目录
红蓝对抗
在红蓝对抗中,一般是给定一批目标单位名称给你进行攻击,而你需要运用你毕生所学在互联网上对目标单位进行资产收集,从这些资产中找到通过一个突破口拿到服务器权限并进行内网横向移动。资产包括目标单位域名、app、公众号、小程序等,全资子公司资产,全资子子公司资产(需与主办方确认)。
一般如果目标公司进不去,我们还能从目标公司的全资子公司进行入手,那如何找目标公司的全资子公司了?
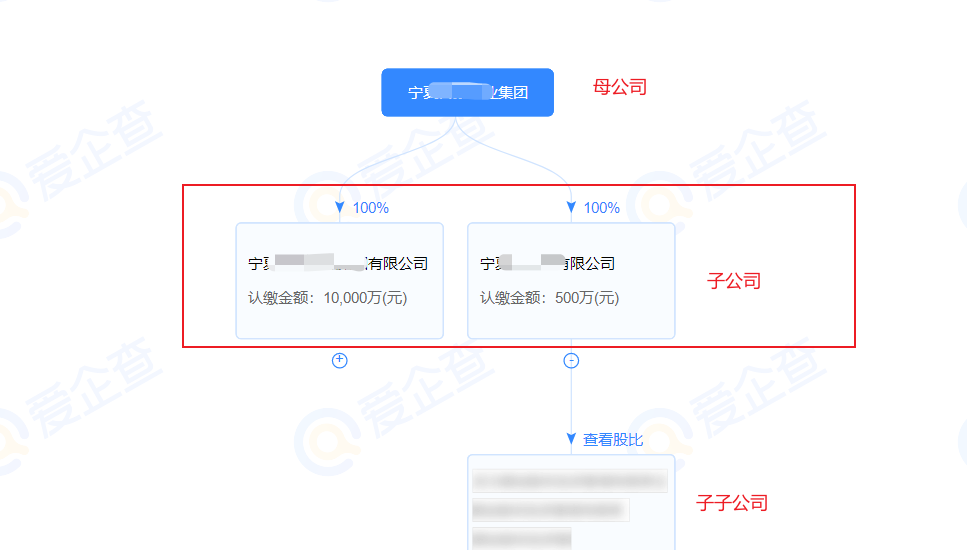
1. 以爱企查为例
输入企业名称—爱企查图谱—股权穿透图

如下两个为该公司的百分之百控股的子公司,一般也可以作为渗透目标
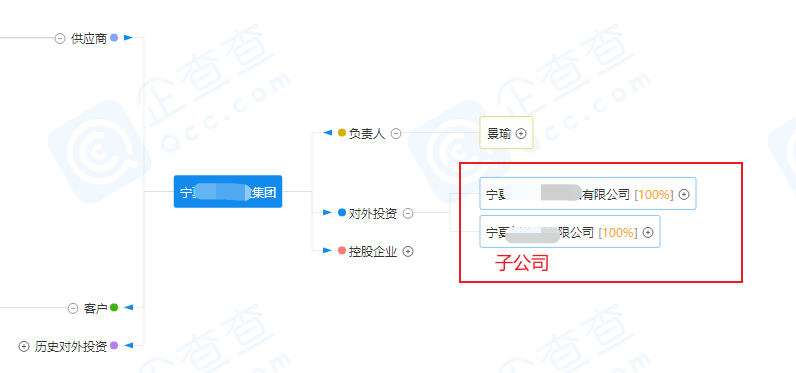
2. 以企查查为例
输入单位名称—查看图谱—企业图谱
对外投资就是该公司的子公司
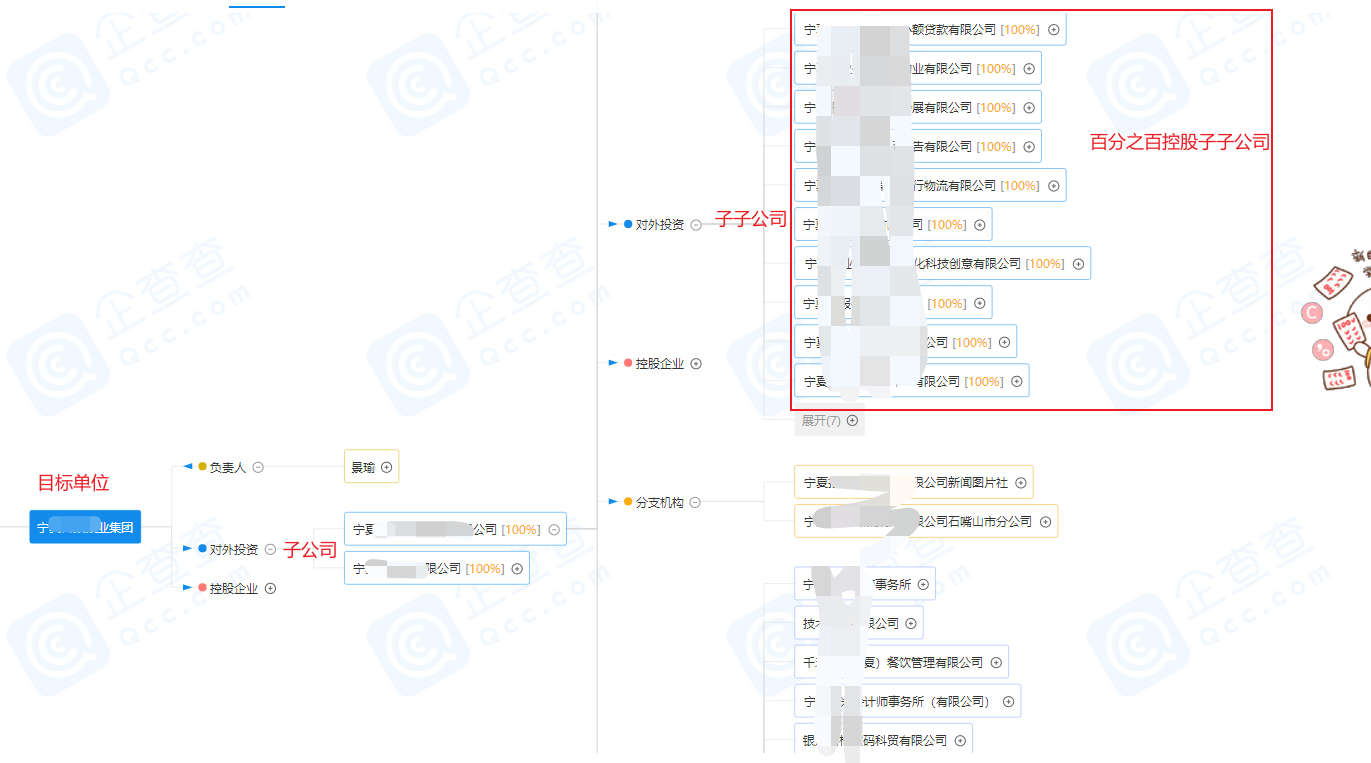
而且,一般情况下百分之百控股的子子公司也能作为渗透目标
ps:在红蓝对抗中,拿服务器权限不是重点,拿一台服务器权限也就100来分。得分的是数据,比如一个sql注入发现数据库中存在50w条敏感数据(如有姓名、手机号、地址、身份证号等,如果只有一个手机号则不算敏感数据),按照最新的平分规则,1w条数据50分,50w条数据就是2500分!!分数一下就上来了
红蓝对抗中,给的目标单位几十个,资产特别多,攻击的时间也短,如何在有限的时间里快速找到突破口进入内网是非常重要的。我的思路大概就是:搜集所有单位的主域名—子域名——存活检测——指纹识别——漏洞批量检测——挑软柿子捏——单个web渗透,然后还有其他的C段查询,敏感端口爆破、app、公众号、小程序也可以同时进行收集
ICP备案查询—查询主域
通过ICP备案查询可以知道该单位备案了多少个网站,一个网站就是一个主域
网站备案是根据国家法律法规 需要网站的所有者向国家有关部门申请的备案,主要有和ICP备案和公安局备案。公安局备案一般按照各地公安机关指定的地点和方式进行。ICP备案可以自主通过官方备案网站在线备案或者通过当地电信部门两种方式来进行备案。
常说的网站备案就是ICP备案,备案的目的就是为了防止在网上从事非法的网站经营活动,打击不良互联网信息的传播,如果网站不备案的话,很有可能被查处以后关停。
域名所在ip的服务器在国内则需要备案,所在服务器为香港或者国外则不需要
那我们为什么要进行ICP备案查询了?进行ICP备案查询我们可以了解到该公司备案了多少个网站,通常一个网站就是一个主域。找到了主域之后我们可以分别对主域爆破子域。常用的查询站点如下
- ICP备案查询 - 天眼查
- 企查查
- 小蓝本
1. ICP备案查询
如下这些站点都属于该公司,当然并不是所有网站都有效,得一个一个看

2. 天眼查
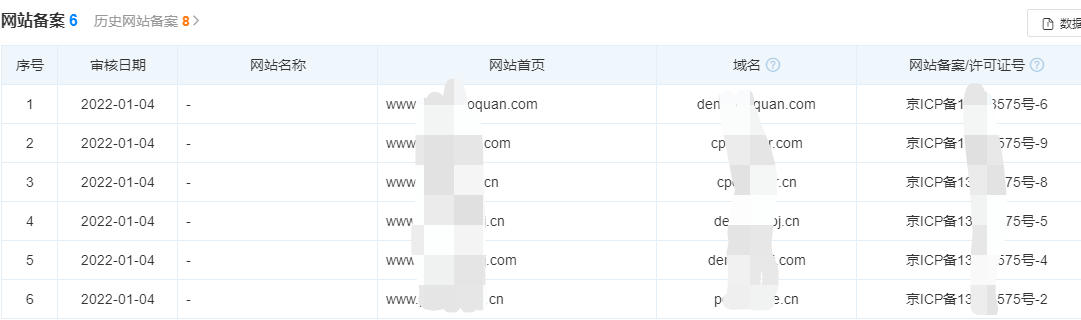
如下,在天眼查中搜索目标公司名称,如下我们可以着重关注网站备案、公众号等信息。
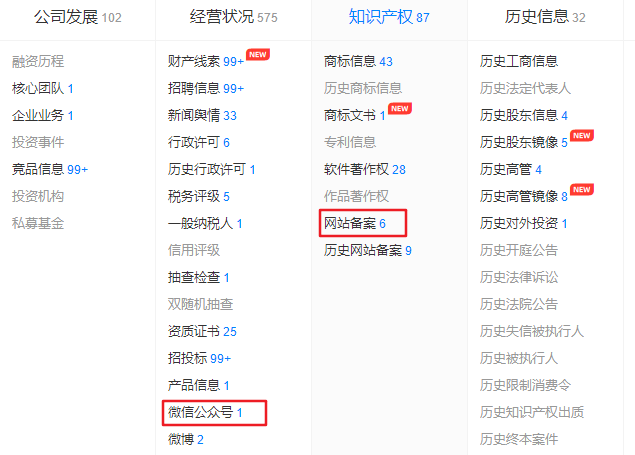
如下,网站备案中显示有有关网站6个
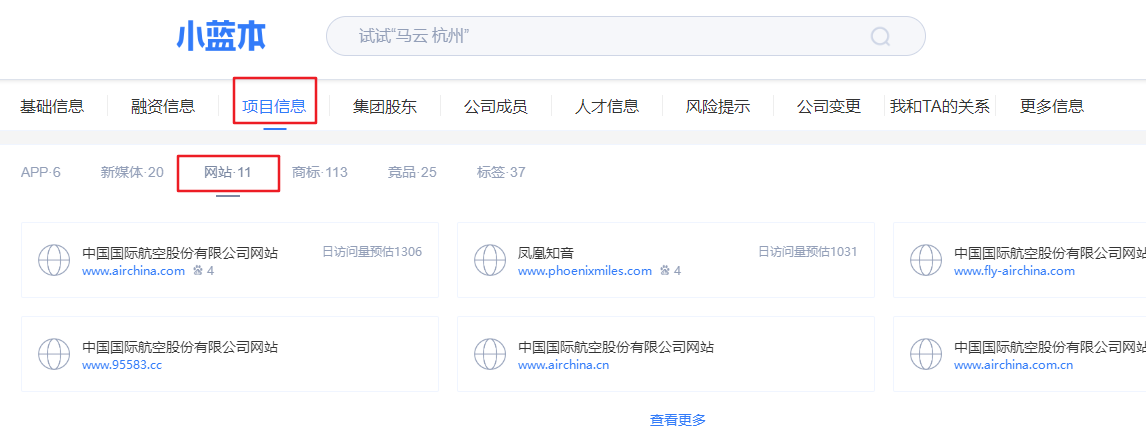
3. 小蓝本企业信息搜索
小蓝本查询出来的网站更多,备案的和未备案的都能查到。ps:未备案的域名除非服务器将开放的端口改为了非 常用端口才可以访问
如也查询到未备案的域名
主站域名一键查询
ENScanGo 是现有开源项目 ENScan 的升级版本,工具地址:https://github.com/wgpsec/ENScan_GO
这是一款由狼组安全团队的 Keac 师傅写的专门用来解决企业信息收集难的问题的工具,可以一键收集目标及其控股公司的 ICP 备案、APP、小程序、微信公众号等信息然后聚合导出。
填写有关cookie信息
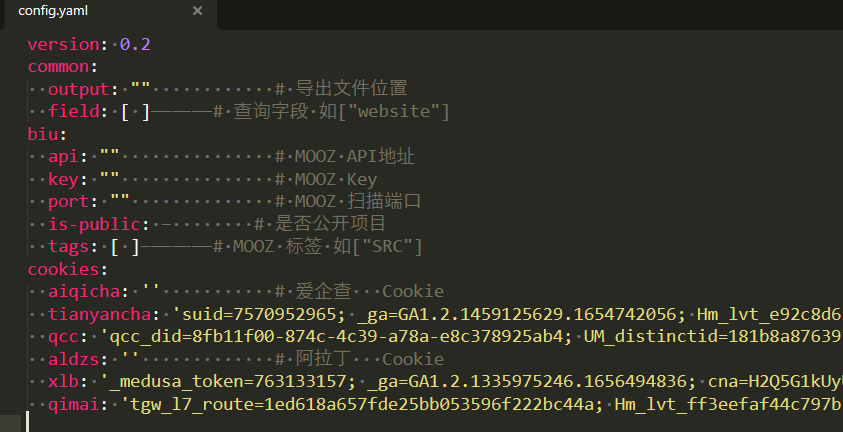
#查询该公司的有关信息
ENScanPublic_amd64_windows.exe -n 北京xx技术有限公司 #默认从爱企查查询
ENScanPublic_amd64_windows.exe -n 北京xx技术有限公司 -type all
-o 文件夹 输出到文件夹位置
ENScanPublic_amd64_windows.exe -n 北京xx技术有限公司 -type all -invest-num 100 #导出控股比例100%的公司,即全资子公司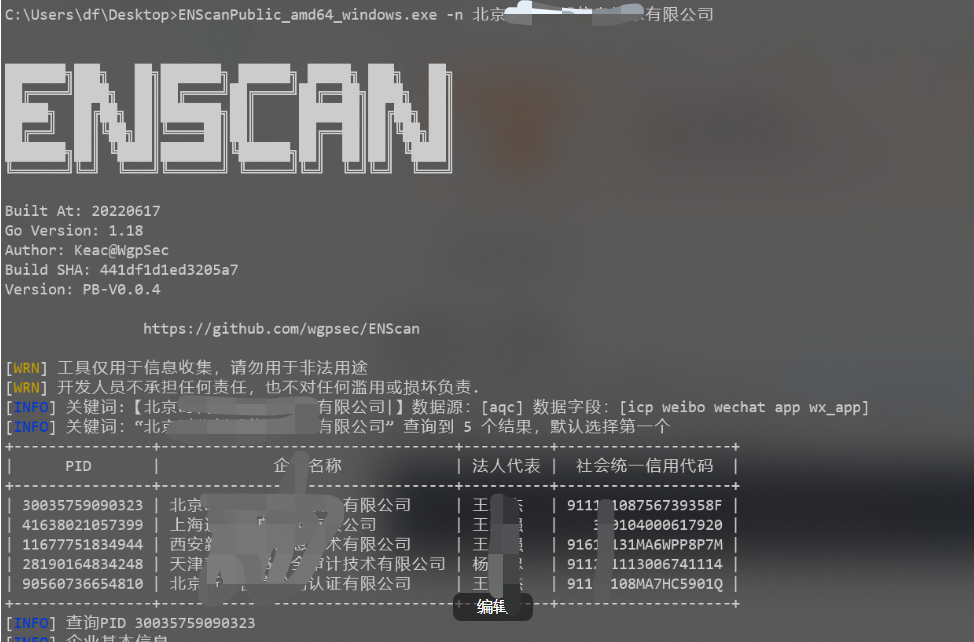
结果自动保存在当前目录 "\outs\公司名.xlsx"中
敏感信息收集
利用搜索引擎、github等托管平台配合一些google语法就可以搜到很多信息。
熟知的googlehack,gitdork,网盘泄露等等。
敏感信息一共要搜集这个几个方面:
- googlehack
- github泄露
- 目标人员姓名/手机/邮箱
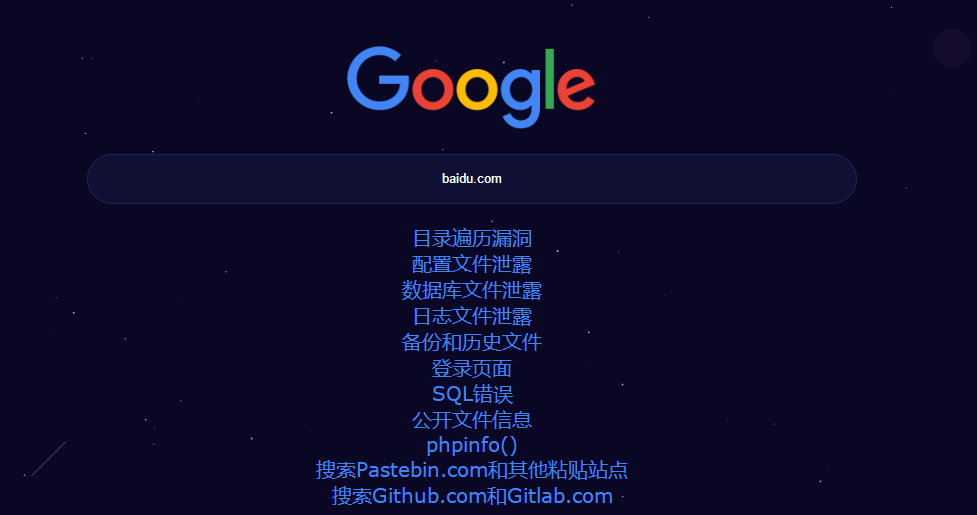
googlehack语法
别人已经写好了语法,直接将主域名放上去就行
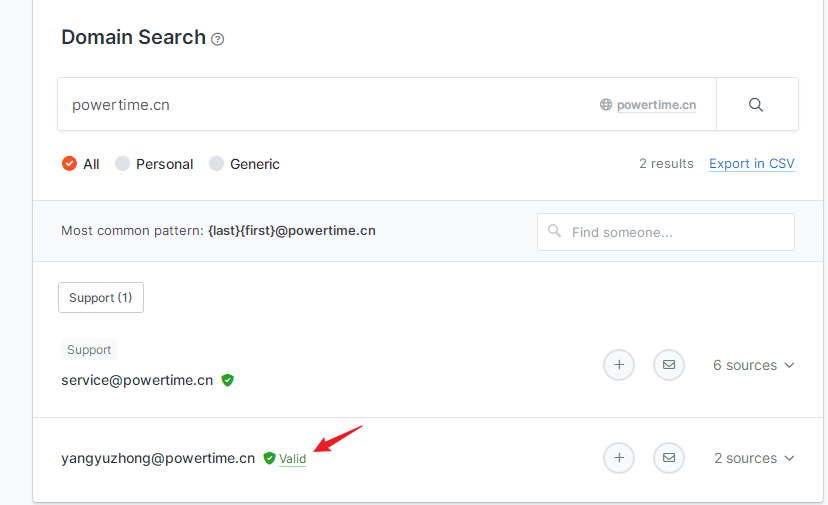
目标邮箱号收集
批量收集目标邮箱的一些常规途径
点一下还能判断该邮箱号目前是否有效
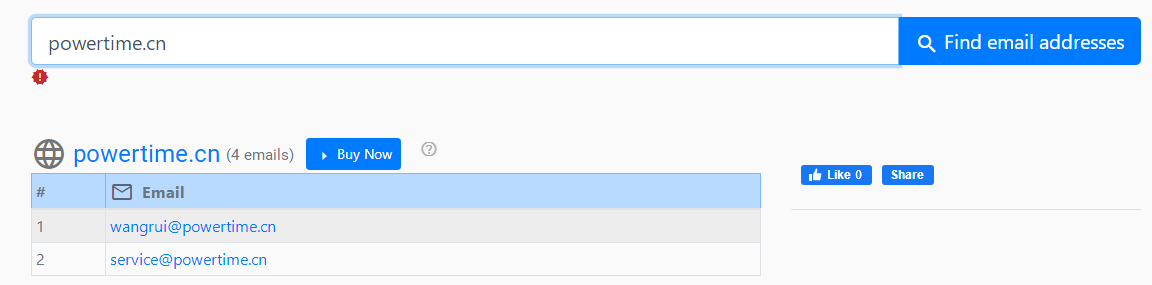
2. Find email addresses of companies and people - Skymem
子域名收集
对于同一个域名,各种方式、工具搜集的结果都不相同,企图用一两种方式就全部将域名收集全,是不可能的。只有综合利用各种工具才能最大程度搜集全信息
被动信息收集
被动信息收集方式是指利用第三方的服务、公开渠道,去获得目标主机的信息,从而不与目标系统直接交互,避免留下痕迹。
证书透明
证书:当通过HTTPS访问web时,网站向浏览器提供数字证书,此证书用于识别网站的主机名,由证书颁发机构(CA,Certificate Authority)颁发。
证书透明:证书透明(CT)是证书颁发机构(CA)必须将其发布的每个SSL/TLS证书发布到公共日志的项目。SSL/TLS证书通常包含域名,子域名和电子邮件地址等信息。
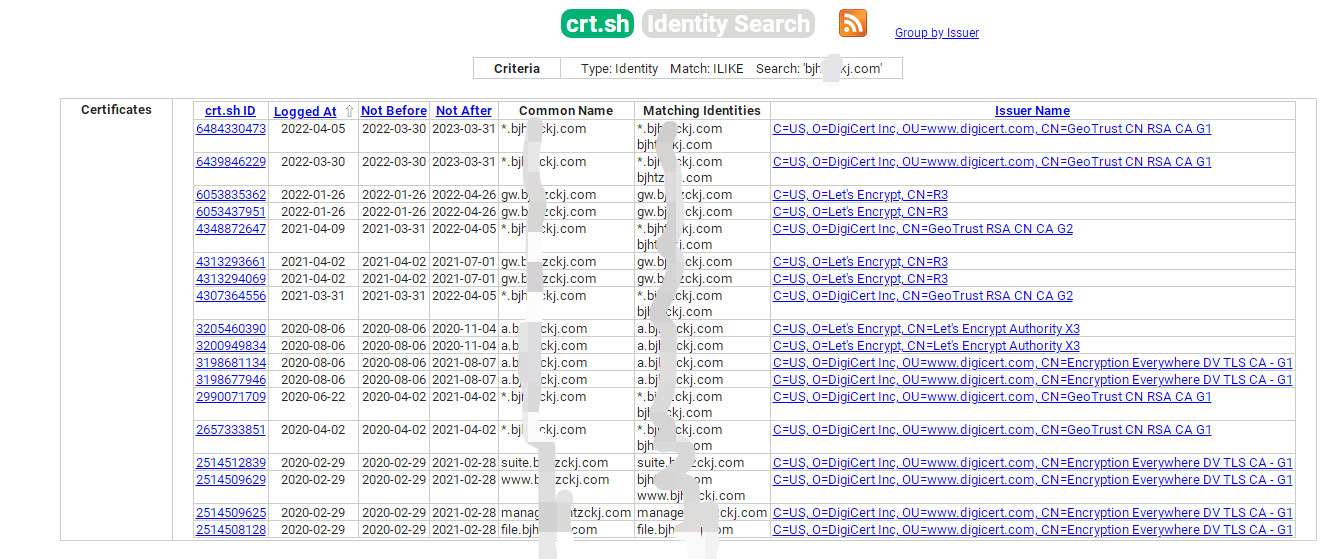
利用Google提出的证书透明度(Certificate Transparency)查询公开的子域,一般查询结果包括域、签发者、有效期和签名等
在线查询地址:
crtsh: crt.sh | Certificate Search
censys: Censys
- 如crt.sh | Certificate Search,输入域名,点击search
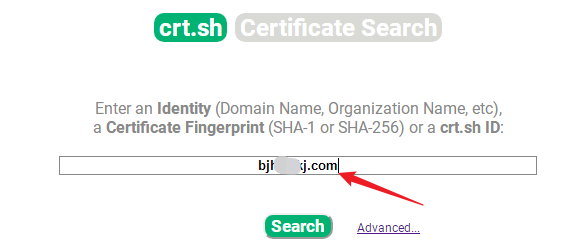
大部分时候查找到的结果比其他工具多
- 如censys
可以免费注册获取API,登录账户之后点击
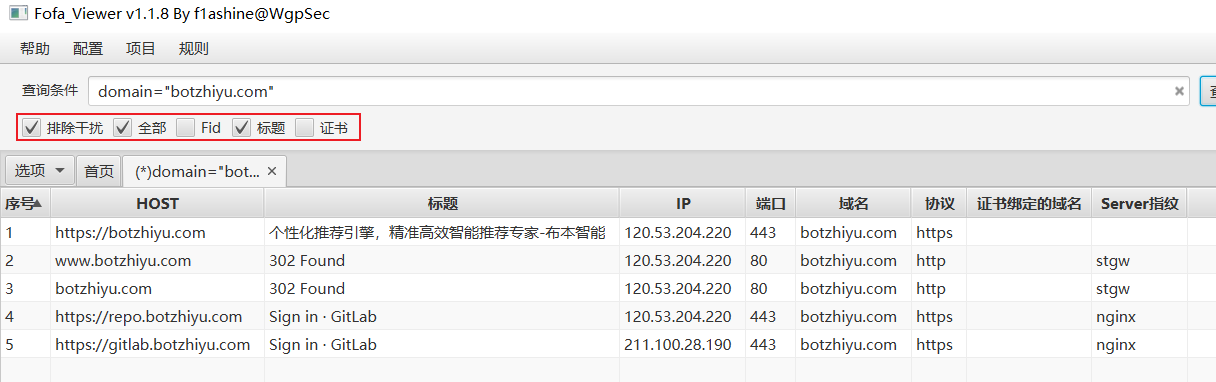
fofa_viewer
就是将fofa做成了一个图形化工具,然后引入fofa的api接口。比在浏览器中更好用。项目地址:https://github.com/wgpsec/fofa_viewer
我们下载jdk文件
1. 配置fofa api,没有fofa会员的话用不了
打开config.properties 配置email和key值(登录fofa后点击头像个人中心——个人资料——复制联系邮箱和api key)

2. 新建fafa.bat文件
填写:java -jar fofaviewer.jar
3. 双击bat文件启动fofa_view
和浏览器中的fofa语法相同,如搜索子域名
在线子域名查询
在线子域名查询 非常强大
第三方DNS服务
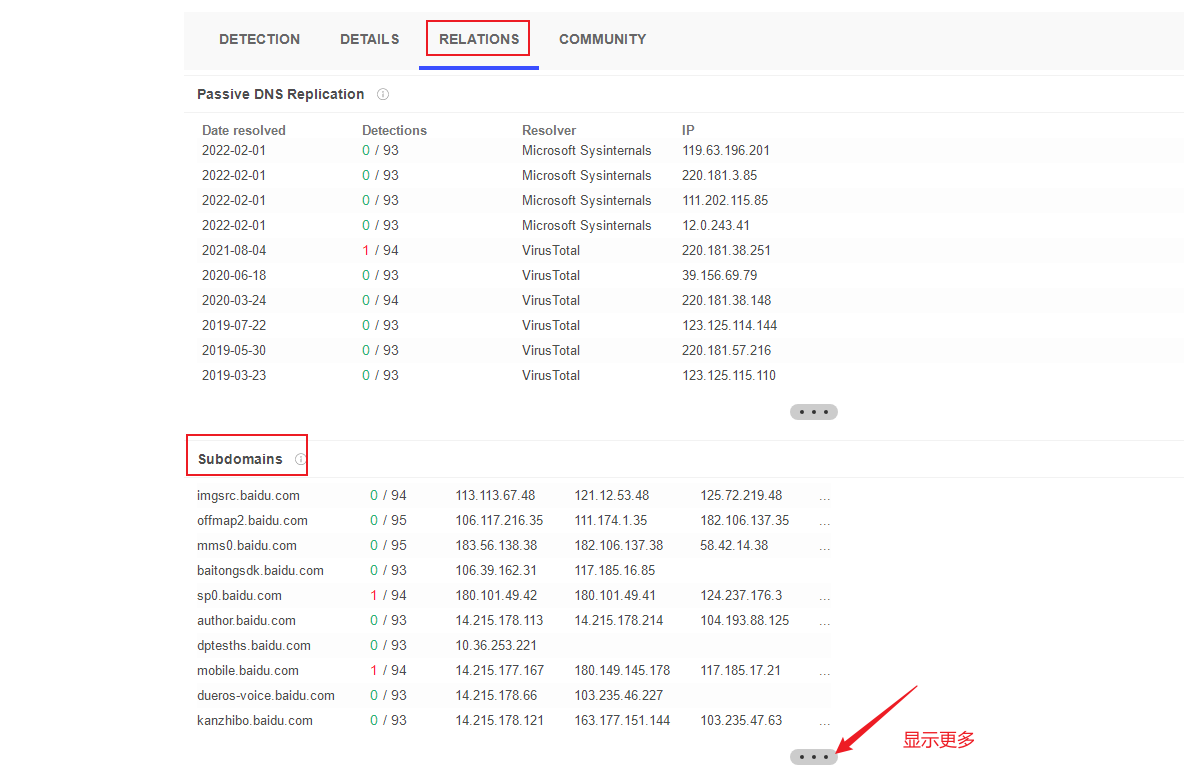
VirusTotal,VirusTotal会运行DNS复制功能,通过存储用户访问URL时执行的DNS解析来构建数据库。
有可能会发现一些其他工具都发现不了的子域
- 输入域名,然后回车
google语法
1. 搜索子域名,排除www主域
site:jd.com -www
主动信息收集
oneforall
首先推荐的就是oneforall这款工具,具体介绍可看,传送门 ——> OneForAll
依赖环境:python3
tips:工具所在的目录不能存在有空格的目录名称,否则文件无法保存
1. 首先安装依赖:pip install -r requirements.txt
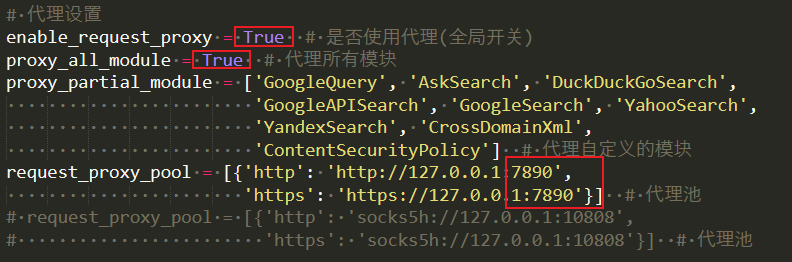
2. 建议在开启了代理的情况下使用,能获取更多的结果
打开config/setting.py文件,修改如下
3. 常用用法
(1)爆破目标子域,默认保存为CSV文件
oneforall.py --target jd.com run结果保存在 \OneForAll-master\results\jd.csv 中
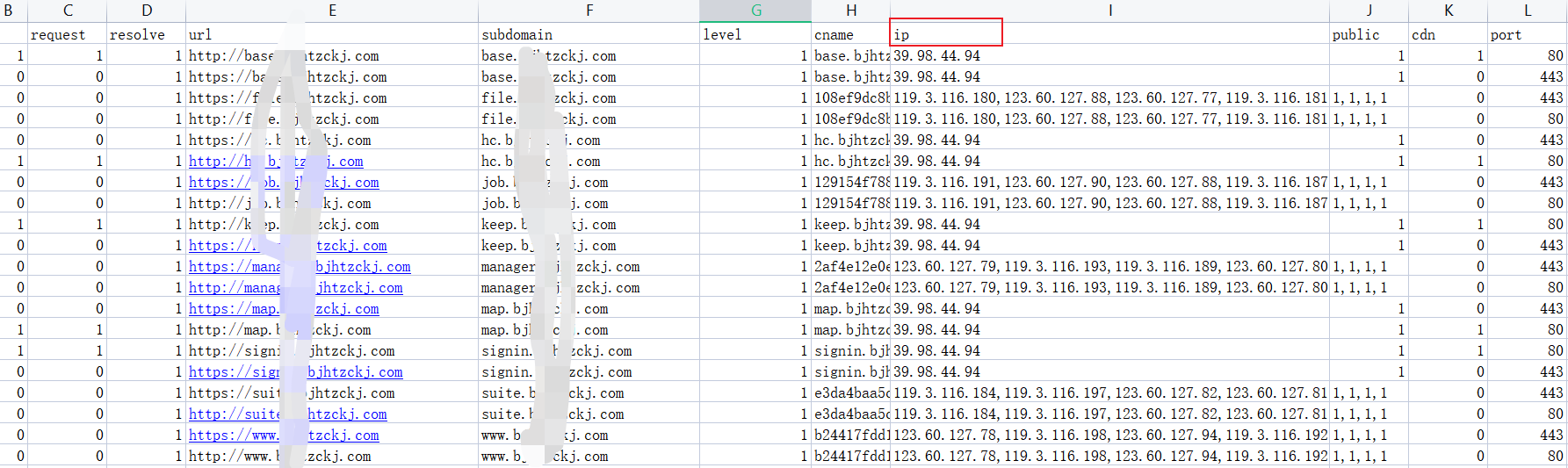
打开文件,ip字段如果有过个ip则存在cdn,否则为真实ip
注意事项
- 只能保存为csv和json格式的文件,有两个配置文件一个setting.py,一个default.py。配置setting.py文件就行
- 使用代理,但是不要代理所有模块
扩展api
建议添加扩展api,能获取到更多子域名
https://github.com/shmilylty/OneForAll/blob/master/docs/collection_modules.md
Sylas—从burp历史记录中提取子域
项目地址:https://github.com/Acmesec/Sylas
此工具需要数据库连接,这里我直接使用phpstudy中的mysql数据库,在里面创建一个数据库如:domain
- 创建一个数据库后连接数据库
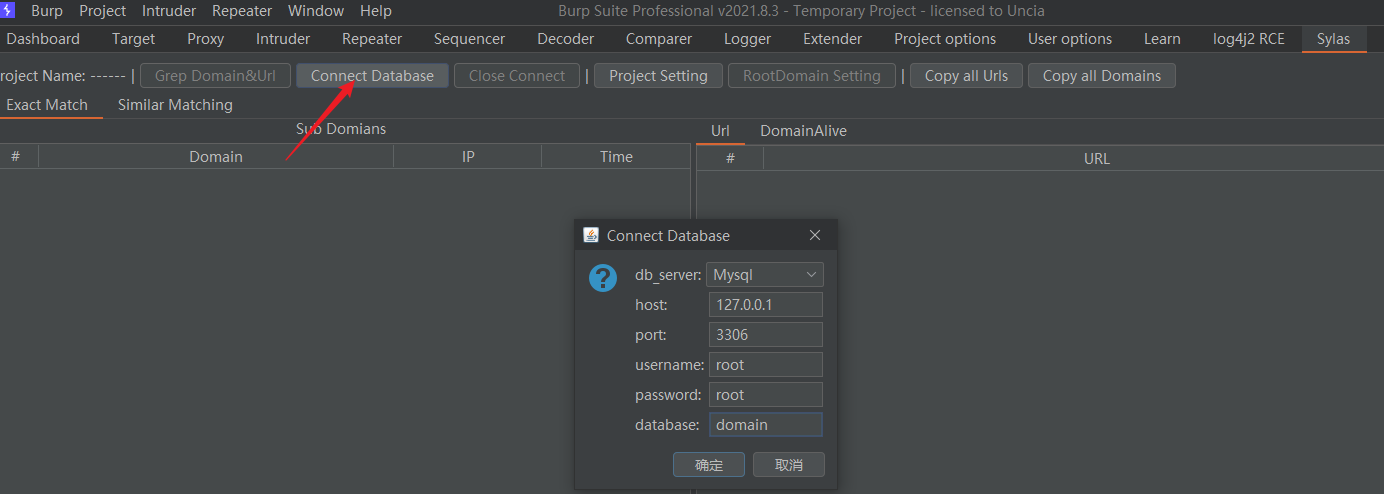
- 新建项目名称,添加后记得选中,再点击确定
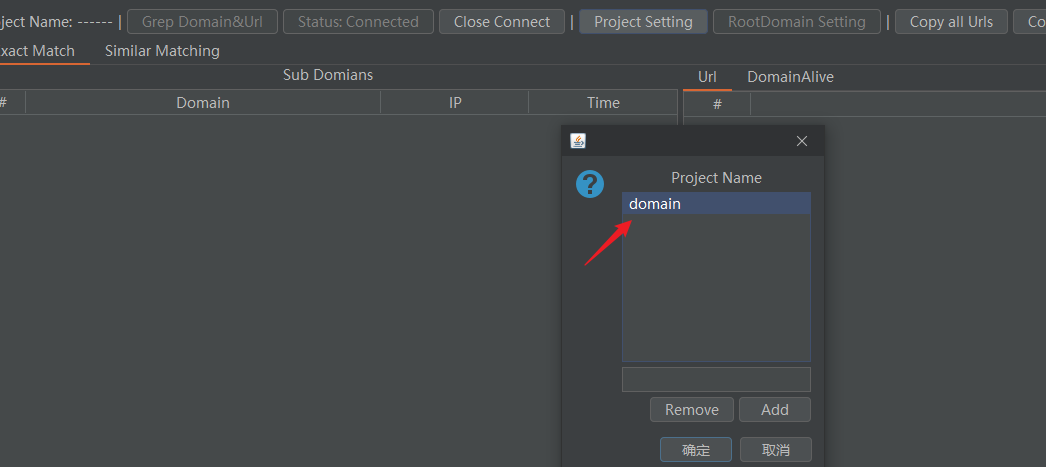
- 添加要提取的根域名
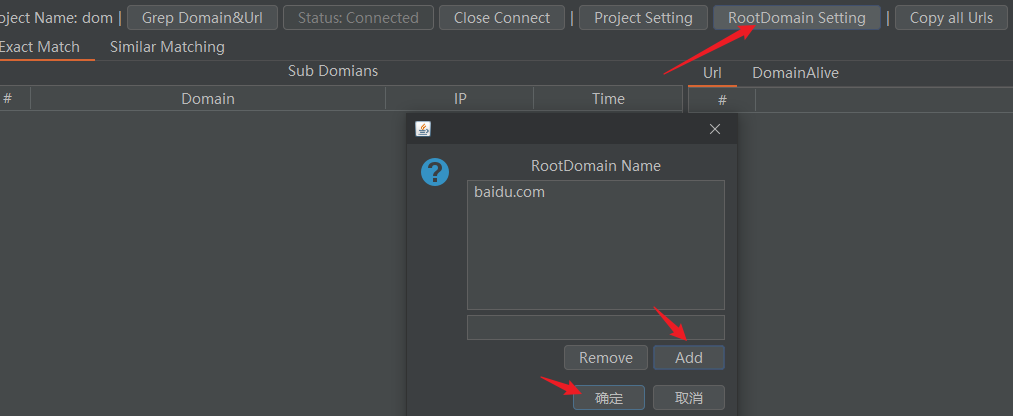
我们是浏览器访问baidu,会自动从burp历史流量中抓取子域
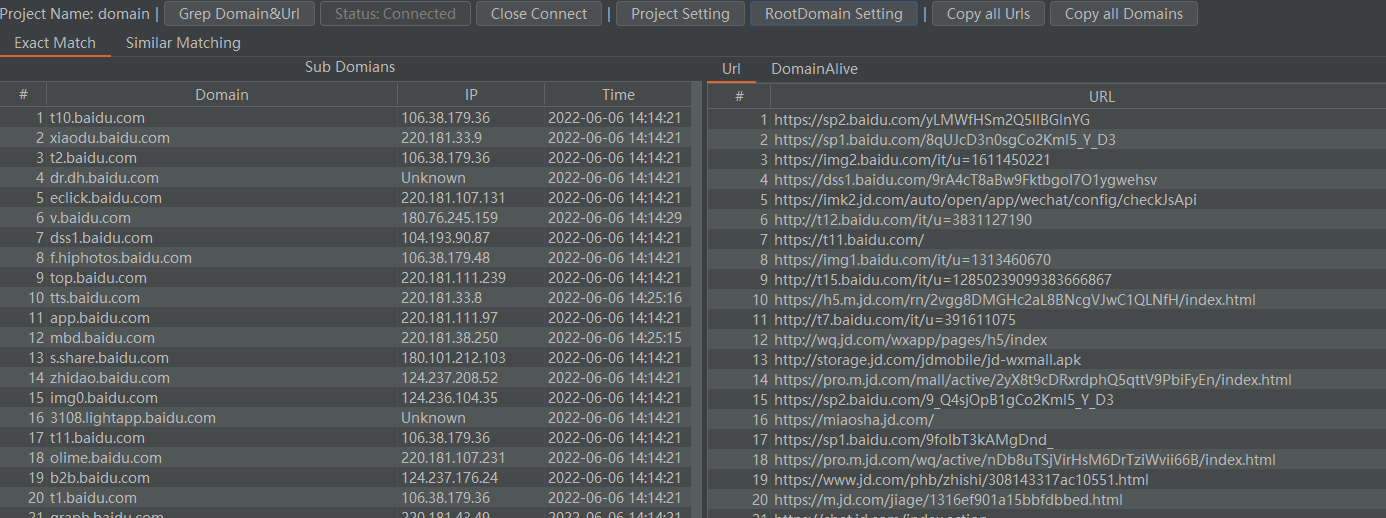
虽然上面有显示复制域名的按钮,但是并没有用。
写了个提取子域名的脚本,将抓取到的这些域名信息复制到domain.txt中
domain.py baidu.com
import re
import os
import argparse
#传参
parser = argparse.ArgumentParser(description='提取Sylas中的子域名')
parser.add_argument('domain',type=str,help='想要提取的子域名,如: "pyhton domain.py jd.com"')
args = parser.parse_args()
domain = args.domain
#打开并读取文件
f = open("domain.txt",'r')
data = f.read()
f.close()
#正则查找子域
sub = re.findall(r'\S*.%s' %(domain), data) #正则中插入变量
if os.path.exists("result-domain.txt"):
os.remove("result-domain.txt")
if sub:
for i in sub:
print(i)
with open("result-domain.txt",'a') as file:
file.write(i+'\n')
print("共提取:",len(sub),"个子域名。结果保存在当前路径'result-domain.txt'文件中")
os.system("result-domain.txt")
else:
print("未能提取出子域名,请重新输入根域名")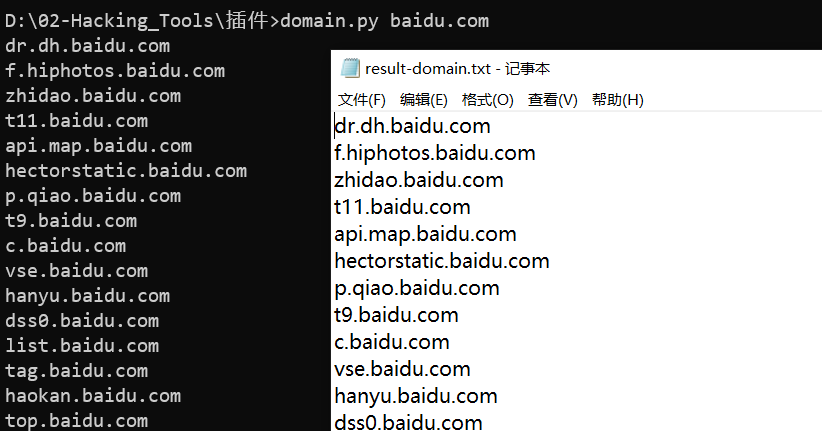
Layer5.0
项目:https://github.com/euphrat1ca/LayerDomainFinder/releases/tag/3
端口扫描
快速扫描大量主机
nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v -p 1-65535 -iL url.txtCMS指纹识别
网站指纹:网站指纹包括应用名、版本、前端框架、后端框架、服务端语言、服务器操作系统、网站容器、内容管理系统和数据库等
渗透测试的时候如果通过一定的方法获取CMS类型、Web服务组件类型及版本信息可以帮助安全工程师快速有效的去验证已知漏洞
常见指纹检测的对象
- CMS信息:比如大汉CMS、织梦、帝国CMS、phpcms、ecshop等;
- 前端技术:比如HTML5、jquery、bootstrap、pure、ace等;
- Web服务器:比如Apache、lighttpd, Nginx, IIS等;
- 应用服务器:比如Tomcat、Jboss、weblogic、websphere等;
- 开发语言:比如PHP、Java、Ruby、Python、C#等;
- 操作系统信息:比如linux、win2k8、win7、kali、centos等;
- CDN信息:是否使用CDN,如cloudflare、360cdn、365cyd、yunjiasu等;
- WAF信息:是否使用waf,如Topsec、Jiasule、Yundun等;
- IP及域名信息:IP和域名注册信息、服务商信息等;
- 端口信息:有些软件或平台还会探测服务器开放的常见端口。
EHole
EHole旨在帮助红队人员在信息收集期间能够快速从C段、大量杂乱的资产中精准定位到易被攻击的系统,从而实施进一步攻击。
项目:https://github.com/EdgeSecurityTeam/EHole
EHole(棱洞)2.0提供了两种指纹识别方式,可从本地读取识别,也可以从FOFA进行批量调用API识别(需要FOFA密钥),同时支持结果JSON格式输出。
- 本地识别
Ehole3.0-Win.exe -h
- -u url 单个网站识别
- -l url.txt 批量识别
- -json export.json 导出json格式
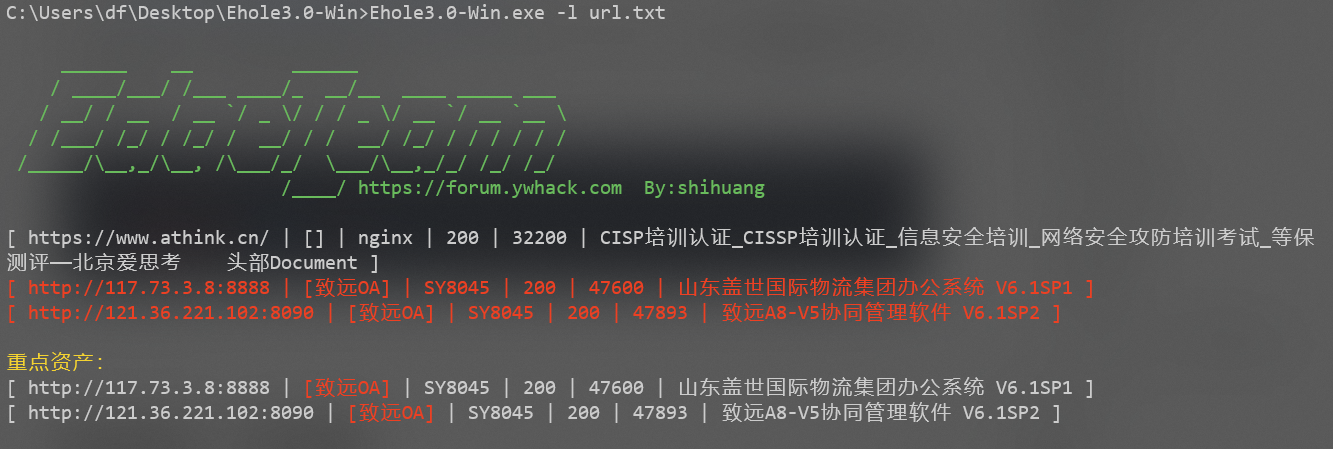
- FOFA识别:
注意:从FOFA识别需要配置FOFA 密钥以及邮箱,在config.ini内配置好密钥以及邮箱即可使用。
ps: 该工具需要输入带http或https的网站,否则不识别,而observer_ward不需要
observer_ward
使用之前先“-v”更新指纹库
指纹库:C:\Users\df\AppData\Roaming\observer_ward
项目:https://github.com/0x727/ObserverWard
observer_ward.exe -u #更新指纹库
observer_ward.exe -t url #单个地址识别
observer_ward.exe -f url.txt #批量识别
observer_ward.exe -f url.txt --proxy http://127.0.0.1:7890
observer_ward.exe -f url.txt -c 1.csv 3导出为csv文件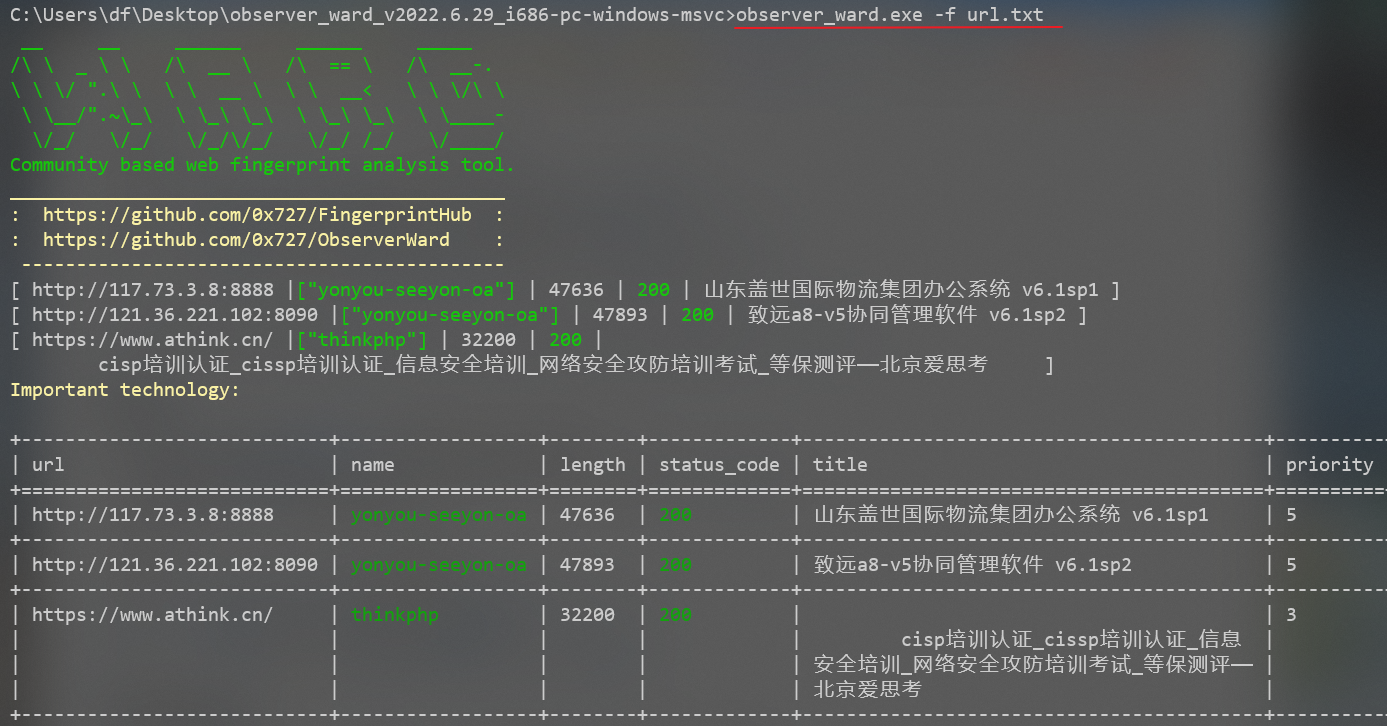
Finger
https://codeload.github.com/EASY233/Finger/zip/refs/heads/main
Wappalyzer
火狐的插件
敏感目录、文件探测
一般爆破目录不附带恶意Payload的话,WAF基本不会拦截的,除非有防DDOS、CC攻击的设备
dirsearch
项目地址:GitHub - maurosoria/dirsearch: Web path scanner
常用参数如下
- -h 查看帮助
- -u xx 目标域名xx
- -e php 扫描网站的类型为php, 类型如php,asp,jsp
- -t 40 线程为40,默认为30
- -x 400, 404, 503 排除响应码400...,即响应码为这个的不输出到屏幕上
- --full-url 输出完成的url模式,这样直接点击就能访问扫描出的结果
- -s 设置请求之间的延时
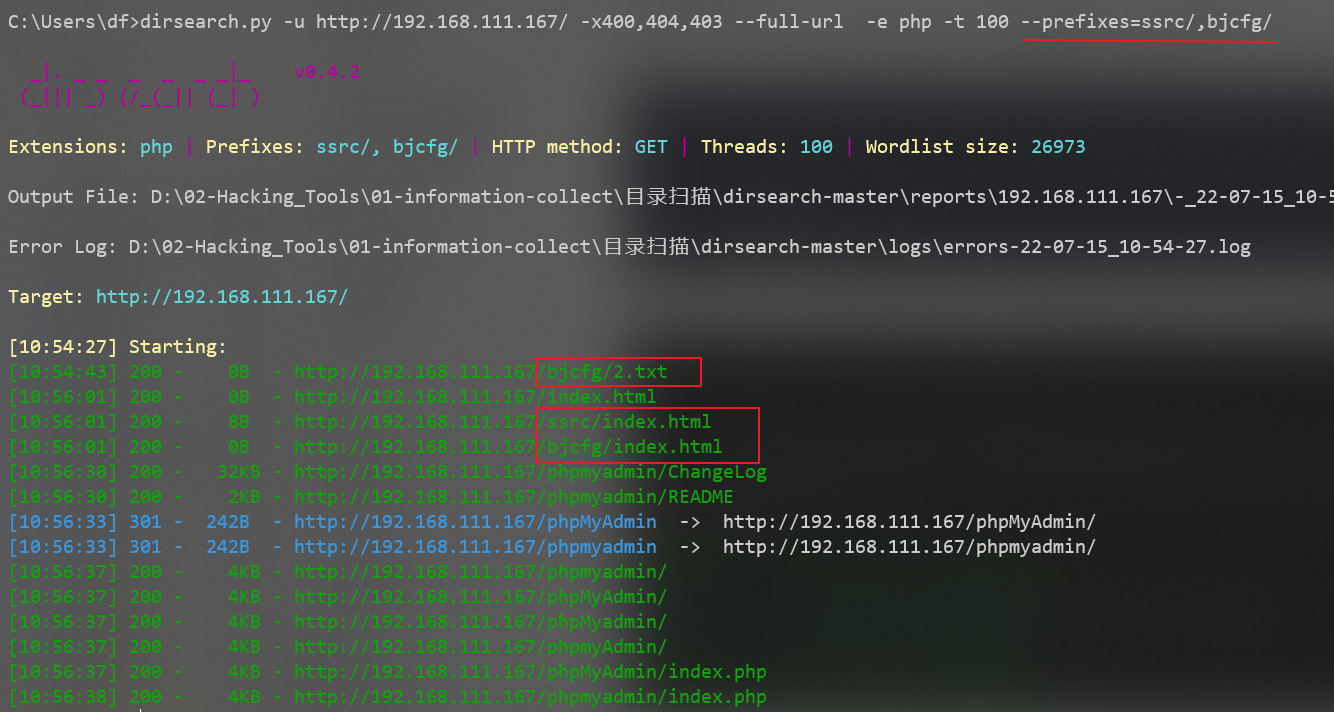
1. 以线程为40的速度扫描php的网站,不显示503,400,404状态码
dirsearch.py -t 40 -e php -x 503,404,400 -u http://jxxx.cn/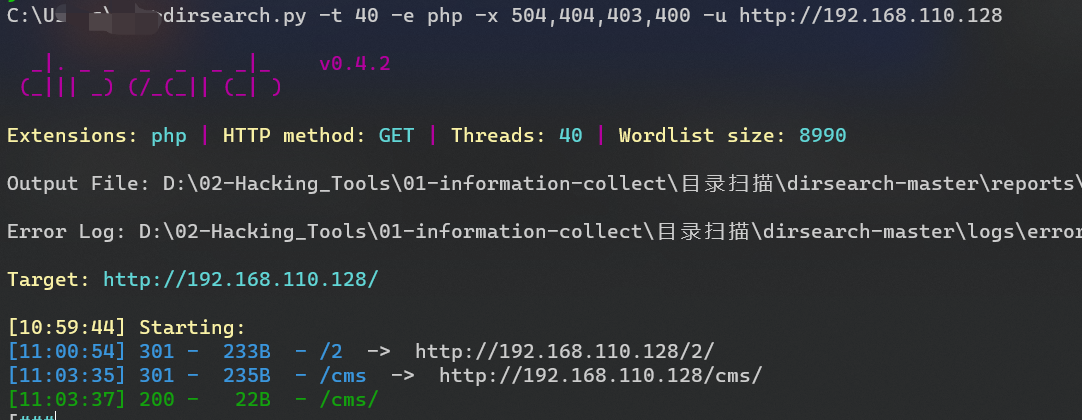
默认使用一个字典,字典位置在:\dirsearch-master\db\dicc.txt。可以在里面加上自己的字典

然后就能扫描到

--prefixes=
可以在所有字典前加自定义n个前缀,这样字典数量就会翻n倍,比如原来字典有100个数,加了一个前缀就有100*n个,它会把原来的字典跑一遍,加上前缀后的字典再跑一遍
#加上一个前缀
--prefixes=ssrc/
#加上两个前缀
--prefixes=ssrc/,bjcfg/我在网站目录中加了ssrc和bjcfg两个个目录,正常字典是跑不出来的,我加上这个参数后就能跑出来了
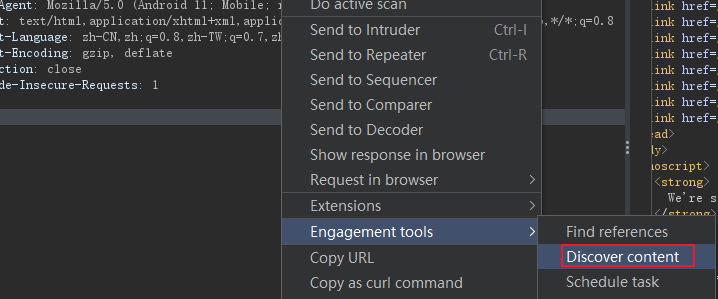
burp之discover content
有时能够发现其他工具发现不了的一些目录
- 选择discover content
- 设置目录爆破起点
- 可以以title进行排序查看结果
JSFinder
在网站的JS文件中,会存在各种对测试有帮助的内容。
地址:https://github.com/Threezh1/JSFinder
JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。
提取URL的正则部分使用的是LinkFinder
JSFinder获取URL和子域名的方式:
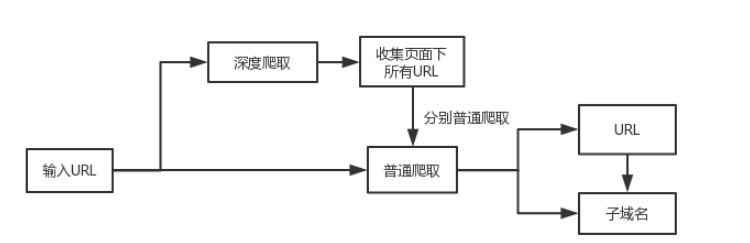
修改几个参数:
(1)响应超时时间改为12,以及加a上代理(代理还是建议不加,影响速度),因为我本机一直开启clash

- 简单爬取
python JSFinder.py -u http://www.xx.com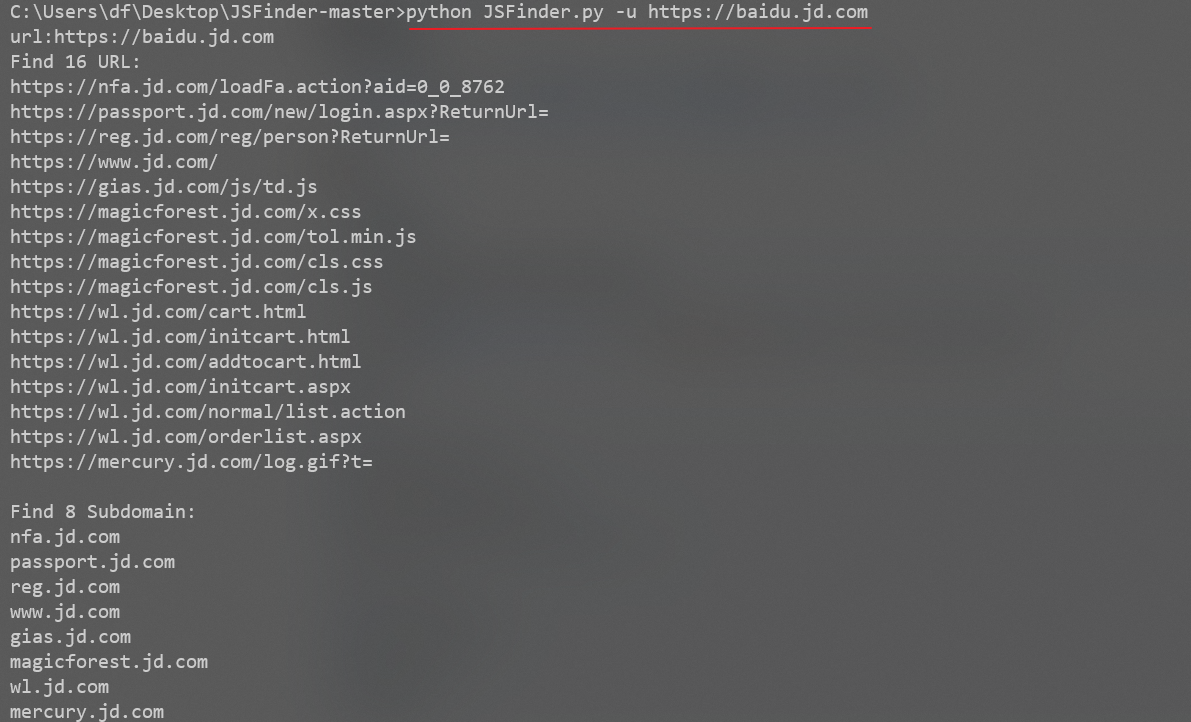
- 深度爬取
深入一层页面爬取JS,时间会消耗的更长,获取的信息也会更多。建议使用-ou 和 -os来指定保存URL和子域名的文件名。
python JSFinder.py -u https://baidu.com -d python JSFinder.py -u https://baidu.com -d -ou url.txt -os sub.txt
