onnxoptimizer、onnxsim被誉为onnx的优化利器,其中onnxsim可以优化常量,onnxoptimizer可以对节点进行压缩。为此以resnet18为例,测试onnxoptimizer、onnxsim对于模型的优化效果。onnxoptimizer、onnxsim的安装代码如下所示:
pip install onnxoptimizer
pip install onnxsim
1、resnet18的结构
resnet18的结构如下所,可见为多个CBR部件构成
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
2、创建onnx模型
import torch
from torchvision import models
model = models.resnet18()
dummy_input=torch.ones((1,3,256,256))
input_names=['input']
output_names=['output']
ONNX_name="resnet18.onnx"
torch.onnx.export(model.eval(), dummy_input, ONNX_name, verbose=True, input_names=input_names,opset_version=16,
dynamic_axes={'input': {0: 'batch',1:'width',2:'height'}, },
output_names=output_names)#,example_outputs=example_outputs此时模型结构如下所示,下图仅为局部。全图请自行运行代码,并上传模型到Netron网站进行可视化。图中的Identity节点是BN运算。
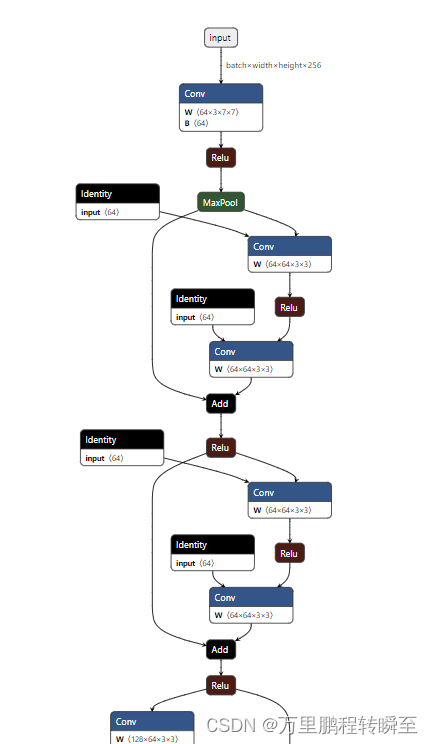
2、onnxoptimizer优化
import onnx
import onnxoptimizer
model = onnx.load(ONNX_name)
new_model = onnxoptimizer.optimize(model)
onnx.save(new_model,"resnet18_optimize.onnx")
# use model_simp as a standard ONNX model objectresnet18_optimize.onnx的结构如下所示,直观上感觉与resnet18.onnx没有任何区别。且两个模型的内存大小是一模一样的,也就是说onnxoptimizer没有优化BN运算。

3、onnxsim优化
import onnx
from onnxsim import simplify
onnx_model = onnx.load(ONNX_name) # load onnx model
model_simp, check = simplify(onnx_model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, "resnet18_simplify.onnx")resnet18_simplify.onnx的结构如下所示,直观上感觉与resnet18.onnx有一定区别,BN运算被合并到了模型中。
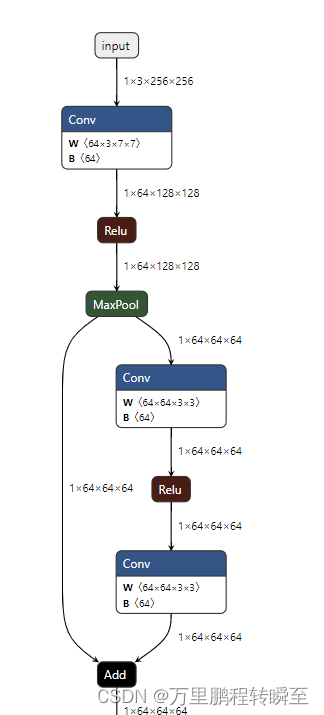
4、运行时间与显存占用对比
import onnxruntime
import numpy as np
import time
import pynvml
import ctypes
import os
#os.environ['Path']+=r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin'
#python3.7版本以上使用下列代码添加依赖项dll的路径
os.add_dll_directory(r'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin')
lib = ctypes.cdll.LoadLibrary(os.getcwd()+ "/dll_export.dll")
#win32api.FreeLibrary(libc._handle) #发现程序运行结束时无法正常退出dll,需要显式释放dll
lib.reset_cuda()
pynvml.nvmlInit()
def get_cuda_msg(tag=""):
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(tag, ", used:",meminfo.used / 1024**2,"Mib","free:",meminfo.free / 1024**2,"Mib")
onnx_path=["resnet18.onnx","resnet18_optimize.onnx","resnet18_simplify.onnx"]
for ONNX_name in onnx_path:
#session = onnxruntime.InferenceSession("traced_sp_model.onnx")
get_cuda_msg("\nStart run")
session = onnxruntime.InferenceSession(ONNX_name, providers=[ 'CUDAExecutionProvider'])#'TensorrtExecutionProvider', 'CPUExecutionProvider'
#print("Input node name:");[print(x.name) for x in session.get_inputs()]
#print("Output node name:");[print(x.name) for x in session.get_outputs()]
#注意数值类型与shape,这应该与torch是相同的
data={
"input":np.ones((1,3,256,256),dtype=np.float32)
}
st=time.time()
for i in range(100):
outputs = session.run(None,data)
print(ONNX_name,outputs[0].shape,(time.time()-st)/100)
get_cuda_msg("End run")
#需要删除占用显存的对象,才可清除cuda缓存。如果是pytorch则需要del model
del session
lib.reset_cuda()
对比结果如下所示,基本上没有区别。进行优化后,执行速度略快,但cuda占用没有显著优势
Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18.onnx (1, 1000) 0.03594543933868408 End run , used: 12257.984375 Mib free: 30.015625 Mib Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18_optimize.onnx (1, 1000) 0.024863476753234862 End run , used: 12183.984375 Mib free: 104.015625 Mib Start run , used: 11289.984375 Mib free: 998.015625 Mib resnet18_simplify.onnx (1, 1000) 0.026698846817016602 End run , used: 12239.984375 Mib free: 48.015625 Mib