今天和大家聊一聊知识图谱,NLP领域相对独立的方向。
过去,有同学把它视为AI的“天坑”之一,因为知识图谱技术栈比较长,如果要掌握所有技术,入门时间会很长,而且往往抓不住重点。
下面我分享一下自己对图谱的理解,以及一些实用的入门资料,希望能对你的学习有帮助!
1 什么是知识图谱?
通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。
比如我想去买车,往往会对比品牌、价格、性能、排量等各方面因素。假如我现在看中了奥迪,想知道“奥迪A4、A5、A6分别多少钱?”
人工客服很难24h响应消费者需求,这时机器人会根据后台存储的结构化数据自动识别。简化版的结构化表格如下所示:
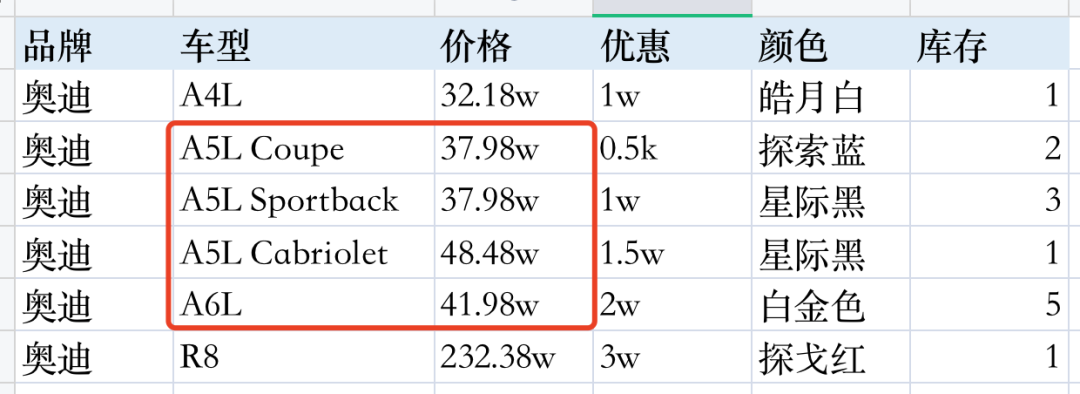
如果没有图谱,用传统的分类、匹配等意图识别方法,首先很难一次回答两种以上车型的价格,其次这些相似问都很接近,直接通过语义区分难度很大。
A4多少钱?/ A5多少钱?/ A6多少钱?
三句话只差一个数字,句向量相似度98%,意图相同(咨询车价)。而图谱首先定位句中实体A4、A5、A6,然后识别出属性“价格”,最后通过“实体-属性-价格”三元组找到正确答案。

知识图谱网络具备以下3种特性:
1.1 由节点(Point)和边(Edge)组成
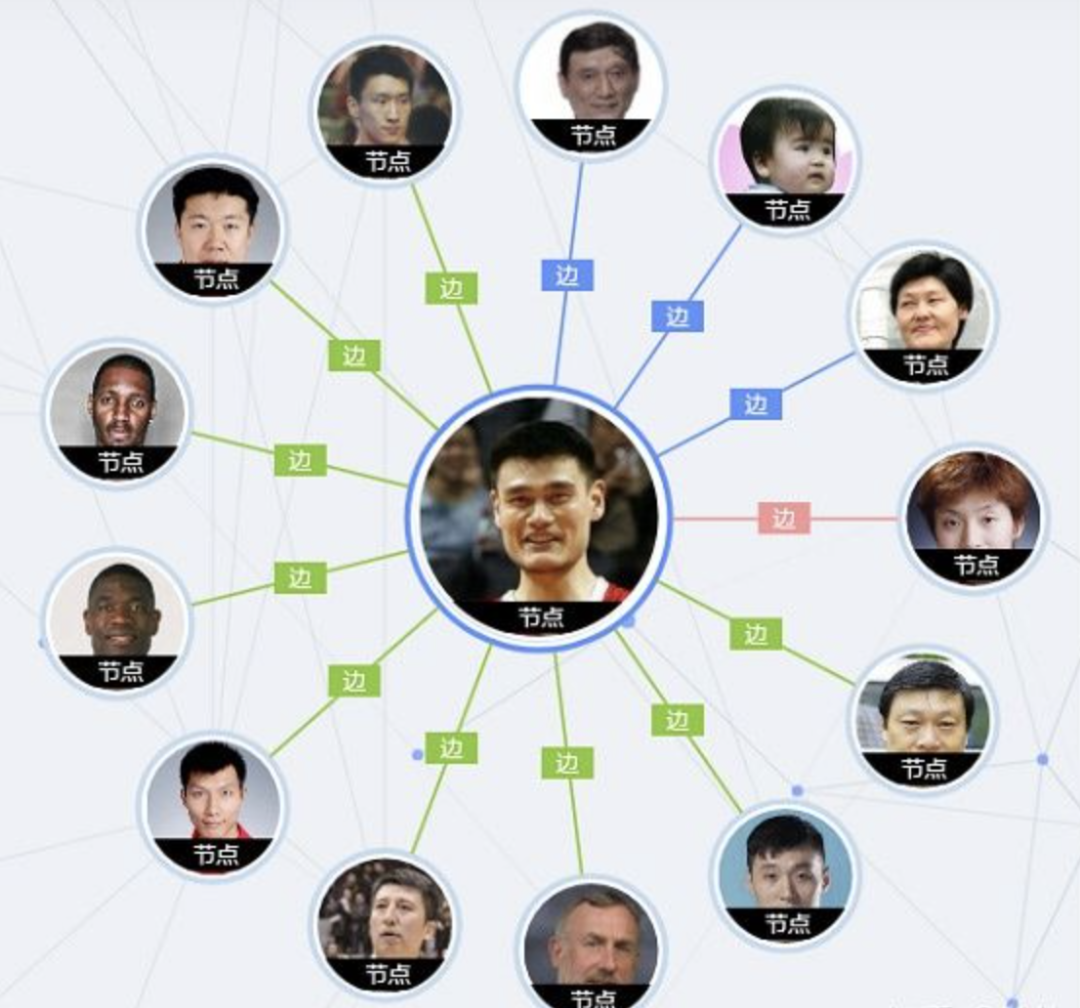
1.2 每个节点表示现实世界存在的“实体”,每条边为实体与实体之间的“关系”
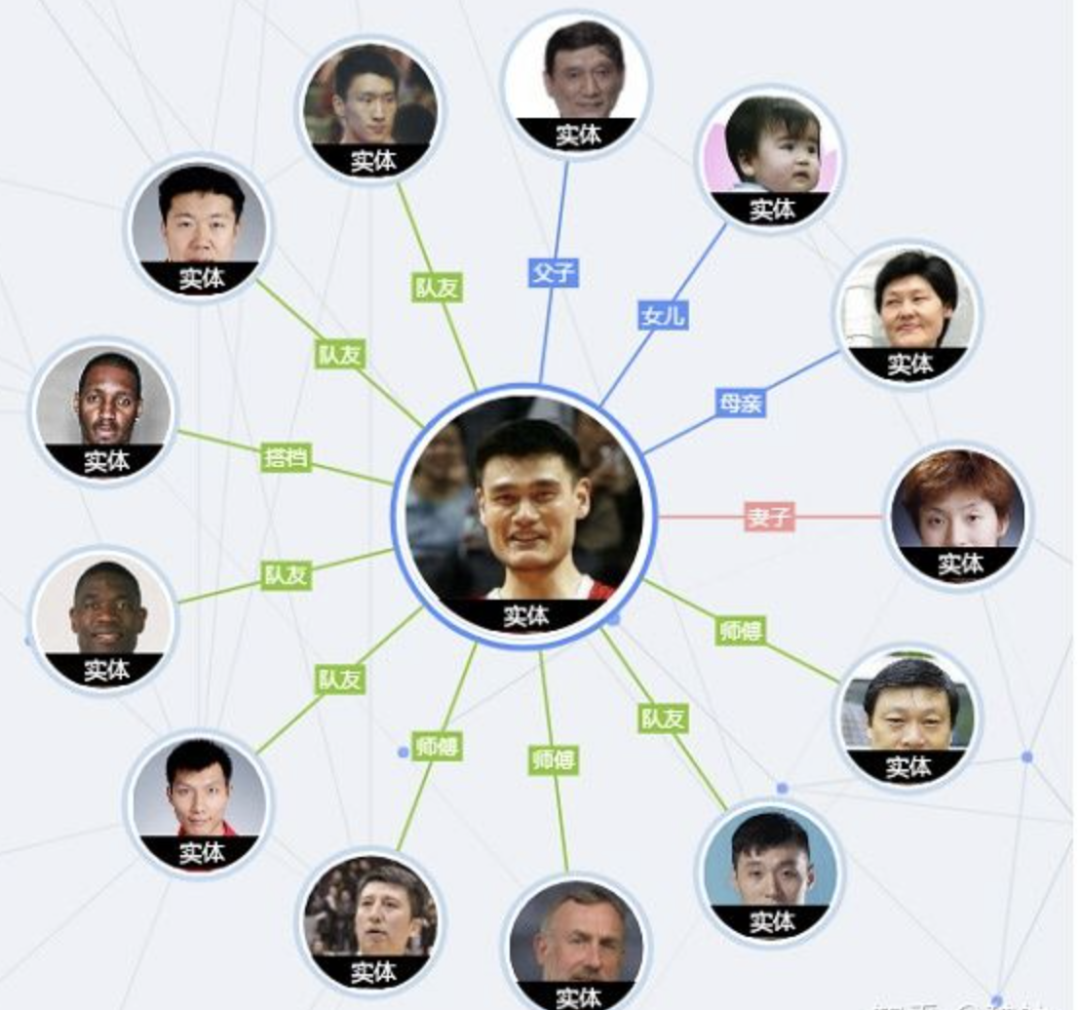
1.3 知识图谱是关系的最有效的表示方式
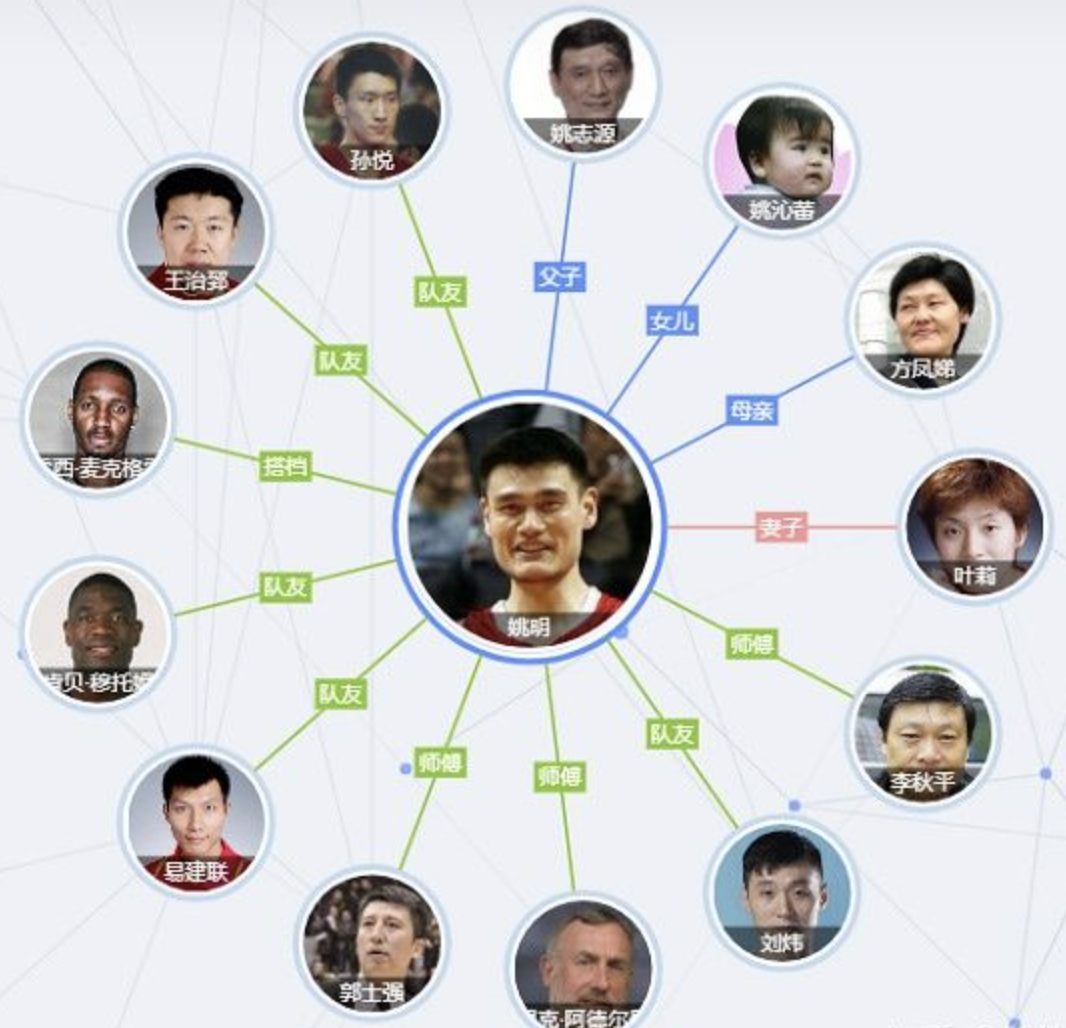
所以,知识图谱本质上就是语义网络,是一种基于图的数据结构。
2 知识图谱能干什么?
知识图谱的应用主要分为两大类:
一是通用知识图谱,通俗讲就是大众版,没有特别深的行业知识及专业内容,一般是解决科普类、常识类等问题。
二是行业知识图谱,通俗讲就是专业版,根据对某个行业或垂域的深入研究而定制的版本,主要是解决当前行业或细分领域的专业问题。
2.1 通用知识图谱
我们日常见到的都是通用知识图谱,主要应用于面向互联网的搜索、推荐、问答等业务场景;
先列举3个通用知识图谱的案例:
2.1.1 百度知识图谱
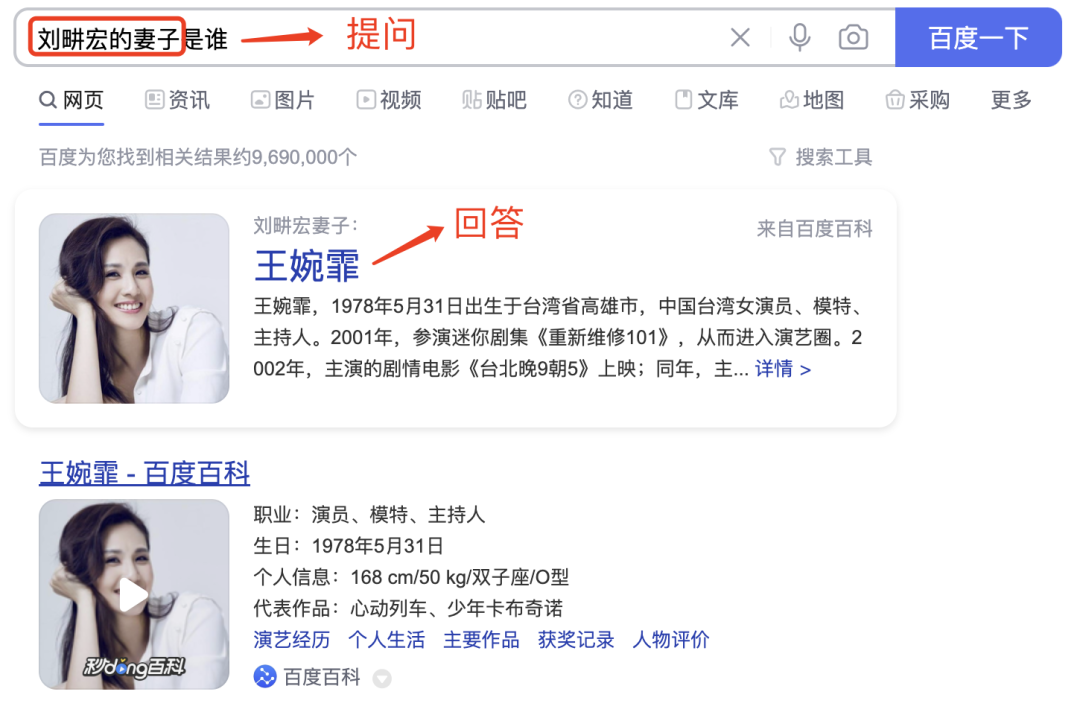
2.1.2 搜狗搜索(sogou.com/)
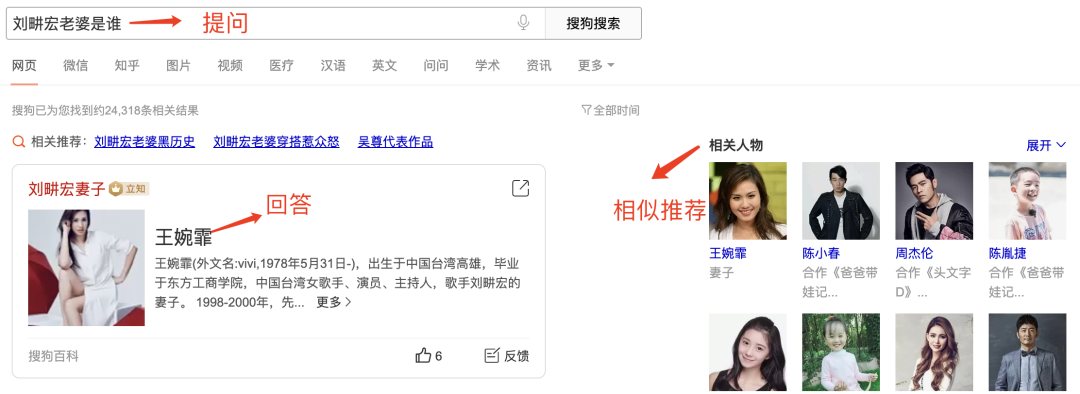
2.1.3 360搜索(so.com)
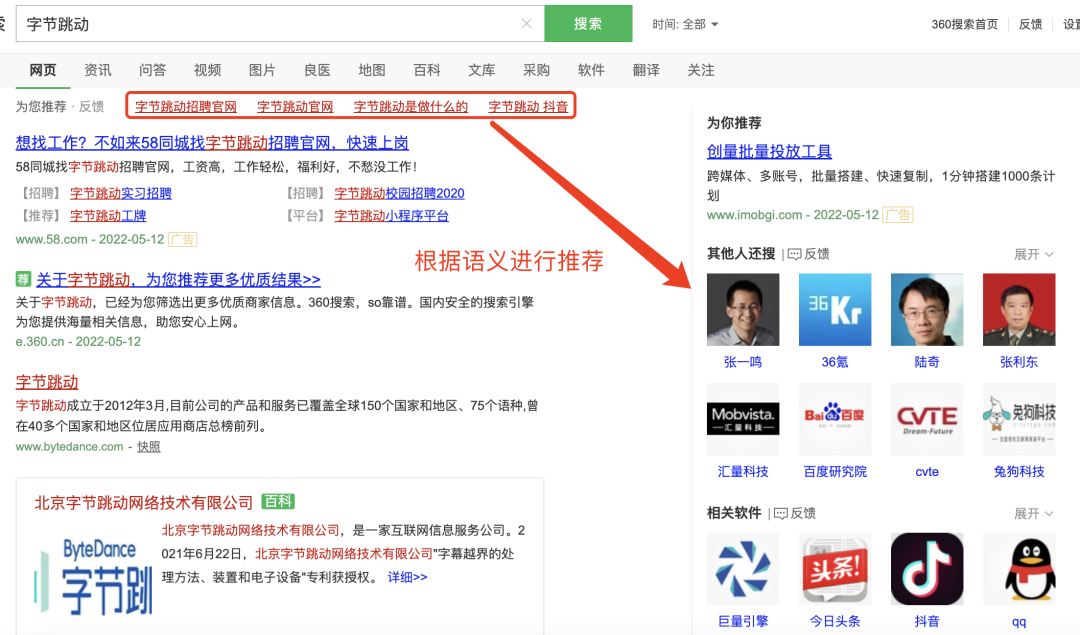
2.2 行业知识图谱
行业知识图谱指面向特定领域的知识图谱,用户目标对象需要考虑行业中各级别的人员,不同人员对应的操作和业务场景不同,因而需要一定的深度与完备性。
行业知识图谱对准确度要求非常高,通常用于辅助各种复杂的分析应用或决策支持,有严格与丰富的数据模式,行业知识图谱中的实体通常属性比较多且具有行业意义。
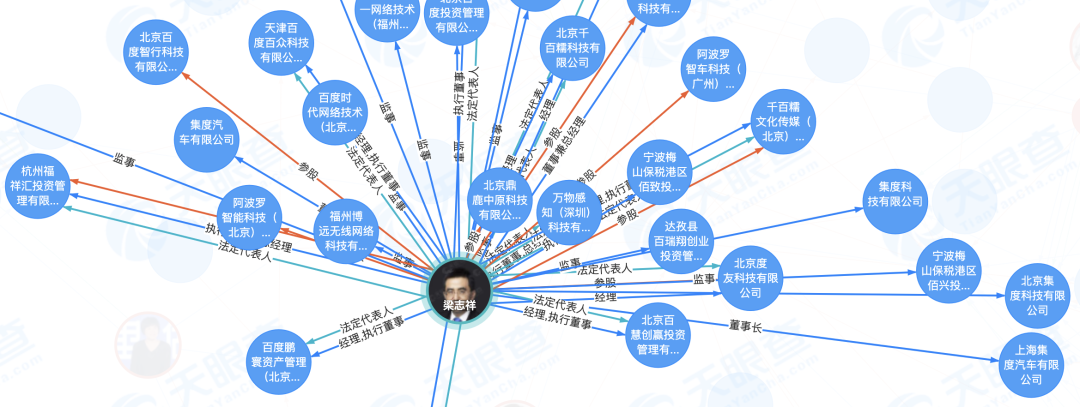
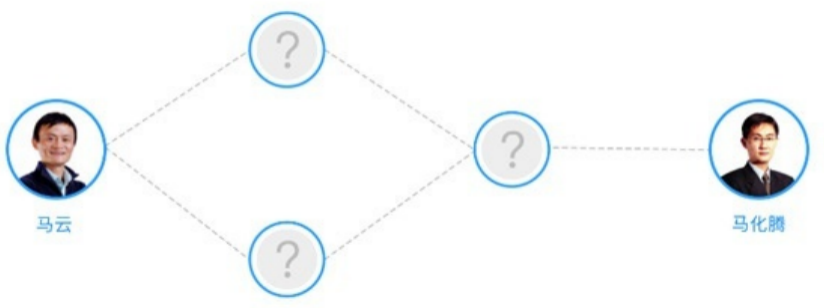
2.2.1 人脉路径查询
基于两个用户之间的关联实体(比如:所在单位、同事、同学、朋友、家人等)找到两者之间的关联路径。
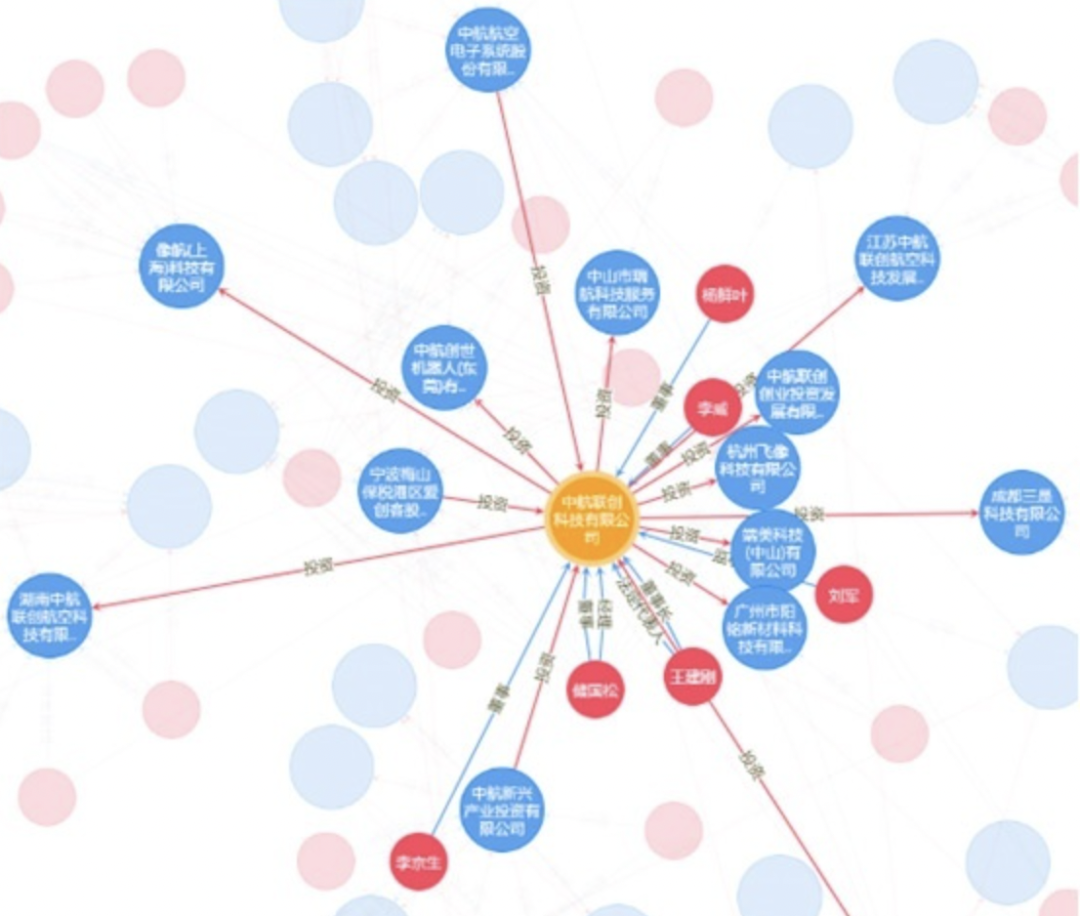
2.2.2 企业社交图谱查询
基于投资、任职、专利、招投标、涉诉关系以目标企业为核心心向外层层扩散,形成一个网络关系图,直观立体展现企业关联。
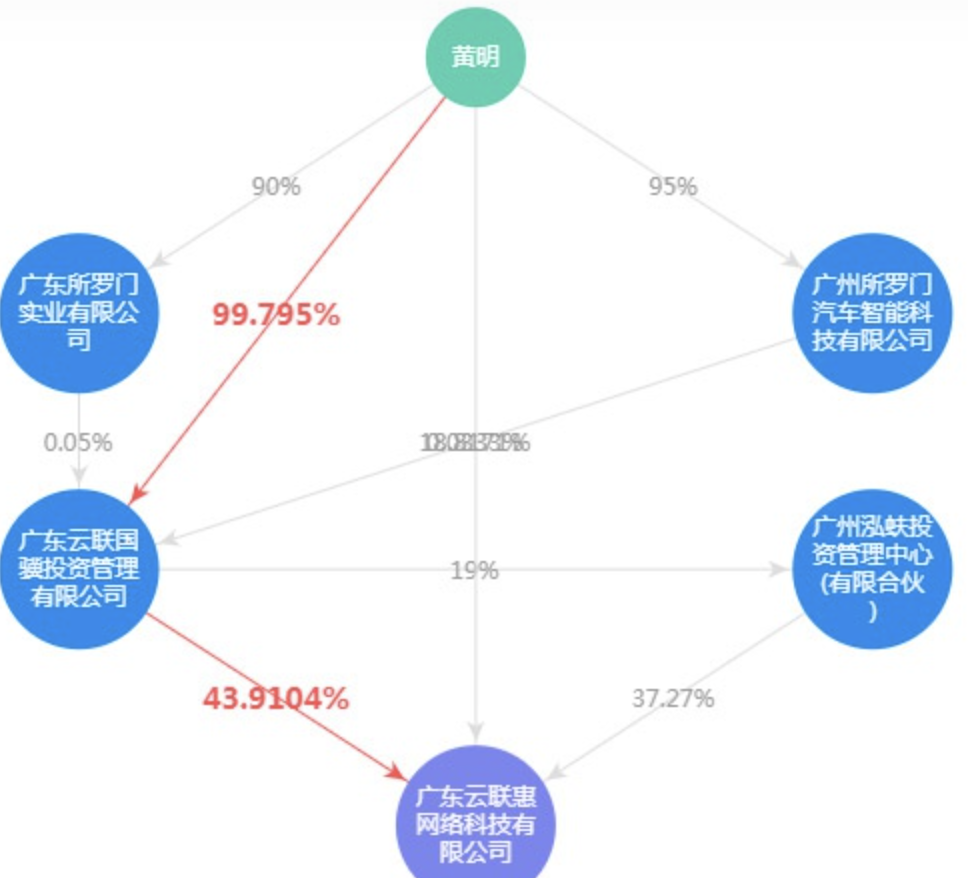
2.2.3 企业最终控股人查询
基于股权投资关系寻找持股比例最大的股东,最终追溯至自然人或国有资源管理部门。
2.2.4 辅助信贷审核
基于知识图谱数据的统一查询,全面掌握客户信息;避免由于系统、数据孤立、信息不一致造成信用重复使用、信息不完整等问题。
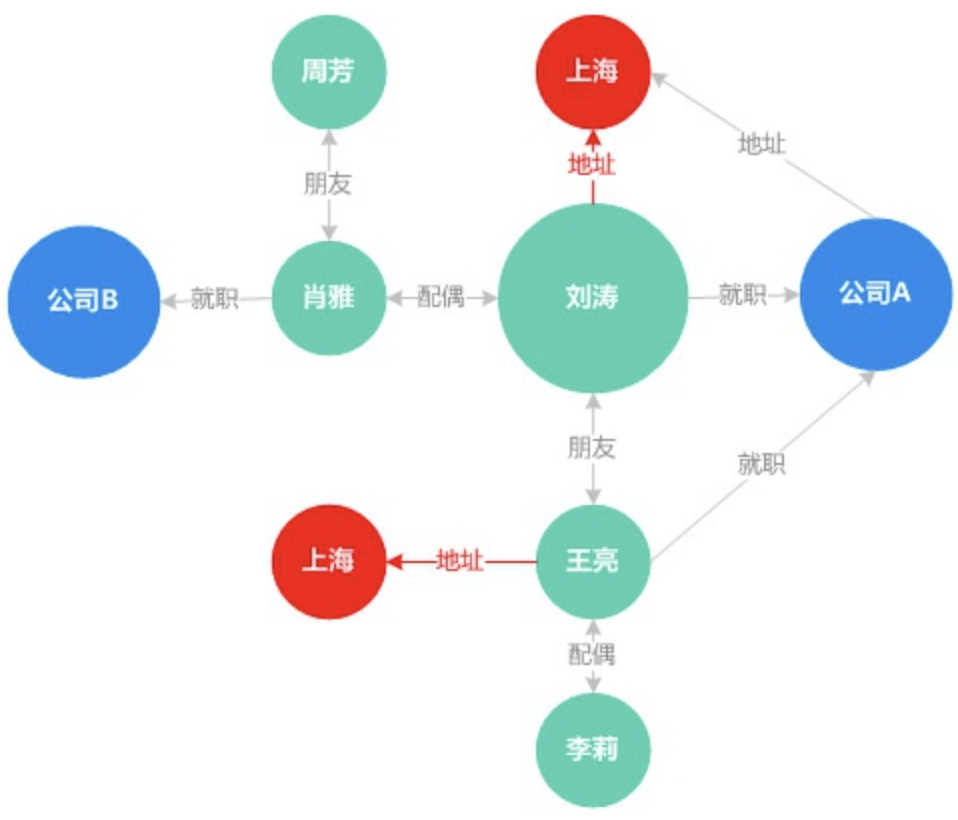
2.2.5 反欺诈之组团骗贷
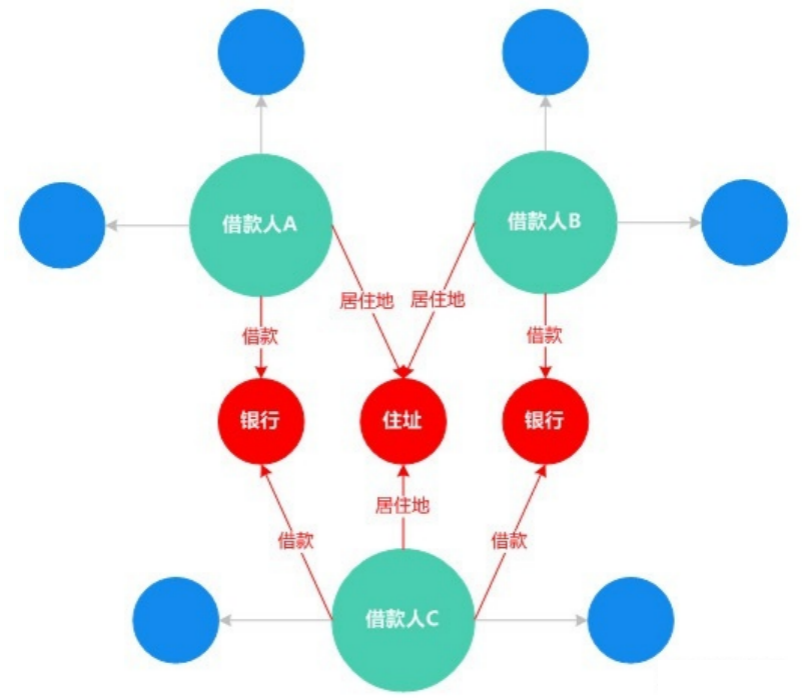
同一个人利用多个身份去申请贷款,详细见下图:虽然贷款人A、贷款人B、贷款人C之间没有直接的关系,但通过知识图谱可以看出三者之间都共享某一部分信息,存在一定的组团骗贷风险。
建设一个知识图谱系统,需要包括:知识建模、知识获取、知识融合、知识存储和知识应用5大部分:
1、知识建模:构建多层级知识体系,将抽象的知识、属性、关联联关系等信息,进行定义、组织、管理,转化成现实的数据库。
2、知识获取:将不同来源、不同结构的数据转化成图谱数据,包括结构化数据、半结构化数据(解析)、知识标引、知识推理等,保障数据的有效性和完整性。
3、知识融合:将多个来源、重复的知识信息进行融合,包括融合计算、融合计算引擎、手动操作融合等。
4、知识存储:根据业务场景提供合理的知识存储方案,存储方案具备灵活、多样化、可拓展特性。
5、知识应用:为已构建知识图谱提供图谱检索、知识计算、图谱可视化等分析与应用能力。并提供各类知识计算的SDK,包含图谱基础应用类、图结构分析类、图谱语义应用类、自然语言处理类、图数据获取类、图谱统计类、数据集数据获取类、数据集统计类。
最后送大家一些我收藏的知识图谱入门资料。
为了了解如何做一个知识图谱,可以先读一下DBpedia的论文:
Zhishi.me - Weaving Chinese Linking Open Data
如果有时间,最好能动手实践做一个百科知识图谱,比如做一个佛学百科知识图谱:
KG-Buddhism: The Chinese Knowledge Graph on Buddhism
知识图谱构建,开发者还需要掌握D2R技术,这里有一个非常好的教程,做一下应该很有帮助:
https://github.com/ryotayamanaka/jist2018-tutorial/wiki
对于知识抽取,包括关系抽取,槽填充,语义角色标注这些,先简单写模板,就够了,如果还想了解更多技术,需要学习word2vec技术,斯坦福NLP网站有很全的资料。
知识推理比较复杂,初学者可以略过,或者了解一下RDFS即可。
知识存储学一下neo4j和MongoDB就可以了,可以试着把自己构建的图谱导入到neo4j做一个可视化效果看看。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书