点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:票风 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/536658399
【文章信息】

Active Learning for Point Cloud Semantic Segmentation via Spatial-Structural Diversity Reasoning
Feifei Shao , Yawei Luo, Ping Liu, Jie Chen , Yi Yang, Yulei Lu, Jun Xiao (ACM MM2022)
论文:https://arxiv.org/abs/2202.12588
code:https://github.com/shaofeifei11/SSDR-AL
【任务介绍】
由于标注一个完整的点云数据集,需要大量人力物力财力。主动学习方法(Active Learning)可以迭代地帮助模型挑选出少量最有价值的数据进行标注,同时这些标注的少量数据可以满足模型的正常训练。用一句话概况就是:用最少的标注成本,标注出最有价值的数据来满足模型的正常训练。
本文将每个独立的点云场景划分为一个个超点区域,每个超点区域大致只包含同一类别的点。
本文主动学习方法具体步骤如下:
随机选择带标签的少量超点样本,训练出一个点云语义分割模型(Randlanet)
利用新训练好的点云语义分割模型去预测其他没有标签的超点,挑出一部分最有价值的未标注的超点
设定具体的标注成本预算,不断的去标注(2)中得到的一部分最有价值的未标注的超点,直到本次标注成本预算消耗完
利用所有标注过的超点去重新训练点云语义分割模型
跳回到(2),直到满足退出条件
最终比较各个主动学习方法在消耗相同的总标注成本的情况下,谁最终训练的点云语义分割模型性能好,就表示谁挑选和标注的超点更具有价值,就代表谁的主动学习方法更好。
【本文动机】

本文指出现有主动学习方法在点云场景中挑选超点样本的方法忽略了超点样本的空间位置和形状的多样性,并提出了一种利用图推理的方法增加被挑选样本的空间结构多样性。除此之外,本文还指出之前方法常用的主导标注(Dominant Labeling)策略容易将超点样本中的少量其他类别的点标注上错误的类别标签,并提出了一种新的噪声感知迭代标注策略。该策略可以识别和丢弃每个超点样本中少量其他类别的点,只标注剩下相同类别的点,进而使得标注后的样本数据不存在噪声标签。
【本文方法】
挑选空间结构多样性的超点
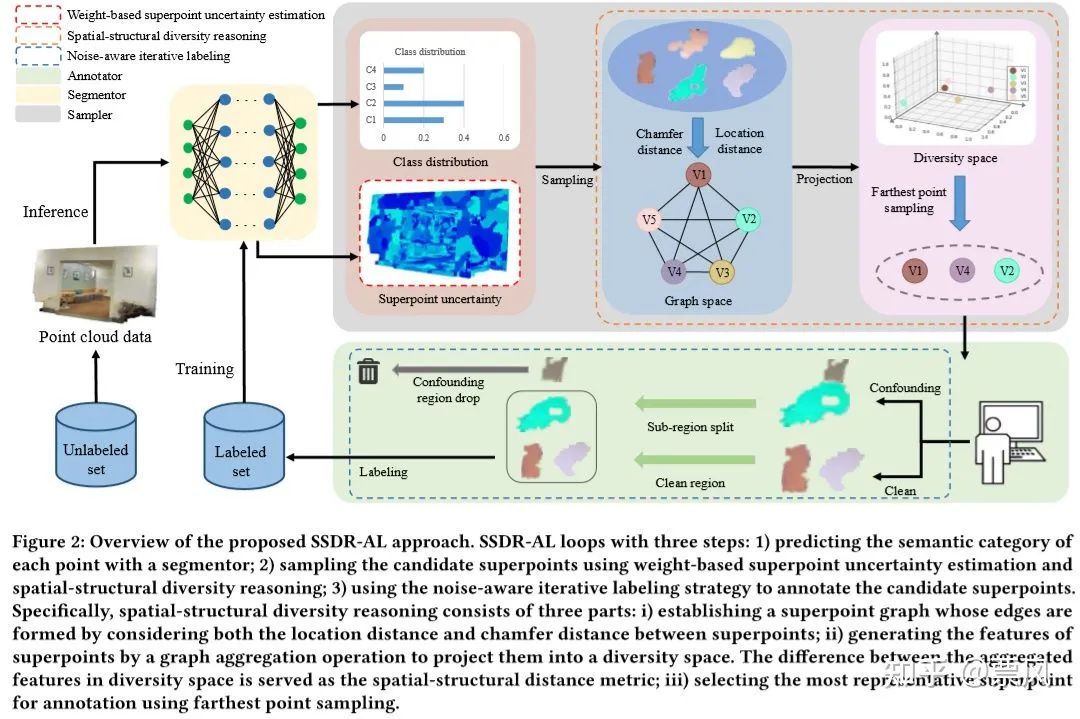
利用语义分割模型预测未标注超点的不确定性,同时得出超点的类别分布并将其作为权重用于挑选构建超点图所需要的超点;
(1.1)得出点point p的不确定性
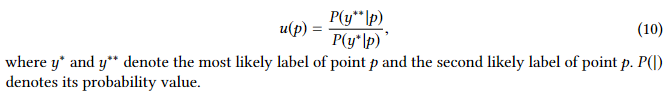
(1.2)得出超点superpoint v的不确定性
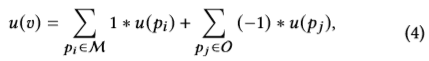
M 表示一个超点中大多数预测类别相同的点point的集合, O 表示一个超点中其他点point的集合
(1.3)得出超点的预测类别分布并将其作为一个权重
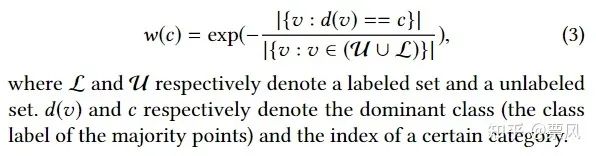
2. 由(1)中挑选出一部分超点构建超点图,超点为图节点,图的边由两个节点之间的的空间距离和倒角距离组成;
(2.1)挑选未标注超点 v* ,用于构建超点图
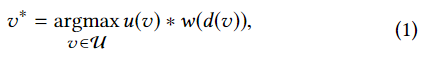
(2.2)计算超点图节点(超点)v 的特征 fvi
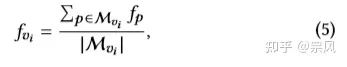
(2.3)计算超点图的边权重 δ (vi, vj)
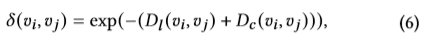
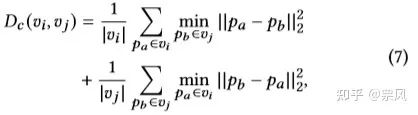
其中 Dl 是两节点的欧式距离, Dc 是两超点的chamfer distance。
3. 通过图聚合推理操作将超点从图空间投影到多样性空间;
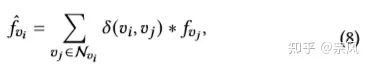
通过聚合操作,会让各个超点形成多个分布,每个分布里面的超点距离相近,形状相似。
4. 在多样性空间中采用最远点采样,挑选出一组空间结构多样性最强的超点集合。即对 fvi 采用最远点采样,得到一批未标注的候选超点(视为最有价值的超点)用于后续的标注。
噪声感知迭代标注策略
因为每个超点superpoint很可能包含多个类别的点point,之前方法(dominant labeling)是把大多数点的类别作为超点中所有点的类别。这就导致超点的小部分其他类别的点存在噪声标签。因此,我们提出一个噪声感知迭代标注策略来感知每个超点中的这一小部分其他类别的点,然后将他们进行拆分且分开标注。

每个超点的纯度 φ(v)为该超点v中大多数相同类别的点的占比。如果超点的纯度较低,我们再根据超点中各个点的类别进行split拆分,得到一个sub-region 集合,然后再根据sub-region的纯度判断是标注还是丢弃。
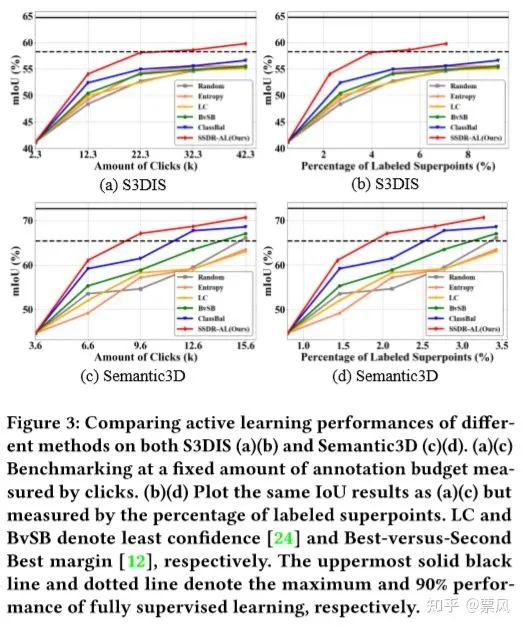
【实验结果】
与其他方法比较
最终本文提出的方法在S3DIS和Semantic3D数据集上获得了SOTA的性能。
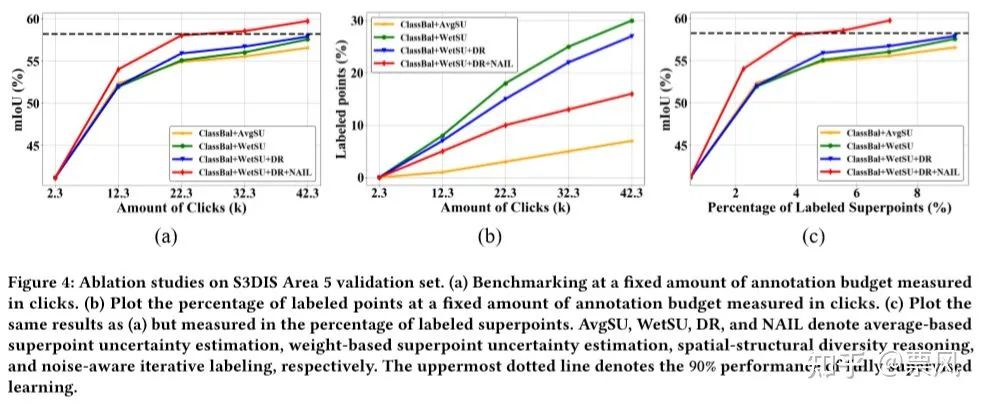
消融实验
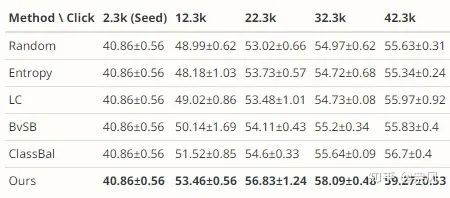
鲁棒性分析(下一版本中更新)
在S3DIS数据集上使用多个seed的实验结果
2. 在S3DIS数据集上使用PointNet++点云语义分割模型

点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看