简介:以上文章讲述的是【线上系统打日志你了解多少】接下来我总结一下【SQL调优与设计规范】。觉得我还可以的可以加群一起督促学习探讨技术。QQ群:1076570504 个人学习资料库http://www.aolanghs.com/ 微信公众号搜索【欢少的成长之路】
一、SQL调优
优化select*
1.尽量避免使用select *,返回无用的字段会降低查询效率。如下:
SELECT * FROM Student
优化方式:使用具体的字段代替*,只返回使用到的字段。
2.明知查询一条数据集,后面一定要加上limit 1
SELECT * FROM Student where username=root and password=123456 limit 1
优化in和not in
尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id IN (2,3)
SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)0
优化or
尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
tip:如果or两边的字段是同一个,如例子中这样。貌似两种方式效率差不多,即使union扫描的是索引,or扫描的是全表
优化运算符
运算能用 = 就不要用 <> ,增加索引使用几率。
SELECT * FROM t WHERE id = 1
SELECT * FROM t WHERE id <> 1
优化insert,update,delete
超过100万以上的数据要把一个大的语句处理分解成小的处理语句
insert进行插入操作的时候一定要指定列名,不允许直接数值
优化where
where后面的列尽量被索引,这样查询效率是非常高的
SELECT * FROM t WHERE id = 1
优化group by
group by后面的列有索引,索引可以消除排序带来的CPU开销,如果是前缀索引,是不能消除排序的。
优化order by
order by后面的列有索引,索引可以消除排序带来的CPU开销,如果是前缀索引,是不能消除排序的。
排序字段顺序,asc/desc升降要跟索引保持一致,充分利用索引的有序性来消除排序带来的CPU开销。
优化limit
对于limit m, n分页查询,越往后面翻页即m越大的情况下SQL的耗时会越来越长,对于这种应该先取出主键id,然后通过主键id跟原表进行Join关联查询。
二、设计规范
UDF用户自定义函数
SQL语句的select后面使用了自定义函数UDF,SQL返回多少行,那么UDF函数就会被调用多少次,这是非常影响性能的
-- getSum是用户自定义函数 根据getSum求成本的总和
select id, payment_id, cos_sn, getSum(cost) from tsransaction where status = 1 and create_time between '2021-01-01 10:00:00' and '2021-01-12 12:00:00';
AUTO_INCREMENT 自增
建表的时候主键id带有AUTO_INCREMENT属性,而且AUTO_INCREMENT=1,在InnoDB内部是通过一个系统全局变量dict_sys.row_id来计数,row_id是一个8字节的bigint unsigned,InnoDB在设计时只给row_id保留了6个字节的长度,这样row_id取值范围就是0到2^48 - 1,如果id的值达到了最大值,下一个值就从0开始继续循环递增,在代码中禁止指定主键id值插入。
NOT NULL不等于空
根据业务含义,尽量将字段都添加上NOT NULL DEFAULT VALUE属性,如果列值存储了大量的NULL,会影响索引的稳定性
DEFAULT默认值
在创建表的时候,建议每个字段尽量都有默认值,禁止DEFAULT NULL
TEXT/BLOB 少用
创建表时如果有图片什么的请采用本地存储(对象存储OSS),当前的路径存在数据库字段中,杜绝直接存图片的二进制数据,如果真有特定的需求请分离出去单独一个表存储。而且操作那个表的时候不要用select*
text类型也是一样的是一个大类型少用,能采用其他方案就其他方案!
三、执行计划
不会看SQL执行计划的话,如何优化?
先分析一下执行计划这些字段分别代表什么意思吧!
(1)id 列:是 select 语句的序号,MySQL将 select 查询分为简单查询和复杂查询。
(2)select_type列:表示对应行是是简单还是复杂的查询。
(3)table 列:表示 explain 的一行正在访问哪个表。
(4)type 列:最重要的列之一。表示关联类型或访问类型,即 MySQL 决定如何查找表中的行。从最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
(5)possible_keys 列:显示查询可能使用哪些索引来查找。
(6)key 列:这一列显示 mysql 实际采用哪个索引来优化对该表的访问。
(7)key_len 列:显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
(8)ref 列:这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名。
(9)rows 列:这一列是 mysql 估计要读取并检测的行数,注意这个不是结果集里的行数。
(10)Extra 列:显示额外信息。比如有 Using index、Using where、Using temporary等。
如下图所示,举个例子哈,查询当前商品ID为1的数据。 Aolang_commodity_id这个字段是存在索引的。所以type显示为const,第二张图是全部查询,type就为ALL是最慢的查询。
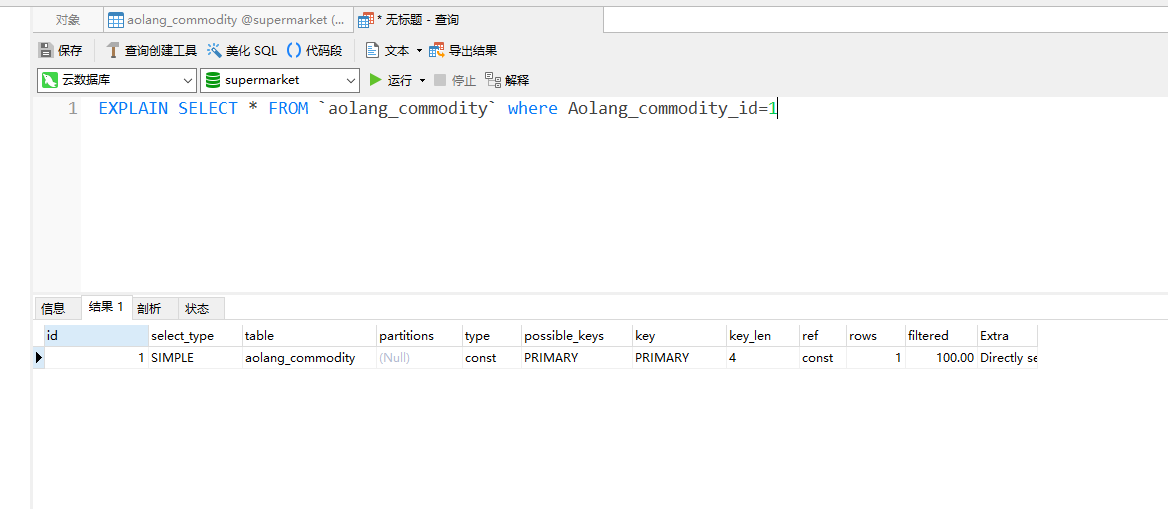
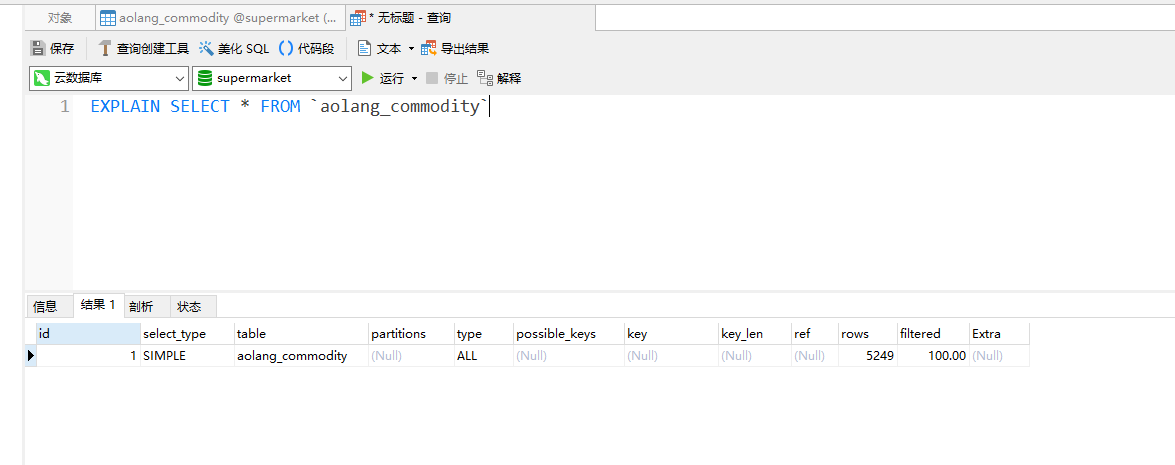
四、线上SQL排查慢查询思路
优化慢查询思路:
- 分析语句,是否加载了不必要的字段/数据
- 分析 SQL 执行句话,是否命中索引等
- 如果 SQL 很复杂,优化 SQL 结构
- 如果表数据量太大,考虑分表
微信公众号关注一下,不迷路哦!

知道的越多,不知道的就越多。找准方向,坚持自己的定位!加油向前不断前行,终会有柳暗花明的一天!
创作不易,你们的支持就是对我最大认可!
文章将持续更新,我们下期见!QQ群:1076570504 微信公众号搜索【欢少的成长之路】请多多支持!