异构计算技术分析
参考文献链接
https://mp.weixin.qq.com/s/xW_Y0JBKK3d42IZvHA9CrQ
https://mp.weixin.qq.com/s/amQj0DYvs9QwIuTpsGEFNg
https://mp.weixin.qq.com/s/Y2cRAHnztWw5l0eeU_pDrg
https://mp.weixin.qq.com/s/WyVgGB8-dPl9L68cppUNaw
什么是异构计算?
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。异构计算已经无处不在,从超算系统到桌面到云到终端,都包含不同类型指令集和体系架构的计算单元,下面先从几个系统了解下异构计算超算系统。
天河-2:包括16,000个计算节点,每个节点 2Xeon (IveBridge)+3Phi。Total 3,120,000 Core, Linpack测试基准为33.86 petaFLOPS ,Power 17.6 megawatts。编程框架:OpenMC/OpeMP。
Mac Pro: Intel Xeon E5 (6/8/2 cores) + Dual AMD FirePro D500 GPU (1526 stream processors, 2.2 teraflops, 3-way 4k video)。编程框架:CUDA、OpenCL、Metal。
Amazon Linux GPU Instances g2.8xlarge: 4 GPU (each with 1,536 CUDA cores and 4 GB of video memory and the ability to 4* 1080p@30fps), 32 vCPU 。编程框架:CUDA,OpenCL。
Qualcomm Snapdragon 820 : octa-core CPU+ Adreno 530 GPU+ Hexagon 680 DSP,编程框架:MARE,OpenCL。
显然,异构计算系统包含了不同异构计算单元,如CPU、GPU、DSP、ASIC、FPGA等。除了异构硬件单元,不同异构计算平台采用的编程框架也不尽相同。那么,为什么要用异构计算?
异构计算优势主要提现在性能、性价比、功耗、面积等指标上,在特定场景,异构计算往往会表现出惊人的计算优势。
• Google Brain:1,000台服务器 (16,000 CPU核) 模拟simulating a model of the brain with a billion synapses.
• Nvidia:three GPU-accelerated servers: 12 GPUs in total, 18,432 CUDA processor cores.
The Nvidia solution uses 100 times less energy, and a 100 times less cost.
关于GPU和CPU的详细分析和对比,请参考文章:GPU技术的现在和ASIC的未来、谈谈GPU和CPU为何不同和GPU关键参数和应用场景。
除OpenCL之外,还有很多编程框架?异构并行计算框架是充分发挥异构硬件性能和屏蔽硬件差异的关键,但目前业界不存在一个统一标准。
OpenCL是业界主流公司推动的异构并行计算编程标准。OpenCL属于性能层,业界很多产能层框架对接OpenCL。
• Intel、ARM、高通的异构硬件均支持OpenCL软件设计。
• Intel Xeon+FPGA异构芯片支持OpenCL。
Nvidia CUDA、Apple Metal是针对各自异构硬件设计的计算私有框架,是封闭系统,但都有广泛的开发者支持。CUDA和OpenCL在设计理念上非常相近,但Nvidia GPU性能业界最强,有能力通过CUDA绑定用户,比如深度学习上Nvidia GPU效果最好,开发者只能选择CUDA。
异构硬件的一个趋势是SOC上集成多种异构硬件。比如高通820芯片集成了ARM64+GPU+DSP等多种形态。
• 但传统的计算框架只针对一种硬件设计,无法支持多形态。
• 高通设计了Symphony异构并行计算框架来发挥多形态异构硬件性能,同时适应未来芯片的演进。
OpenCL异构编程技术得到各大厂家的大力支持,可屏蔽异构硬件与OS差异,简化异构核编程复杂度,OpenCL由苹果提出,得到业界大多数厂商的支持:如Nvidia、Apple、AMD、ARM、INTEL、TI等等,支撑GPGPU、DSP、FPGA等通用硬件加速器。
• 优势:OpenCL是针对GPGPU大规模数据并行的特性所开发的底层编程框架,屏蔽各厂商GPU之间的差异,与芯片设计协同演进,C语言的扩展。
• 不足:性能的可移植性不足。
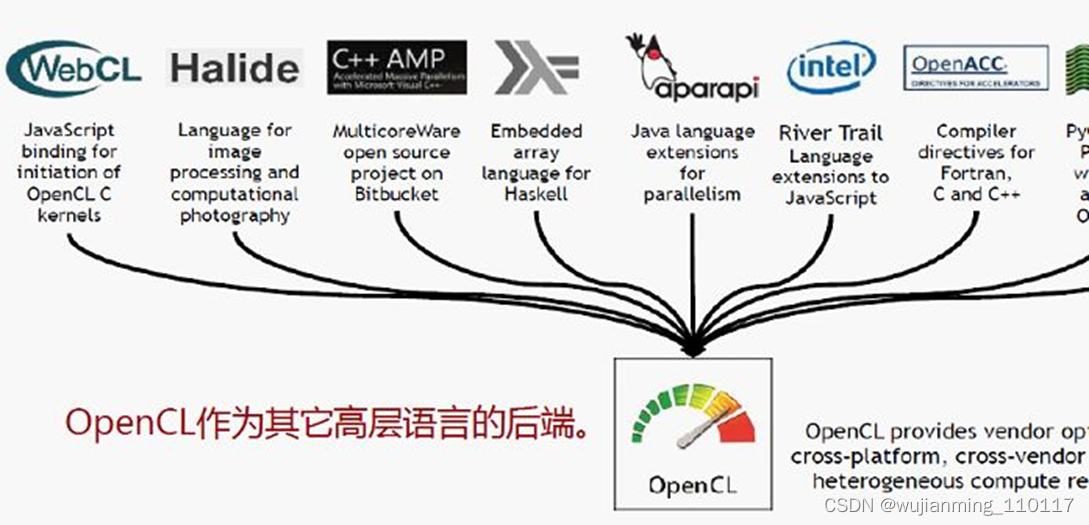
OpenCL编程模型中隐含了很多的硬件特征,比如并行粒度、内存模型、存储层次、资源粒度、内存带宽和延迟、ISA差异等,这导致不同的加速器上的OpenCL代码都要重新思考上述特征。
随着FPGA的广泛使用,成本逐步降低,作为软件定义实现快速在线指令优化,对整个编译器、运行框架、OS产生巨大影响。新架构对软件的挑战:
• 1)支持CPU+FPGA融合并行的计算框架,包括FPGA编译和高层语言设计。
• 2)大规模分布式FPGA资源管理与调度
• 3)高性能FPGA算法库。
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU、DSP、ASIC、FPGA等。
FPGA和GPU/CPU对比具有以下不同:
• 1.软件定义的硬件架构:GPU/CPU硬件固定,其并行性设计是适应固定硬件。而FPGA的硬件逻辑可以通过软件动态改变,从硬件的角度来适配软件,从而获得更高的计算性能。
• 2.更高并行性、能效比:FPGA拥有更丰富的计算资源组件,从而能够满足更多并行计算需求。并且能够充分发掘软件算法中的并行性,降低功耗。
同时,新架构融合CPU+FPGA,将成为一种发展趋势:
• 1. 异构核首次作为一等公民:通过CPU+FPGA的融合设计,由主机+外设的Offloading模式转变为异构多核片上系统设计,CPU与FPGA地位等同,通信方式由板级转向片内。
• 2. OpenCL带来了FPGA的编程革命:提高了FPGA的可编程性,将程序员从复杂的硬件电路设计中解救出来,更专注于系统/算法的设计。
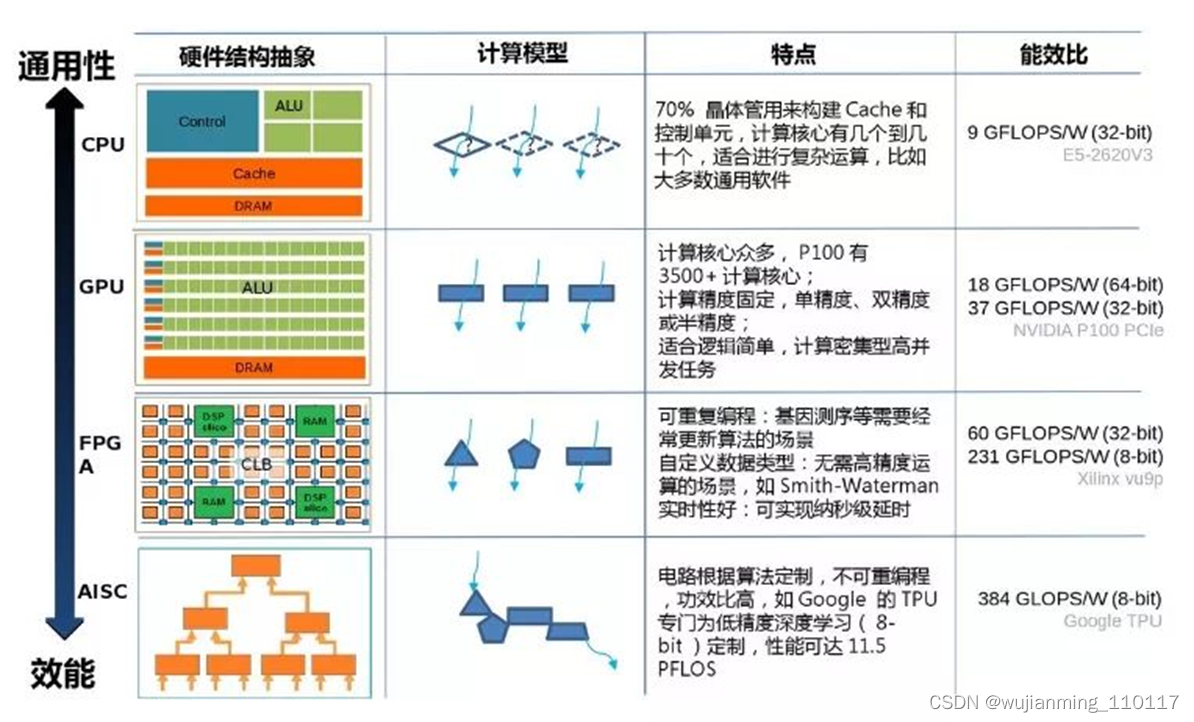
总结:CPU主要是做通用控制以及计算的,整个算术逻辑单元ALU占整个芯片面积不到5%。CPU里面包含很多控制逻辑,预测,Cache等逻辑,所以算力不高,但是什么都能做。
• CPU主要特点:主频高,但核数有限;逻辑控制和算术运算单元、具有大量缓存,主要功能在于管理和调度任务。
GPU专门用来做浮点运算,只能作为协处理器配合CPU完成特定计算。但GPU天然假设所有运算可以并行(GPU具有数千个计算核),整个芯片90%都是运算逻辑。所以算力非常高,通常是CPU的几十上百倍。
• GPU特点:高并发(几千个核并),强浮点能力和高显存带宽。
FPGA主频低但集成大量计算单元,流水线并行和数据并行,具备硬件编程和加速和特定应用IP核。然而,ASIC是针对某一场景优化的专用处理单元,硬件基本不可编程,采用多个IP集成,但有高性价比和能效比。
异构计算,要全面爆发了?
最近来自数据中心三大厂商英特尔、英伟达和AMD三大半导体厂商的消息颇多,无论是AMD收购赛灵思,还是英特尔最近透露的Falcon Shores,再加上去年英伟达所推出的Grace CPU,CPU厂商开始研究GPU、GPU厂商开始研发CPU,这些动作无不是释放一个明显的信号,芯片行业正在向异构架构整合发展。而部分国内厂商也嗅到了这个先机,开始往多架构产品线布局。异构计算,要全面爆发了吗?
三大厂商引领异构计算
异构计算(英语:Heterogeneouscomputing),又称为异质运算,早在80年代中期就产生了,其主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU、DSP、ASIC、FPGA等。目前“CPU+GPU”以及“CPU+FPGA”都是受业界关注的异构计算平台。 现在随着5G、AI、云计算等新兴领域对计算量的需求,已经超过了通用CPU的发展速度,仅通过提升CPU时钟频率和内核数量而提高计算能力的传统方式遇到了散热和能耗瓶颈,所以需要GPU、FPGA、DSP,现在还多了DPU,这些计算单元去配合CPU进行并行计算,大家分工协作,“专人干专事”,以此来很好的满足这些计算需求。 而英特尔、AMD、英伟达三大厂商最近的一些列集中的动作更是把异构计算推上了风口浪尖:
• 英特尔CPU+GPU新架构Falcon Shores
英特尔在最近的投资者会议中提出了一个新架构——Falcon Shores。这是一款将X86和Xe GPU 整合到一个Xeon插槽中的新架构。该架构将利用英特尔埃米时代工艺技术、下一代封装、英特尔正在开发的新型超带宽共享内存以及领先的I/O技术。他们预计,相对于当前平台,Falcon Shores将提供超过5倍的每瓦性能、超过5倍的计算密度增加以及超过5倍的内存容量和带宽提升。据路线图所示,Falcon Shores计划于2024年完成。

(图源:英特尔) 目前英特尔已经有CPU、FPGA、IPU等产品线,现在也投入了运算级GPU的研发,在Intel 投资日上,英特尔谈到了两款GPU产品,分别是面向游戏玩家的Xe-HPG架构Alchemist GPU以及面向数据中心的Xe-HPC架构GPU芯片Ponte Vecchio,后者是MCM(Multi-chip Module)/chiplet形态的GPU芯片。而且近日,AMD独立GPU等项目的首席SoC架构师Rohit Verma也从AMD跳槽到英特尔。英特尔这次GPU的动作可以说计划长远、且非常大。
• 英伟达Grace CPU
2021年4月,英伟达公布了其首款代号为Grace的CPU产品,这是专为人工智能和超算使用需求打造的。该产品采用下一代Arm Neoverse内核,在NVIDIA放出的设计示图中,Grace CPU是以MCM(Multi-Chip Module,多芯片模组)形式构成,包括CPU、GPU、DPU和带有ECC的LPDDR5x的新型高带宽内存子系统,辅以使用 NVLink 通道技术。可以说是专为连接英伟达GPU所设计。据悉,Grace预计在2023年发布。

英伟达的Grace视图不是一个芯片,而是多模块形式(图源:英伟达) 对于英伟达来说,Grace CPU的研发将对其意义深远,使其不必完全受制于AMD和英特尔在CPU上的的合作关系,可以说是自立自强的一个表现。因为即使GPU的并行能力不断提高,但GPU终究在加速运算中扮演资料运算,仍需搭配CPU执行基本的系统,以及由CPU 发号运算的命令,所以GPU和CPU之间的沟通很重要。而x86架构的CPU又受限PCIe频宽的影响,GPU与CPU之间沟通效率很低,无法满足巨量数据传输处理效率需求,此前英伟达为了解决这个问题,研发了高速通道技术NVLink,但合作伙伴只有较冷门的IBM Power,而市场占有率较大的英特尔和AMD都有自身的加速器,自然也不会加入英伟达的支援阵列。 所以英伟达只能另起炉灶,踏上自研CPU之路,借由Arm架构的特性,Grace可让GPU直接存取系统存储资源,让CPU更好的处理其他工作。未来或许能看见更多Arm架构CPU搭配NVIDIA GPU的组合应用。此举也昭示了将Arm架构应用在AI运算及超算领域确实有其发展机会,同时或将吸引更多伺服器业者开始进行Arm布局,扩大Arm架构在手机、嵌入式以外的应用。
• AMD收购赛灵思,补齐FPGA产品线
近日AMD完成了对赛灵思的收购,AMD的CPU和赛灵思的FPGA,未来也将走向CPU+FPGA的异构整合中。因为,这条路英特尔已经趟过,收购了Altera之后,FPGA产品线在英特尔中发挥的不错,2018 年,英特尔宣布将“Skylake”至强SP处理器 Arria 10 FPGA 混合在一个封装中的产品。FPGA在现成CPU 上运行的编程语言和用于实现某些功能或软件堆栈的定制ASIC之间的边界仍然具有吸引力。 总之,收购赛灵思之后,AMD 设计的每个计算设备,无论是单芯片还是封装中的Chiplet集合,都可以在 AMD 认为合适的时候添加一些可编程逻辑。 英特尔向GPU扩展的动作很大,英伟达研究CPU自立自强的决心也很大,气势正旺的AMD有了FPGA也如虎添翼。随着三大厂商逐渐补齐产品线,异构计算或将进入全面爆发。未来,异构计算会越来越多的取代原来通用计算不擅长的部分。
国内芯片厂商跟进
不同于国际大厂在各方面实力雄厚,国内厂商难以在短时间内形成如此全的产品线,但是国产芯片厂商现在已经渐渐开始选择通过投资和合作的方式埋下异构的种子。 2021年11月,GPU芯片企业壁仞科技,与IDG资本、字节跳动等共同参与了国产DPU初创企业云脉芯联数亿元的天使轮投资。据壁仞科技创始人、董事长、CEO张文透露,除了DPU之外,从布局整体计算产业出发,壁仞科技正在密切关注国产CPU的最新发展,未来形成CPU+GPU+DPU的全国产系统级解决方案。 日前,DPU芯片厂商云豹智能与AI芯片厂商燧原科技达成了战略合作,共同研发和提供大规模高性能AI算力平台解决方案。基于云豹智能云霄DPU和燧原科技云燧T20率先推出了DataDirectPathStorage解决方案,为AI训练储存访问提供更高效的解决方案。在传统解决方案中,云燧T20访问存储时,需要将数据先搬移到系统内存,再由系统内存搬移到目标设备。而基于DataDirectPath Storage技术,云燧T20可通过DPU直接获得数据,从而绕过系统内存和CPU,让数据访问速度更快,访问延迟更短,系统开销更小。 此外,国内还有异构处理器IP提供商华夏芯,通过自主设计的Unity统一指令集架构和基于此架构的CPU、DSP、GPU、AI专用处理器系列IP与SoC,在提升性能价格比的同时,显著降低计算芯片研发成本和研发复杂度,同时缩短研发周期,减少开发人员工作量和降低开发门槛。据悉,华夏芯的Unity和英特尔的OneAPI都是为了简化编程环境,但不同的是,OneAPI是面向不同体系架构的统一编程环境,Unity是面向不同微架构的统一体系架构和统一编程环境。
晶圆厂和封装厂在异构集成上的布局
异构计算的强大只有完备的通用计算芯片产品线还不够,还必须要有先进的异构集成封装技术将其巧妙的封装在一起,才能达到最终提升算力的目的。因此,这几年异构集成也重新定义了封装在芯片产业链中的地位,现在封装起到一个重新架构的作用。
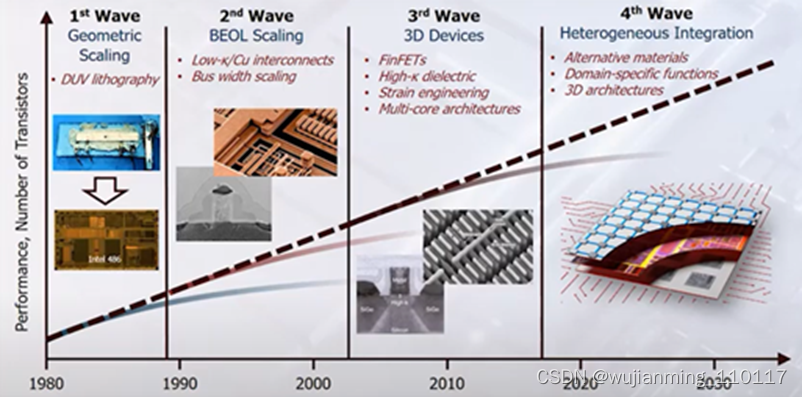
异构集成将是延长摩尔定律的第4波浪潮(图源:ERI summit 2020)
过去,考虑到功耗、性能、成本等因素的影响,芯片的集成首先在单片上进行,例如SoC。但现在摩尔定律逐渐来到极限,在单片上继续微缩,成本效益越发不受控制。而得益于近十年来先进封装与芯片堆叠技术的发展,例如3D堆叠、SiP等,也使得异构集成成为了大幅存在可能。下图显示了先进芯片封装技术的趋势。
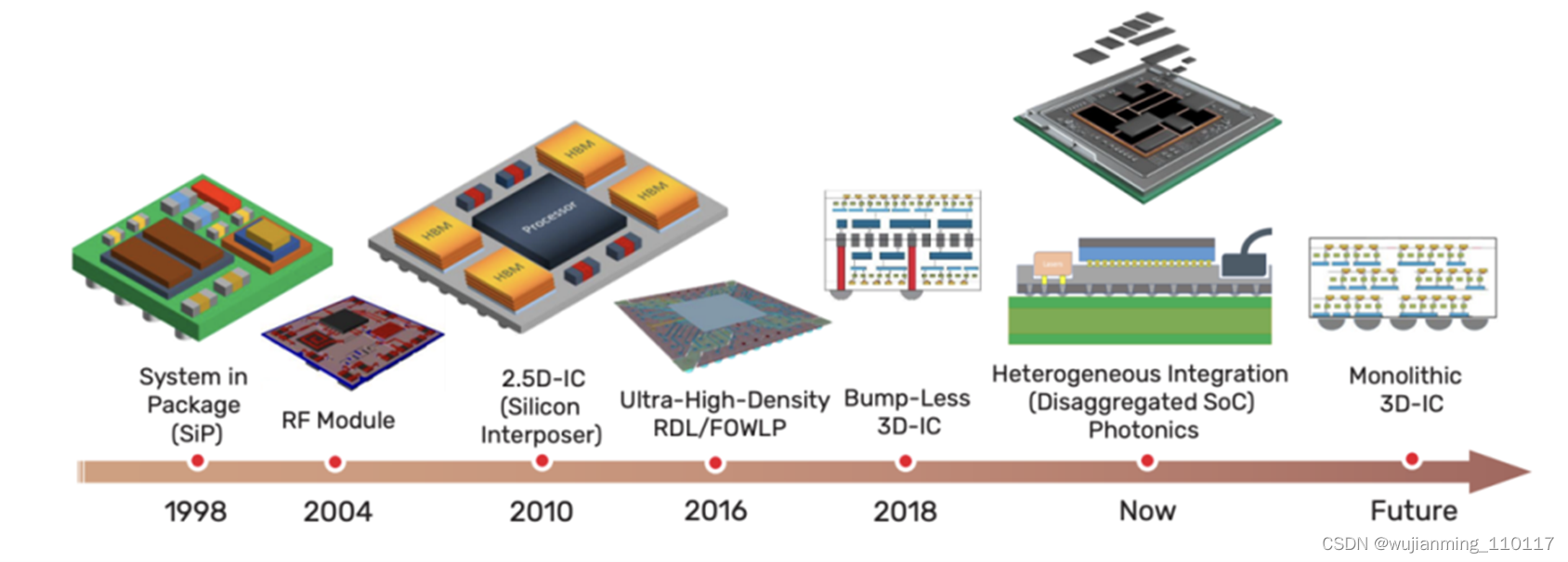
先进多芯片(let)封装技术的演进(图源:Cadence) 异构集成主要是将多个不同工艺节点的芯片封装到一个封装内部,这些芯片可以是不同种类、不同制造商、甚至是不同材料(Si/SiC/GaN)、不同工艺节点(如7nm和28nm等搭配),以此来达到增强功能和提高性能。新的封装技术能够将来自不同制造工艺流程的小芯片集成到具有多种功能的单个封装中。 为此,无论是台积电、三星和英特尔这样的晶圆大厂,还是封装厂,都在积极布局异构集成,在半导体后道技术上做好集成的工作。先进封装逐渐成为集成电路芯片成品制造产业的关键工艺技术之一。
• 三大晶圆厂发力3D先进封装
目前英特尔、三星电子与台积电已具备成熟的2.5D封装经验,如较为人熟知的台积电的CoWos,三星的I-Cube。接下来重点看下3D封装,因为3D封装可以说将异构集成发挥的淋漓尽致。 在3D封装部分,英特尔已量产Foveros技术,其是使用异构堆叠逻辑处理运算,可以把各个逻辑芯片堆叠一起。以往堆叠仅用于存储,现在首度把芯片堆叠从传统的被动硅中介层与堆叠记忆体,扩展到高效能逻辑产品,如CPU、GPU与AI 处理器等。此外,英特尔还研发了三项助于Foveros的技术,分别为Co-EMIB、ODI和MDIO,其中,Co-EMIB 能连接更高的运算性能和能力,并能够让两个或多个Foveros元件互连,设计人员还能够以非常高的频宽和非常低的功耗连接模拟器、存储器和其他模组。ODI技术则为封装中小芯片之间的全方位互连通讯提供了更大的灵活性。顶部芯片可以像EMIB 技术一样与其他小芯片进行通讯,同时还可以像Foveros 技术一样,通过硅通孔(TSV)与下面的底部裸片进行垂直通讯。 近日,英特尔为Aurora 超级计算机提供动力的处理器 Ponte Vecchio,就是一个结合了多个计算、缓存、网络和内存硅片或“小芯片”的封装。封装中的每块tile都是使用不同的工艺技术制成的,这可以说是异构集成的一个鲜明例子。该处理器就使用了Foveros的3D堆叠封装技术和Co-EMIB连接技术。
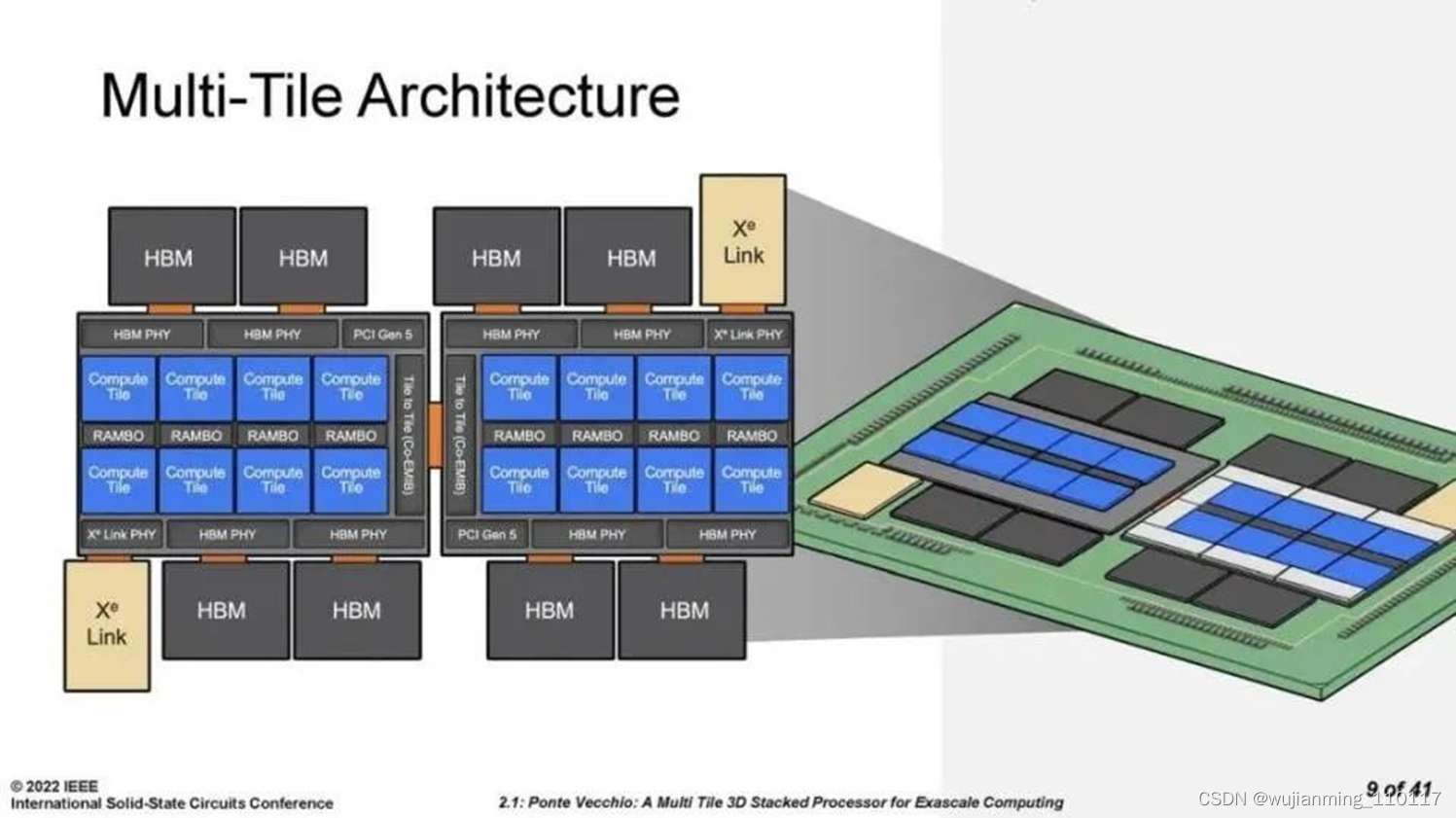
Ponte Vecchio由使用3D和 2D技术连接的多个计算、缓存、I/O 和内存块组成。资料来源:英特尔公司。 三星的3D封装技术是X-Cube,其与英特尔的Foveros 3D堆叠技术路线大致相同。目前三星已经完成了3D堆叠SRAM的验证,此外,三星也提供了一项差异化技术,ISC(集成堆叠电容),这一电容应用了已经在三星DRAM产品中获得验证的硅电容结构、材料和工艺,具有1100nF/mm2的电容密度,可以有效提高电源完整性。三星的ISC还提供了多种不同的配置,比如分立型、硅中介层型和多晶圆堆叠型,以满足客户不同的结构需求,ISC预计将在2022年进入量产阶段。 台积电提出了3D多芯片与系统整合芯片(SoIC)的整合方案。SoIC是将不同尺寸、制程技术,以及材料的已知良好裸片直接堆叠在一起。台积电表示,相较于传统使用微凸块的3D集成电路解决方案,SoIC的凸块密度与速度高出数倍,同时大幅减少功耗。此外,台积电也推出了3D Fabric,3DFabric能协助客户将多个逻辑芯片,甚至串联高频宽记忆体(HBM)或异构小芯片,例如模拟、I/O,以及射频模组连结在一起,联合3D SoIC技术能提供更好的灵活性,透过稳固的芯片互连打造出强大的系统。 从上述三大厂商在3D封装的研究也可以看出,三家都各自提供了异构设计的方法和工具,来帮助设计者克服多出来的接口IP或者潜在的功耗增加,以及多芯片互联的问题等等。
• 封装厂在先进封装上的努力
在异构集成的大势之下,封装厂的作用自然也是重要的一环。在封装领域,我国可谓发展较早,实力相对较强。而系统级封装(System inPackage, SiP)能实现高度集成的微型化系统,整合各种感测器与多样功能的芯片(例如MCU、存储器)等在终端产品之微小空间中,是未来穿戴装置主流封装技术。因此,各家封装厂也在SiP封装上大力布局。 首先是在SiP封装布局已有10年之久的日月光、拿下了苹果的订单后,日月光今年将进入收割元年,而且日月光今年将SiP列为营收中的单独要项。法人表示,日月光SiP目前应用以Wi-Fi整合芯片及指纹辨识芯片为主,产能利用率达满载。预估2022年SiP营收占日月光整体营收比重将达20%以上。 安靠(Amkor)基于衬底的SiP技术在其韩国ATK4光州的最大批量制造工厂应用。去年11月底,据报道,Amkor计划在越南Bac Ninh建立最先进的智能工厂,新工厂的第一阶段将专注于系统级封装 (SiP) 组装和测试解决方案。据Amkor透露,一期建设预计将于 2022 年开始,根据预计的客户产品周期,预计将于 2023 年下半年开始大批量生产。 大陆的封装企业,尤其是中国封测三强(长电、通富、华天)近几年通过自主研发和兼并收购,正在快速积累先进封装技术。例如长电科技旗下长电韩国积极布局高阶SiP封装业务,切入手机和穿戴式装置等终端产品;2016年收购了AMD两家专门从事封装及测试业务子公司的通富微电,也在做SiP的产品,而且公司2021年上半年2.5D/3D封装产品技术已完成立项。 上述这些封装企业主要是针对年产量在10KK左右的SiP封装需求,但除此之外,还有一些专注于细分领域(如工业和医疗等)的异质集成SiP封装厂商,如摩尔精英等,他们主要是解决市场上多样化、小批量的产品设计生产需求。据了解,摩尔精英已经在惠山经济开发区建立自有SiP工厂,所面向的客户主要为年产量1kk左右的产品,摩尔精英SiP一站式服务提供从电路图设计到量产的各个环节。 不过综合来看,IDM与晶圆代工厂商在2.5D、3D等封装技术的发展相对委外半导体封测(OSAT)业者成熟、完整,也具有多年量产经验,所以专业封测厂商不仅要与同业竞争,也要与晶圆代工厂一起竞争。
结语
来到2022年,异构计算大战,一触即发。芯片厂商不遗余力的布局CPU、GPU、FPGA、DPU等计算芯片,放出你争我赶的时间轴,代工厂和封装厂也在铆足劲向异构计算的先进封装布局,不止这些厂商,EDA厂商、半导体设备厂商、材料厂商、测试企业等都在为异构计算的来临做准备,异构计算的发展需要全产业链的共同协作,各产业链成熟起来,才能真正迎来大爆发。
超异构 x Chiplet:双剑合璧,实现算力指数级提升
Chiplet标准UCIe已经得到很多主流大厂的认可,席卷之势愈发明显。但就Chiplet的价值挖掘,目前可见的,都还停留在如何降成本和简单地扩大设计规模方面。我们觉得,Chiplet的价值还没有得到充分挖掘。
Chiplet带来的价值,不应该是线性增长,而应该是指数增长:
• 一方面,量变会引起质变,Chiplet的流行,快速增加的单芯片设计规模,会给系统架构创新提供更大的发挥空间,使得计算的架构,从异构走向超异构。
• 另一方面,超异构带来的算力指数级提升,使得Chiplet的价值得到更加充分的发挥,反过来会促进Chiplet的大范围流行。
01 背景知识
1.1 单DIE性能和成本
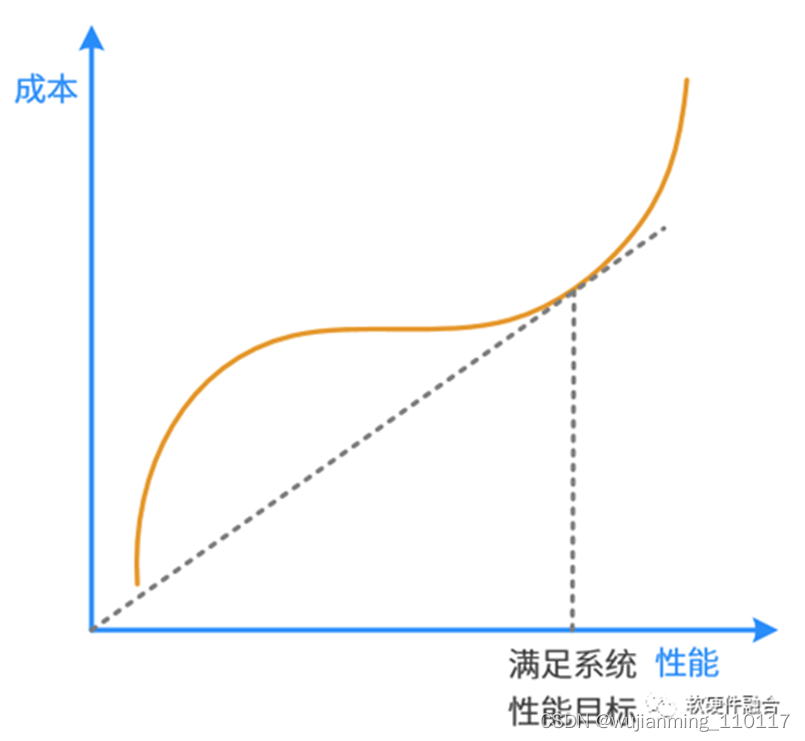
单DIE的性能和成本,是正相关的关系。通常的芯片DIE设计,一定是在保证系统所需性能的条件下,选择最合适的工艺,达到最合适的面积(成本),达到在性能约束条件下的性能成本比最优。或者说:
• 在系统性能成本最优的状态下,受边际效应影响,想再想增加单DIE性能,所需要付出的成本代价非常高,会显著影响性价比。
• 在系统性能成本最优的状态下,想要再优化单DIE成本,可能会引起性能的大比例下降,反而不是性价比最优。
1.2 Chiplet协议UCIe
英特尔、AMD、ARM、高通、三星、台积电、日月光等大厂,以及Google Cloud、Meta、微软于2022年3月2日宣布了一项新技术标准UCIe(Universal Chiplet Interconnect Express)。UCIe是一个开放的行业互连标准,可以实现小芯片之间的封装级互连,具有高带宽、低延迟、经济节能的优点。
UCIe能够满足几乎所有计算领域,包括云端、边缘端、企业、5G、汽车、高性能计算和移动设备等,对算力、内存、存储和互连不断增长的需求。UCIe 具有封装集成不同Die的能力,这些Die可以来自不同的晶圆厂、采用不同的设计和封装方式。

UCIe白皮书中给出的Chiplets封装集成的价值:
• 首先是面积的影响。为了满足不断增长的性能需求,芯片面积增加,有些设计甚至会超出掩模版面积的限制。即使不超过面积限制,改用多个小芯片也更有利于提升良率。另外,多个相同Die的集成封装能够适用于更大规模的场景。
• 另一个价值体现在降低成本。例如,处理器核心可以采用先进的工艺,用更高的成本换取极致的性能,而内存和I/O控制器则可以复用非先进工艺。随着工艺节点的进步,成本增长非常迅速。若采用多Die集成模式,有些Die的功能不变,我们不必对其采用先进工艺,可在节省成本的同时快速抢占市场。Chiplet封装集成模式还可以使用户能够自主选择Die的数量和类型。例如,用户可以根据需求挑选任意数量的计算、内存和I/O Die,并无需进行Die的定制设计,可降低产品的SKU成本。
• 允许厂商能够以快速且经济的方式提供定制解决方案。如图1所示,不同的应用场景可能需要不同的计算加速能力,但可以使用同一种核心、内存和I/O。Chiplet方式允许厂商根据功能需求对不同的功能单元应用不同的工艺节点,并实现共同封装。相比板级互连,封装级互连具有线长更短、布线更紧密的优点。
1.3 超异构计算
系统变得越来越庞大,系统可以分解成很多个子系统,子系统的规模已经达到传统单系统的规模。因此,都升级一下:系统变成了宏系统,子系统变成了系统。
系统足够庞大,场景综合,单类型架构无法包打天下:
• CPU灵活性最好,但性能较差;
• DSA性能很好,但灵活性差;
• GPU介于两者之间,可以说能较好的平衡性能和灵活性,也可以说,性能和灵活性都不够极致。
规模庞大的复杂系统存在很多硬件加速的空间:
• 复杂系统最核心的一个特征是二八定律。用户只关心自己的应用,而应用通常只占系统的20%,另外80%用户不关心的也相对确定的部分,一般称为基础设施,这些是可以通过硬件加速来优化性能的。
• 系统是逐步发展和沉淀的。很多原本属于应用层的工作任务,随着时间推移,越来越成熟,逐渐地沉淀成了基础设施。这些沉淀的工作任务可以通过硬件加速来优化性能。最典型的场景是AI推理,现在已经成为了基础的服务,供不同的应用调用。
• 在云计算、边缘计算等形式的综合计算模式下,单个用户应用的规模可能不大,但因为云计算的超大规模和多租户,很多相似的用户应用其总和规模足够庞大,因此,也可以通过GPU、FPGA或专用芯片的方式进行加速优化。
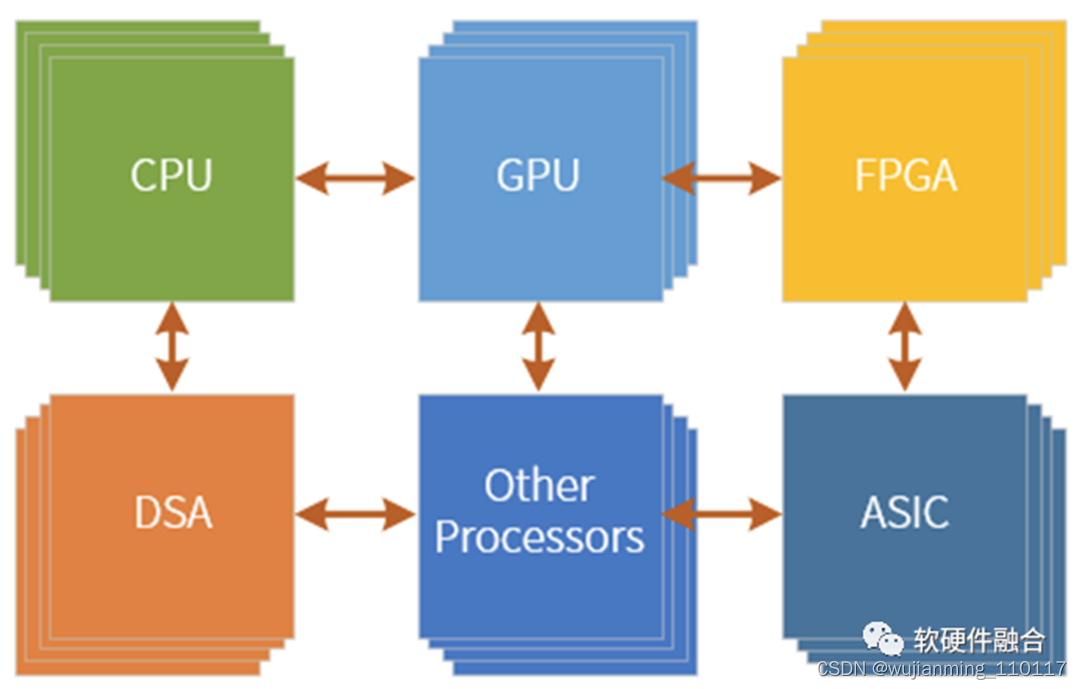
那么,要做的就是扬长避短,把不同类型的处理引擎协作起来,把各种引擎的优势充分利用起来,形成超异构计算架构:
• DSA负责相对确定的大计算量的工作;
• GPU负责应用层有一些性能敏感的并且有一定弹性的工作;
• CPU啥都能干,负责兜底。
于是整个系统架构就变成了超异构架构。
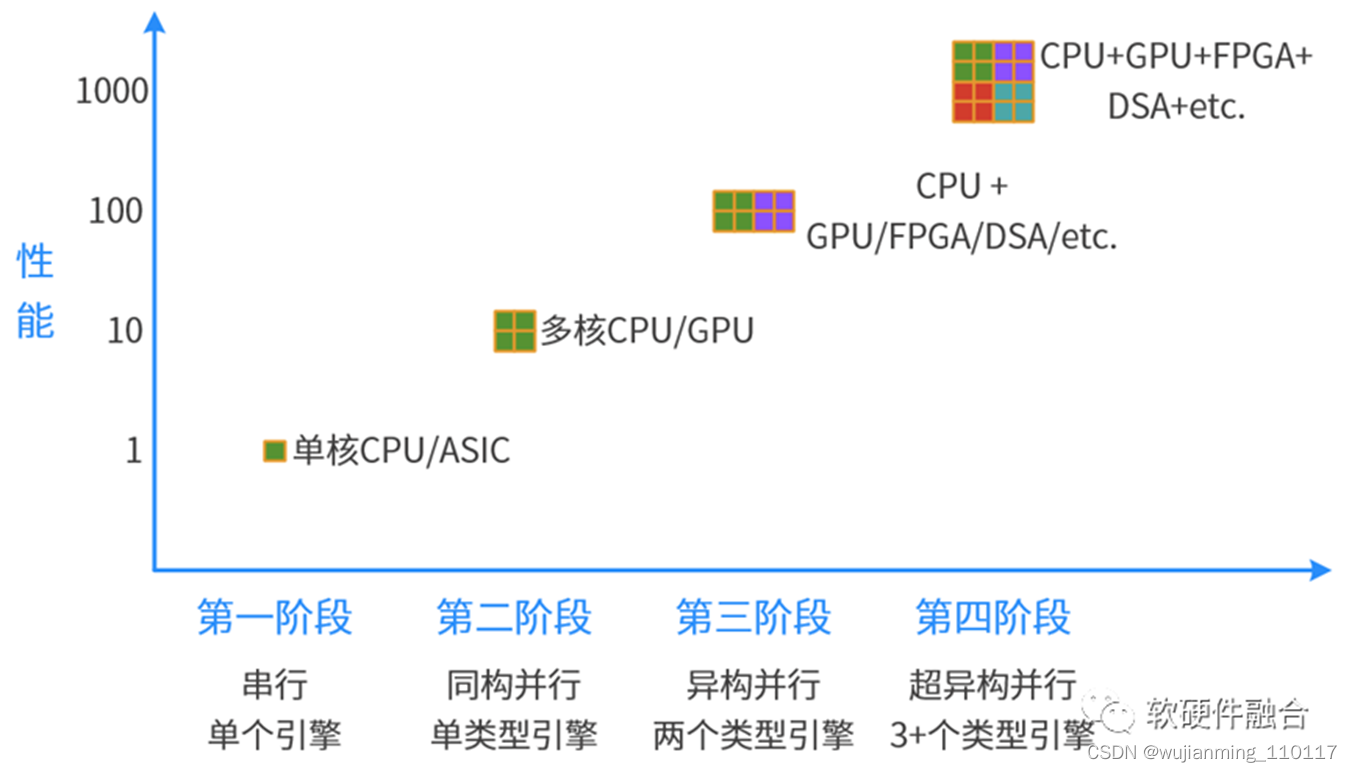
总结一下计算架构发展的四个阶段:
• 第一阶段,单CPU串行计算;
• 第二极端,多核CPU的并行计算;
• 第三阶段,CPU+xPU的异构计算;
• 第四阶段,CPU+GPU+DSA+etc.的超异构计算。
02 Chiplet技术方案
2.1 方案1:设计规模不变,优化单DIE面积和良率等
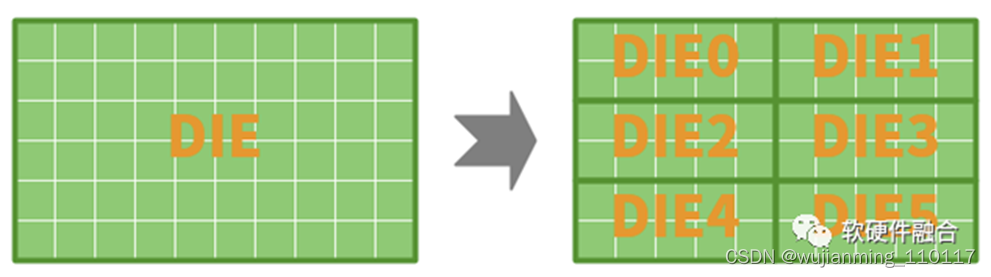
一般情况下,在同等工艺同等功耗技术下,我们可以简单地认为,面积和成本成正比的。Chiplet实现用面积更小的DIE,实现同等规模设计,其优势主要为:
单DIE面积变小,增加芯片良率。而通常,单DIE的面积是已经平衡好良率的情况下的,再减小面积优化良率,可能效果并不是很明显。并且,多DIE封装会带来额外的良率风险。这样,一里一外的问题,通过多DIE来优化良率的效果可能就不会很明显。
• 可以让一些DIE不采用先进工艺,通过较低一些的工艺降低成本。
在不改变性能的条件下,通过Chiplet封装可以降低成本;也可以反过来说,在同样成本条件下,通过Chiplet封装可以提升性能。
2.2 方案2:单DIE设计规模不变,多DIE集成
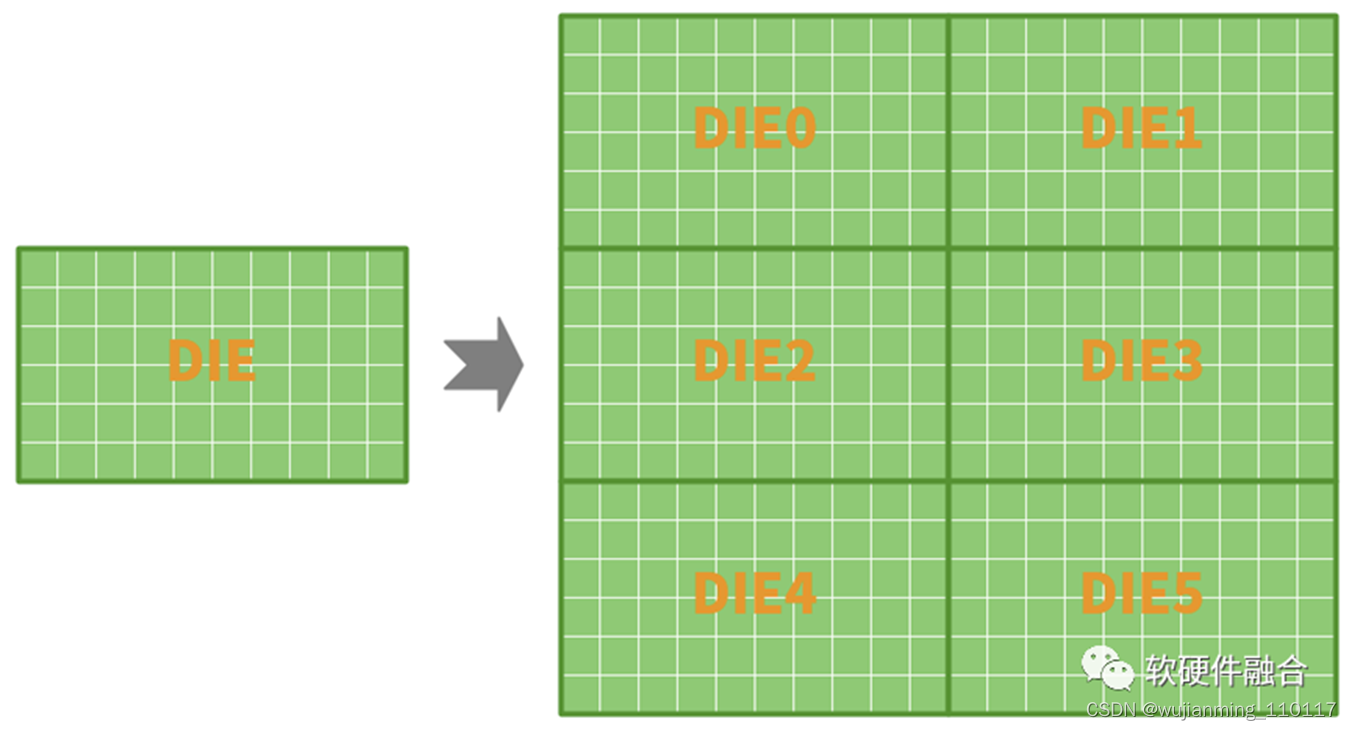
当我们确定好单个DIE的性能和面积(功耗)的时候,这个时候相当于是把工艺的价值挖掘到了最优。需要Chiplet的价值,也同样需要工艺的价值,都不能少。
我们要做的是在工艺价值的基础上,再叠加Chiplet封装的价值。而不是如方案1一样,为了Chiplet而Chiplet,反而放弃工艺的价值。
因此,我们可以在原有DIE的基础上,通过多DIE封装来立竿见影地提升性能。
2.3 方案3:多DIE集成设计规模倍增,并且重构系统
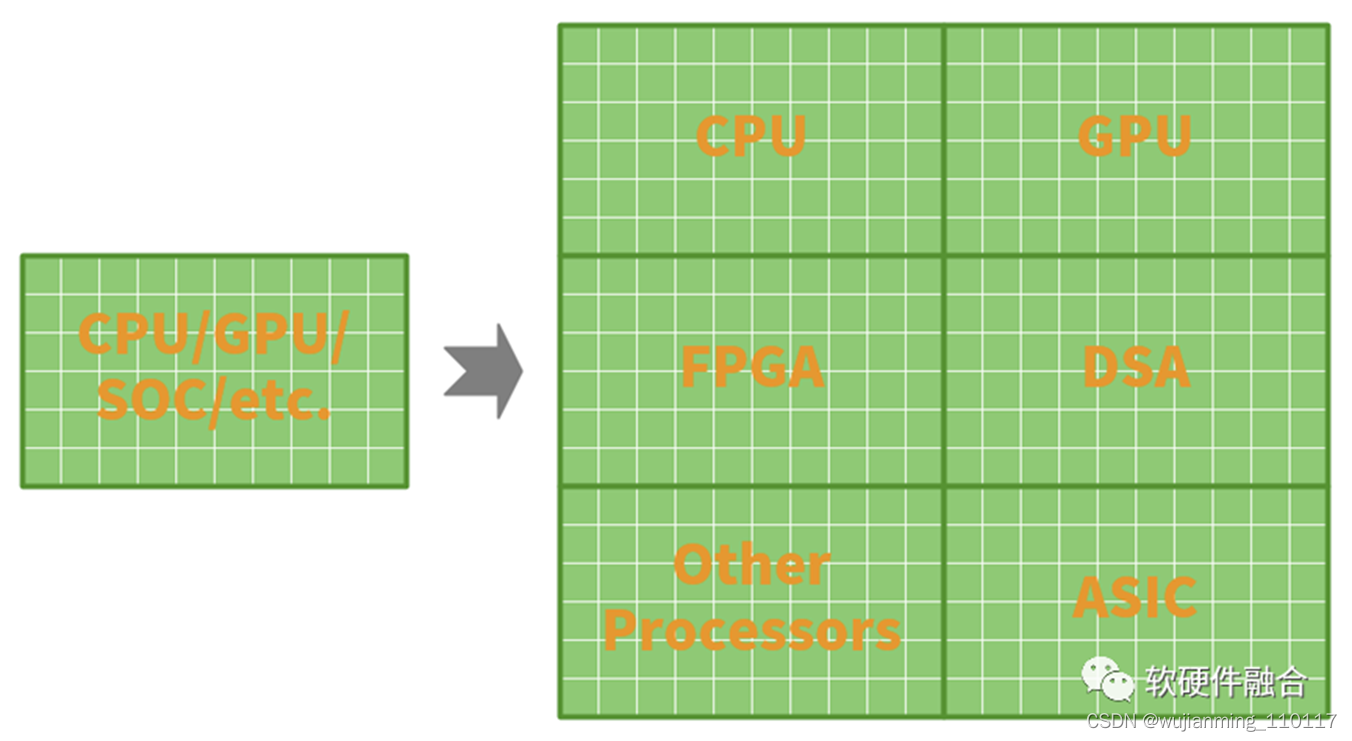
通常,CPU组成的芯片,性能不够;而GPU、DSA组成的芯片无法单独工作,需要外挂CPU,形成CPU+XPU的异构计算架构;而SOC本质上是CPU+xPU的多个异构系统的集成。
异构计算和SOC,本质上都是以CPU为中心的系统,XPU是一个个孤岛,所有的事情都需要CPU的参与才能把这些处理引串起来。
超异构完全打破不同处理引擎之间的界限,CPU和其他XPU同样的地位,XPU间可以非常充分的交互,达到系统充分的整合。超异构计算可以做到:
性能和灵活性兼顾。因为二八定律的缘故,绝大部分计算是在DSA级别的处理引擎中完成,所以性能效率很好。而用户关心的应用依然是在CPU级别的处理引擎完成,又兼顾了灵活可编程性。
• 因为超异构计算架构可以驾驭更大的系统,因此,可以做到,在性能效率和DSA同量级的情况下,性能相比DSA再数量级的提升。
2.4 方案性能提升对比
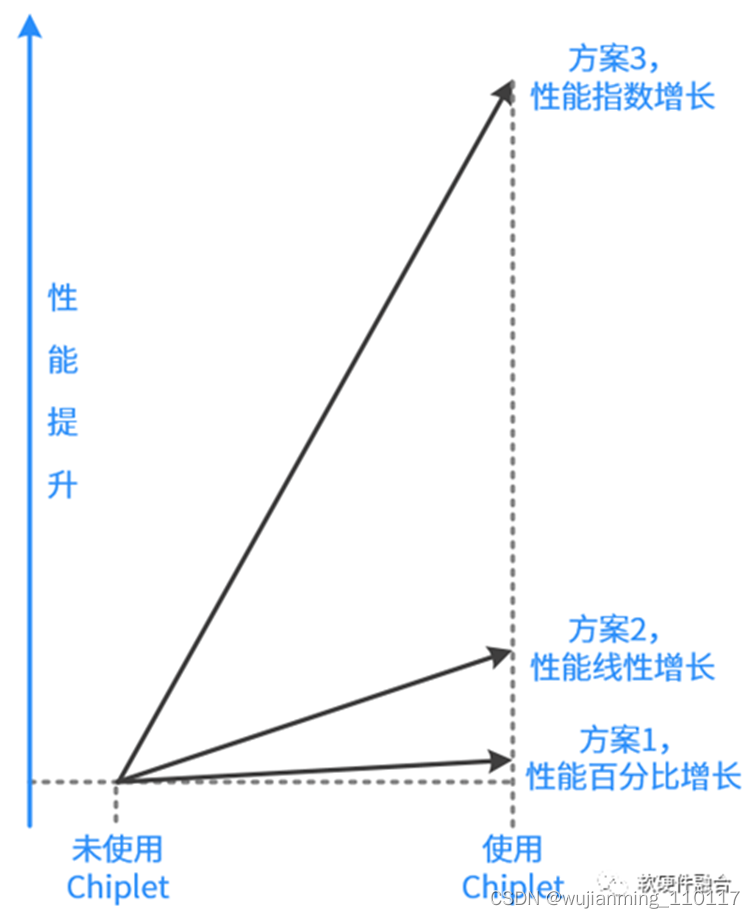
注意:本节内容是定性分析,还无法做到定量分析。
方案1,可以实现性能的百分比增长。方案1的道理很好理解,本来的目标是优化成本,在同等性能情况下,能够百分比地优化成本。我们相应地折算一下,在同等成本下,方案1可以做到性能的百分比提升。
方案2,可以实现性能的线性增长。方案2也很好理解,通过增加更多数量的DIE来提升并行度,以此来提升性能。集成多少个DIE,性能就增加到多少倍。
方案3,可以实现性能的指数增长。方案3通过整个系统重构,挖掘系统的一些可加速的点,然后再实现整个系统的充分整合重构。以此来提升性能。可以达到数量级的性能增长。
03 总结
3.1 设计规模的量变,引起系统架构的质变
规模是一个很重要的因素。
云计算百万台的超大规模,其软硬件架构和运营模式跟传统的数百台的私有机房是完全迥异的。深度神经网络,通过更大量数据、更深层次网络的量变,成就了AI的“智”变。
芯片也是同样的道理,随着规模的增长,很多设计方案考虑的问题会跟以前完全不一样。在小规模的时候,我们强调定制,极度优化性能和功耗等;但等到超大规模IC设计,我们更多关注的是通用性、可编程性、易用性、生态等。
Chiplet机制,提供了立竿见影让芯片设计规模数量级增加的能力。如果我们不在系统架构层次创新,充分利用芯片规模数量级增加的这个优势,只是简单的平行扩展,那真是暴殄天物,浪费Chiplet给系统架构师们的馈赠。
换个角度,现有的异构计算也好,SOC也好,无法驾驭Chiplet提供的超大规模芯片系统。需要本质的、体系性的系统架构创新,来更好地驾驭Chiplet的价值。
3.2 超异构,让Chiplet价值得到更大的发挥
超异构集成更多的处理引擎,提供更高的并行性,实现更分布式的系统,可以更好地驾驭数量级增加的芯片设计规模。
此外,Chiplet更好地容纳现有宏系统的承载,通过超异构,使得很多性能优化措施得到落实,从而使得性能指数级增长(而不是根据面积的增加,线性增长)。
可以说,超异构,成就了Chiplet更大的价值,使得Chiplet方案得到更大范围的落地,促进Chiplet技术的成熟和市场繁荣。
3.3 Chiplet和超异构的关系:双剑合璧,相互成就
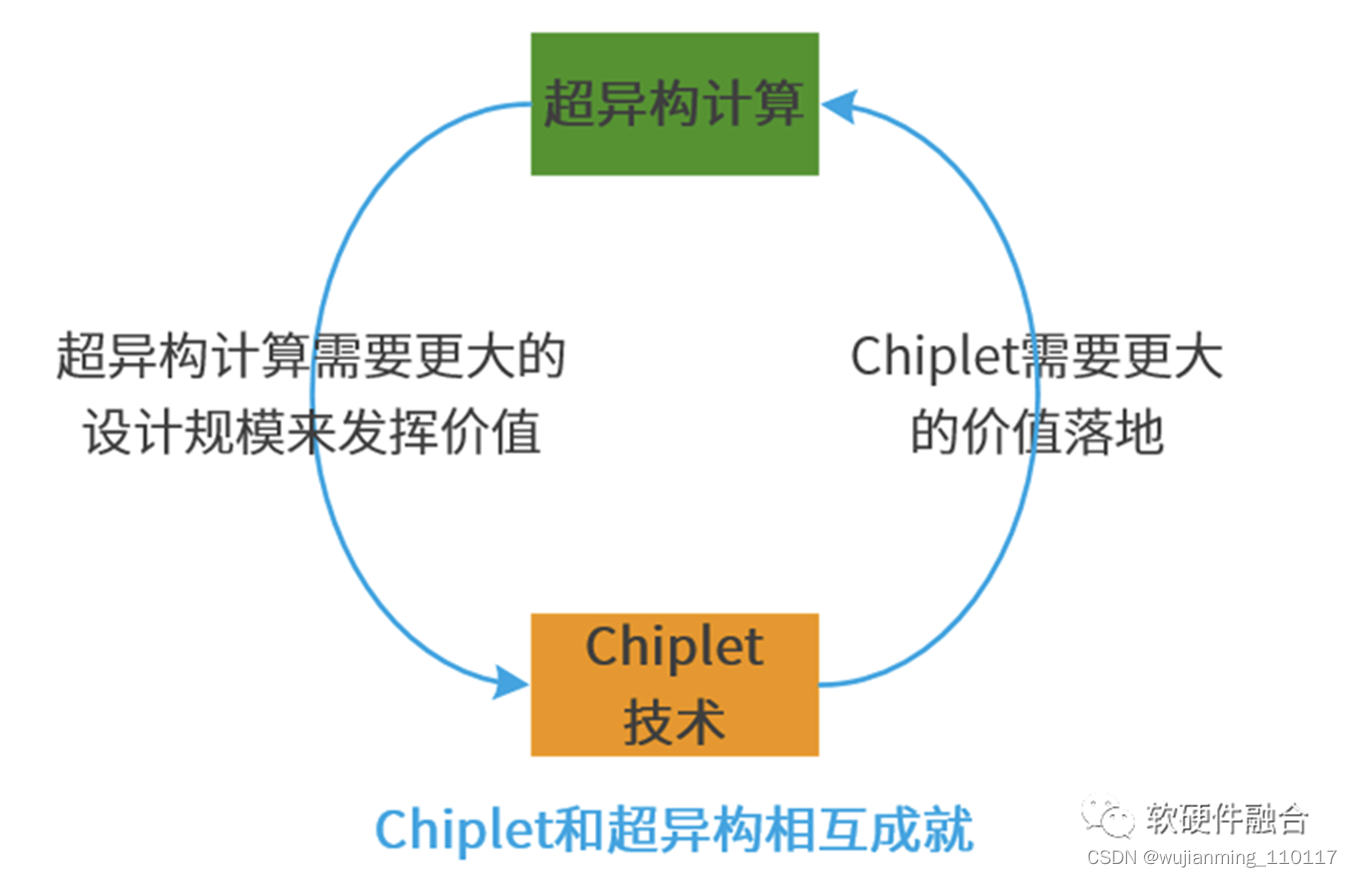
超异构计算和Chiplet技术是相互协同、相互成就的关系:
系统越大,设计规模越大,超异构的性能优势就越明显。
• 超异构计算,需要数量级提升的晶体管资源,而Chiplet可以在芯片层次提供如此规模的晶体管资源,实现超异构计算方案和价值落地。
• 超异构计算的价值得到充分体现,超异构不断落地,会带动Chiplet的价值发挥、更广泛的落地以及市场繁荣。
• 随着超异构的发展,对Chiplet的要求会不断提高,需要Chiplet技术向更高的能力迈进。
异构计算三驾马车
无论是以数据中心和云计算为代表的高性能计算应用,还是以手机为代表的消费类应用,对处理器算力的需求越来越高,且要处理的信息也越来越复杂,单一类型和架构的处理器已经无法胜任。既要保证算力和性能,又要具备多类型任务的处理能力,还要控制好功耗和成本。能满足以上这些要求的,只能通过异构计算来实现,也就是在一个处理器系统内,需要集成如CPU、GPU、FPGA、AI、通信总线和接口等多种功能模块。
目前来看,高性能计算领域对异构计算的需求最为迫切,近些年,行业三大处理器厂商英特尔、AMD和英伟达都在基于自身的技术和产品优势,不断扩充技术和产品边界,以满足数据中心和云计算对异构处理器的需求。
英伟达凭借其GPU在AI训练方面的先天优势,在数据中心AI应用方面如鱼得水,但要想拓展更广阔的市场,只靠GPU还是不够,因此,英伟达一直在觊觎由英特尔和AMD统治的CPU市场,且动作频频。英特尔与英伟达正相反,其CPU具有绝对统治力,但在高性能GPU方面落后太多,近两年也在大力投入独立GPU显卡业务,以补齐短板。AMD则介于两者之间,CPU和GPU技术和产品相对均衡,且随着近几年技术和产品力的提升,市占率和营收打着滚地向上升,弄得英特尔如坐针毡,不过,AMD并没有满足于已经拥有的良好发展势头,要在CPU和GPU之外,再开辟出一片更广阔的天地,将异构计算进行到底。
风云再起
近期,这三大处理器厂商又在异构计算方面动作频频,例如,英伟达迫切想要收购Arm,就是补上服务器CPU这一课,但因为涉及面太广,收购Arm没有成功。与英伟达相比,AMD收购赛灵思则顺利得多,目前已经基本完成,其目的就是要补上FPGA这一课。英特尔则于近期发布了新的处理器发展路线图,其中包括CPU和GPU的融合发展。
这三大处理器厂商的行动有望把异构计算推向一个新的发展阶段。
• 英伟达失去Arm了?
在宣布收购Arm之前,英伟达就已经在进行Arm架构CPU的研发了,且一直在延续。
近期,英伟达首席执行官黄仁勋(Jensen Huang)表示,关于Arm,该公司仍然雄心勃勃,有很宏伟的计划,为从数据中心到机器人技术的各种应用创建一个完整的基于Arm的CPU产品组合。
据悉,该公司进行着多个Arm项目,例如即将进入自动驾驶汽车,工业自动化等的新Orin SoC。黄仁勋表示,英伟达围绕 Arm 架构进行了大量的CPU开发,过去几年,Arm在超大规模企业和数据中心稳步发展。这促使该公司加速高端CPU的开发。
在开发Arm 架构处理器的同时,英伟达仍然会继续支持x86 CPU平台,因为这毕竟是市场的主流产品。
对于异构计算,黄仁勋表示,英伟达将横跨CPU,GPU和DPU的三芯片战略。另外,无论是x86还是Arm,都将开发出最好的CPU产品。英伟达将与计算机行业的合作伙伴一起,提供世界上最好的计算平台,以应对这个时代最具影响力的挑战。
据悉,英伟达有望于2023上半年推出基于Arm的Grace CPU,用于大型AI和高性能工作负载。而Grace只是个开始,之后还会有一系列产品推出。黄仁勋表示,该公司将把Arm CPU融入起加速计算平台的全系列方案当中,也就是说,英伟达的目标是将Arm 架构CPU全面融入其GPU方案当中。今后几年,英伟达GPU+CPU融合发展的策略或将越来越清晰。
• AMD紧追不舍
在三大处理器厂商当中,无论是规模还是营收,AMD都逊于英特尔和英伟达,因此,该公司正在借助近几年强劲的上升势头,缩小与两大竞争对手的差距。
近期,AMD完成了对赛灵思的收购,实际上,在宣布收购后者之前,AMD早就获得了其相关授权,一直将赛灵思的IP与其处理器紧密结合,相关研发正在进行当中,预计将在2023年推出首款融合产品。
收购赛灵思肯定是为了应对高性能计算市场的增长需求。目前,与赛灵思相比,AMD擅长服务器CPU,还有一系列数据中心用GPU,而赛灵思在SmartNIC、AI推理和AI分析方面有不少IP资源、技术和产品。合并后,AMD就在与Marvell、英特尔和英伟达的竞争中增加了砝码,特别是在AI推理方面,赛灵思能进一步强化AMD的竞争力。另外,AMD也正在数据中心GPU的AI训练市场发力,这方面,其与英伟达有较大差距,而赛灵思的AI软件堆栈更加成熟,这将为AMD GPU带来急需的软件资源和技术。
• 英特尔的CPU+GPU融合又进一步
当下,超级计算机使用通用CPU来运行需要强大单线程性能的工作负载,以及用于高度并行工作负载的计算 GPU 加速器。目前,这种架构已被证明在性能、功耗和成本方面是平衡的。在此基础上,CPU和GPU资源的更紧密集成将进一步提高性能,并使更多的工作负载能够访问加速计算。
在高性能计算领域,英特尔强在CPU,而GPU显然是短板。因此,该公司正在不遗余力地开发高性能GPU,并将其与CPU融合,以提升计算效率。
最近,英特尔发布了代号为Falcon Shores的新架构设计,它将通用x86处理器内核和Xe-HPC GPU内核整合到一个Xeon插槽中,该公司还为此开发了共享高带宽内存。该产品预计将于2024年上市。
Falcon Shores的特点就是利用下一代封装、内存和IO技术,为计算大型数据集和训练巨型AI模型的系统提供强大的性能和效率改进。

实际上,Falcon Shores就是整合了CPU和GPU的XPU,它使用了MCM(多芯片模块)封装形式,可以根据应用灵活调整x86和Xe-HPC的内核比例。CPU和GPU将使用统一的高带宽内存(英特尔开发的一种全新类型内存)来提高性能并大大简化GPU编程。
结语
综上,高性能计算处理器三强正在异构计算研发上持续发力,以争取实现CPU、GPU、FPGA、AI等更好的融合。
然而,要实现以上目标,除了在芯片设计层面实现突破之外,芯片制造、制程和封装才是将理念化为实际产品的关键。在这方面,传统IDM英特尔似乎更具优势,而AMD原本也是IDM,只是后来将芯片制造业务剥离出去了,实际上,该公司依然具备制程和封装的基因。而相对而言,英伟达是一家纯粹的Fabless,在制程和封装方面对合作伙伴的依赖度更高一些。
过去几年,AMD因其率先推向市场的chiplet和互连技术而占得了先机,在此基础上,该公司推出了新一代封装技术,也就是3D堆叠V-Cache。在这方面,赛灵思也可以为AMD提供帮助,因为赛灵思已经为其自适应FPGA平台构建了一系列高性能封装和互连技术。
据悉,英特尔的Falcon Shores架构可能要依赖其Intel 20A或Intel 18A制程工艺去实现,并使用该公司自研的高级封装技术进行整合。
英特尔表示,Falcon Shores将是该公司到2027年实现ZettaFLOPS级超级计算机目标的关键步骤。为了在5年内将超级计算机的性能提高1000倍,英特尔将需要新的处理架构(即x86和Xe架构的改进与融合),新的工艺技术和先进的封装方法,更快的内存和I/O接口,以及新的系统架构。
对于英伟达而言,异构整合的推进,在制程和封装方面会略逊于英特尔和AMD,不仅在高性能应用领域,消费级GPU也有体现,例如,英特尔希望Meteor Lake通过集成GPU解决方案提供类似于独立显卡的性能,发烧友细分市场还将有独立的GPU,这将与英伟达的Ada Lovelace(RTX 40系列)和AMD 的RDNA 3(RX 7000系列)GPU方案竞争。这里,AMD可能会将RDNA 3 GPU集成到其CPU中(采用3D芯片堆叠封装),英特尔也有类似的自研方案。然而,目前英伟达还没有与那两家竞争的解决方案。虽说英伟达也在发展采用MCM封装的GPU方案,但其异构属性不强,至少还没有将x86架构CPU融入进去,这或许就是该公司努力追求Arm,并已进行多年Arm架构CPU研发的一个原因,因为英伟达先天不具备x86基因,预计Arm才能帮助该公司实现真正的异构计算。
参考文献链接
https://mp.weixin.qq.com/s/xW_Y0JBKK3d42IZvHA9CrQ
https://mp.weixin.qq.com/s/amQj0DYvs9QwIuTpsGEFNg
https://mp.weixin.qq.com/s/Y2cRAHnztWw5l0eeU_pDrg
https://mp.weixin.qq.com/s/WyVgGB8-dPl9L68cppUNaw