DataScience&ML:金融科技之风控领域的CreditRisk+模型(信用风险度量模型)的简介、案例应用(代码实现)之详细攻略
目录
4、计算贷款组合违约损失概率分布表(联合概率密度/累计概率密度/期望损失)、违约损失的概率分布图
CreditRisk+模型的简介
CreditRisk+模型是根据针对火灾险的财险精算原理,对贷款组合违约率进行分析的,并假设在组合中,每笔贷款只有违约和不违约两种状态。CreditRisk+模型认为,贷款组合中不同类型的贷款同时违约的概率是很小的且相互独立,因此,贷款组合的违约率服从泊松分布。
1、CreditRisk+模型的背景
CreditRisk+模型是1993年瑞士信贷金融产品公司(CSFB)开发的信用风险度量模型。它采用保险精算方法推导债券、贷款组合的损失分布,建立仅考虑违约风险的模型。该模型属于信用违约风险度量模型,它在对违约风险进行分析时使用风险暴露的规模、期限以及债务人信用质量等信息,是一个违约风险的统计模型。
瑞士信贷公司尽量避免对金融工具价格行为本身进行研究,而是建立债务人违约事件的概率分布和金融资产分布之间的关系。通过保险建模技术, CreditRisk+模型有效刻画了信用风险偶发性的特征,同时也直观的给出了贷款违约数量以及组合损失的分布。
2、模型框架
2.0、CreditRisk+模型简介
CreditRisk+模型有三块组成,信用风险管理、经济资本配置及积极的组合管理。
(1)、信用风险管理模块:需要设定相关的输入变量,违约率、违约率波动性、风险暴露和回收率。模型中的违约率和违约波动性,是根据不同的信用评级的违约率统计资料,得出的经验数据。
| 信用风险管理模块 |
|
| 模型输入 |
违约率、违约率波动、违约损失率 风险敞口 |
| 模型输出 |
违约数量分布、违约损失分布 |
(2)、经济资本配置模块:风险管理者根据损失分布,判断在一定的置信水平下非预期信用违约损失水平,以配置相应的经济资本。度量信用风险暴露组合损失的波动性,以及非预期损失水平的相对可能性,是有效的信用违约管理的基本任务。
(3)、积极的组合管理模块:风险管理者可以根据对风险的偏好,来设计限额系统以及进行积极的组合管理。限额系统包括:控制风险暴露规模的单个债务人限额、控制最大的期限限额、控制一定信用级别的所有债务人的风险暴露额、控制在地区和行业部门的集中限额。
2.1、违约事件的描述
1)、存在n个债务人,假设每个债务人以概率p发生违约,以概率(1-p)不发生违约;
2)、对任意固定时间间隔△t,贷款违约率保持相同;
3)、债务人数量较大,而每个债务人的违约率很小,而且任意时间段内的违约数量之间不相关;
当单个债务人违约的概率很低时,可以使用泊松分布刻画固定时间段(如一年)内债务人违约数量的概率分布。根据泊松分布的特征,一年内一组债权人中有m个发生违约的概率可以表示为:
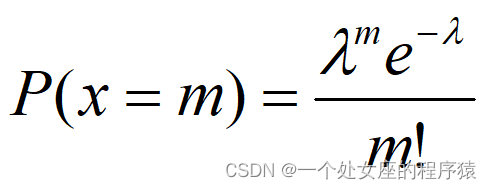
如果有一个由10000个债务人组成的组群的平均违约数量为10。根据假设3),违约数量具有时间上的不相关性,那么下一年中没有违约发生的概率为:
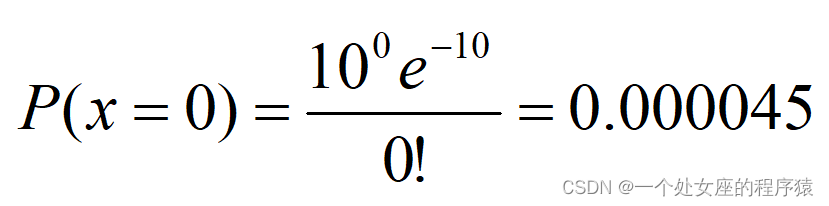
同理,有20个违约的概率为:
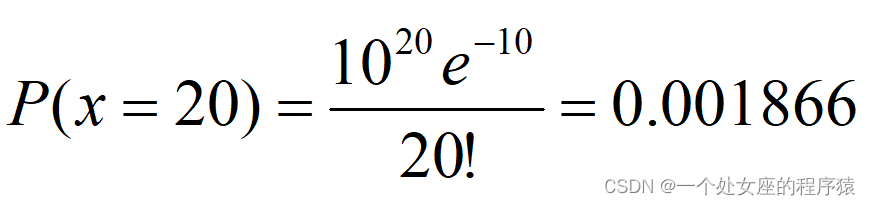
由此即可获得一组债务人违约数量的概率分布。
2.2、风险暴露的频段分级
第一,根据所有贷款的风险暴露情况,设定风险暴露频段值,记为L。例如,取L=2万元作为一个频段值。
第二,用N笔贷款中最大一笔贷款风险暴露值,除以频段值L,将计算数值按照四舍五入为整数,称为风险暴露的频段总级数,设为m,于是得到m个风险暴露频段级。例如,一个由1000个贷款组成的组合,最大一笔贷款的风险暴露为11万元,频段值L=2万元,那么总频段m=6,共可分为2、4、6、8、10、12六个频段。
第三,将每笔贷款的风险暴露数量除以频段值L,再按照四舍五入的规则将计算数值凑成整数,然后将该笔贷款归类到该整数值所对应的频段级。
类似地,可将所有贷款归类。例如,1000笔贷款组合中的一笔风险暴露为7万元的贷款,计算7/2=3.5万元,四舍五入后归入频段4万元。
2.3、各个频段级的贷款违约数量和违约损失概率分布
假设处于某频段级的贷款违约数服从泊松分布,于是可以计算每一个频段内违约数量的概率分布。例如,对于频段4万元,如果对应有200笔贷款,这一频段组合的违约数量服从均值为5的泊松分布,那么,可以计算相应的违约数量x的概率分布。
同样在该频段内,平均风险暴露为4万元已知,那么用违约数量x乘以4万元,即可计算得到该频段内违约损失的概率分布。
2.4、贷款组合的违约损失分布
在求出各个频段级的贷款违约概率及预期损失后,加总m个风险暴露频段级的损失,则可以得到N笔贷款组合的损失分布。
在每个分级内,所有债务人共享一个风险暴露和违约损失。然而,相同的组合损失金额有可能对应多种损失组合,例如,同样的100万元损失,两频段的组合可能是(20,80),也有可能是(30,70)。
因此,需要加总计算概率。进而可以计算所有可能损失组合对应的概率,最终得到整个贷款组合损失的分布。案例分析—基于CreditRisk模型的信贷资产证券化信用风险管理与控制。
2.5、模型评价—模型的优缺点
Credirisk+模型将保险建模技术引入信用风险领域,抓住信用违约事件的特征,从而可计算违约损失的概率分布。;
| 优点 |
(1)、没有对违约原因做任何假设:CreditRisk+模型属于一种违约风险统计模型,它的一大优势是没有对违约原因做任何假设; (2)、模型应用比较简单:要求的估计量和输入数据较少,仅需要债务工具的违约和风险暴露的数据; (3)、该模型将违约率视为连续随机变量,并将违约率的波动率纳入模型以体现违约率本身的不确定性这一特征。通过使用违约波动率参数,CreditRisk+模型得以得到简化,而且不用考虑违约相关性特征。 |
| 缺点 |
(1)、忽略了信用等级变化,因而贷款信用风险在计算期间内固定不变,与实际情况不符合; (2)、忽略了转移风险,每个债务人的敞口是固定的,不依赖于发行人信用质量的变化以及未来利率的变动 (3)、分组时,对每笔贷款暴露近似到组,从而将高估投资组合的方差; (4)、忽略了市场风险:CreditRisk+模型的缺点在于,它假设不存在市场风险。 (5)、该模型也没有涉及期权和外汇掉期等信用衍生品。 |
CreditRisk+模型的应用
1、根据贷款基本信息进行频段切分
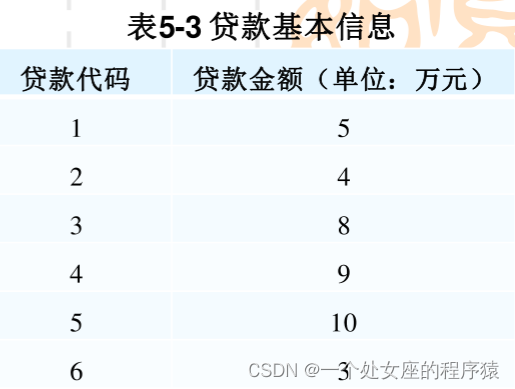
考察一家银行6笔贷款的情况,如表贷款进基本信息所示。假设将风险暴露的频段值选定为L=5万人民币,共有两个风险暴露的频段级,分别记为v1和v2,频段划分后得到频段切表。

第一步,计算6笔贷款在各自频段级的违约率和预期损失分布。假设这两个频段级的贷款平均违约数目为入=1,违约数量x服从泊松分布。对频段v1,

2、计算各个频段的违约概率和期望损失
同理,可计算频段v2的违约概率和期望损失。频段v1和v2的违约概率汇总于下表—违约数量概率分布表,

| 违约观察值 |
违约概率 |
期望损失 |
||
| v1 |
V2 |
v1 |
V2 |
|
| 0 |
0.3679 |
0.3679 |
1.8394 |
3.6788 |
| 1 |
0.3679 |
0.3679 |
1.8394 |
3.6788 |
| 2 |
0.1839 |
0.1839 |
0.9197 |
1.8394 |
| 3 |
0.0613 |
0.0613 |
0.3066 |
0.6131 |
3、计算任意违约组合的联合违约概率分布
第二步,计算二频段级违约组合的联合违约概率。由于v1频段有四种情形,n1=0,1,2,3,v2频段也有四种情形,n2=1,2,3,4,共计16种违约组合(n1,n2>6根据假设,两个频段发生违约是独立事件,故联合违约概率可以表达为各自概率的乘积。例如:
P(x1=0,x2=0)=P(x1=0)*P(x2=0)=0.3679*0.3679=0.1353
同理可得任意违约组合(x1,x2)的联合概率分布,如下表所示—组合违约概率分布表。需要注意的是,同一损失总金额对应多个概率。例如,对于15万人民币的损失,对应(1,1)和(3,0〉两种违约组合。
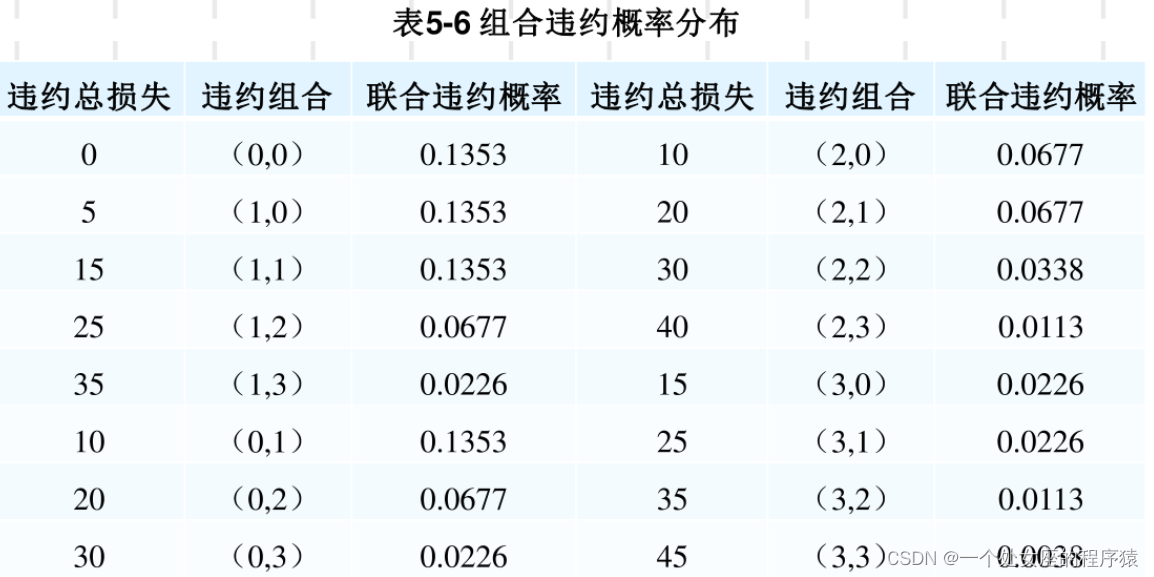
4、计算贷款组合违约损失概率分布表(联合概率密度/累计概率密度/期望损失)、违约损失的概率分布图
经过整理可得贷款组合违约损失概率分布,如表—违约损失概率分布表,进而得到—违约损失的概率分布图。
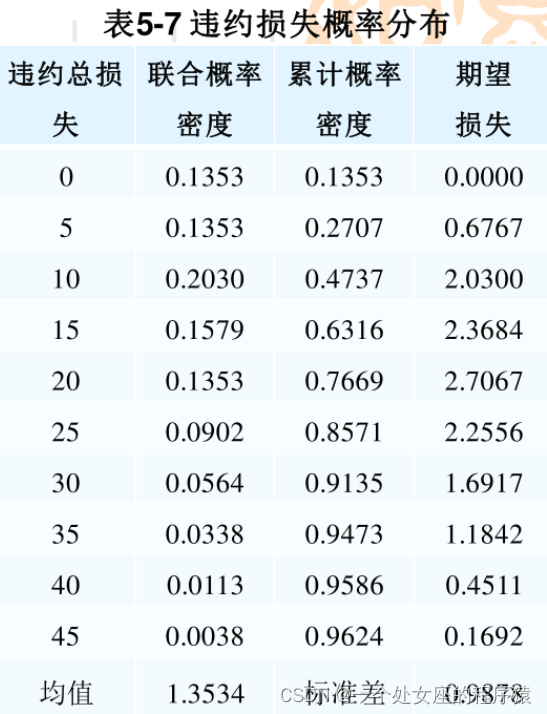
显然,该银行6笔贷款组成的贷款组合,未来一年期望的损失金额为1.35万元人民币。大致可看出,未来有95%的把握损失不会超过40万元人民币。

5、代码实现
输出结果
1、根据贷款基本信息进行频段切分
{1: [5, 4, 3], 2: [8, 9, 10]}
[[0.3679 0.3679]
[0.3679 0.3679]
[0.1839 0.1839]
[0.0613 0.0613]]
2、计算各个频段的违约概率和期望损失
[[0.1354 0.1354 0.0677 0.0226]
[0.1354 0.1354 0.0677 0.0226]
[0.0677 0.0677 0.0338 0.0113]
[0.0226 0.0226 0.0113 0.0038]]
[[ 0. 10. 20. 30.]
[ 5. 15. 25. 35.]
[10. 20. 30. 40.]
[15. 25. 35. 45.]]
3、任意违约组合的联合违约概率分布
{0.0: 0.1354, 5.0: 0.1354, 10.0: 0.2031, 15.0: 0.158, 20.0: 0.1354, 25.0: 0.0903, 30.0: 0.0564, 35.0: 0.0339, 40.0: 0.0113, 45.0: 0.0038}
4、计算各个频段的违约概率和期望损失
{0.0: 0.1354, 5.0: 0.2708, 10.0: 0.4739, 15.0: 0.6319, 20.0: 0.7673, 25.0: 0.8576, 30.0: 0.914, 35.0: 0.9479000000000001, 40.0: 0.9592, 45.0: 0.9630000000000001}
[0.0, 0.6769999999999999, 2.031, 2.37, 2.7079999999999997, 2.2575000000000003, 1.692, 1.1864999999999999, 0.45199999999999996, 0.171]
1.3545
0.9374032750102808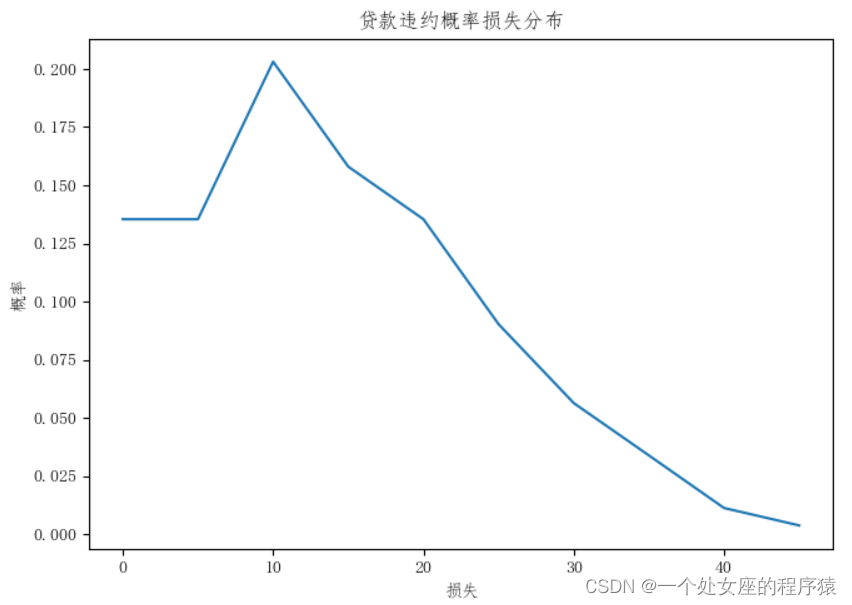
实现代码
# encoding: utf-8
import numpy as np
import scipy.stats as st
# 1、根据贷款基本信息进行频段切分
money = [5,4,8,9,10,3]
L = 5
labelnum = round(max(money) / L) # 风险暴露总级数
label = {} # 频段级及对应的贷款贷款金额
for i in money:
for j in range(1, labelnum+1):
if round(i / L) == j:
if j not in label.keys():
label[j] = [i]
else:
label[j].append(i)
print('1、根据贷款基本信息进行频段切分')
print(label)
# 2、计算各个频段的违约概率和期望损失
arr = np.zeros((len(label[1])+1,labelnum)) # 各个频段级对应的违约数的概率分布
# λ=1
rv = st.poisson(1)
for i in range(arr.shape[0]):
for j in range(arr.shape[1]):
arr[i][j] = round(rv.pmf(i), 4)
print(arr)
pro = np.zeros((arr.shape[0], arr.shape[0])) # 联合违约概率
loss = np.zeros((arr.shape[0], arr.shape[0])) # 违约总损失
for i in range(pro.shape[0]):
for j in range(pro.shape[1]):
loss[i, j] = i * L + j * 2* L
pro[i, j] = round(arr[i, 0] * arr[j, 1], 4)
print('2、计算各个频段的违约概率和期望损失')
print(pro)
print(loss)
# 3、计算任意违约组合的联合违约概率分布
arr2 = {}# 整理之后的贷款违约损失的概率分布
for i in range(pro.shape[0]):
for j in range(pro.shape[1]):
if loss[i, j] not in arr2.keys():
arr2[loss[i, j]] = pro[i, j]
else:
arr2[loss[i, j]] = round((arr2[loss[i, j]] + pro[i, j]), 4)
arr2 = sorted(arr2.items(), key=lambda x: x[0])
arr2 = dict(arr2)
print('3、任意违约组合的联合违约概率分布')
print(arr2)
# 绘制违约损失的概率分布图
x = arr2.keys()
y = arr2.values()
Xlabel="损失"
Ylabel="概率"
title='贷款违约概率损失分布'
draw_curve(x,y,Xlabel,Ylabel,title)
# 4、计算贷款组合违约损失概率分布表(联合概率密度/累计概率密度/期望损失)、违约损失的概率分布图
accu_pro = {}# 累积概率密度
for j in range(len(arr2)):
sum = 0
for i in range(j+1):
sum = sum + list(arr2.values())[i]
accu_pro[list(arr2.keys())[j]] = sum
accu_pro = sorted(accu_pro.items(), key=lambda x: x[0])
accu_pro = dict(accu_pro)
print('4、计算各个频段的违约概率和期望损失')
print(accu_pro)
E_loss = [i*j for i,j in arr2.items()]# 期望损失
print(E_loss)
print(np.mean(E_loss))
print(np.std(E_loss))
参考文章