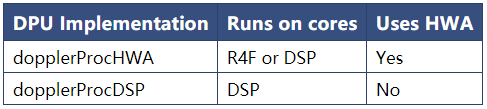
这个DPU实现了多普勒FFT(2dfft)
Doppler DPU
此DPU期望以DPIF_RADARCUBE_FORMAT_1格式所述的1D FFT数据作为radar cube的输入。此DPU的输出是DPIF_DETMATRIX_FORMAT_1中描述的格式的检测矩阵。这些是此DPU支持的唯一格式。
多普勒DPU有两种不同的实现方式:
DopplerProcHWA
radar cube中的数据通过EDMA移动到HWA存储器中,HWA执行所需的计算,EDMA将数据从HWA内存移动到检测矩阵中。
下图显示了DPU实现的高级框图:
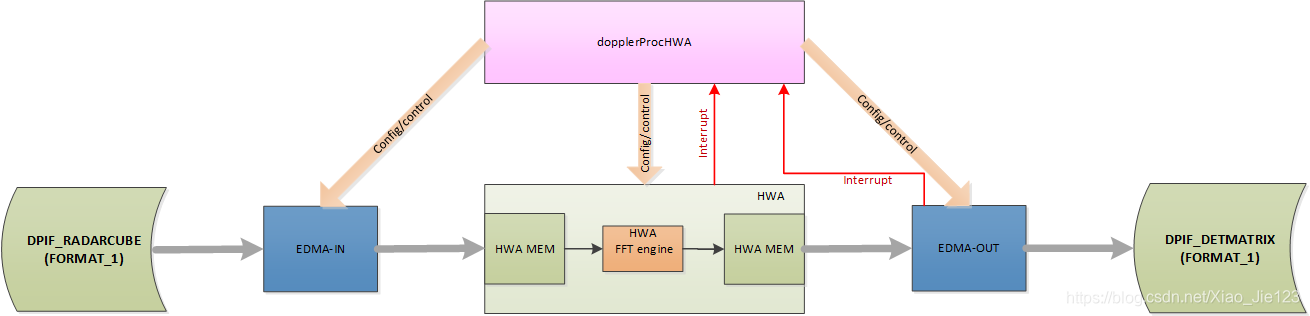
此DPU所需的资源列表在DPU_DopplerProcHWA_HW_Resources_t中描述。特别是,所需的EDMA信道数量是恒定的,不依赖于DPU配置。另一方面,所需的HWA参数集的数目是在DPU_DopplerProcHWA_HwaCfg_t中描述的在数据路径上描述的TX天线的数量的函数。
除上述资源外,对于DPU配置所需的其他参数在DPU的DPU_DopplerProcHWA_StaticConfig_t中。特别地,DPU将多普勒chirps(numDopplerChirps)的数量作为输入,不需要二的幂次。它产生一个多普勒维数等于numDopplererBins的检测矩阵,它必须是大于或等于numDopplerChirps的2的幂次方。另一个DPU输入是range bin的数量,他必须是偶数,但不需要是2的幂次。

下面是DPU实现的详细信息:
EDMA用于将数据从radar cube移动到HWA内存中,并在处理完成后将数据从HWA内存中移动到detection matrix。无论DPU如何配置,此DPU都需要所有4个HWA内存库。在这个文档中,HWA存储库被命名为M0,M1,M2,M3。
在下面的情况下使用ping/pong方案:
M0和M2被用于ping输入/处理
M1和M3被用于pong输入/处理
在每次迭代(ping/pong)中,radar cube矩阵中的一列被带入HWA进行处理,这种列由固定距离的所有样本组成,也就是说,对于一个固定的距离,所有多普勒chirp的所有接收虚拟天线。
下面的步骤由HWA对M内存中的数据(如上图所示的radar cube的一列)执行。下面给出了ping缓冲区的说明。Pong缓冲区处理与ping相同,只是M0内存被M1替换,M2内存被M3替换。
Windowing
在运行FFT之前,输入样本乘以一个窗函数。窗口的带下和系数在DPU_DopplerProcHWA_HwaCfg_t中定义。
窗口系数由应用程序代码进行指定
FFT and Log2|.|
在此步骤中,计算每个样本的绝对值的2D FFT和log2,输入样本在M0中,输出样本在M2中。输入样本的类型是cmplxImRe_t并且输出的类型是uint16_t。这个步骤将输入样本数从N=numDopplerChirps转换为输出样本数K=numDopplerBins,这个是多普勒FFT的大小。numDopplerBins和numDopplerChirps都是这个DPU的输入参数,numDopplerBins必须是大于或等于numDopplerChirps的2次幂。
Summation
计算每个droppler bin的所有虚拟天线的总和。
上一步的输出(HWA Log2 等级)采用的是Q11格式。在HWA中使用FFT进行求和,在DC(第0个)bin中获得和。求和的输入在M2上,输出是在M0上。此FFT编程的srcScale为3,这意味着3个冗余位(符号位扩展,在本例中没有符号)被添加到MSB中,5个LSB用0填充,因此计算前的输入格式是Q[11+5]格式。dstScale被设置为8,因此总和输出将丢弃8位,从而得到Q[11+5-8]=Q8格式的结果。The FFT size is the next power of 2 of number of virtual antennas并且FFT被编程为启用所有butterfly scaling stages,因此FFT输出结果将是1/N’ * sum(.),此时N‘=2^Ceil(log2(N)),N=numVirtualAntennas。输入CFAR和输出是Q8格式,因此CFAR threshold-scale也需要采用Q8格式。如果CFAR阈值最初打算用dB表示(比如为了方便用户),那么我们需要在输入CFAR算法之前进行一些转换。这个推导如下:
设N是天线的数量,N‘=2^Ceil(log2(N)),用户友好的CFAR阈值(dB)为TdB(= 20log10(|.|))。CFAR一般需要如下的做法:
CUT(Cell Under Test)=1/N * sum(log10(|.|)) > TdB/20 + 噪声项平均值(类似于在LHS上查看CUT)
给定log10(|.|) = log2(|.|)/log2(10),并进一步调整项以进行类似的计算,以匹配上面的描述和输出:
2^8 * 1/ N’ * sum(log2(|.|)) > TdB/20log2(10)*2^8 * (N/N’) + 噪声项平均值(类似于在LHS上查看CUT)
因此,提供给在这个多普勒DPU的输出上运行的CFAR算法的CFAR的阈值是T = 256 * TdB / 6 * N / N’
一旦计算出所有Doppler bins的总和,EDMA将结果从M0传输到detection matrix
HWA memory bank size limitation
此DPU配置中的参数必须满足以下两个条件:
4 * numRxAntennas * numtxantenas * numDopplerChirps <= 16384
2 * numRxAntennas * numtxantenas * numDopperBins <= 16384
在HWA中(每次ping/pong迭代)引入的数据大小是radar cube的一列。radar cube列的大小是4 * numRxAntennas * numTxAntennas * numDopplerChirps(1),此时4bytes是(cmplx16ImRe_t)的大小,即样本大小。
在2DFFT和Log2|.|之后大小为2*numRxAntennas * numTxAntennas * numDopplerBins(2),此时2bytes是(uint16_t)的大小.
上面的两个数量(1和2)应该(独立地)放入一个大小为16KB地hwa M地内存分区中
Exported APIs
DPU初始化通过DPU_DopplerProcHWA_init初始化完成
DPU配置由DPU_DopplerProcHWA_config完成,只有在DPU初始化完成后才能进行配置。配置参数在DPU_DopplerProcHWA_Config中描述
DPU通过调用DPU_DopplerProcHWA_process来执行。
这将触发EDMA的第一次ping/pong传输,此后,整个radar cube的Doppler DPU处理由硬件驱动:EDMA将移动数据并触发HWA,后者将处理数据并触发EDMA将数据移出(to detection matrix)并且触发下一个EDMA移入等等。radar cube的所有列将将在这个循环中处理,不需要CPU的干预,当HWA处理完radar cube的所有列时,它将生成一个中断,当最后一个EDMA传输到detection matrix已经到达时,EDMA将生成一个中断。当接收到两个中断时,DPU完成处理。在下图中,两个中断都用绿色的方框表示
Detailed block diagram for 3 TX 4RX
下图详细描述了3个TX和4个RX天线情况下的DPU实现。蓝色箭头连接的蓝色框表示不同的HWA参数集

DopplerProcDSP
在这个版本的多普勒DPU-HWA没有使用。所有的计算都由DSP完成
利用EDMA将radar cube中数据移动到scratch memory中,DSP执行所需要的计算,EDMA将数据从scratch memory移动到detection matrix中。
下图展示了DPU实现的高级框图
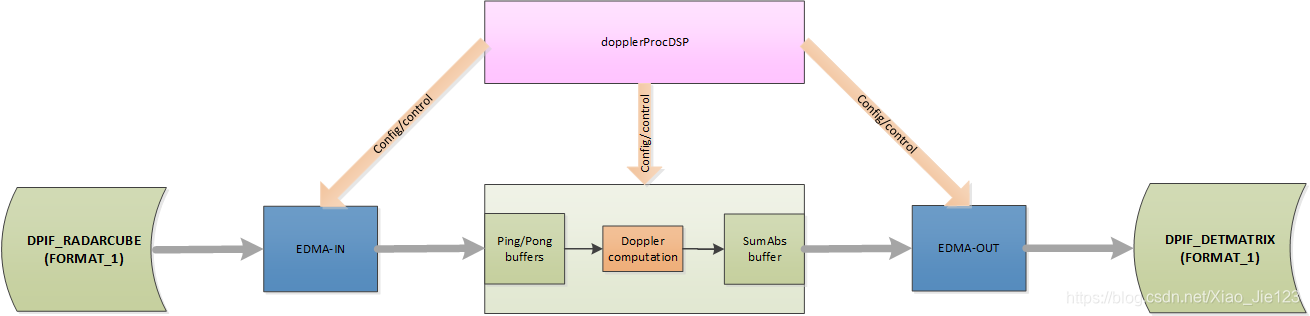
这个DPU所需要的资源列表在DPU_DopplerProcDSP_HW_Resources_t中描述。特别是,所需的EDMA通道数量是恒定的,不依赖于DPU配置
除了上述资源外,DPU配置所需的其他参数在DPU_DopplerProcDSP_StaticConfig_t中被列出。特别地,DPU以Doppler chirps(numDopplerChirps)的数量作为输入,不需要是2的幂次,但是需要是4个倍数。它产生一个多普勒维度等于numDopplerBins的detection matrix。它必须是大于或等于numDopperChirps的2的幂次方。另外,由于DSPLIB对FFT实现的限制,numDopperBins必须至少为16.

下面是DPU实施的详细信息:
Input data
EDMA用于将数据从radar cube移动到DPU scratch buffers中。
使用ping/pong缓冲方案,其中在每次迭代(ping/pong)中,从radar cube矩阵中获取与一个虚拟天线(对于固定距离的天线)相关的数据进行处理。
对一个固定的range bin,虚拟天线的处理顺序必须保证BPM可以被解码并且全部的虚拟天线都可以被求和。为了以虚拟天线数据的最小临时缓冲区来实现此目标,虚拟天线的序列按以下顺序进行处理:
- 下一个发送天线用于相同range bin和相同的RX天线。这样保证了BPM可以被解码
- 一旦固定range bin和固定RX天线的所有TX天线耗尽1,移动到相同range bin的下一个接收天线(以确保可以计算所有的虚拟天线的总和),然后重复1。
- 处理完此range bin的所有虚拟天线后,移动到下一个range bin
接下来的章节对[3TX,4RX]和[2TX,4RX]情况下的ping/pong数据模式进行说明
Static Clutter Removal
当静态杂波消除被启用时,从样本中减去多普勒FFT的输入样本的平均值
Windowing
在FFT运算之前,输入样本乘以实对称窗函数。窗口的大小和系数在DPU_DopplerProcDSP_HW_Resources_t资源中被定义。窗口系数必须由应用程序提供。
注意,窗口函数还执行IQ swap。在加窗之前,样本的格式与radar cube中的格式相同,即cmplx16ImRe_t。在加窗之后,输出为cmplx32ImRe_t格式。
FFT
计算FFT,输出具有cmplx32ReIm_t类型的numDopplerbin样本。
BPM decoding
如果启用了BPM,当FFT输出可用于2个TX天线(对于同一个RX天线和range bin),则BPM被解码。下一节将详细介绍BPM实现
Log2|.|
计算每个样本绝对值的Log2,输出为Q8格式的16位数字。
Summation and Output
对每个虚拟天线的每个droppler bin进行累加。请注意,在累加之前,求和中的每个因子除以2^Ceil(Log2(numVirtualAntennas))。这样做的目的是在HWA和DSP版本的DPU之间具有相同的CFAR阈值尺度解释,这种解释允许为downstream CFAR算法配置相同的阈值尺度,无论是在HWA还是在DSP版本的多普勒DPU上运行。参见DopplerProcHWA中求和部分中关于将CFAR阈值尺度从用户友好的dB单位转换为CFAR算法所需的描述。
一旦所有的虚拟天线都针对给定的range bin进行了处理,累积的阵列通过EDMA传输到detection matrix。
Detail block diagram for 3 TX 4 RX TDM-MIMO(no BPM)
下图详细描述了3个TX和4RX天线(无BPM)的DPU实现
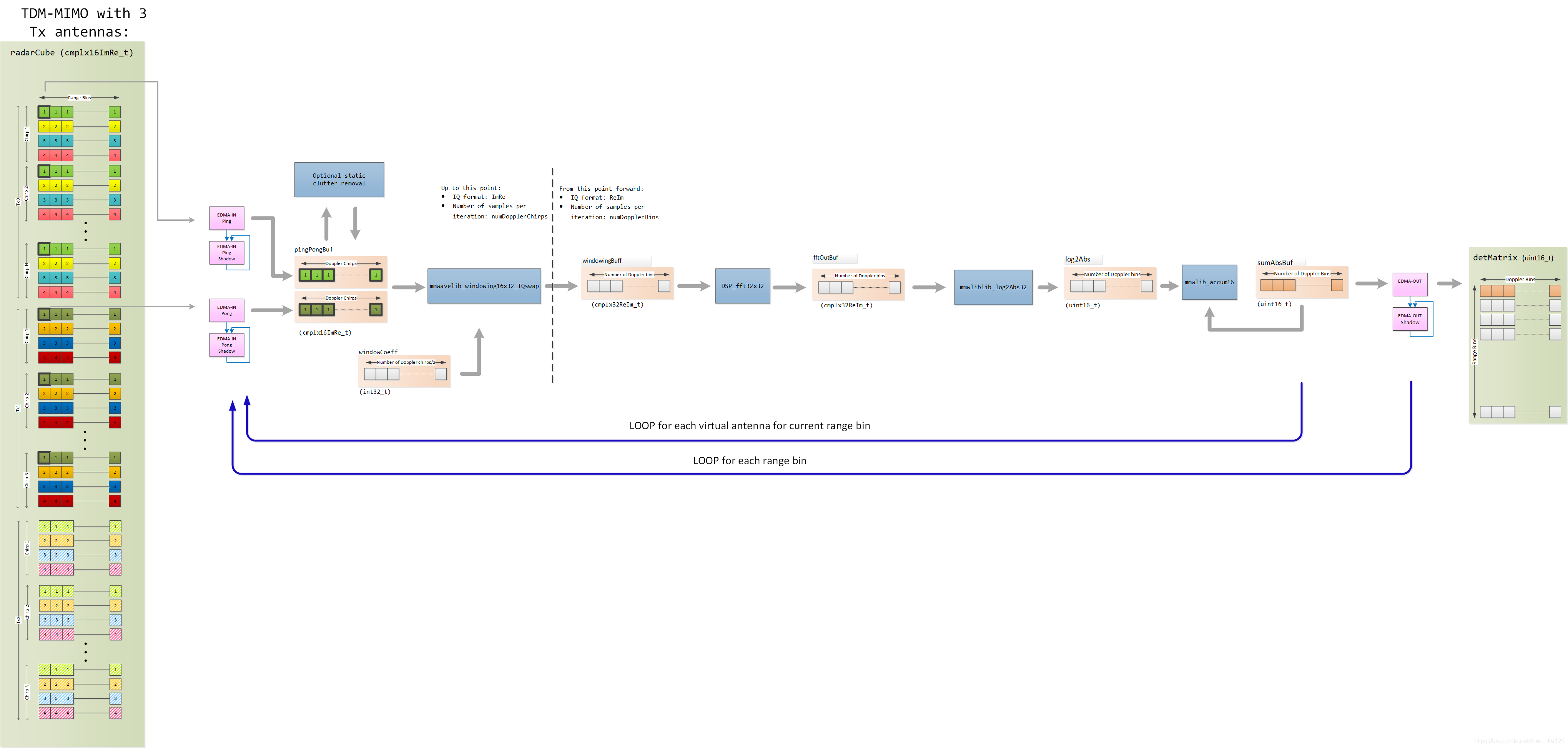
下图说明了3个TX和4个RX天线情况下的ping/pong模式

BPM Scheme
与TDM-MIMO类似,在BPM方案中,帧由多个块组成,每个块由2个chirp间隔组成。然而,与TDM-MIMO中每个chirp间隔中有两个发射天线是活动的。此DPU仅支持带有两个TX天线(如A和B)的BPM方案。在偶数时隙(0,2,……)中,两个发射天线应配置为以正相位进行传输,即
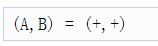
在奇数时隙(1,3……)中,发射天线应配置为相位发射
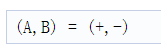
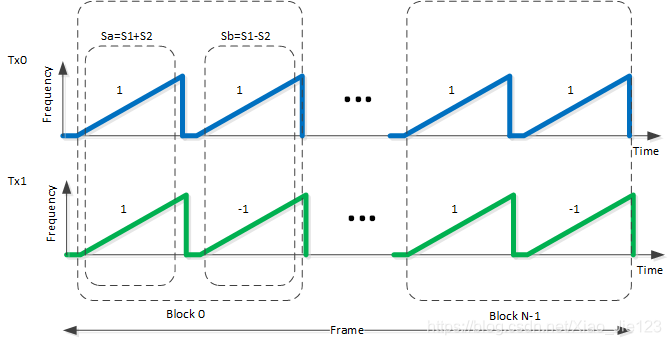
BPM方案如下图所示,其中TX0用作天线A并且TX1用作天线B
BPM decoding
让S1和S2表示来自两个TX天线的chirp信号。在时隙零点,发送组和信号Sa=S1+S2。相似地,在时序1中,发送组合信号Sb=S1-S2。使用相应的接收信号(S’a和S’b),在特定接收的RX天线处,使用
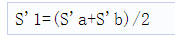
和
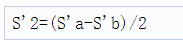
在两个发射天线上同时传输时,每个chirp间隔的总发射功率增加,并且这可以转换为3dB的信噪比改善。
Order of the TX antennas in the BPM scheme
BPM解码将按照(A,B),而不是(B,A)的顺序产生虚拟天线阵列,这将用于AoA处理。因此用户必须确保到物理发射天线的(A,B)映射对应于预期的虚拟天线顺序。以6843 EVM天线布置为例,如下图所示。注意,DPU将TX天线索引为(TX0、TX1、TX2),在设备中对应于(TX1、TX2、TX3)。
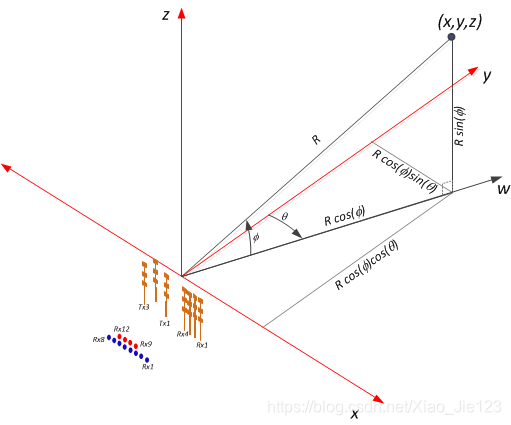
这里,两个天线TX1和TX3可以在方位角方向创建一个8个天线的虚拟阵列。为了确保AoA计算的正确虚拟天线处理,在BPM解码之后,TX1虚拟天线应该在TX3之前,因为当TX1在TX3之前(BPM解码后,其结果基本上应该类似于TDM-MIMO)。因此,A=TX1和B=TX3。换句话说,BPM的配置为
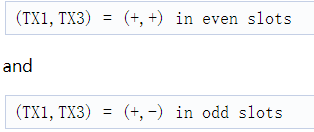
反过来排列将是错误的
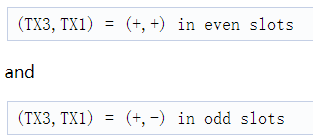
Doppler DPU changes when BPM is enabled
启用BPM时,多普勒DPU处理中会进行以下的修改:
多普勒FFT之后进行多普勒补偿和BPM解码。注意,解码后的数据没有存储在radar cube中,因此需要在波达方向计算期间再次进行BPM解码(在更小的样本集上)。下图显示了在多普勒处理中所需要的改变。当BPM启用时,fftOutBuf缓冲区的大小将加倍,以同时容纳Ping(TX0+TX1)和Pong(TX0-TX1),以便BPM可以被解码,解码后的数据被写回fftOutBuf
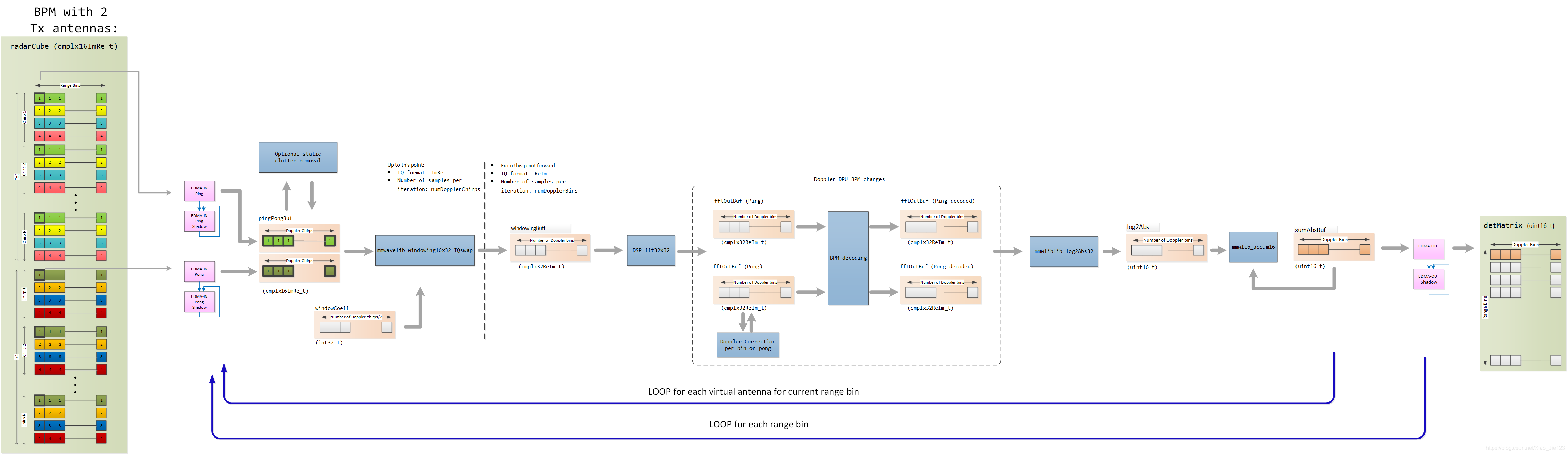
下图显示了2个TX和4个RX天线情况下的ping/pong模式(无论是否启用BPM)
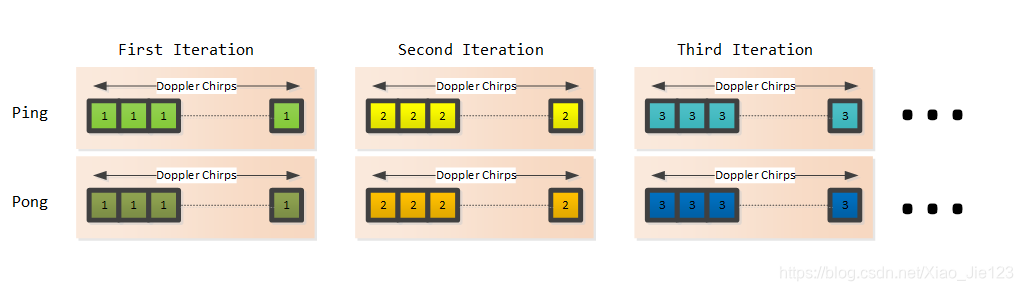
Exported APIs
DPU初始化通过DPU_DopplerProcDSP_init来完成
DPU配置由DPU_DopplerProcDSP_config来完成。只有在DPU初始化后才能进行配置。配置参数在DPU_DopplerProcDSP_Config中描述
DPU通过调用DPU_DopplerProcDSP_process来执行
参考文献:
- 《mmWave SDK Module Documentation》