第一章 变量、常用循环体、代码结构、代码练习
第二章 列表、元组等数据结构、字符串驻留机制及字符串格式化操作
第三章 函数、面向对象、文件操作、深浅拷贝、模块、异常及捕获
第四章 项目打包、类和对象高级、序列、迭代器、生成器、装饰器
第五章 正则表达式、json、logging日志配置、数据库操作、枚举、闭包、匿名函数和高阶函数、time、datetime
第六章 Socket编程、多线程(创建方式、线程通信、线程锁、线程池)
Python Socket编程
HTTP、Socket、TCP概念
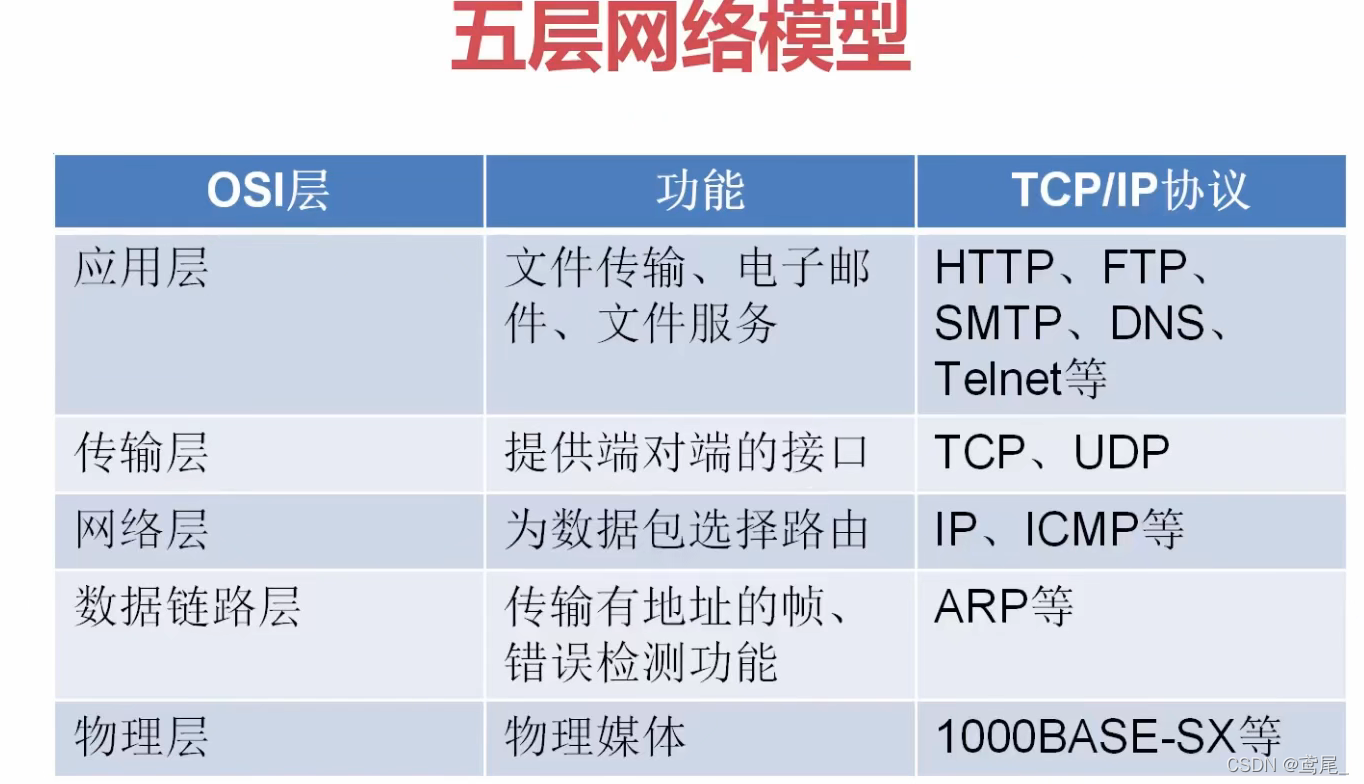
ClientA 发请求到 ServerB,就要经过这5层网络模型(详细的应该是7层)
Socket和Server实现通信
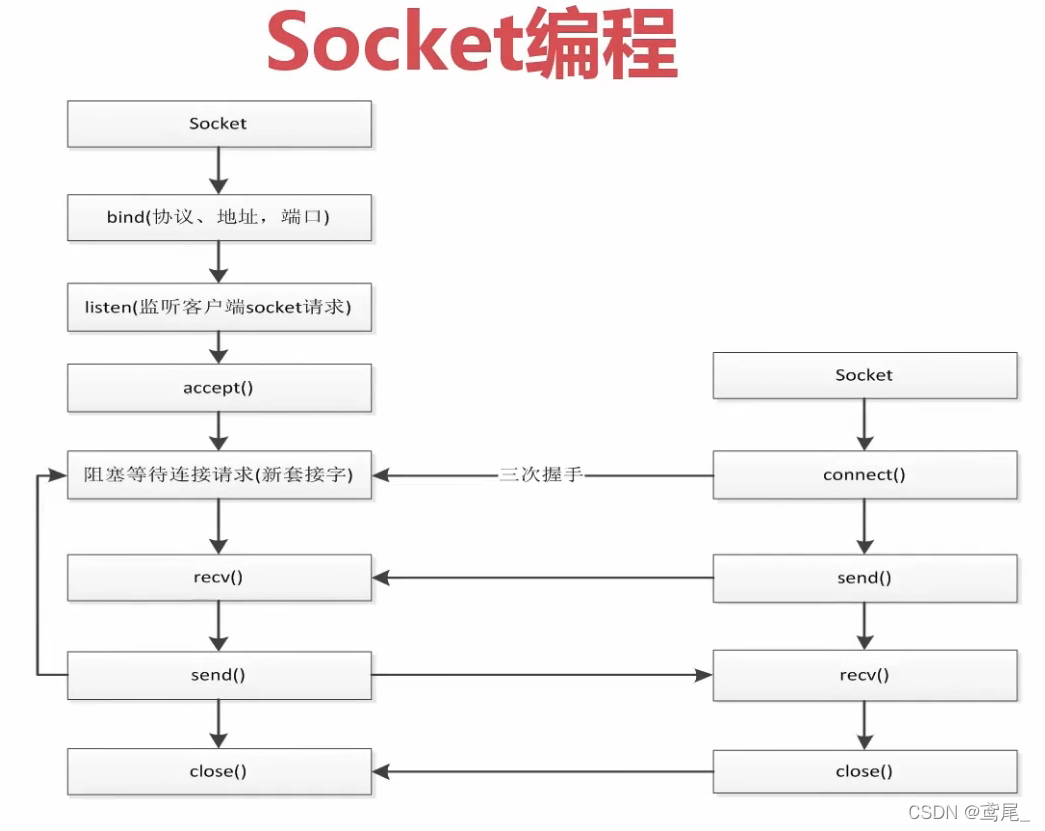
浏览器,底层也是用的socket编程
每个应用程序指定一个端口,根据端口确定应用程序
简单实现:
服务端(接收数据并返回数据给客户端):
import socket
# 类型:socket.AF_INET 可以理解为 IPV4
# 协议:socket.SOCK_STREAM
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 8000)) # (client客户端ip, 端口)
server.listen() # 监听
# addr:客户端来源信息
sock, addr = server.accept() # 获得一个客户端的连接(阻塞式,只有客户端连接后,下面才执行)
data = sock.recv(1024) # 接收客户端数据, 一次获取 1024b数据(1k)
print(data.decode("utf-8"))# 注意拿到的数据是 字节类型的,需要解码
sock.send('hello {}'.format(data.decode('utf-8')).encode('UTF-8'))
server.close()
sock.close()
客户端(发送数据,并取到服务器返回的数据):
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8000)) # (服务端ip,端口) 连接到一个服务器
client.send("bobby".encode("utf-8"))
data = client.recv(1024) # 接收服务端信息
print(data.decode('utf-8'))
client.close()
结果就是: 客户端向服务端发送了’bobby’数据,然后服务端收到后返回给客户端’hello bobby’的数据

实现聊天
服务端
import socket
# 类型:socket.AF_INET 可以理解为 IPV4
# 协议:socket.SOCK_STREAM
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 8000)) # (client客户端ip, 端口)
server.listen() # 监听
sock, addr = server.accept() # 获得一个客户端的连接(阻塞式,只有客户端连接后,下面才执行)
while True:
data = sock.recv(1024).decode('utf-8') # 接收客户端数据并且解码, 一次获取 1024b数据(1k)
print(data)
if 'exit' == data:
print('客户端发送完毕,已断开连接')
break
re_data = input()
sock.send(re_data.encode('UTF-8'))
sock.close()
客户端
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8000))
while True:
re_data = input()
client.send(re_data.encode("utf-8"))
if 'exit' == re_data:
print('客户端退出..')
break
data = client.recv(1024)
res = data.decode('utf-8')
print(res)
client.close()
但是只是实现了一对一的(client–>server)的通信,如何能让一个server为多个client服务呢?
服务端采用多线程模式
这样使用,可以供多个客户端来和服务器进行数据交互。
import socket
import threading
def deal(conn, client):
print(f'新线程开始处理客户端 {
client} 的请求数据')
while True:
data = conn.recv(1024).decode('utf-8') # 接收客户端数据并且解码, 一次获取 1024b数据(1k)
print('接收到客户端发送的信息:%s' % data)
if 'exit' == data:
print('客户端发送完毕,已断开连接')
break
re_data = data.upper()
conn.send(re_data.encode('UTF-8'))
conn.close()
# 类型:socket.AF_INET 可以理解为 IPV4
# 协议:socket.SOCK_STREAM
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 8000)) # (client客户端ip, 端口)
server.listen() # 监听
while True:
sock, addr = server.accept() # 获得一个客户端的连接(阻塞式,只有客户端连接后,下面才执行)
xd = threading.Thread(target=deal, args=(sock, addr))
xd.start() # 启动一个线程
socket模拟http(百度为例)
访问百度地址时,需要传入三个参数:(其他网址不一定是这三个)
- GET path 请求类型及地址
- Host: 主机
- Connection: 连接
import socket
from urllib.parse import urlparse
def get_url(url):
# 通过socket请求html
url = urlparse(url) # 解析url
host = url.netloc # 获取主机(域名)
path = url.path
if path == "":
path = "/"
# 建立socket连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80))
client.send("GET {0} HTTP/1.1\r\nHost:{1}\r\nConnection:close\r\n\r\n".format(path, host).encode('utf-8'))
data = b"" # 表示是byte类型
while True:
d = client.recv(1024) # 一次性获取多少byte
if d:
data += d
else:
break
data = data.decode('utf-8')
html_data = data.split("\r\n\r\n")[1] # 只取html内容
print(html_data)
client.close()
if __name__ == '__main__':
get_url("http://www.baidu.com")
socketserver库
对服务端中的方法进行了封装,可以快速开发。
import socketserver
class MyHandler(socketserver.BaseRequestHandler):
def handle(self):
while True:
data = self.request.recv(1024).decode('utf-8') # 接收客户端数据并且解码, 一次获取 1024b数据(1k)
print('接收到客户端%s发送的信息:%s' % (self.client_address, data))
if 'exit' == data:
print('客户端发送完毕,已断开连接')
break
re_data = data.upper()
self.request.send(re_data.encode('UTF-8'))
self.request.close()
hostaddress = ('0.0.0.0', 8000)
server = socketserver.ThreadingTCPServer(hostaddress, MyHandler) # TCP server
print('启动socket服务,等待客户端连接')
server.serve_forever() # 服务一直执行,且可处理多客户端的连接
客户端省略了,和之前的一样
多线程
GIL
GIL:global interpreter lock(全局解释器锁)(cpython)
python中一个线程对应于c语言中的一个线程
gil使得同一时刻只有一个线程运行在CPU上执行字节码,保证线程安全(效率低),无法将多个线程映射到多个CPU上执行
但 gil会在一定条件(字节码行数和时间片,遇到io操作)下释放锁,其他线程就会去执行起来(线程不是绝对的安全)
字节码执行过程示例:
def add1(a):
a += 1
def desc1(a):
a -= 1
import dis
print(dis.dis(add1))
print(dis.dis(desc1))
---------------------------------
25 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (a)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
28 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_SUBTRACT
6 STORE_FAST 0 (a)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
# add1()执行顺序
'''
1. 加载a
2. 加载1
3. +
4. 赋值给a
'''
由上可知,两个函数的执行,都是按照这个顺序执行,但是如果gil在某个条件下突然把锁释放了,那么别的线程就会去执行自己的字节码,假如以上a是一个全局变量,那么在不加锁的情况下,会导致数据的不安全。
threading多线程
对于io操作来说,多线程和多进程性能差别不大
实现方式:
- 通过Thread类创建
- 继承Thread类创建
多线程示例:
如下一共执行了 3 个线程
- 主线程
- t1 子线程
- t2 子线程
当子线程没有设置为守护线程时,主线程就算执行完也要等子线程执行完,子线程执行完毕后才关闭,除非设置子线程为守护线程
通过Thread类创建线程
代码量较小时使用
import threading
import time
# 通过Thread类创建
def get_detail_html(url):
print("get detail html started")
time.sleep(2) # 睡眠2s
print('get detail html end')
def get_detail_url(url):
print("get detail url started")
time.sleep(2) # 睡眠2s
print('get detail url end')
if __name__ == '__main__':
t1 = threading.Thread(target=get_detail_html, args=('',))
t2 = threading.Thread(target=get_detail_url, args=('',))
t1.setDaemon(True) # 设置子线程为 守护线程,当主线程关闭后,子线程也被关闭
t2.setDaemon(True)
start_time = time.time()
t1.start()
t2.start()
print('last time: {}'.format(time.time() - start_time))
- join() : 线程强行介入执行
if __name__ == '__main__':
t1 = threading.Thread(target=get_detail_html, args=('',))
t2 = threading.Thread(target=get_detail_url, args=('',))
t1.setDaemon(True) # 设置子线程为 守护线程,当主线程关闭后,子线程也被关闭
t2.setDaemon(True)
start_time = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
# 当t1、t2子线程执行完之后,才会执行
print('last time: {}'.format(time.time() - start_time))
继承Thread类
代码量大且需求逻辑较为复杂时使用
import threading
import time
class GetDetailHtml(threading.Thread):
def __init__(self, name):
super().__init__(name=name)
def run(self):
print("get detail html started")
time.sleep(2) # 睡眠2s
print('get detail html end')
class GetDetailUrl(threading.Thread):
def __init__(self, name):
super().__init__(name=name)
def run(self):
print("get detail url started")
time.sleep(2) # 睡眠2s
print('get detail url end')
if __name__ == '__main__':
t1 = GetDetailHtml('get_detail_html')
t2 = GetDetailUrl('get_detail_url')
start_time = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
print('last time: {}'.format(time.time() - start_time))
线程通信
线程间的通信
共享变量
创建一个全局的变量,多个线程共享这个变量
- 但是这样就造成了线程不安全,每个线程都可以同时修改这个变量,解决方法就是使用
锁
Queue
通过queue的方式进行线程间通信
Queue是一种线程安全的数据类型,底层使用了deque()双端队列
- get()
- put(item,block=True,timeout=None)
- put_nowait() 异步方法
- get_nowait() 异步方法
- join()
- task_done() 任务结束时调用,退出
import threading
import time
from queue import Queue
# 通过Thread类创建
def get_detail_html(queue):
while True:
url = queue.get() # 获取数据,是一个阻塞方法
print(url)
print("get detail html started")
time.sleep(2) # 睡眠2s
print('get detail html end')
def get_detail_url(queue):
while True:
print("get detail url started")
time.sleep(2) # 睡眠2s
for i in range(2):
queue.put('http://aaaaa.com/{id}'.format(id=i))
print('get detail url end')
if __name__ == '__main__':
detail_url_queue = Queue(maxsize=1000)
thread_dtail_url = threading.Thread(target=get_detail_url, args=(detail_url_queue,))
thread_dtail_url.start()
for i in range(5):
html_thread = threading.Thread(target=get_detail_html, args=(detail_url_queue,))
html_thread.start()
start_time = time.time()
print('last time: {}'.format(time.time() - start_time))
线程同步锁 Lock、RLock
Lock
-
Lock锁确保某一时刻,只有获取到锁资源的代码块才可以执行代码
-
保证线程的安全性
-
但是,用锁会影响性能
-
还可能引起死锁
total = 0
lock = Lock()
def add():
global total
for i in range(1000000):
lock.acquire() # 获取锁
total += 1
lock.release() # 释放锁
def desc():
global total
for i in range(1000000):
lock.acquire() # 获取锁
total -= 1
lock.release() # 释放锁
t1 = threading.Thread(target=add)
t2 = threading.Thread(target=desc)
t1.start()
t2.start()
t1.join()
t2.join()
print(total) # 无论怎么执行,返回的结果都是 0,保证了数据的安全
死锁,如上文代码段
- 多次获取锁,没释放
# 多次调用 lock.acquire
for i in range(1000000):
lock.acquire() # 获取锁
lock.acquire()
total += 1
lock.release() # 释放锁
# 调用了带获取锁资源的函数
# 多次调用 lock.acquire
def ds(lock):
lock.acquire()
..
lock.release()
for i in range(1000000):
lock.acquire() # 获取锁
ds(lock) # 调用了带获取锁资源的函数
lock.release() # 释放锁
注意:一个线程中,在释放锁资源之前只能执行一次,lock.acquire()获取锁资源,否则就会造成死锁
而RLock就解决了这个问题。
- 两个线程互相等待对方释放资源,造成死锁
RLock可重入锁
在同一个线程里面,可以连续多次调用acquire来获取锁资源,但是要注意acquire的次数要和release的次数相等,让它们成对出现。
以下连续调用获取锁资源时,就不会出现死锁问题了,上文说到的多次获取锁没释放的两种情况造成死锁的问题就不存在了
from threading import RLock
lock = RLock()
# 多次调用 lock.acquire
for i in range(1000000):
lock.acquire() # 获取锁
lock.acquire() # 获取锁
total += 1
lock.release() # 释放锁
lock.release() # 释放锁
condition
条件变量,用于复杂的线程间同步
两个线程间的对话,两个线程交替执行
是一个上下文管理器,__enter__()时会去获取锁,__exit__()时,会去释放锁
主要方法:
- wait() : 线程等待
- notify() : 唤醒处于等待状态的线程
import threading
from threading import Condition
class XiaoAi(threading.Thread):
def __init__(self, name, condition):
super().__init__(name=name)
self.condition = condition
def run(self):
with self.condition:
self.condition.wait()
print("{}:在".format(self.name))
self.condition.notify()
self.condition.wait()
print("{}:好啊".format(self.name))
self.condition.notify()
class TianMao(threading.Thread):
def __init__(self, name, condition):
super().__init__(name=name)
self.condition = condition
def run(self):
with self.condition:
print("{}:小爱同学".format(self.name))
self.condition.notify()
self.condition.wait()
print("{}:我们来对古诗吧".format(self.name))
self.condition.notify()
self.condition.wait()
if __name__ == '__main__':
condition = Condition()
xiao_ai = XiaoAi('小爱', condition)
tian_mao = TianMao('天猫精灵', condition)
xiao_ai.start() # 一定要注意线程的执行顺序,谁先启动
tian_mao.start() # 让xiao_ai线程先启动,优先进入线程等待状态,等待tian_mao将xiao_ai唤醒且tian_mao进入等待,以此类推,完成交替执行
--------------------------------------
天猫精灵:小爱同学
小爱:在
天猫精灵:我们来对古诗吧
小爱:好啊
- 启动顺序很重要
- 在调用with cond后才能调用 wait()或notify()方法,否则报错
Semaphore
内部由condition实现
用于控制进入数量的锁
如:文件读写操作,写只允许一个线程写,而读可以允许多个线程一起读
- acquire() 获取锁 获取后锁数量 -1
- release() 释放锁,释放后锁数量 +1
import threading
import time
class HtmlSpider(threading.Thread):
def __init__(self, url, sem):
super().__init__()
self.url = url
self.sem = sem
def run(self) -> None:
time.sleep(2)
print('got html text success')
# 爬取完后,释放锁
self.sem.release()
class UrlProducer(threading.Thread):
def __init__(self, sem):
super().__init__()
self.sem = sem
def run(self) -> None:
for i in range(20):
self.sem.acquire() # 获取锁,获取后锁数量 -1
html_thread = HtmlSpider('http://baidu.com/{}'.format(i), sem)
html_thread.start()
if __name__ == '__main__':
sem = threading.Semaphore(3) # 一次分配3把锁,只有3个线程能同时运行,每有一个线程获取锁,锁数量-1,锁释放收数量再加回来,当锁数量为0时,其他线程全部停止,只有3个线程能运行
url_producer = UrlProducer(sem)
url_producer.start()
ThreadPoolExecutor线程池
-
集中管理线程。
-
当一个线程完成的时候,我们的主线程能够立即知道子线程的状态。
-
futures可以让多线程和多进程编码接口一致
Future类的简单方法:
- done() 判断任务是否执行完成
- cancel() 取消任务(任务一旦执行,就不能再取消了,可以在任务还没执行时取消,比如将 max_workers设置小一点)
- result() 获取任务结束后的返回值(这是一个阻塞方法)
from concurrent.futures import ThreadPoolExecutor
import time
def get_html(times):
time.sleep(times)
print('get page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=1) # max_workers 同时运行的线程数量
# 通过submit函数提交执行的函数到线程池中, submit是立即返回,没有阻塞
task1 = executor.submit(get_html, 3)
task2 = executor.submit(get_html, 2)
# 判断任务是否完成
print(task1.done()) # False
print(task2.cancel()) # 取消执行task2,返回True或False(任务一旦执行,就不能再取消了,可以在任务还没执行时取消,比如将 max_workers设置小一点)
time.sleep(4)
print(task1.done()) # True
print(task1.result()) # 获取任务结束后的返回值 是一个阻塞方法
as_complete()函数
获取已经完成的任务(批量)
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def get_html(times):
time.sleep(times)
print('get page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # max_workers 同时运行的线程数量
urls = [3, 2, 4]
all_task = [executor.submit(get_html, url) for url in urls] # 谁先完成按顺序返回谁
for future in as_completed(all_task): # as_completed函数 会把已经完成的任务返回
data = future.result()
print(data) # 2 3 4
ThreadPoolExecutor获取以及完成的task
from concurrent.futures import ThreadPoolExecutor
import time
def get_html(times):
time.sleep(times)
print('get page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # max_workers 同时运行的线程数量
urls = [3, 2, 4]
for data in executor.map(get_html, urls): # 会按照执行顺序返回,跟谁先完成无关
print(data) # 3 2 4
wait()函数的使用
- wait(obj) : 等obj任务执行完之后,后面的代码才会执行
- wait(obj, return_when)
return_when当某些条件下,后面的代码可以执行
from concurrent.futures import ThreadPoolExecutor, wait
import time
def get_html(times):
time.sleep(times)
print('get page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # max_workers 同时运行的线程数量
urls = [3, 2, 4]
all_task = [executor.submit(get_html, url) for url in urls]
wait(all_task) # 等待 Future(任务)执行完成,后面的代码才会执行
print('main')