1、什么是 Redis?
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
(1)Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(2)Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
(3)Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 优势
(1)性能极高 – Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。
(2)丰富的数据类型 – Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及Ordered Sets 数据类型操作。
(3)原子 – Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC指令包起来。
(4)丰富的特性 – Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 与其他 key-value 存储有什么不同?
(1)Redis 有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis 的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
(2)Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样 Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
2、Redis 的数据类型?
Redis主要有5种数据类型,包括String,List,Set,Zset,Hash,满足大部分的使用要求
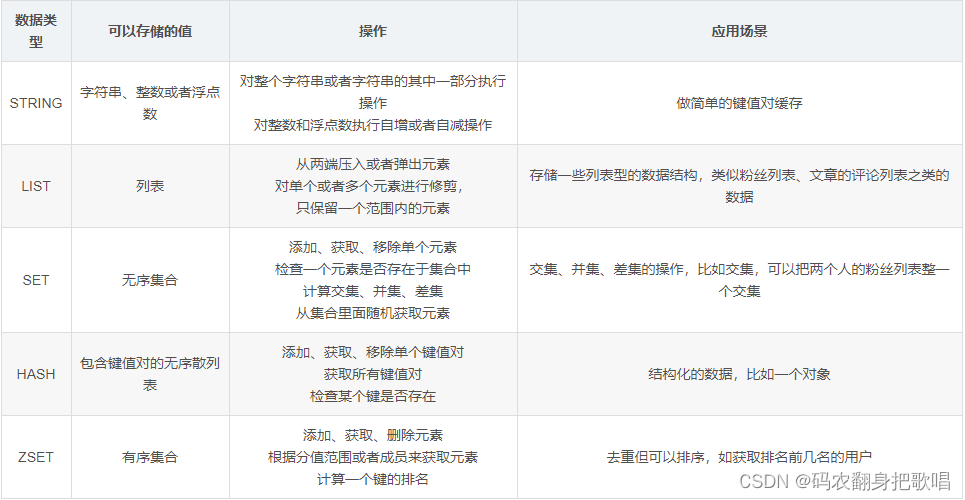
3、使用 Redis 有哪些好处?
(1)速度快,因为数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O1)
(2)支持丰富数据类型,支持 string,list,set,Zset,hash 等
(3)支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4)丰富的特性:可用于缓存,消息,按 key 设置过期时间,过期后将会自动删除
4、Redis 相比 Memcached 有哪些优势?
(1)Memcached 所有的值均是简单的字符串,redis 作为其替代者,支持更为丰富的数据类
(2)Redis 的速度比 Memcached 快很
(3)Redis 可以持久化其数据
5、Memcache 与 Redis 的区别都有哪些?
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!Redis 与 Memcached 主要有以下不同:
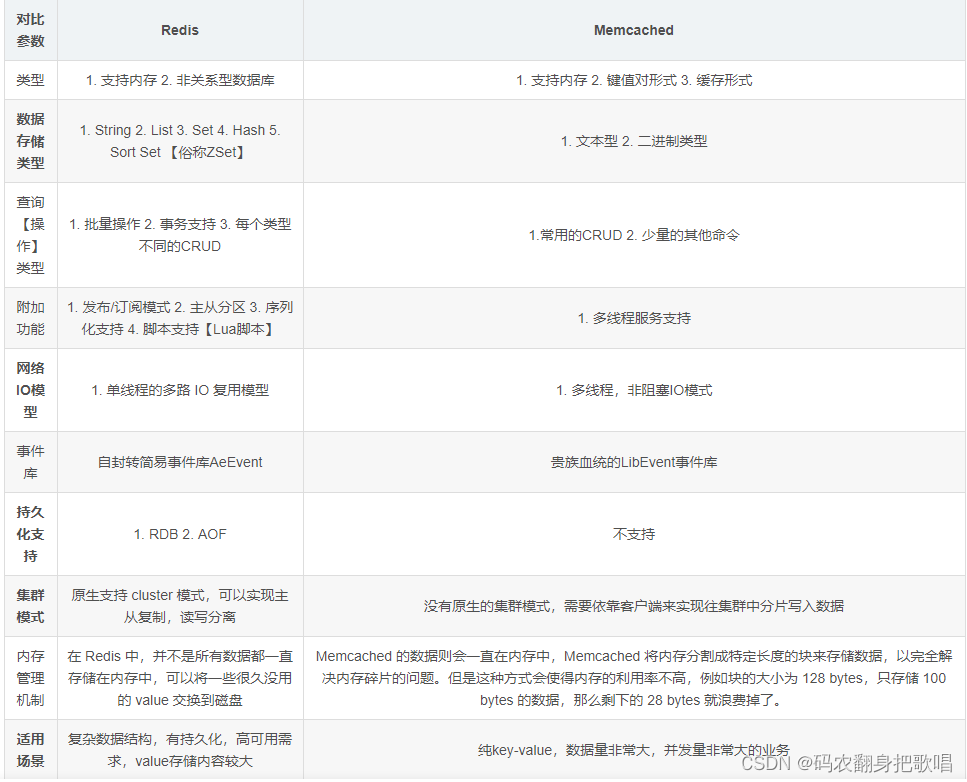
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
6、Redis 是单进程单线程的?
答:Redis 是单进程单线程的,redis 利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
7、一个字符串类型的值能存储最大容量是多少?
答:512M
8、Redis 的持久化机制是什么?各自的优缺点?
Redis提供两种持久化机制 RDB 和 AOF 机制:
1、RDBRedis DataBase)持久化方式:
是指用数据集快照的方式半持久化模式)记录 redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:
(1)只有一个文件 dump.rdb,方便持久化。
(2)容灾性好,一个文件可以保存到安全的磁盘。
(3)性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis的高性能)
(4)相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
2、AOFAppend-only file)持久化方式:
是指所有的命令行记录以 redis 命令请求协议的格式完全持久化存储)保存为 aof 文件。
优点:
(1)数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录到 aof 文件中一次。
(2)通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof工具解决数据一致性问题。
(3)AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
缺点:
(1)AOF 文件比 RDB 文件大,且恢复速度慢。
(2)数据集大的时候,比 rdb 启动效率低。
9、Redis 常见性能问题和解决方案:
(1)Master 最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务
(2)如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一
(3)为了主从复制的速度和连接的稳定性,Master 和 Slave 最好在同一个局域网
(4)尽量避免在压力很大的主库上增加从
(5)主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1<- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现 Slave 对 Master的替换。如果 Master 挂了,可以立刻启用 Slave1 做 Master,其他不变。
10、redis 过期键的删除策略?
(1)定时删除:在设置键的过期时间的同时,创建一个定时器 timer). 让定时器在键的过期时间来临时,立即执行对键的删除操作。
(2)惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
(3)定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
11、Redis 的回收策略(淘汰策略)?
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
注意这里的 6 种机制,volatile 和 allkeys 规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的 lru、ttl 以及 random 是三种不同的淘汰策略,再加上一种 no-enviction 永不回收的策略。
使用策略规则:
(1)如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用 allkeys-lru
(2)如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
12、为什么 Redis 需要把所有数据放到内存中?
答 :Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。在内存越来越便宜的今天,redis 将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
13、Redis 的同步机制了解么?
答:Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
14、Pipeline 有什么好处,为什么要用 pipeline?
答:可以将多次 IO 往返的时间缩减为一次,前提是 pipeline 执行的指令之间没有因果相关性。使用 redis-benchmark 进行压测的时候可以发现影响 redis 的 QPS峰值的一个重要因素是 pipeline 批次指令的数目。
15、是否使用过 Redis 集群,集群的原理是什么?
(1)Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为master,继续提供服务。
(2)Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。
16、Redis 集群方案什么情况下会导致整个集群不可用?
答:有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺少 5501-11000 这个范围的槽而不可用。
17、Redis 支持的 Java 客户端都有哪些?官方推荐用哪个?
答:Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson。
18、Jedis 与 Redisson 对比有什么优缺点?
答:Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持;Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等 Redis 特性。
Redisson 的宗旨是促进使用者对 Redis 的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
19、Redis 如何设置密码及验证密码?
设置密码:config set requirepass 123456
授权密码:auth 123456
20、说说 Redis 哈希槽的概念?
答:Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
21、Redis 集群的主从复制模型是怎样的?
答:为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品.
22、Redis 集群会有写操作丢失吗?为什么?
答 :Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
23、Redis 集群之间是如何复制的?
答:异步复制
24、Redis 集群最大节点个数是多少?
答:16384 个。
25、Redis 集群如何选择数据库?
答:Redis 集群目前无法做数据库选择,默认在 0 数据库。
26、怎么测试 Redis 的连通性?
答:使用 ping 命令。
27、怎么理解 Redis 事务?
答:
(1)事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
(2)事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
28、Redis 事务相关的命令有哪几个?
答:MULTI、EXEC、DISCARD、WATCH
29、Redis key 的过期时间和永久有效分别怎么设置?
答:EXPIRE 和 PERSIST 命令。
30、Redis 如何做内存优化?
答:尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面。
31、Redis 回收进程如何工作的?
答:一个客户端运行了新的命令,添加了新的数据。Redi 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
32、都有哪些办法可以降低 Redis 的内存使用情况呢?
答:如果你使用的是 32 位的 Redis 实例,可以好好利用 Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的 Key-Value 可以用更紧凑的方式存放到一起。
33、Redis 的内存用完了会发生什么?
答:如果达到设置的上限,Redis 的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容。
34、Redis 多线程的实现机制?
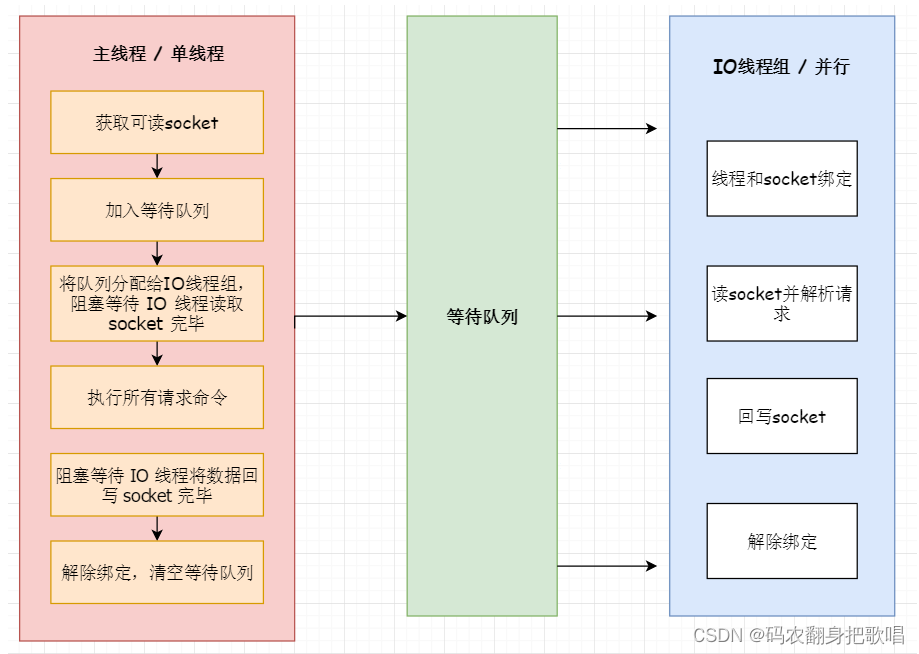
大致流程如下:
1)主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列;
2)主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程;
3)主线程阻塞等待 IO 线程读取 socket 完毕;
4)主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行;
5)主线程阻塞等待 IO 线程将数据回写 socket 完毕;
6)解除绑定,清空等待队列。
该设计的特点:
1)IO 线程要么同时在读 socket,要么同时在写,不会同时读或写。
2)IO 线程只负责读写 socket 解析命令,不负责命令处理。
总结
整理好的全套面试题文档,点开下面卡片,扫码免费领取