端的实例它所接受的并发请求,或者正在处理的并发请求它是不一样的,如何确保我的请求是平均分配到哪个实例上面去的呢?
可能不同的实例在不同的地域,客户端怎么能够实现一个就近访问。
互联网架构发展进程
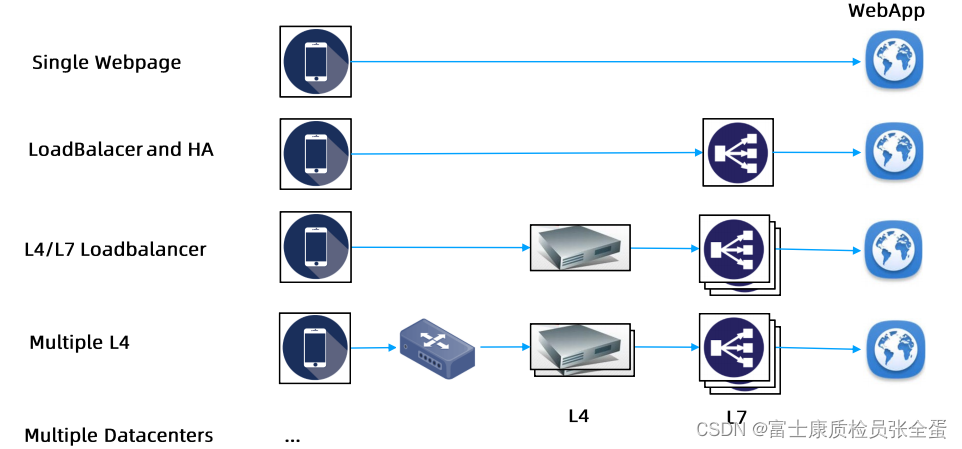
冗余部署,后面多几个实例,然后前面去创建负载均衡,这个负载均衡在其上面基础上提供虚拟ip,客户端访问的是负载均衡的虚拟ip,当请求过来了之后,它会按照负载均衡既定的策略,把这个请求转发到我的后端,只要有一台机器活着,那么请求就可以被接受,这样就极大的提升了我的可用性。
简单的负载均衡已经没有办法满足整个网站的流量了,前面想要加上硬件的负载均衡,前端加上四层的负载均衡,如果请求过来的话,将流量均分到不同的API网关上面去,每个API网关又基于不同的URL转到不同的微服务里面。(由单体架构到微服务,一个网站里面所支撑的这种应用实例很多,由前面统一的API网关接入,基于不同的URL转到不同的backend里面去,在此基础之上我再做四层的负载均衡)
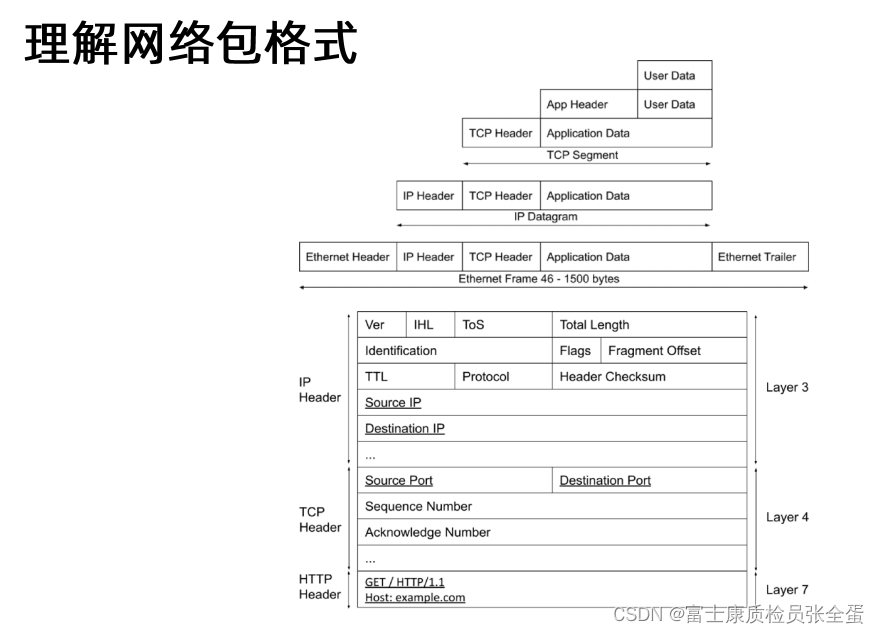
用户的数据和App Header,这是应用层面所要做的事情,比如你要去启一个HTTP请求,其实也就是请求的数据包是什么,你的Header是什么,这些东西最终会组成Application Data,这个数据包往外发的时候,这个数据包就会交给操作系统,操作系统就会在这个基础之上加上TCP Header,主要加的是源端口和目标端口...................................
这里面最重要的几个属性就是源地址,目标地址,源端口,目标端口,这就是做负载均衡策略所想要的信息,如果希望一个数据包的流量改写,用户访问了负载均衡的虚拟ip,希望它丢到一个真实的物理服务器上面,其实就是改一下destination的ip,如果我希望改变端口,只需要改destination的port,因为负载均衡就是去做这种事情的,其中负载均衡的技术就是NAT,就是网络地址转换,它相当于通过某些机制,来帮你将原始数据包目标地址转换掉,然后让你的包往下走,它就可以给你换成真实的IP地址,那你这个包就出去了。
集中式LB的服务发现

在每个集群边缘都会有一个都会有一些入栈的负载均衡,你外部的请求如何进来,通常会使用集中式的负载均衡去做。
在集群的外部,比如采购了F5的设备,那么这个设备就架在了kubernetes集群之上,任何的外部请求进来都要走这个负载均衡器,这个负载均衡器里面通过网络地址转换的技术将外部网络转化为内部的网络,然后将请求转到真实的后端服务器上面去,这样外部的请求就到了集群内部了。
这种负载均衡器往往承担着网络地址转换的职责。

大部分集群上面都会有集中的接入层,接入层最多的比如上面有防火墙,然后接下来有负载均衡器,负载均衡器下面才是节点。
那么所有的外部网络请求都是通过负载均衡器接入进来的,那么所有请求都要去负载均衡绕一圈。
进程内LB服务发现
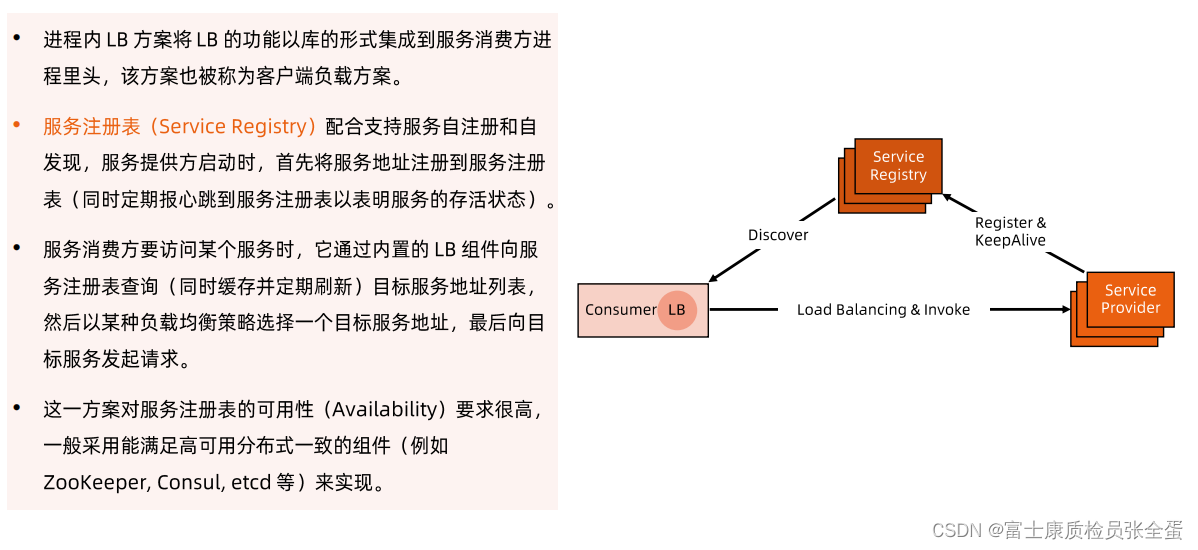
spring cloud里面其实有自己的服务发现机制,它有自己的服务注册中心eureka,每个实例在启动的时候,他要去服务注册中心里面,把自己注册上,我是服务A的一个实例,这个是我的地址,然后它要不断的给服务注册中心发送心跳说我还活着,来保证这个转发地址在注册中心是有效的,如果不去保活,那么就会认为你过期了,就不是一个有效地址了。
上面是服务提供方,服务消费方他要去访问服务,它其实是不知道这个地址的,它可能只知道服务的名称,他去问服务注册中心说,我要访问访问B,请给我服务B的有效地址,服务注册中心就会将请求发给他,那就是discover的机制。
可以看到LB组件和consumer的业务代码是强耦合的,LB版本一升级,那么所有的业务都得升级,这样维护成本就很大了。

独立LB进程服务发现
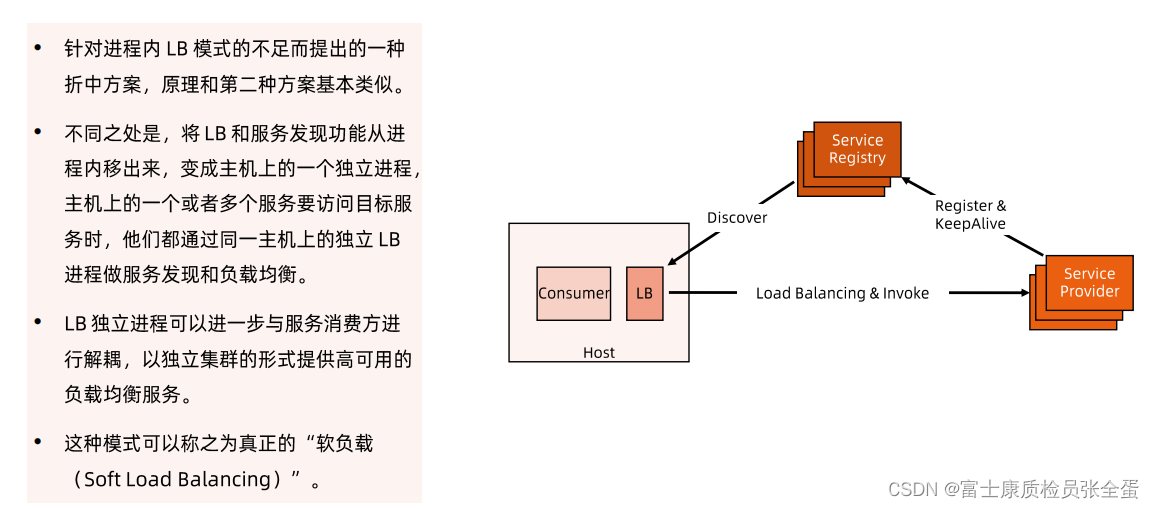
左边是一个host,这个host上面运行了不同的进程,一个是consumer的进程,一个是LB的进程,consumer进程是真正的用户业务代码,它其实只关注业务,还有LB进程,它去做服务发现,它去做负载均衡,它去转发真正的服务调用,这样将负载均衡的逻辑和消费者的逻辑,业务代码分离开来,它们两个是独立的进程,可以独立的升级和维护,这样我的业务逻辑只关注自己的业务逻辑,我们可以通过某些业务逻辑去访问服务的时候,这些请求全部转发到LB,然后由LB将这个请求转发出去,这个是我们推崇的模式。 
负载均衡

DNS负载均衡

DNS负载均衡
所谓DNS就是域名服务器,在发起一个网络调用的时候我们会去访问一个域名,而不是一个IP地址,因为域名容易记住,我们系统配置的时候都会去配置DNS服务器,它会去接受域名查询的请求,你问我域名,我就要告诉你IP地址,我自己不知道就要往上找,域名查询一般是配置为递归配置的,它自己不知道域名,你可以去配置它的上游服务器,上游又可以有上游,层层追溯,最后到Root DNS Server。