1 一些说明
音视频技术,本身纷繁复杂,对于初学者来说可不那么容易。网上没有一门系统讲解音视频技术知识与实战的课程。更可怕的是,网上的内容和讲解的水平参差不齐,漏洞百出,那基本上全是坑。有很多人就是掉到坑里,爬不出来了。
对音视频基础知识的系统掌握程度实际决定着你今后能够走多远走多高。俗话说得好 基础不牢地动山摇,那对于音视频开发来说就尤其如此。一个小的知识点掌握得不好,就有可能卡你好几天。
把基础的音视频知识学习好,才能学习其他更高阶的东西,这样对于工作才能游刃有余。
并且音视频基础知识都是音视频面试环节中必不可少的面试点,比如说gop是什么,为什么会产生花屏和卡顿,关键帧的时间间隔是多长等等这些呢。都是我们面试中,经常被问到的问题。所以你掌握了音视频的工作原理之后,才能应对面试官提出的原理性问题。
那么了解了原理之后,采集编码,可以开始学习流媒体服务器,那在流媒体服务器这一块呢,我们首先可以学习Nginx来搭建一个最初级的自己环境内部的流媒体服务器,那么通过这个服务器呢我们就可以进行推流和拉流了。那么之后,可以看看SRS。SRS是一个比较成熟的这个商业方案。如果你的公司具有一定的资源能够拿到很多的硬件资源的话,那你完全可以通过srs搭建一套可以商用化的流媒体服务集群,那你说我自己的公司或者是我自己的这个掌握资源也没有这么多,那这个时候呢如果你还想打造这种商业的媒体服务器,其实还有一种办法就是通过CDN网络。那么有很多的cdn厂商了,包括阿里对吧腾讯等等等等。
相对来说呢,音视频的知识比较庞杂枯燥,有很多很小很琐碎的知识点,这也是为什么在网上很难找到比较系统的介绍音视频知识的资源。
本文为学习笔记,所以里面会有很多乱七八糟重叠或是引用一些大佬的见解,冒犯之处,见谅。
2 音频介绍
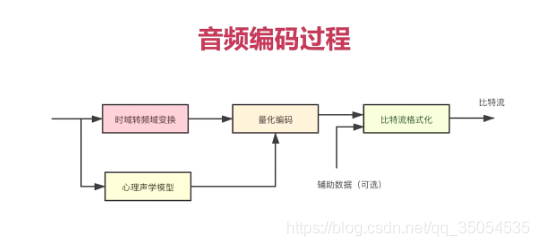
2-1 音视频处理流程
在讲解音频之前呢,我们首先来了解一下音频的整个处理流程,对于这个处理流程的了解。对于我们后边学习音频有个至关重要的作用。
整个在音频处理的过程中它需要经历几个步骤。对于每一个不同的步骤你都应该做哪些事情。你需要清楚整个的这个音频流转的大的这个方向是什么。
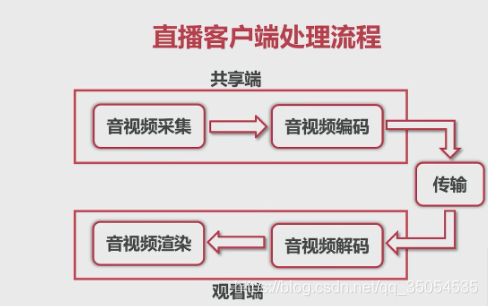
首先对于音频的处理流程,实际是包括了两个层面的。(基于这个娱乐直播系统作为这个背景)
第一个层面,是直播客户端的处理流程。
第二个层面呢,是这个音频数据的流转,也就是说当我采集后。那采集的是什么数据,在我编码之后编码出的是什么格式。
下面呢,我们就来看一下直播客户端的这个处理流程。我们在进行这个直播客户端编写的过程中啊。要分成几个模块,那对于不同的模块,你要做不同的事情。那么对于音频来讲呢,首先你要做的事情就是音频的采集。对音频的采集实际我们只要调一些相关的api就可以了,并不是特别的复杂,但是对于不同的平台。这些api其实是完全不一样的,比如说我们在这个安卓端他有audio_record还有media_records,那我们什么时候应该使用audio recording,什么时候应该用media record。那在这个ios端的也有很多的录制音频的方法,比如其实大家最常用的可能是…这是非常底层的一层api,在它的上层呢,其实还有av foundation这一层的api,那我们又该如何选择呢 ,那这些呢,其实都是我们必须要知道的,对于我们后边深入的学习音视频必须要知道的。但是在知道这一切之前,我们应该知道对于音频来说,你第一步要做的事情就应该是从你的麦克风上,你的音频设备上将这些数据抓取到,这是我们这个直播客户端要做的第一件事,就就是音频的采集,那当你采集完音频之后。那你要想传输实际再说并不能直接进行传输,为什么呢。因为这时候采集的数据它的数据量是非常大的。当你要直接放入到网上给他传入到对端的时候,那就很有可能由于你的数据量比较大,从而将整个的这个网络线路给打死。让大家想到的办法就是将这个非常大的音频也好,视频也好,进行一个编码,编码后的数据就是非常小的数据了。它对于编码这块的具体的分为有损编码跟无损编码,对吧,什么时候应该用有损,什么应该无损。那么有损是去掉了哪些数据,这些呢下面会说明。
那这就是我们的这个客户端的一个共享端,客户端应该是有共享端和观看端两个端,要共享端做的就是这个音视频的采集,采集完编码,编码完传输到对端。那对端就是观看端,那首先他要将接收到的所有的数据先进行解码。扬声器让他去播放那个声音,但它是没法播放的,他必须要将原来压缩后的数据,解码后,还原回原始的数据,那么拿到原始数据之后呢才能交给这个播放器,如果是视频的话应该是交给渲染器进行渲染,如果音频的话交给扬声器直接播放出来。由driver再驱动硬件模块将声音播放出来。
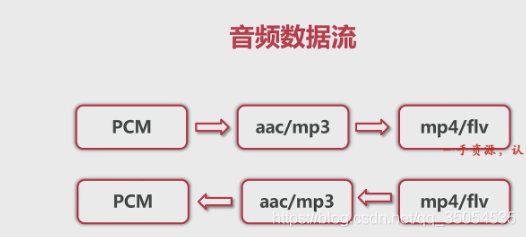
当我们通过 audio record 、media records或者是这个audio unit类似的这些api去做这件事的时候去采集数据的时候。那么现在我们 只要知道我们采集的数据就是PCM,他是一个数字信号。我们自然中说话的这种声音,各种声音它是一种模拟信号。将模拟信号转成数字信号,这个数字信号的就是PCM数据。那拿到这个PCM数据之后经过编码器(那就有很多的编码器了,我们知道的比较熟悉的有AAC编码器,mp3编码器对吧)。经过这个编码器之后呢就编译出相应的编码格式。拿到压缩(编码)后的数据之后我们可以在它外层,给它套一个套,相当于给她穿了一件马甲。那么给它套了一层这个格式之后,就产生了这样一种格式的多媒体文件。
对于我们的直播系统来说呢,采集的时候你采集出PCM。编码后的编码成具体的这个压缩后的数据直接进行传输了,而没有生成多媒体文件,但是有些情况下呢,你可能需要生成多媒体文件。
2-2 声音是如何被听到的

2-3 声音的三要素
2-4 模数转换
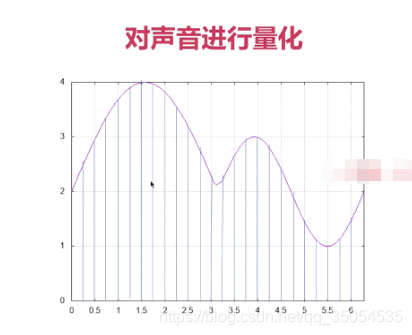
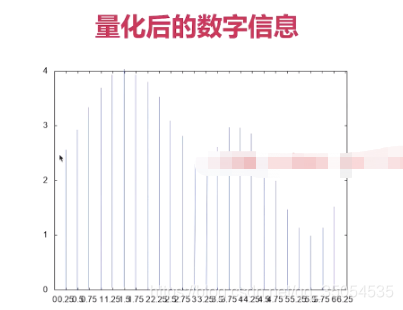
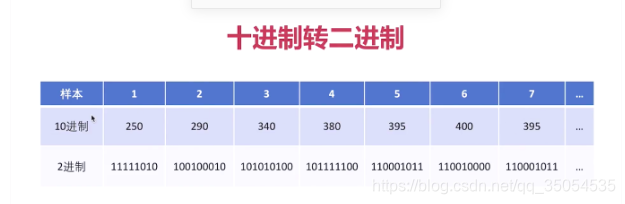
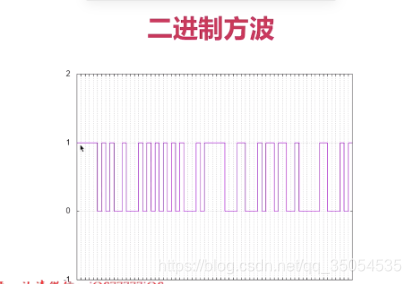
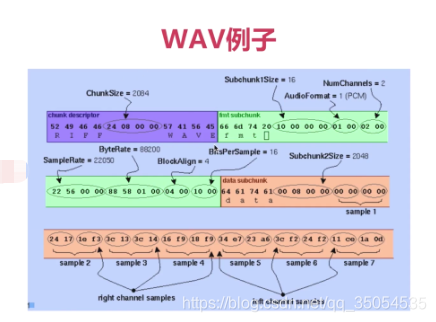
2-5 PCM与WAV
对于音频来说,有一个位深或者需要采样大小的一个概念。这个采样大小是什么意思呢,就是说你能够表述的这个数值的最大范围值是多少。一般情况下呢,是使用八位或者是16位,八位呢它是表述的范围就是负128到正128,无符号数就是0到255,如果是16位就是负32768到正32768,这样一个范围,他们表现的这个值呢,是非常大的。

对于音频的原始数据来说,它包括这三个重要的概念, 但在介绍这个之前呢,我们首先要知道我们要存储音频的原始数据的格式是什么,那实际上最常用的有两种格式了。PCM和wav,这个PCM数据就是纯的音频数据,他没有任何的格式,对于PCM数据来说,里边的每一个数据,它是有一定的含义的。如果你把它封装成一个多媒体文件的话,就有了一个文件格式的概念,就是wav,WAV呢,你既可以存储原始数据就是PCM数据,也可以存储这个压缩数据。但是大多数情况下,99%我们都用wav来存储原始数据,也就是PCM数据,那什么意思呢。其实WAV他就是在pcm这个原始数据之上, 套了一个头,这个头呢包含了一些最基本的信息。现在我们只要知道对于音频的原始数据来说。一种是PCM数据,它是纯的音频数据。另外 一种是在PCM上加了一个头的wav。

那么我们再来看看 这个量化的基本概念啊,现在我们来一一看一下,第一个就是采用大小或者说是有的地方叫做位深,就是说你的这个位深 越大,它描述的这个峰值就越大, 描述的峰值越大,那么这个对于我们一段声音的波形来说,他的这个声音的强度其实是更真实的。
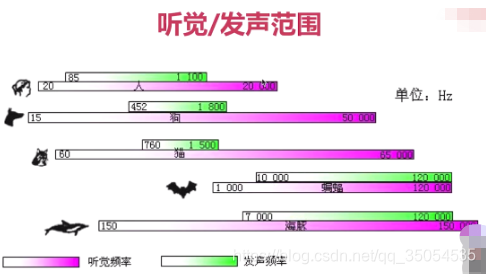
他第二个呢是采样率。就是说对于一段音频波形来说,我们进行这个模数转换的时候。那我是按照什么样的这个频率采样了,这都是我们常见的采样率,采样率越高。与模拟信号之间的模仿呢就越接近,对吧,它的误差就越小。那么你采样率越低,那么有一些很敏感的信息他就忽略掉了,对于我们通常打电话来说一般都是8k的采样率。
那么第三个呢 就是声道数,那分为单声道双声道和多声道或者我们称为立体声。三个以上的就称为立体声了 ,有的认为是两个是立体声,这个没关系,我们只要知道这个声道数其实是在我们这个听声音的时候是非常关键的一个要素就好了,但实际就是对于我们正常人来说分为左耳和右耳。实际它就是双声道,左耳听到一个声音,右耳听到一个声音,当然。这个双声道的时候,可能两个声道的声音可以是一模一样的 ,也可以两个声音是有不同的。对于多声道,我们可以想像在我们的一个电脑上我可以摆六个喇叭,那每一个喇叭呢就是一个声道。这样呢 如果他把你环抱起来的话,实际就是形成了一个立体声,就在前后左右上下很多的方向你都可以放一个喇叭这样你的感受的音响的效果就会更好,比如说我们在电影院啊你听到那个声音就非常震撼。但是如果同样的影片你拿到电脑上去我们的普通耳机去听的话那就效果就会差很多,对就是这个道理。
所以我们进行这个量化的时候有三个概念。PCM数据就是你的采样大小乘以你的采样率,乘以你的声道数,就是一个采样,就一秒钟的采样了多少,这数据是多少。
正常网络,比如我们是十兆的光纤,上行和下行其实它是有一个比例的,下行是10M,但是上行可能只有2M,4M,你光传一个音频就是被压缩的音频就非常的这个困难。可以这么大的码流显然是无法在我们的网上传输的,所以我们要进行这个数据的压缩压缩后的数据就非常小了

3 音频的编码技术
3-1 音频有损压缩技术


那所谓的音频编码呢,实际就是音频的压缩技术。
对于音频压缩技术来说。他实际是追求两个极端,第一个极端是将数据量压缩得越来越小对越小越好,对吧,第二个极端是压缩的速度越快越好,当然这两个极端来说,它是有一些这个悖论的,很难达到既压缩得最小,又能压缩的最快。一般情况下呢,要寻求一个平衡点。就是说我压缩的点已经适合于网络传输了,那么同时呢他速度又特别快。这个编解码技术。是最适合我们的实时通讯传输的,这是我们最喜欢的一种编码技术ok。
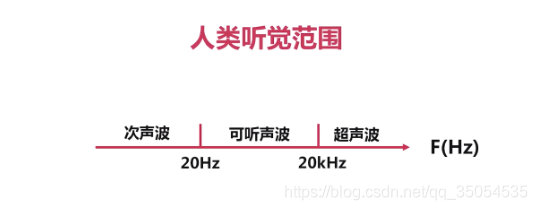
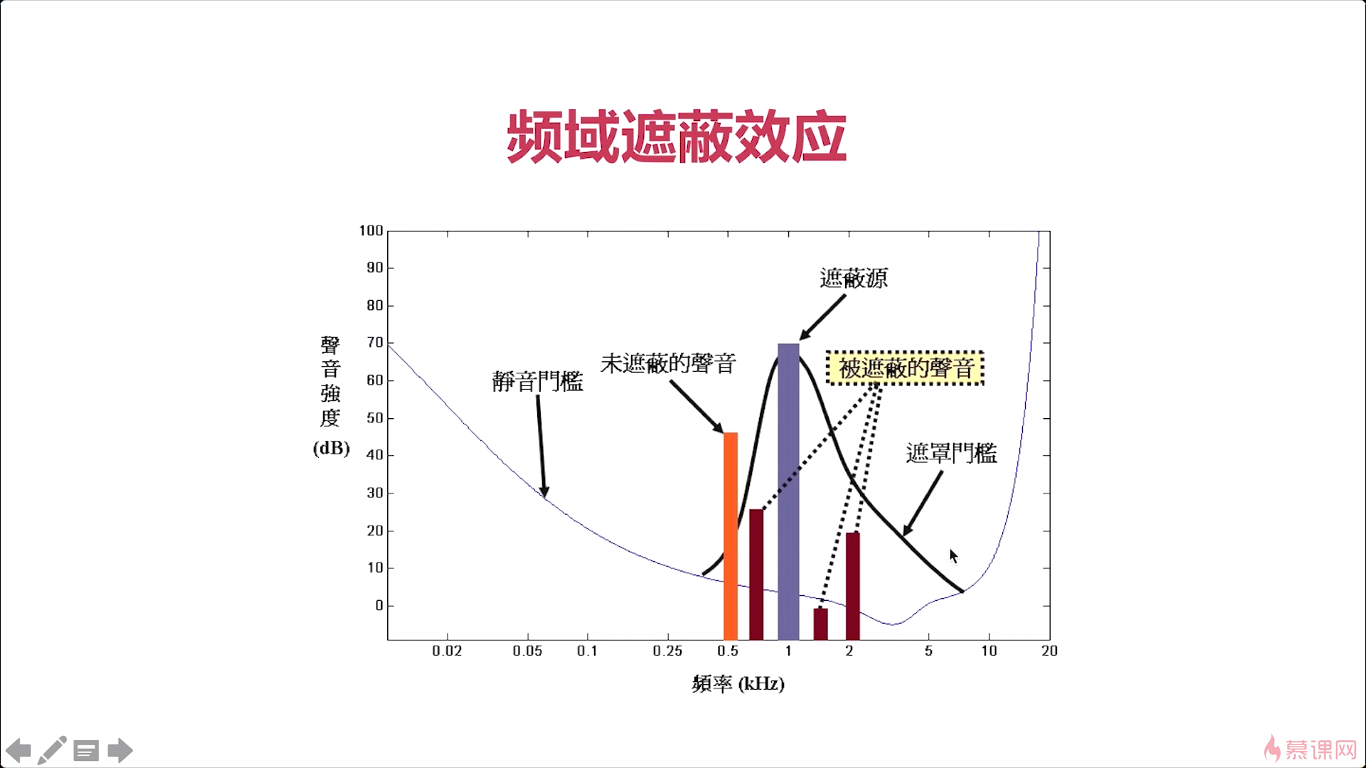
对于我们这个音频的压缩来说。那所谓的消除冗余信息,我们应该有一些了解,比如说我们所讲的人的听觉范围是在哪呢。是在20赫兹以上到两万赫兹以下,这段其实是我对于我们人来说是最敏感的,对吧那根据这个原则。20一下以及两万赫兹以上的这个数据,其实我们采集到了但也是没有任何意义的数据,对吧所以这些信息呢都属于冗余信息。对于这部分信息我们都应该将它踢除掉对而且这些信息t除掉之后,它就没法再恢复回和原来一模一样了,对吧所以这也称为什么呢称为有损压缩,这所谓有损压缩技术就是说当我们把数据进行压缩之后就无法再还原回和原来一模一样的信息吧。
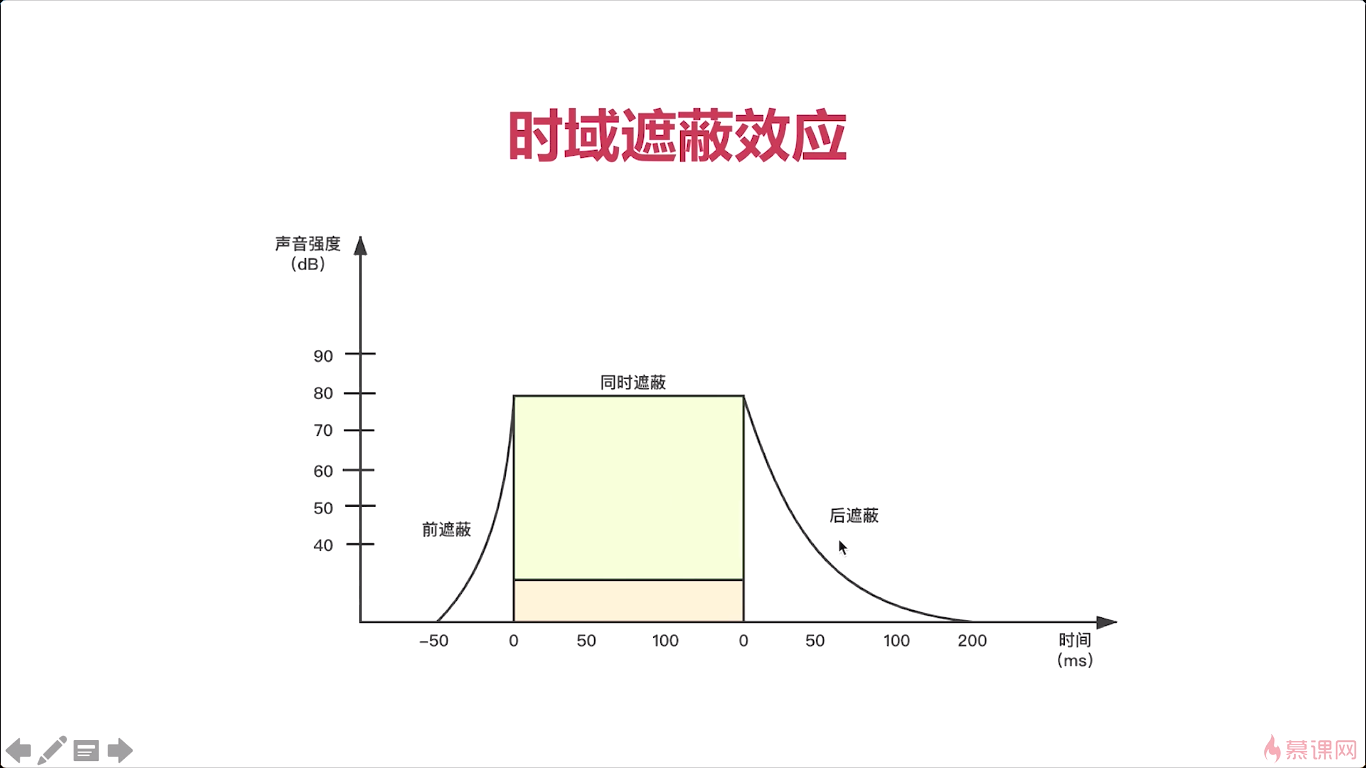
那第二种呢就是无损压缩。剩下的就是我们人比较敏感的一些具体信息,但对于这些信息呢我们在进行一下无损压缩,让他这个数据量变得更小,那这样就达到了一个非常好的压缩效果对吧,像无损压缩技术比如说我们传统7z…等等,
3-2 音频无损压缩技术
熵编码是一系列技术的统称。

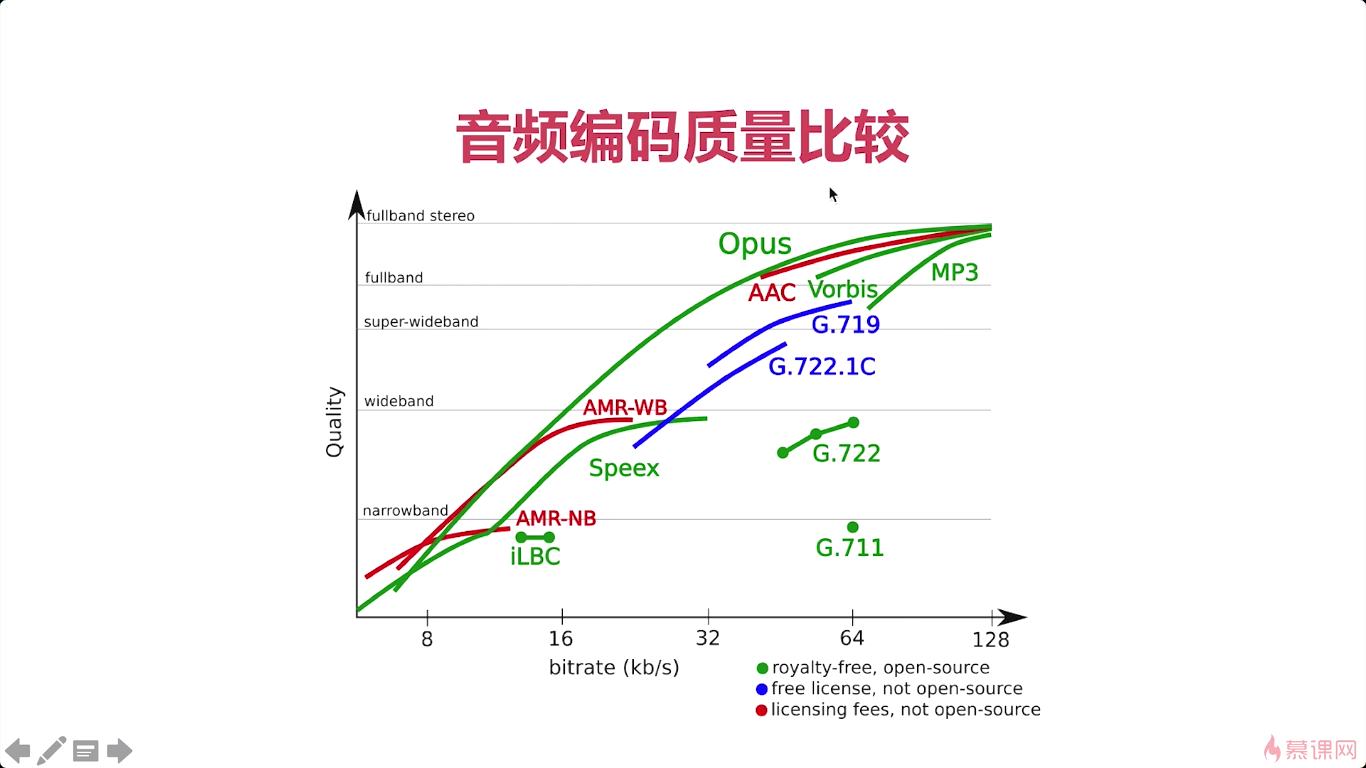
3-3 几种常见编解码器的比较
OPUS它有什么特点呢第一个是延迟小第二个是压缩率高。做实时通讯的相关应用的,基本上都使用的是OPUS。
AAC呢可以说是目前应用最广泛的一款编解码器。
OGG由于它是这个收费的,所以应用的不如前面这两款呢应用的广泛.
那在他们之前呢其实speek是应用的相对比较广泛的一款编解码器,它有一个非常好的一个功能,就是它包括了这个回音消除,这个功能那在之前的这种实时通讯的领域中呢那回音消除可以说是一个非常难以解决的问题.
G.711是属于窄带音频,也就是说它编码后的这个数据呢非常小,适合于在非常窄的这个网络上进行传输。但是它有一个非常不好的一点就是它的这个声音损耗特别严重。像我们正常的通话他都有失真的这种情况。如果你要是播放一些音乐文件,乐器的一个声音,其实听起来要保真性要特别好才行,他就不适合
由于webrtc,所以OPUS在未来大概率会把AAC淘汰掉

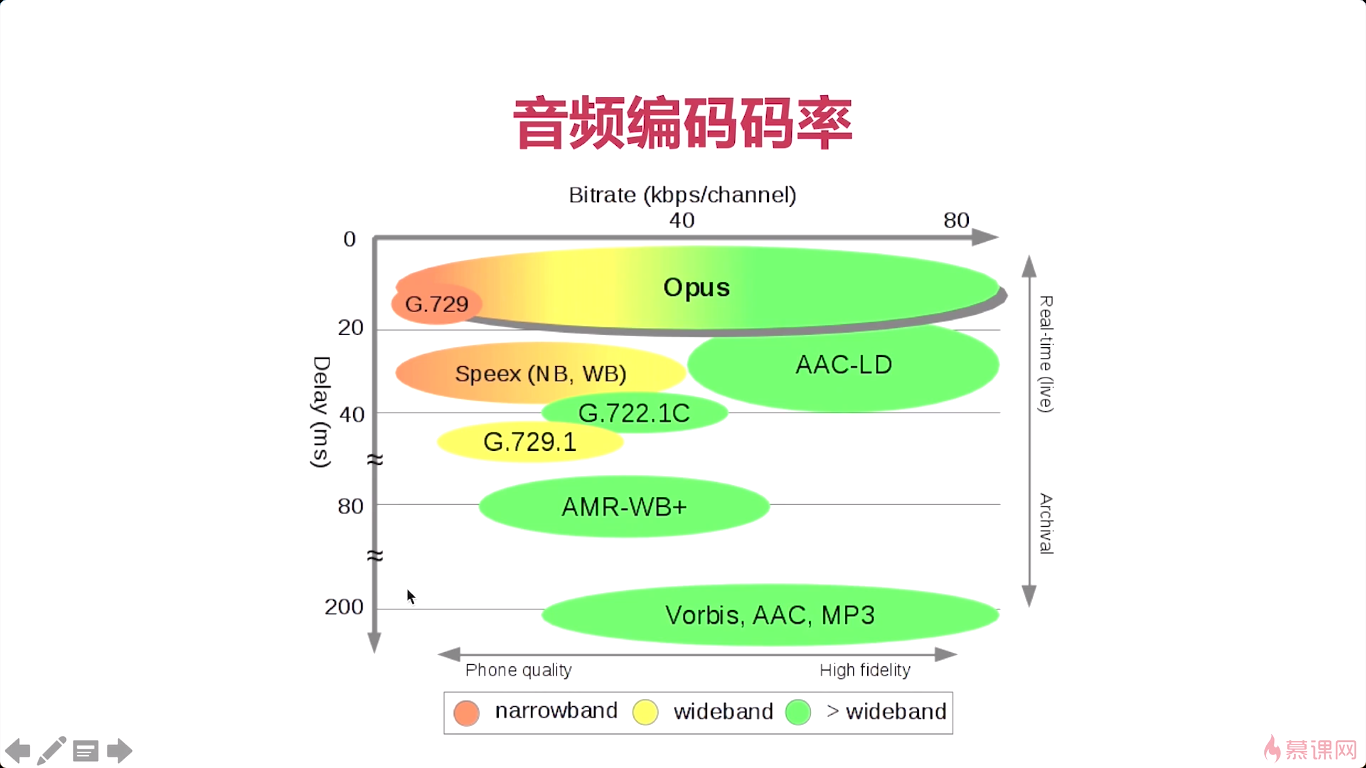
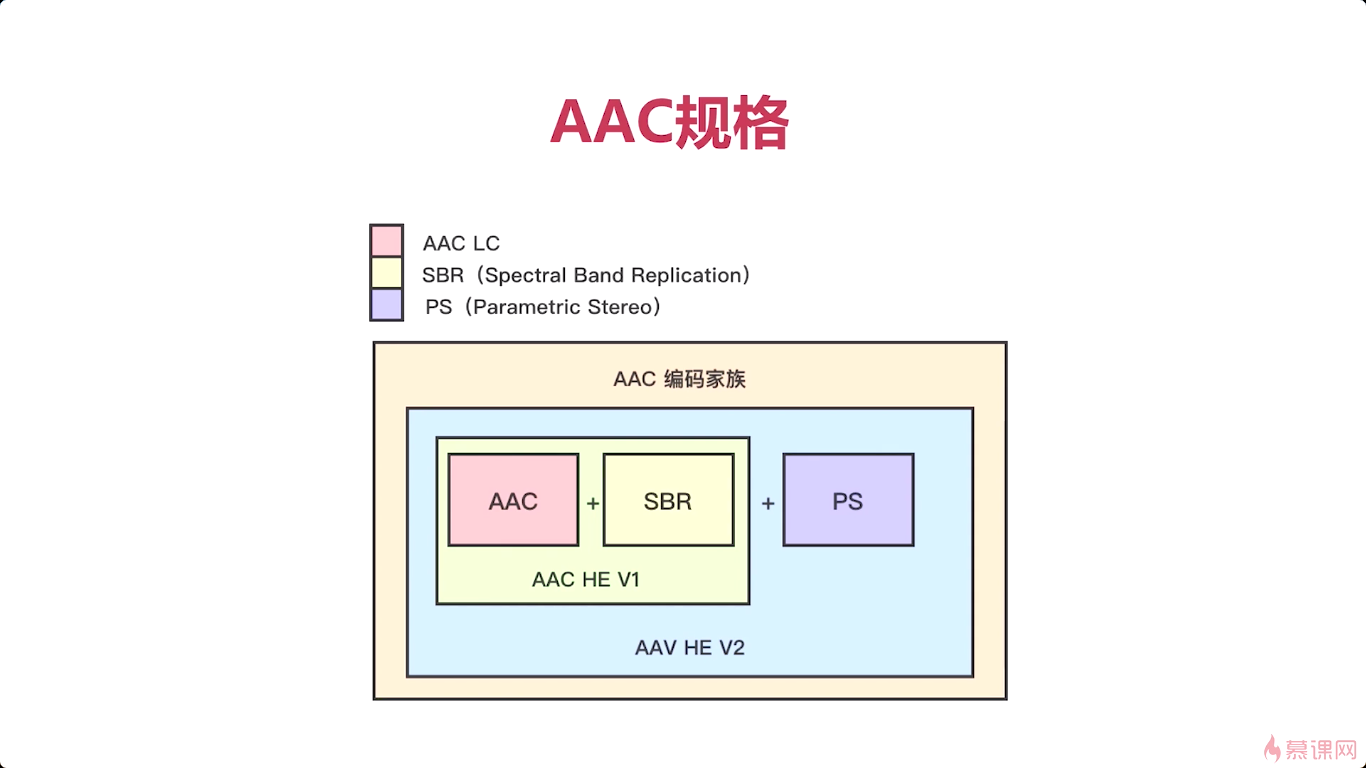
3-4 AAC编码器介绍
那么在这么多的编解码器中呢。其实目前常用的编解码器就两种OPUS,AAC。
aac呢可以说是最成熟而且是应用最广泛的一种编解码器,那么对于每一种编解码器来说其实他都有各自的特点,你要想使用某一种编解码器的。你需要对它做一个深入的研究,而这里,我们使用的编解码器主要是aac,所以让我们对aac作一下重点的这个讲解,首先呢我们要知道AAC是由何而来的对吧它.
他的目的呢就是取代这个mp3,因为mp3相对来说他的存储的这个文件压缩比,还是比较低啊,压缩后的文件比较大…
AAC两个优点,压缩率高,保真性好。
AAC LC、AAC HE V2比较常用,AAC HE V1用的比较少,基本被V2取代。



3-5 ADTS格式




3-6 通过ffmpeg生成AAC数据
-i : input
-vn : video none
-c:a :codec audio
libfdk_aac应该算是AAC编解码器中性能最好的一款编解码器
-ar :audio sample_rate
-channel 双声道


4 音频操作
4-1 什么是音频重采样

三元组中任意一组值发生改变,都叫重采样。
采样大小(比如16位),有的地方叫位深。

那么另外一个呢就是便于方便运算,比如说我们在处理音频的时候有一个非常有名的一个问题,就是回音消除问题对吧。在一般的回音消除的时候,我们都会将这个音频的声道呢变成单声道。为什么呢,因为在处理回音消除的时候,只有一个声道的时候,这个数据是最单纯的,是最好处理的,如果你是多声道的时候,两个声道很有可能他那个声音是不一样,对吧,我们在听一个比较高音质的音频的时候,你会发现左声道和右声道他们是有一些差别的,有的是低音重一些,有的是这个高音重一些对吧,反正就是总是有一些不一样,他会达到一个非常好的一个效果。让他们两个声道保持一些差别,让你听出来的声音呢更有立体感,那这样就给这个回音消除造成了很大的这个困难,你左边的声道是这样,右边声道是这样,我应该怎么消除呢,它很难计算。所以这个时候呢,一般我们会把双声道变成这个单声道呢。那这样呢就为了便于我们的运算。

FFMPEG是跨平台的,所以它上面都有大部分平台的设备参数


5 图像的基本知识、YUV
5-1 图像的基本概念

就是它是由一组图像组成。为了传输或者是占用更小的空间而被压缩的。一般情况下呢,在显示设备上进行显示的数据,叫做视频。一般情况下我们所说的这个视频呢都是经过压缩的。主要是为了占用更小的空间或者是在传输的过程中呢。它这个传输的数据量比较小,所以要进行一个压缩,否则的话它就占用的空间特别大。那他最终在哪显示呢,就是在这个显示设备上。那通过这个简单的定义呢我们就知道这个关键点了,图象、压缩和显示设备。那下面呢我们就对这几个关键词呢一一做一下讲解。
图像呢,它是由像素组成的,大家都非常清楚。在这里呢我们可以看一下这个这张小图。这张小图 呢是有很多的小格子组成的。当然,这里面呢这个清楚的表达我这个含义呢,在每个小格子这个边上呢都有一个线。那真实的在显示设备上去看的时候,它不可能出现这个线路。所以那通过这些小格子的拼装呢,我们就能拼装成一张图是吧。这是像素。而像素都是RGB组成的,每一个像素它的颜色都是通过rgb来展示出来的。再有一个重要的概念呢,就是分辨率。那这么多的小格子这么多的像素,它就有一个分辨率。所谓的分辨率呢,其实就是你这个横向x轴有多少个像素,纵向有多少个像素。他的这个乘积,也就是说整个这张图是有多少个像素点描述出来的。

上面的图呢,就是像素,可在这一个像素中实际在显示器上呢。就是由三个发光二极管然后组成的,一个是红色一个是绿色一个蓝色。
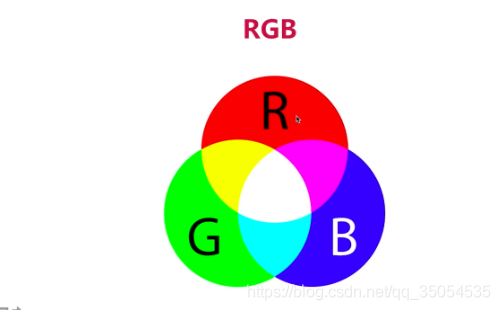

对于RGB来说呢,就是每一个像素是由三个发光二极管不同的颜色组成的,对吧.那当每个发光二极管显示的亮度不一样的时候,它们就组成了各种不一样的颜色。

那对于每一个像素来说呢,它还是有一定的位深的,所谓位深就是我们用多少个位,来表示一个像素。我们来看一下那最常见的呢,是RGB888,就是每一个元素呢,是占一个字节,是占用八位,所以一个RGB呢,它是由24位组成的,这是我们通常情况下的这个数据。
它还有一种呢,是RGBA,它是占32位。它的含义呢,就是透明度。也就是说你这个颜色他的这个透明度是什么样子的。那有的呢,是完全不透明的还有是半透明的。那通过什么来控制的呢,实际上就是通过这个A。 RGBA这种方式呢他就是在用32位。最后一位用来控制A的,也就是它的这个透明度是多少。
5-2 屏幕显示器
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VU1KNMLr-1610356447473)(https://uploader.shimo.im/f/CUmnUBKMdBNcPkZH.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]](https://img-blog.csdnimg.cn/20210303214038840.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1MDU0NTM1,size_16,color_FFFFFF,t_70)
先来看一下像素,其实像素的概念最原始的就是从显示器来的。因为你要显示 吗,才会有像素,那将每一个点都点亮。每一个点都有不同的颜色,最终将它拼成一幅图,这才是真正像素,它的由来对吧。而对于我们图像来说呢。为了能够让我们的显示器,让哪个像素点亮,哪个不亮,每个像素点显示不同的颜色。对吧,所以我们这个图像也就是说它的数据也要对应有像素的概念。所以一谈到像素,就是有两个方面的,一个是我们的显示器是有像素的,另一方面呢是我们的图像数据是有像素的。

那么如果我们用显微镜去看一下我们屏幕的话,其实我们的屏幕就是这个样子。每一个点其实都是由三个发光二极管组成的。就是红绿蓝对吧,我们这么看,从右往左看,红绿蓝每个都是红绿蓝、红绿蓝、RGB,对吧。那有无数的这些发光二极管,最终呢,组成了我们整个的屏幕,而 每三个发光二极管红绿蓝就组成了一个像素。根据我们图像的数据,它是什么颜色的,然后去控制这个发光二极管的强弱,光的强度跟弱度,从而最终形成我们不同的颜色,最终拼在一起呢,就形成了我们真正看到的图像,对吧。ok这就是屏幕。

好,那图像与屏幕的关系通过我们刚才的这个介绍啊。你应该已经基本清楚了。那图像呢它是数据对吧。最终会通过数据来驱动整个屏幕,去显示。ok这就是图像与屏幕的关系。

好了解了这个之后呢。后边我们在展示的时候那你就非常容易理解了。另外一个我们需要知道的就是rgb的颜色问题,实际上实际生活中,我们RGB图像,在很多情况下,并不是RGB,它是BGR。有同学就会发现就有一些图像你在展示的时候,它的颜色实际上是不对的。就是因为它本身数据不是RGB而是BGR。也是三原色, 但是它们排列的顺序不一样了,这样就导致了你最终送给这个显示器显示的时候,是你送的是BGR数据,这个对于显示器的驱动来说,他并不知道你送的是BGR啊。它还按着RGB的数据去解释,屏幕上去渲染,这样造成什么问题呢,就造成你的色彩与真实的色彩是不一样的。所以我们要做的时候,怎么做呢?其实对于这种BGR数据,把它转换成RGB数据,转换完了之后你再去渲染的时候这个问题就迎刃而解了对吧。知道原理之后,你才能知道问题的根源是在哪,他有很多同学。在这个底下就会问我,说为什么我这个图片展示的时候以真实的那个图片展示不一样,或者说我自己编的程序展示出来了这个颜色不对,而别人用别的图片浏览器去看的时候呢,颜色是对的,什么原因呢,其实就是这个原因,非常简单,你只要知道这个原理就特别容易去解决这个问题对吧。
那什么数据使用的是BGR这个格式呢?就是bmp这种格式。所以我们在播放bmp这个图像的时候。一定要想着先进行一次转换。再进行展示就ok了,那一般的情况下我们用什么库或者说是怎么写这个函数去将转成RGB呢,一种方法呢,是你了解他整个的结构之后,你自己去写一个程序就转换,对吧这其实非常好写,只不过顺序做一下变化。你读出每一个像素点的值给他做一下转换。再重新存进去就ok了 这是一种方式,那还有一种方式呢,就是我们用别人写好,现成的库去做这件事。比如所FFMPEG库,它里边有一个LIB_SW_square,那就是专门做这个事了,也不是专门做这个事的,算是是其中的一个小的功能对吧,你调一下这个api就可以完成转化了。这是RGB的一个色彩问题。

好,另外呢,我们还要了解一下这个屏幕的指标,那经常我们会看到一些指标它是什么含义对吧,第一个呢是ppi,就是每英寸的这个像素数。比如说我们手机上经常会看到这个PPI,其实它跟分辨率呢是很类似的,但是他这个指标呢,就是你这个屏幕,比如说横向的,在这个一寸长的距离内,一共放了多少个像素点,当然你放的像素点越多。说明你的密度越大,他的这个显示效果就更细腻,就会更好对吧。 那我们就能知道如果你像素密度特别多的话,那你这个屏幕一定是一块比较好的屏幕。因为你这个空间很小嘛,空间很小,你能放那么多的二极管 ,那说明那个技术非常厉害了对吧。
第二个呢是DPI,是指的每英寸的点数。实际这个ppi和dpi基本就是相同的。是一对一的关系,但是对于有些屏幕来说呢,这个dpi是每英寸的点数。对于每一个点来说,他有可能包括的不只是一个像素,可能是多个像素。对于这种屏幕呢其实是比较少见的,基本上是ppi就等于dpi。这个稍作了解就OK.
那有一个指标啊,PPI>300,再一寸这么大的一个距离里呢,如果你能放300个以上的像素,那就达到了视网膜的级别。所谓的 视网膜级别,就是我们人眼已经区分不出来它里边儿是由像素组成的,对吧,就认为它就是一块的东西。我们就认为他们是一体的,并不能看出里边儿每一个小的点对吧。这也就是屏幕的指标。
5-3 码流的计算

我们来介绍一下,码流的计算。对于码流的计算呢,我们首先要知道两个简单而且非常重要的概念。第一个是分辨率,第二个 呢是帧率。
x轴乘以y轴的像素个数。那当然我们一般的时候就是通过这个x来表达。他并不需要真正计算出他到底等于多少。其实我们想知道的就是它宽是多大高是多大。常见的宽高比呢,16:9或者是四比三,对于四比三来说大家可能见得比较少了,比如说像我们以前看的电视机。都是四比三的,还有包括我们以前非常老的这种显示器,像九几年的时候,我们那个显示器呢就是方方正正的那种。基本上都是四比三的这个显示器。看随着这个技术的发展呢现在基本上都是16比九的。对于视频来说那几乎都是16比九。那这两个呢其实都是我们的一个常规的格式。那如果你的这个视频呢,这个宽高不是这种16比九或者四比三的,那它属于一个非标准的这个视频的分辨率。那对于这种分辨率呢其实我们要做一次转换,要把它转换成四比三或者16比九。有很多时候呢我们在做这种这个渲染的时候啊。不是这两种情况下,那你在渲染的时候呢,就会容易出错,渲染出这个结果呢,与你想达到的结果并不符合你的预期。所以我们在拿到这个非标准化的时候一定要想着先把它转成这个16比九或四比三,之后呢我们再去渲染这样,才是一个标准的流程。其实这些最基本的概念其实是非常重要的对吧。很多的问题都是由于你概念的不清楚。才导致了这个你最终费了九牛二虎之力。可能是为了解决一个问题花了一周或者两周的时间还解决不好。最根本的原因就在于你对这个原理不了解。如果你对这个原理清楚的话,也就是分分钟的时间,那第三个呢就是我们常见的这种分辨率啊,有这个360p,720p,1K,2K。那360p呢其实就是640乘以360,720p呢。这个就是高清了,就是1280乘以720。大家自己去这个看一下就ok了对吧。那等于四比三呢我们常见的是640乘以480。

所谓帧率就是每秒钟采集或者播放图像的个数。对于播放器来说,每秒放多少帧,就是帧率,对于我们采集的设备来说我们要从设备上采集 图像,就是每秒钟我们能采集多少帧,那就是它的帧率。实际上就是每秒钟图像的个数。那对于普通的动画来说,像我们以前的动画片都是25帧每秒。但实际上呢在我们真正的这个远程通讯或者是这个看电影的时候,他们的帧率都是不一样的。比如对于我们实时通讯来说,一般情况下,我们为了调低码流大小,我们会把它设成这个15帧。与你的带宽是有密切关系的,如果你带宽足够的话,当然是越高越好,但是为了保证实时性,防止数据量太大,把你的带宽打死,那么这个时候呢,我们可能会调低你的这个帧率,那最低的情况下呢,一般我们就保持每秒15帧。其实就可以基本满足我们实时通讯的这个要求了,除非说。你的这个通讯时,对这个视频质量要求特别高,比如说我们是远程的教学中的这个绘图对吧,这个时候呢你的这个要求的清晰度跟这个帧率呢,可能会高一些。但对于一般呢,我们只是显示一个头像的话,其实你15帧每秒其实没有任何问题的。
比如录制视频。这种情况下呢,一般我们都是30帧每秒,就满足了我们日常的这个需求了。60帧每秒呢比如我们的这个电影儿对吧,电影在这个拍摄的时候基本上都是在60帧以上的这种帧。那这样呢,可以保证一个非常平滑的一个效果就是每一个细节你都看得非常清楚,尤其是人的面部表情。要求的这个平滑度越高,那对你的这个帧率啊,就要求越高。那对于你显示的清晰程度实际是与分辨率密切相关的,是吧。那你想让这幅图非常的清晰你就分辨率特别高,那你想让那个视频特别平滑那你就帧特别高,ok。

那介绍完这两个概念之后呢,我们现在就来看一下,未编码的这个RGB的码流如何计算。比如说 一个720p的就是1280乘720乘以3乘以25。可最后我们约等于多少呢约等于69兆对吧。但这个是不是这个我们通常所说的码率呢,并不是。我们通常所说的码流是按位来计算的,所以应该是69M再乘以一个8。500多M。

5-4 图像的显示

看今天呢我们就来说一说图像的展示。那所谓的图像呢其实之前的课程中呢我们已经向你介绍过了。它就是用于屏幕显示的数据。在图像与显示器之间呢他有很多概念是相通的。他们中的这个像素呢都是由rgb。这是我们第一个,要知道的那第二个呢他有分辨率的概念对吧。
因为显示器的大小很有可能是不一样的。在不同的场景下我们的这个图像呢应该如何去展示。这里举得这个例子就是图像大小等于显示区域大小。当我们真正去显示的时候并不是说将整个屏幕都是占用了,对吧。我们会写一个这个app,在app里呢有一个显示空间。那这个显示空间呢它也有一个大小,比如说我们默认的720P,那我们图像呢如果也是720p的,那说明这个图像大小等于显示区域大小。那就是1比1的关系,直接将图像放进去之后进行展示就ok了。那还有什么呢,还有这个图像小于显示区域的。可这个时候呢我们就要有两种选择了,一种呢是将图片进行一个拉伸。可拉伸之后呢,符合我们整个显示区域大小之后,然后进行展示,那拉伸之后,图像有可能会发生一些变化,比如变形。那还有一种可能呢,就是说我们这个图像虽然很小,但是它四周有留白,就不用管你的这个显示区域是多大我的图像就这么大。
还有一种case呢,就是图像大于显示区域。那如果你的图像视屏显示区域大的,那也有两种办法那第一种办法呢就是将图像进行缩小。另外我的显示区域就这么大,那你图片很大没关系呀然后我就给你上下左右切掉。




一般情况下我们会左右留白,很少有上下留白的。那这里我举了一个特殊的例子,可能就是这个图像哪儿都比较小。所以要进行四周的留白,当然对于这种情况呢,其实我们做下拉伸之后呢,然后尽量让他两头不留白,左右留白。这是我们一般的做法,当然你所有的图像啊其实都要符合一个原则,你要符合一个16比九或者是四比三的这个比例,那才更好的处理。如果你这个比例不能达到的话。

5-5-1 什么是YUV
简介
YUV是视频、图片、相机等应用中使用的一类图像格式,实际上是所有“YUV”像素格式共有的颜色空间的名称。 与RGB格式(红 - 绿 - 蓝)不同,YUV是用一个称为Y(相当于灰度)的“亮度”分量和两个“色度”分量表示,分别称为U(蓝色投影)和V(红色投影),由此得名。
YUV也可以称为YCbCr,虽然这些术语意味着略有不同,但它们往往会混淆并可互换使用。
Y表示亮度分量:如果只显示Y的话,图像看起来会是一张黑白照。
U(Cb)表示色度分量:是照片蓝色部分去掉亮度(Y)。
V(Cr)表示色度分量:是照片红色部分去掉亮度(Y)。
要说清楚YUV,得分别说清楚以下两点:
- YUV的采样格式:即我们在采集图片、视频帧时,是如何获取每个像素的Y、U、V三个分量的。
- YUV的存储格式:即Y、U、V三个分量的值,是以什么方式存储在内存或者文件中的。
为了理解这两点,破费功夫,只因没有在网上找到比较让人满意的解读。最后找到了两篇文档:
VLC提供的wiki和微软家提供的Video Rendering with 8-Bit YUV Formats
YUV采样格式
什么是扫描线(scan line)
为了说明采样格式,先说明一下待会儿会用的的概念:扫描线
什么是扫描线?这是关于电视显示的术语,用来描述电视是如何显示画面的。wiki中是这么解释的:
电视萤幕由电子枪射出的电子,经由磁场偏向后打在屏幕上而发光,因此每一个图框都由电子枪的扫描线画出来。
大概意思如下图:图片来源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jBtWKQjm-1610356447499)(https://uploader.shimo.im/f/MfVtBnMIUxNUfF0a.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]
电子枪的扫描线从左上角像素点到右下角像素点顺序移动,喷射电子显像。
我猜,这种像素的显示方式也对像素的采样方式产生了影响,YUV采样格式中就大量提到了扫描线,至于这中间是否有什么历史"恩怨",大家如果知道,不妨留言分享。
宏像素 (macropixels)
像素是视频显示的基本单位,因为它代表了屏幕上一个"点"的色彩,通常也会被形象地称为"像素点"。通常RGB格式像素点,会有Red、Green、Blue三个基本像素分量组成。也就是说,只要确定了红、绿、蓝三个像素分量就能确定这个像素将要显示什么。
同理,YUV格式也可以分为三个分量,即Y、U、V一一对应。
但和RGB不一样的是,利用人体眼睛对亮度分量(Y)敏感,而对色度分量(U和V)不敏感的原理,视频可以通过降低色度分量的采样数据,达到降低视频数据量而人眼很难分辨的目的。所以,目前流行的YUV采样,基本都是降低色度分量的采集。
也就是说,一个视频帧中,亮度分量Y的采样数不会被改变,但色度分量U和V会被降低采样数(downsampling)。如此一来,Y、U、V三个分量将无法达到和RGB一样一一对应的效果。
好在YUV所有的格式中,U、V分量的采样数是相等的,只是不同的Y分量之间,需要共享数量不足的UV分量,为了让这个共享更好的表达,YUV出现了宏像素的概念。即:当前格式下,至少需要x个像素点的采样数据,才能将这x个像素点完整表达,这几个像素点组成了一个宏像素,每个像素点称为宏像素点。所谓的完整表达,也就是让所有的Y分量都有对应的UV分量可以使用。
如果看到这里,还不是很懂,你可以先跳过这节,这对后文的阅读影响不是很大。
宏像素的概念,是从微软家的那个文档看到的,但他家没做任何解释,网上也没有。这一节的内容,实际上是本人自己琢磨了好久才总结出来的。受限知识水平,请大家谨慎参考,如果有大神发现有误,请留言帮帮小弟,一拜……再拜……
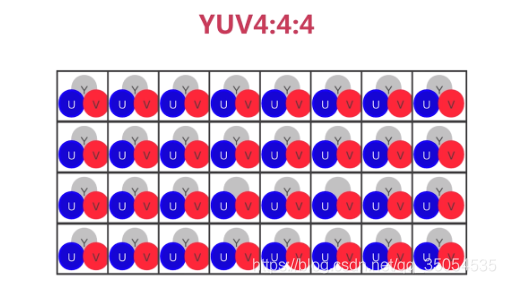
YUV4:4:4
YUV格式,采用A:B:C表示法用于描述UV色度分量相对于Y分量的采样率。这怎么理解呢,以YUV4:4:4为例。
YUV4:4:4的采样方式表示:各采样分量在扫面每个像素点时,都不会降低采样率。
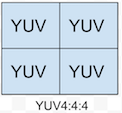
如图,一个方格表示一个像素点,方格中的YUV分别表示有在该像素点采YUV分量。之所以用四个方格显示,是因为YUV格式中,UV分量最小时需要四个像素共享一个UV分量对。同时,共享一个UV分量对的像素点,在平面上和UV分量都有临近的关系,所以这四个像素点不会是同一条扫面线上的点,而是分布在两条扫描线上。
所以,一个宏像素最多容纳四个宏像素点。而在YUV4:X:X的表示法中,的4表达的也是这个意思。
从图可以看出,YUV4:4:4的采样方式,是对每个像素点进行Y、U、V分量的全采样。
关于内存占用,因为YUV模式的每个分量都是存储在一个字节(8bit)中的。
所以,对于四个像素,YUV4:4:4格式需要48 + 48 + 4*8 = 96位,因此,每个像素深度为24位。
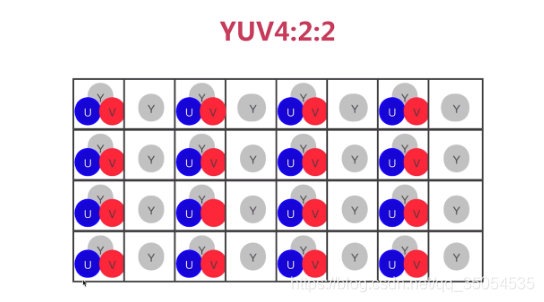
YUV4:2:2
YUV4:2:2的采样方式表示:水平方向Y分量与UV分量2:1采样,垂直方向不降低采样率。也就是这样:
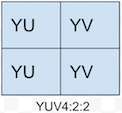
水平方向上的两个像素点组成了一个宏像素,两个像素点共享一对UV像素分量。
至于U和V分量是从水平方向第一个像素采集,还是分开到两个像素采集。如果是分开采集,是先采U分量还是先采集V分量,这个可能需要更专业的解释了。根据我搜索到的资料,最准确的说法只是,在扫描线上,水平方向上的UV分量是Y分量的一半。
对于四个像素,YUV4:2:2格式需要48 + 28 + 2*8 = 64位,每个像素深度为16位。
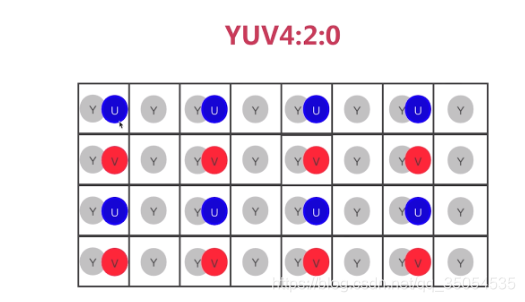
YUV4:2:0
YUV4:2:2的采样方式表示:水平和垂直方向上Y分量和UV分量对的采样比都是2:1。
目前YUV4:2:0有两种变体,一种用于MPEG-1标准如下图:
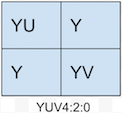
另一个常用语MPEG-2标准,我们经常见到的4:2:0通常都是这种。如下图:
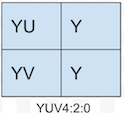
对于四个像素,YUV4:2:0格式需要4*8 + 8 + 8 = 48位,每个像素深度为12位。
YUV存储格式
YUV的存储格式分为打包格式(packet formats)和平面格式(planar formats)。
在打包格式中,Y,U和V组件存储在单个数组中,YUV三个分量是顺序交错存储。 像素被组织成宏像素组,其布局取决于采样格式。
在平面格式中,Y,U和V分量存储在三个不同的平面(数组)中。YUV三个分量被分开存储在三个不同的数组中。
4:4:4,24位像素深度
YUV4:4:4实际上表达的是:采样模式位4:4:4的打包存储的数据。它的存储方式如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xyHUmEoM-1610356447505)(https://uploader.shimo.im/f/u0A71T3JmhGAfulv.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]
一个小方格代表一个字节,一组连续的小方格代表一个像素。
4:2:2,16位像素深度
4:2:2的采样格式共有两种存储方式
- YUY2
- UYVY
它们的存储方式都是打包格式,其中每个宏像素是两个像素,编码为四个连续字节。
YUY2
在YUY2格式中,中第一个字节包含第一个Y样本,第二个字节包含第一个U(Cb)样本,第三个字节包含第二个Y样本,以及 第四个字节包含第一个V(Cr)样本,如图所示:

UYVY
这种格式与YUY2相同,只是字节顺序颠倒了 - 也就是说,色度和亮度字节被翻转,如图:

4:2:0,12位像素深度
下面要介绍的4:2:0格式都采用了平面存储模式,共有四种:
- IMC2
- IMC4
- YV12
- NV12
所有的4:2:0模式,色度分量无论是在水平还是垂直方向上,采样数都是亮度分量的1/4。
IMC2
IMC2格式的存储方式如图:
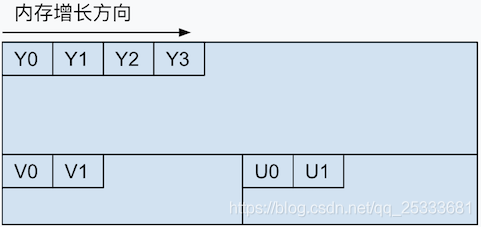
每个分量以一个字节存储,平面存储格式的意思就是,先存储视频帧中所有的Y分量。Y分量存储完之后,才开始存储色度分量。在IMC2格式中,YUV三分量的存储关系是:先存所有的Y分量、再存所有的V分量,最后存储U分量。
为了便于处理和表达,通常在代码中会以三个数组来分别装着三个分量。
另外需要提一嘴,在IMC2格式中,存储UV分量的内存空间步长分别是存储Y分量的一半。另外因为色度分量的采样书是Y分量的1/4,所以,及时色度分量占用空间是亮度分量的一半,也会有一些空闲的内存。
IMC4
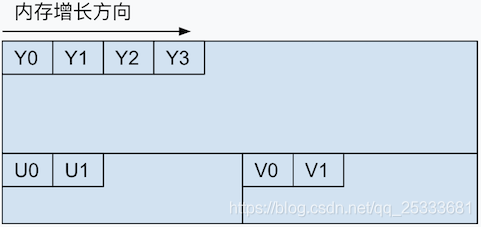
和IMC2格式类似,只是U、V两个色度分量的存储顺序对调了一下。
YV12&I420
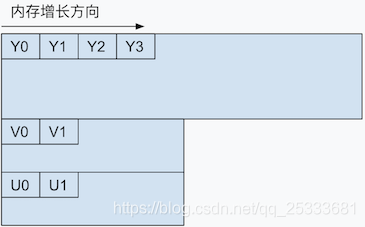
YV12格式的存储方式又有变化,存储色度分量的内存步幅是亮度分量的一半,首先Y分量数据以unsigned char数组的形式存储,紧跟着后面存V分量,最后存U分量。
I420和YV12的存储方式差不多,区别的地方在于,I420的Y分量后,存储的是U分量,最后存V分量,色度分量的存储顺序替换了一下。另外I420也被称为YUV420P。
YV12、I420、YUV420p这三个名词在多媒体开发中,是出现频率比较高的是那个了。大家不妨记忆一下
NV12
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gof2elbc-1610356447514)(https://uploader.shimo.im/f/PuSEXCkloHipEtiF.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]
NV12格式首先存储Y分量平面,作为具有偶数行的无符号字符值数组。 Y平面后面紧跟着一个无符号字符值数组,其中包含打包的U(Cb)和V(Cr)样本。
剧终
本文以理解为主,部分讲述并不代表事实,在生产场景这已经够用了。
5-5-2YUV



*




5-6 YUV的常见格式
YUV420:
第一行:只有Y和Cb分量
第二行:只有Y和Cr分量
第三行:只有Y和Cb分量
第四行:只有Y和Cr分量
第五行:只有Y和Cb分量
第六行:只有Y和Cr分量
…
…



我们这里关于上图的计算方式,只讲YUV420。
5-7 YUV的存储格式
我们来介绍一下yuv的存储。主要指的是 yuv420的存储格式,那对于yuv444,yuv422都是类似的。
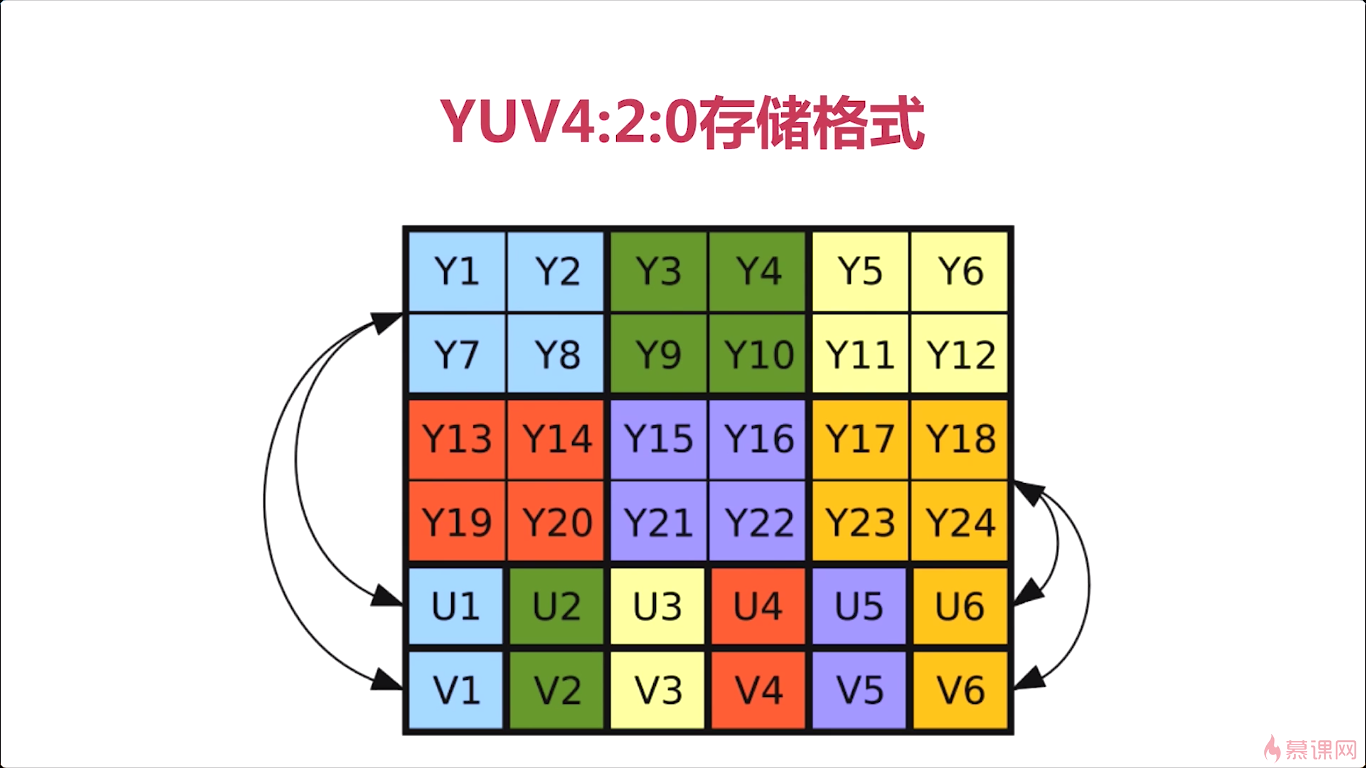
那对于这个YUV420的存储格式。有几个点我们需要掌握,第一个点呢就是,它是按照分层来存储的,那我们可以看到啊,在这个示意图中呢,前面的这半部分,都是Y相关的信息。之后才是U和V的信息,他是一层一层这样存储的,那这样的一个存储格式就特别适合于这个黑白电视机相兼容对吧 ,彩色电视与黑白电视相兼容,因为如果你是一个黑白电视的话,我们只要读取前面的Y相关的数据,就可以了,对于U和V,它可以舍弃掉。如果你想展示一个彩色,就要涉及到U和V。那么对于我们YUV420这种格式呢,他是怎么去使得Y和UV对应的呢。实际就是与他这个名字是相关的,四。就每一个y的前四个,对应一个U和V,你看图中箭头浅蓝色的色块。
我们知道如上存储的时候,你在解析的时候,比如说我们进行这个视频的渲染,那你读取的每一个Y对应的UV,它是一个固定的关系了。通过这个,我们就可以知道他们的关系, 第一层的第一行取出两个与第二行取出两个对应的呢就是。U中的第一个和V中的第一个。一行一行的这个扫描那么我们就可以。将整个的视频进行一个彩色的展示。这个就是YUV420的存储格式。

那其实这张图呢就是我们这节课所要讲的一个核心内容。那么接下来呢,我们看看这个常见的存储格式,那刚才我们讲了这个呢,是最普通的,最广泛使用的这种。那对于我们常见的呢,实际还分为平面存储和打包存储。对于平面存储来说,又分为I420和YV12这两种模式,I420就是我们刚才所介绍的,前面是y,后边是跟着U,再跟着V,而YV12呢,它存储的前面是y,后边变成了先存V后存U。这是他们一些细微的差别,那么我们只要知道。这两种模式最主要的区别是在于先存V还是先存U。
对于打包模式来说,就是先存Y,再存UV、UV

那对于我们这种平面存储和打包存储啊,实际在我们日常工作中经常用到,比如说像ios她应该都是YV12了,而对于安卓系统来说一般都是NV21。所以这两种模式我们必须都要掌握,因为你在工作中呢,随时都有可能遇到,对于我们这门课来说呢。在底层的这个YUV呢,可能我们就不是特别的详细的去做了。但是在我们的日常工作中,你是做移动端开发的,很有可能你会使用这个硬件的加速,对吧,还有这个通过硬件的摄像头采集。采集出的数据都是跟这个YUV密切相关的。那么我们在编码的时候,你也要告诉这个编码器那你使用的YUV是什么格式。这样才能正常的编码,否则的话编码之后,然后你再播放出来的数据就完全错乱了,对吧,它显示不出来。

那接下来呢我们再来看,这个yuv的未编码的YUV的码流是多少,在之前呢,我已经向你介绍过RGB的码流,他是怎么计算的。
我们在网络传输的时候是以位为单位的,比如说你是一兆的带宽,实际是一兆的比特位,而不是一兆的字节数,对吧这个我们要清楚。

5-8 YUV操作




让我们首先来看一下如何生成yuv,那生成yuv有很多的方式,那一种呢是我们通过这个硬件设备,摄像头采集到YUV的数据。那么另外一种方式呢,是我们可以通过多媒体文件,然后从多媒体文件中呢抽取出YUV。但由于我们还没有学到如何从设备上采集视频数据,对吧,那今天呢我们就使用多媒体文件来生成yuv。那这个命令呢,就是通过FFMPEG从多媒体文件中获取到YUV数据,那我们来一一看一下它的参数,那第一个参数呢就是他的输入文件,对吧,那这里呢你可以写任何一个多媒体文件,只要这个多媒体文件中含有视频就ok。第二个参数呢,an,a代表是audion呢代表是none,那就是没有音频。所以如果你的这个多媒体文件中呢是带音频的,那通过这个-an就可以把音频给过滤掉。第三个参数呢是cv代表的是视频的解码器编码器。那后边儿带着这个rawvideo表示的是说,我们对于这个多媒体文件中的视频做rawvideo处理,经过他处理之后,我们就可以获取到YUV数据了。ok那最后一个参数是指定输出的YUV数据的格式,那您既可以指定YUV420p,也可以指定其他的类型。
我们来解释一下这两个参数第一个参数呢是指明你要播放的这个YUV的它的格式是什么。如果是YUV420P话实际这个参数呢,是可以省略掉的,因为ffplay默认的就是YUV420p。第二个呢是最关键的一个参数,就是你要告诉他你的播放的分辨率是多少.
大家一个新的这个参数-vf。简单滤波。


6 H264技术介绍
6-1 H264压缩码率与GOP
我举了一个例子,假设我们有一个一秒钟的视频。分辨率呢是640乘以480,帧率是15帧,格式是YUV420P。码流多大?
结果应该是55M


对于h264他建议的码流大小是多少呢?是500kbps,通过这两个值我们就可以得出。它的压缩比是1:100,那对于我们一个完整的视频像一个电影。那这个数据量其实对于我们普通的磁盘空间而言,就是存不了几部电影。ok所以呢这个也是我们面试的时候经常被问到的一个问题。很多人都说 ,我学过音视频知道h264编码原理等等等等。那人家问你说这个h264的这个压缩比是多少。那你要知道他是1%,对吧,这才能知道你真的学过。帧率对于码流来说起到一个作用,帧率越高,占用空间越大,那如果我们用h264进行压缩的话,帧率呢相对来说,起到的作用就会小很多。随着我们后边课程的介绍那你会了解到。分辨率和帧率到底哪个对码流的影响更大。
实际我们在拍电影的时候。看到那个电影院播放的视频都是120帧每秒。这样你才能看到这个,电影非常的平滑。那对于像我这个录课一般都是30帧以上的视频。15帧是用在实时通讯,大家一起开会的时候,对吧,像视频会议啊,还有在线教育一般都会用到15帧每秒的帧率。
那例子中他的建议码流是500kbps,那这个数值是从哪儿来的呢。实际上我们在网上去搜索的时候可以看到很多的这种数值,但这个数值呢一般不是说通过严谨的科学计算出来的,而是各个厂家经过大量的实践,它是一个经验值,经验总结出来的,实际我们可以通过一个网址找到。就是声网给的值,它在整个音视频领域其实还是蛮权威的对吧。我们去做的时候也是按这个直接作为参考的。打开网址,打开这个文档中心之后,我们点击视频通话,点进阶功能,点视频管理,点设置视频属性。
看你在做这个视频相关的开发的时候,你要设置这个码流其实就可以参考这里边儿的。如果是直播码流,就是娱乐直播这种通过ramp进行数据传输的。为什么设这么高的码流呢?就是为了它的流畅度,因为对于娱乐直播来说主播在讲的时候,观众有一些延迟比如说有几秒甚至是十几秒的延迟是关系不大。因为当你看的时候他只要是连续的一直在播。你就认为这个节目其实是非常好的对吧,清晰度也够,流畅度也够。因为你与主播没有交互所以你感受不到这种延迟性。但是对于实时通讯来说,这种交互就不能产生太大的延迟,所以对于实时通讯来说,码流设置小一点,保证网络的通畅性。
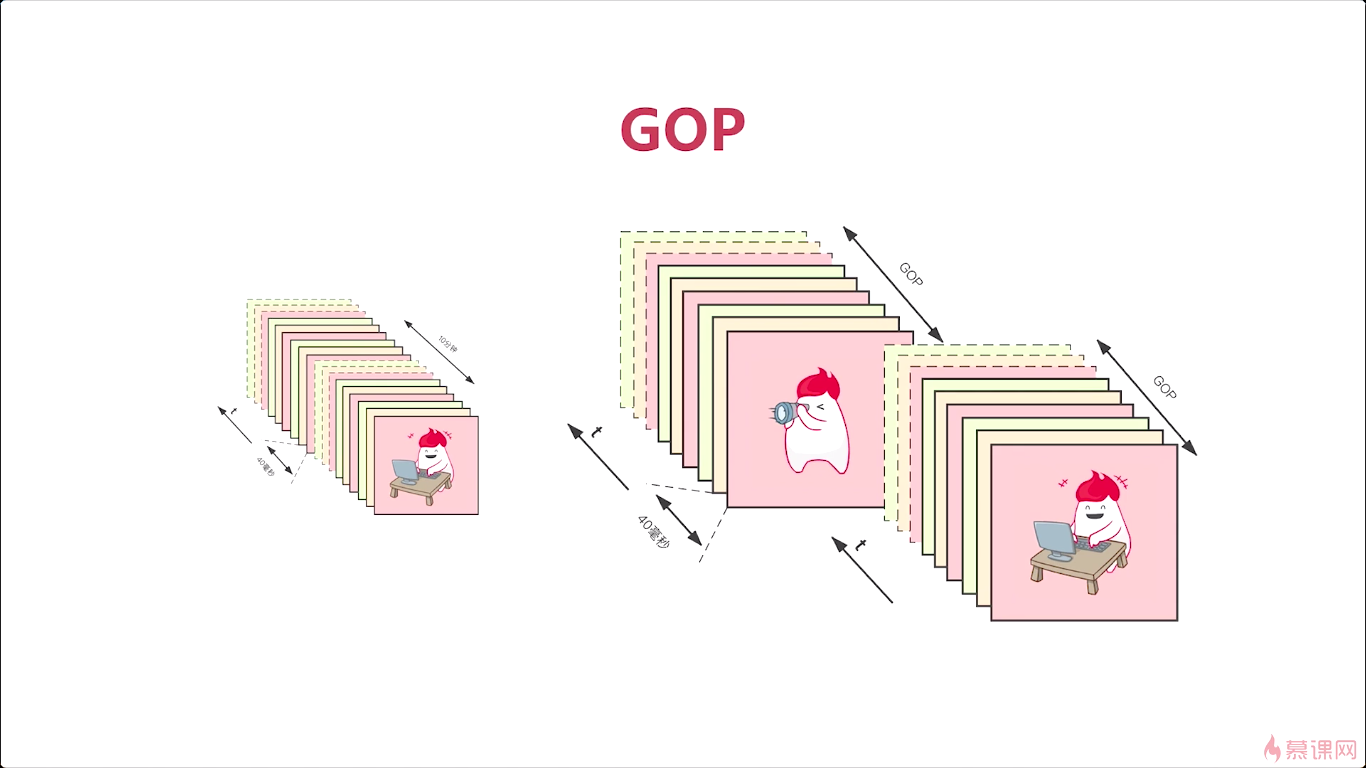
我们再来介绍一个非常关键的知识点,就是GOP也是我们在面试。面试开发岗的时候呢,面试官经常问道的一个问题。
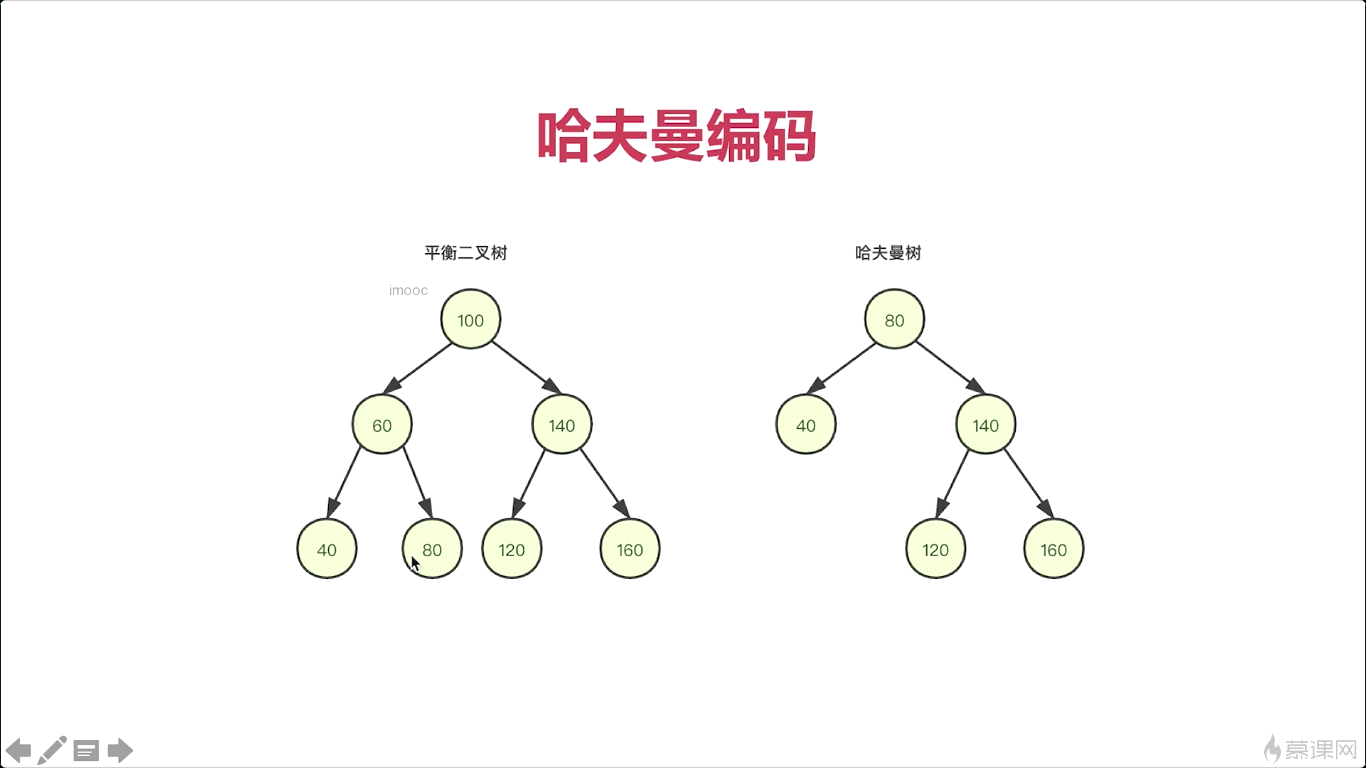
对于这么多的帧,实际我们在压缩的时候就比较困难。科学家们就想到一个非常好的办法,就是将这些帧进行一下分组,怎么进行分组呢。就是按照他们的相关性进行分组,比如我这里举个例子,对于这样一个视频呢,我分成两组,那怎么分的呢。小人一样,只是他们角度的不一样,我们把它分成一组。所以呢每一个group其实都是描述的一个图像目标的细微的差别。在同一个组中的这个视频帧这样他是强相关的,不同组之间的相关性特别小。这样我们就可以把这个视频划分成许多的组,每一组呢都是强相关的视频帧,组成了这一组GOP,英文全称就是group of picture。
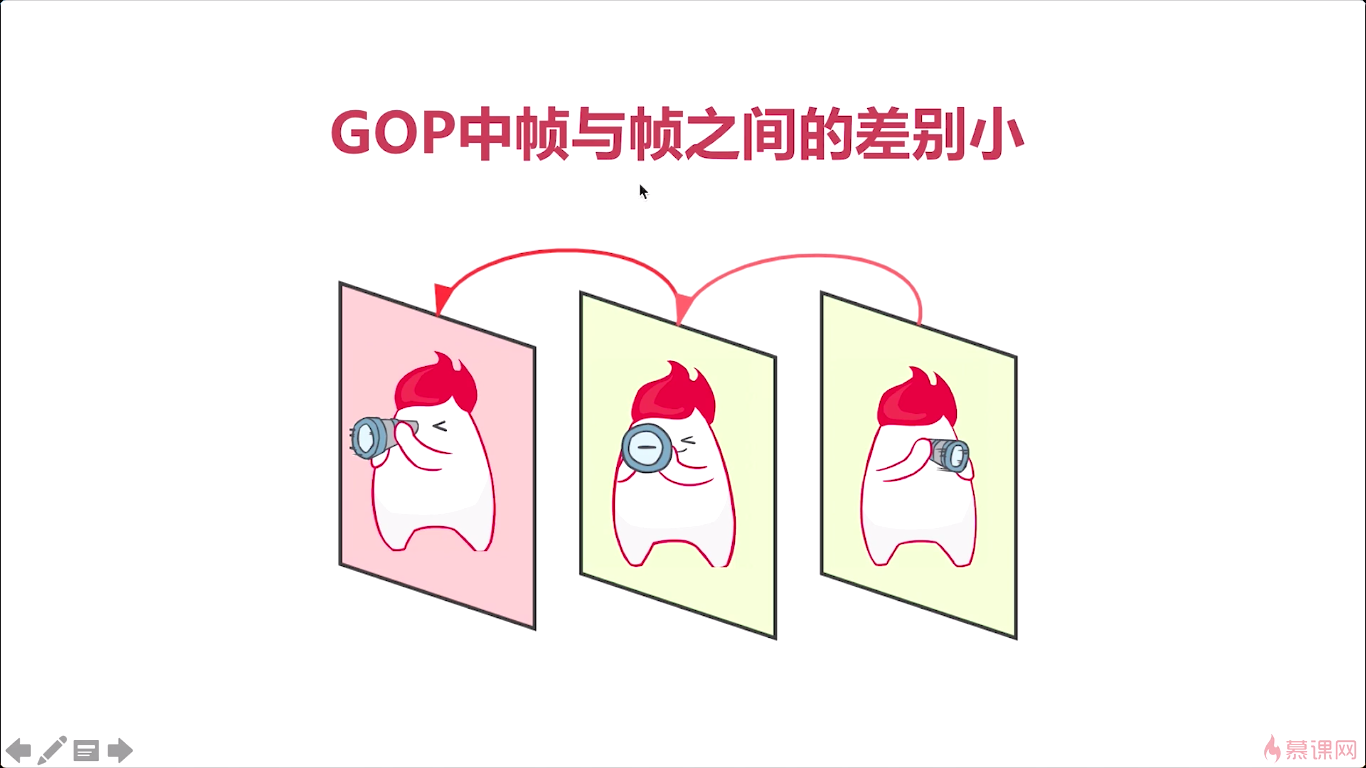
GOP的帧与帧之间的差别特别小。所以对于这样一组真来说他们进行编码的时候。非常容易压缩了,这个数据量会很容易地下降下去,为什么呢,我们来看一下啊。那么因为我们所有的图片都是这个小人儿的吧。差别就是转换的角度不一样或者这个小人儿的姿势不一样对吧,对于整个背景来说。背景图完全是一样的。所以当我们进行计算的时候,完全可以把所有的这个背景用一张图表示,对于差值我们进行一下存储。这个GOP的这一组帧进行压缩的时候,它会压缩的非常小。只需要存很少的数据就可以将原来的一组帧,还原回来,对吧,那这个呢,就是GOP的意义,那实际上呢,这GOP也是我们后续学习H264编解码技术的一个核心的知识点。它是一把钥匙,只有我们掌握了什么是GOP,那你才能学习后面所有的知识,否则就跟看天书一样。
6-2 H264中的I帧P帧和B帧

IPB帧,这些帧呢,其实都是H264中非常关键基本的一些概念。那对于这些知识的了解呢,对于你后面的学习有着非常大的好处。而且呢这些知识也是我们面试官经常问的一些问题.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Epg10ve8-1610356447562)(https://uploader.shimo.im/f/LFW8Cec6IQpeudau.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]
P帧约占I的一半,这样就大大减少了这个数据量。
虽然B帧的压缩率是最高的,但是他同时带来一个非常大的坏处,就是它占用cpu以及耗时是非常多的。那如果你B帧的帧数越多,你的延迟性就会越大。对于实时通讯来说呢,一定是快速的让对方看到,那你这个数据传输过去之后呢应该立即就解码,然后让展示了出来,这样才是一个最好的方式,所以在大部分的这个实时通讯的场景中,只使用I和P帧,不使用B帧。
在音视频转码的服务中呢,他会大量的使用B帧,就为了减少存储空间,我们如果去这个云服务厂商去买一定的空间的话,你会发现你买的空间越大,那你的这个花费就成指数增长对吧。我刚开始的时候可能就是一个最基本的比如说500兆,可能就是一个相当于免费一样,但是你用500个g、500个t那就完全不一样了。
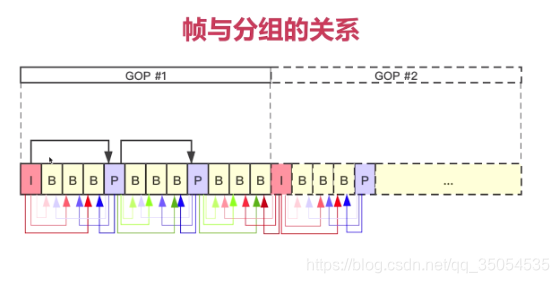
图上B帧和B帧之间是没有参考的。

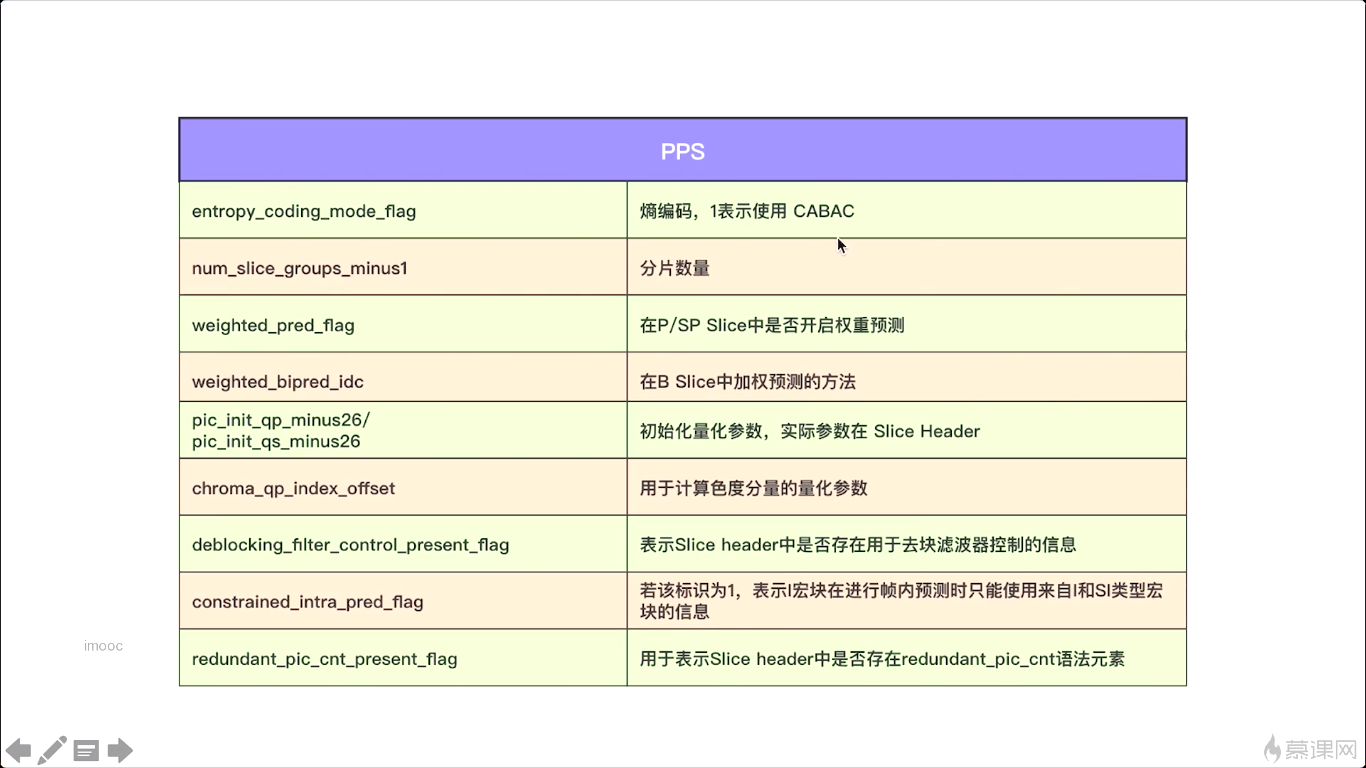
实际在h264中呢,还有两个特殊的帧,就是sps跟pps,那就不能称为帧了,这应该称为这个参数数据,那他其实也属于I帧的一部分,也就是说在每个IDR前面都会有一个sps跟pps这两个帧,这两个帧一般是同时出现的,不会单独出现那么。这两个帧的作用是什么呢?我们来看一下,sps就是序列参数集,对帧组的一个参数设置是吧,就是GOP的一个参数设置,我们看看它包括哪些内容,看图。sps相关的就是修饰或者是约束GOP的一些参数。
第二个呢是pps,对于GOP中,这一组中的每一幅图像的一个参数约束。
重点呢,就是你要知道这两个东西是成对出现的,是在IDR帧之前。
6-3 H264中的宏块
今天呢我们来介绍一下h264的压缩技术。实际上H264的压缩技术啊,它是由一系列的技术所组成的一个系列集合,不是简简单单的一个技术。

第一个技术就是帧内压缩技术解决的就是空域数据冗余问题。什么是空域呢?我们来想象一下一张图片对吧,它占用一定的空间。那么 所谓的帧内压缩技术就是解决这张图片内的这个数据压缩问题。比如你是一个天蓝色的背景,背景的前面有一个物体,那整个这个天蓝色的背景你实际上可以用非常小的一个数据量进行一个存储。后面在进行解压缩的时候,可以通过这很少的数据量就能完全还原回去。对于前面这个物体呢实际也有相应的这个算法对吧。对于帧内压缩技术来说呢解决的就是这些问题。
帧间压缩技术,就是帧与帧之间的进行一个压缩对吧。那他解决了呢是时域的数据问题。所谓时域,就是随着时间的推移,每一个时间段你都会有一帧数据对吧。那这一帧一帧的数据,他们之间可以做参考的,那我第一帧是一个I帧,它的压缩比会低一些。但是第二帧呢,我就可以根据第一帧的数据进行一个压缩,进行一个残差值。那我用第二帧的数据减去第一帧的数据它的变化量进行一个压缩,那就使得这个数据量非常小了。这里说的比较简单,实际的真正处理过程呢还是蛮复杂的。
第三,做DCT,那做完余弦变换之后这个数据会呈现一个什么模型呢。他就会将真正有数据的这个地方啊,进行一个滤波。滤波完成之后呢,就是把所有的数据集中到一块儿,另外一块就全部变成0了。这样就大大的减少了我们后边处理数据的这种复杂度。通过这样一个滤波处理之后呢,后边我们在对 都给它聚集了这一块数据 然后再进行一个压缩,这样呢,这个数据量就会变得更小。所谓的DCT,就是把数据进行一个调整,更有利于我们后边做无损压缩。
最后一个就是CABAC压缩,就是根据上下文进行一个数据的压缩。那对于这两块呢,数据余弦变换和CADAC,它都属于无损压缩技术。而对于这个帧间压缩跟这个帧内压缩呢,都属于有损压缩技术。尤其是帧内压缩,其实就是将这个不必要的数据全部去掉。比如说我们人眼啊,对于图片来说它对亮度更关注是吧,对色度就弱一些,那这个时候呢我们就可以把很多与色度相关的这些数据呢给他减少掉,从而减少整个数据量。而帧间呢,是我们根据前一帧的这个数据,因为前一帧已经是有损的了。所以呢我们后一帧是根据前一帧做参考的,那也是有损的。
所以我们可以大体上分为 就是前两项是有损压缩后两项是无损压缩。
CABAC目前来说也是一个比较老的无损压缩技术。那么现在最新的就有更高效的这个无损压缩技术。其实对于我们现在来说,我们不是搞这个数学的也不是搞算法的,我们只要知道他有这些技术就ok了。具体怎么做,那我们就可以留给那些专门做数学的或者是做算法的一些工程师去处理就ok了。那这是整个H264压缩技术的一个概况。

宏块呢,是我们上面所讲的这些知识中啊最为关键的一个基础点。我们之前说,GOP,他是打开我们学习H264编解码的一把钥匙。而宏块呢,则是我们就进行H264编解码最基础的一个知识点。所以我们这节课的重点是要把这个宏块给弄清楚。
宏块就是视频压缩操作的一个基本单元是吧。那无论是帧间压缩还是帧内压缩都是以宏块为计数单位了。


那我们要把它切换成一个个宏块那他是什么样子呢,这个宏块是按像素来的,8*8的一个像素,它就称为一个宏块。看右边这张图呢就是宏块的一个具体的表现。最开始的时候每个宏块的每个像素。都有一定的值,有一定的颜色对吧。那后边呢我们就会按照这个宏块去给他进行压缩。

那我们将底下这张图啊,全部用宏块划分完成之后他变成什么样子呢。就变成上面这张图的样子,看起来整体的这个图形呢跟下边儿是一样的。但是它的色彩啊,它的这种平滑度啊,都不如下面这张好看。通过这样一个划分呢,就更有利于我们后边进行这个视频的编码和解码。
那对于宏块来说,我们还可以划成很多的子块。比如在这里,这是h264的一个子块儿的划分,对吧。那整个这个大的块儿是16乘16的。等一会儿我们会介绍到这个h264它宏块划分的这个尺寸大小,那有很多尺寸。那么整个这个大块儿呢是16乘16,那么我们中间给他进行一个平均分配。每一块是88,在88里又可以划分,…经过这样一个划分之后,每一个宏块就非常小了。宏块的大与小,其实对于我们编码有着非常重要的这个关系。如果你宏块非常小,那我们进行压缩的时候控制力就更强对吧。如果你宏块特别大那控制力就弱一些。但是有一点,一个非常平滑的一个背景,就一个天蓝色的背景对吧。宏块划得大,它的处理速度就快,整个背景来说,没有太多的细节的,我们只要划分一个非常大的一个16乘16的,我们很快就能将整个背景进行处理掉。而对于很多细节纹理特别强的这些图。有很多小细节比如一个眉毛都很清楚的这些细节那你就画成很小的这种宏块。处理起来呢,它的压缩比就更高。

对于右边这张图就是典型的例子,对于MPEG2,就是将一个这个16乘16的划分成四等份每个是8乘8,处理时候呢,每一块的数据量就非常多,而H264呢,他就对这个宏块划分做了非常大的这个灵活性。那么将宏块划分成小的之后呢我们能看到。解压缩的时候你可以看到每一块都非常小对吧,整个的这个背景呢几乎你都不用存什么数据。只要存一些特定的这个纹理的数据就ok了。
所以宏块划分的越仔细,对于我们后面的编解码就很重要。
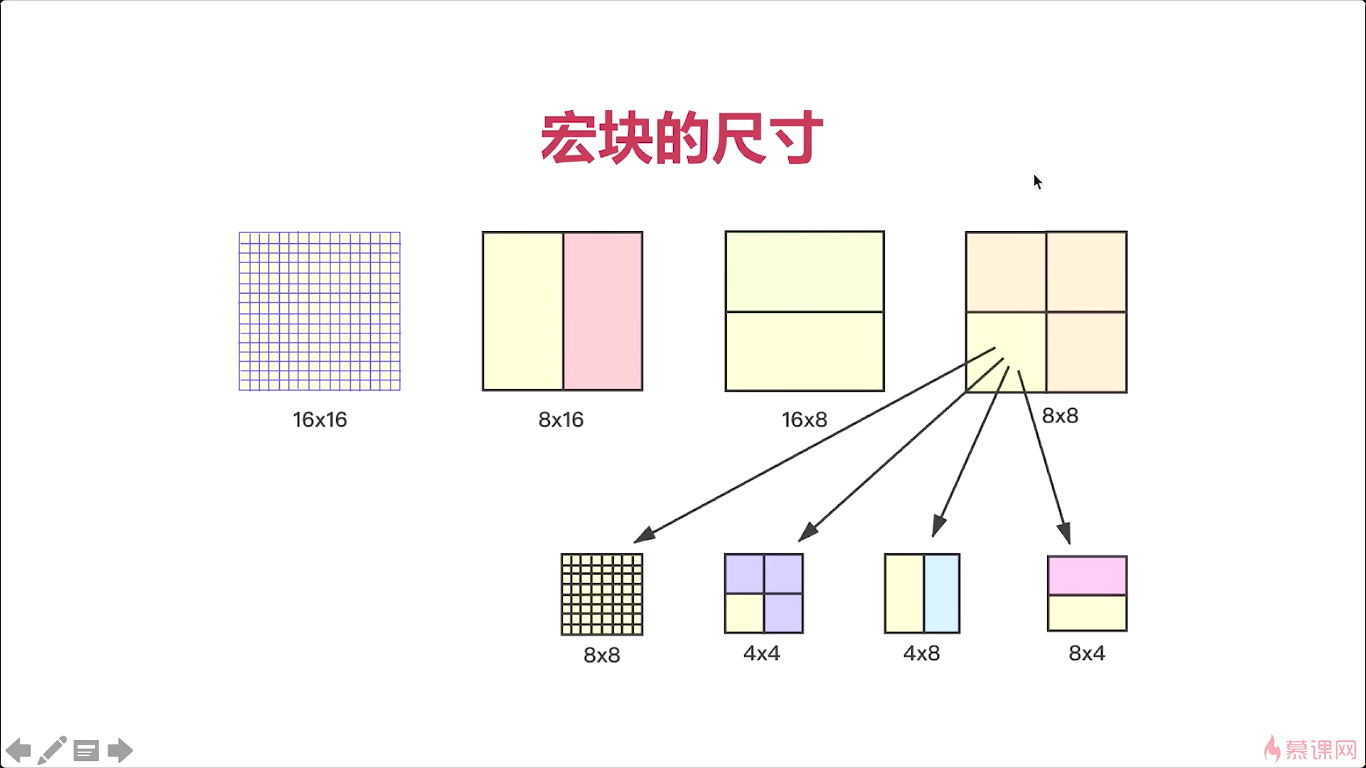
那对于宏块都有哪些尺寸呢,对于h264有很多尺寸。那么最常见的我们以前默认的就是16乘16。经过图上个划分之后呢我们这个压缩率啊就大大提高了。我们H264相对于MPEG啊其实是有一个质的飞跃的对吧。
6-4 帧内压缩技术
今天呢我们来介绍一下帧内压缩技术,那我们要进行帧内压缩就要有一个帧内压缩的一个理论,对吧。那对于帧内压缩他的理论包括哪些呢,我们来看一下。

那第一个呢,非常关键的就是相邻像素之间的差别不是很大,所以可以通过宏块进行预测,那什么意思呢就是我们的所有像素,像素量你单独拿出来之后,您可以看到每个像素点之间的差别其实非常小的。而我们上节课就向你介绍了整个h264他进行这个编解码的时候,都是以什么为单位呢,都是宏块为单位的对吧。一个一个的像素进行处理这个效率太低了,那最少你也得是一个4乘4的一个小块,所以在H264,在帧内进行压缩的时候呢,它是以这个宏块为基础的,对他并不是只是我这两个像素相邻,我就对这个像素进行一个处理,而是说把这个4乘4的一个像素按着一块一块码好之后呢,让两个宏块之间进行比较那么这两个宏块之间由于是邻近在一起,所以他们之间的这个差别也不是很大。那有的人可能会觉得那个颜色不一样,对吧,有的很明显。那下面呢,我们就来解决这个问题,人对亮度的敏感度超过了色度。像我们黑白电视只要你能看到影像对吧我们就知道他讲的是什么故事,它是一个怎么样一个过程不影响我们正常的视觉。那你加了颜色之后呢,他感觉更好,但是呢,你把这个颜色稍微做一些偏差其实也是无所谓的,对吧,这是我们大家都能感觉到的。而对于我们要处理的这个数据啊,实际大家都已经知道了,我们要进行压缩的数据是什么数据呢,是YUV数据,YUV数据,它有一个天然的好处就是可以将亮度和色度进行这个区分, 那亮度就是Y数据,那色度呢就是UV数据,所以我们在处理的时候呢,可以直接对Y数据进行处理,然后UV数据呢做另外的处理,这样我们z再进行帧内压缩的时候就可以实现我们这个预测的方法进行压缩了,那所谓的预测就是说当我们不知道下一个宏块,也就是下一个4乘4,16个像素是多少的时候,我们可以根据他之前的或者已经已知的这个像素,来推断出下一个16个像素它具体是什么样子的,ok啊这就是我们整个帧内压缩的一个理论基础。
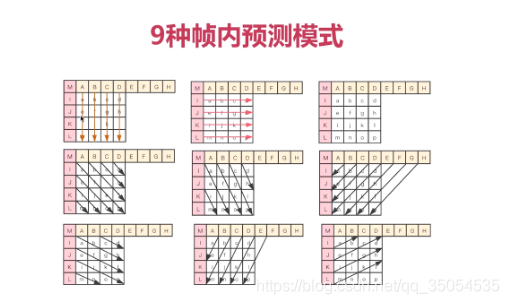
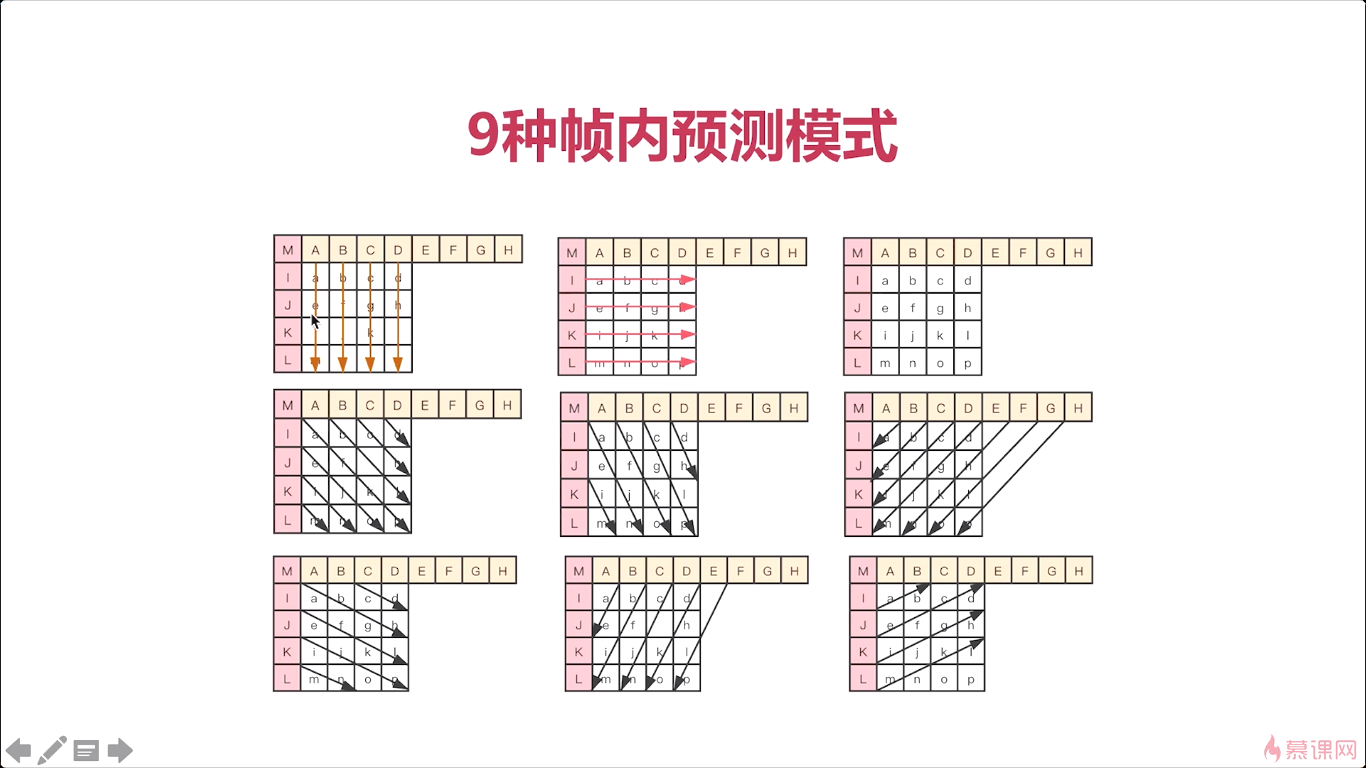
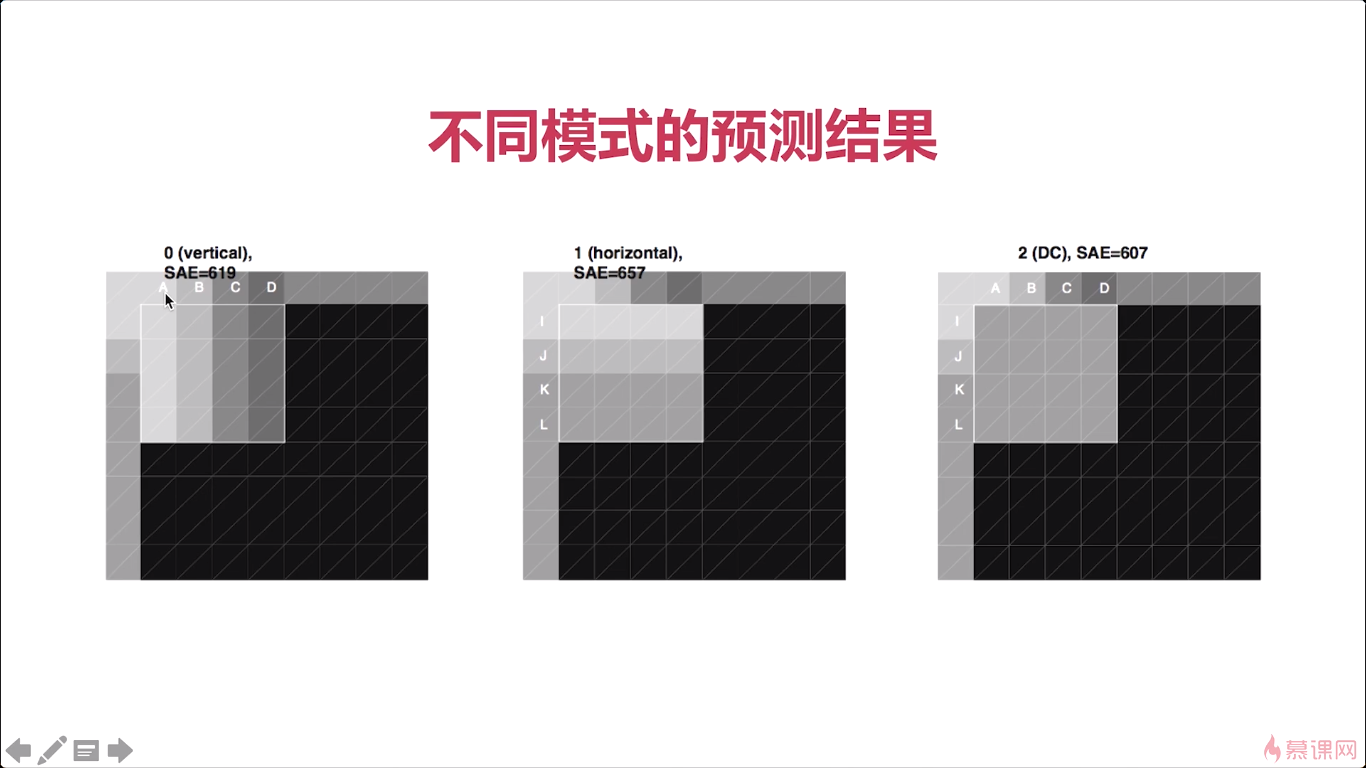
好,那我们了解了这个理论基础之后呢我们再往下看。那对于帧内预测来说呢,h264提供了九种这个模式,从零到九。那我们现在只要知道有这几种模式就ok了,那么在这九种模式在使用的时候呢,实际会做一个预判,也就是说,我从某一个点、某一个宏块为基础,那么在这个 宏块下边的一个宏块或者是它右边的一个宏块,那应该是什么,进行推算的时候呢实际有九种模式进行推算。那至于选择哪一种模式,在H264中呢,有一种算法就是可以快速的定位我应该使用哪一种模式,他的一个基本原则是什么呢,就是这九种模式中哪种模式最接近于原来的这个4乘4的这个宏块,那就选择那种模式,这个有很多的论文,大家有兴趣的话去可以看一下这个具体的论文怎么去选择具体使用哪种模式,对于每一个宏块的预测,都是不一样的,它都是可以根据一个快速的一个方法去定位下一个宏块去采用哪种模式。那么通过这样呢,我们就可以把所有的这个宏块啊,进行一个处理,处理之后呢,我们就可以看到那这个宏块呢,都变成了数字,364354,他这是什么意思呢,就是我这个宏块使用的预测模式是第几个模式。那这个三呢,就代表模式三,六呢代表模式六,他是这样一个这个处理,那我们后边儿再处理的时候那你只要知道它选用的模式是什么,我们就可以知道这个宏块,他应该是什么数据了,对吧,因为它可以通过模式预测出来啊。
那具体的九种模式是什么呢,就是我这里画的这九种模式。第一个图,代表每一列的值都相等,比如第一列就都是A,第二列都是B…第二个图同理,横向都相等,第三个图就是平均值,每个像素都是一样的值。
我们就简单列举了三个那对于其他不同模式有兴趣的同学呢可以继续去看一些论文。好那这就是不同模式的预测结果。


在这里我们再来举一个具体例子啊, 像我这张图片对吧就是一幅图,视频中的一幅图那么我们要对这一小块儿进行一个预测。我们现在通过这个大图可以看到啊它这是一个帽檐儿对吧,上边是一些砖的颜色,然后这边呢还是帽檐儿的这个白色帽子的白色。在这边呢就是帽子里边对一些颜色让我们来看一下。那这张图呢就是我们从那个小的方块中抽取出来了。左边是原始数据,右边呢是按照4乘4的这个亮度块进行预测,我们一定要记住啊,亮度块与色度块是单独进行预测的,要知道这一点。那预测出的结果呢,它实际是通过上边的这个数据和左边的这个数据那推测出来的。我们可以看到这两个数据几乎是一样的对吧。有一些细微的差别,但是差别呢不是太大,所以通过这种预测我们就可以将这个数据量大大地减少,那你通过这个整张图,我们可以看到那上边儿这是一个帽檐儿对吧。能看到一个大体的结果呢。那所以通过这样一个预测我们基本上可以获取到原始图几乎是一模一样的,但还是有一些细微差别。



那么对于这些细微差别呢其实还需要进行一个处理。但如果是一整张图我们就预测下来之后可以看到啊。你可以看到整体上都是差不多的但是呢。可以看到这个清晰度会差很多。对吧为什么差很多呢,就因为这些预测的时候呢,有一些块他分不清了。对那这个时候会怎么办呢实际还有一个残杀值的计算,当我们将所有的这个数据预测出来之后,那么还要通过原始图与这个预测的图进行一个差值计算。计算出的结果就是这张灰色的小图。
他们对端进行解码的时候就可以根据这个模式先把原来的这个图像预测出来。预测出来之后呢再加上我们的这个残杀值就能完全的还原成,这个数据与原始数据还是有一些差别的,比如说一些色度上的一个差别,那肯定是有一些损失的对吧,因为这是有损压缩。
当然你可以做到完全的这个无损压缩,那这样的话其实这个整个处理的这个过程也非常长,所以呢,在我们真实的这个使用过程中,很少有完全的一点都不存在损失的这样压缩。

6-5 帧间压缩技术


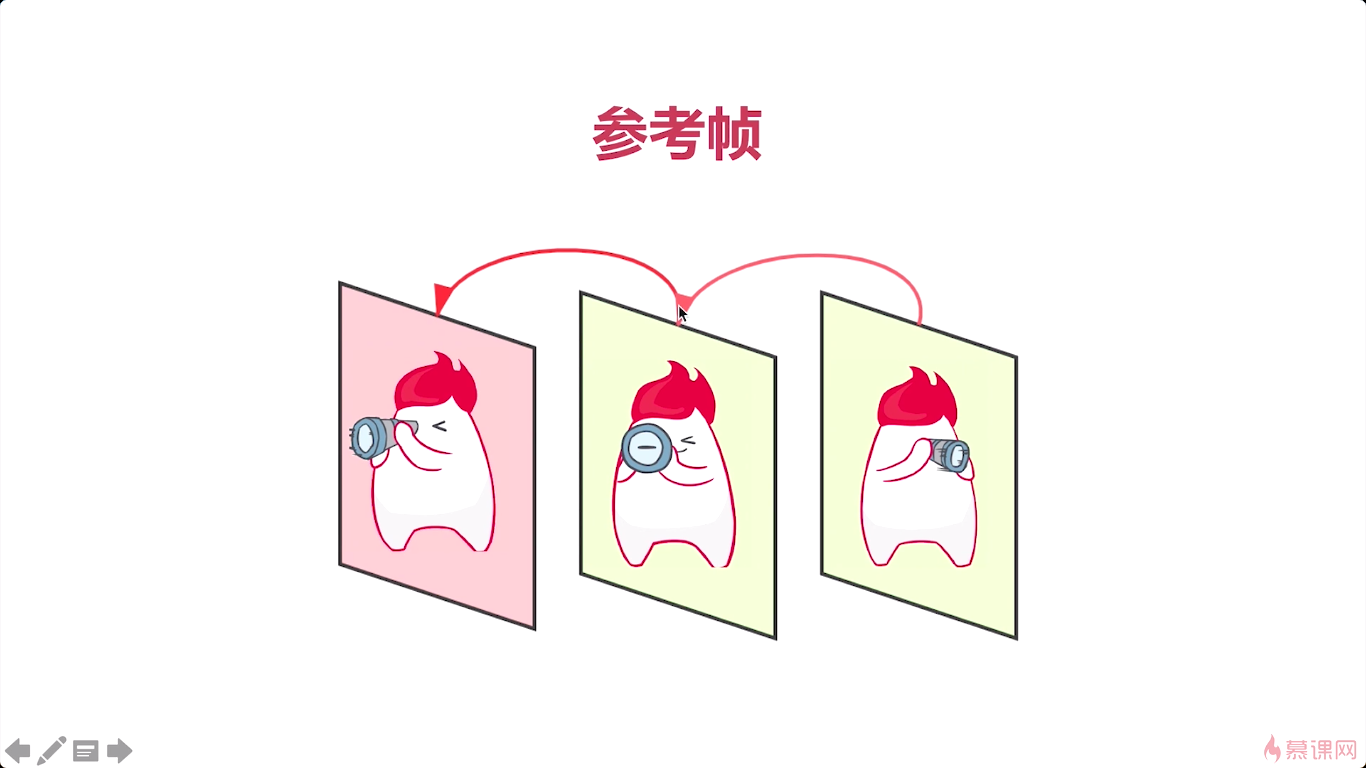
最主要的我们要知道所谓的帧间压缩一定是在同一个GOP之内的。不同的GOP之间两个帧进行帧间压缩这是不可能做到的。因为两个不同的GOP他们帧之间的这个差距太大了。也没有什么相关性,这样呢你就没法儿进行了一个压缩。而在同一个GOP之间呢,他们的帧是强相关的。
后边的帧要参考前面的帧进行压缩。

那第三个呢就是运动估计,运动估计的是我们帧间压缩的一个最为重要的一个压缩技术。那它是通过宏块匹配的方式。找到这个运动矢量,那所谓的运动矢量就是它是有方向的吧。一个宏块从一个坐标到另外一个坐标,而且是有方向的,这叫做矢量。运动矢量就是它有一个运动的轨迹,所以呢所谓的运动估计,就是通过宏块匹配的方法,最终找到运动的矢量。所以你在看相关的资料的时候,会看到运动估计,那你一定要知道,它指的是一个过程。

那最后一个呢是运动补偿,这也是我们经常看资料会看到的。找到残差值,最后呢我们在解码的时候,他把这个残差值给他补上去。

台球滚动,也就宏块的这个距离以及他的这个方向,我们就给他记录下来这就是运动食量。

对于宏块的查找的算法呢其实有很多了我这里列举了几个。那你感兴趣的同学呢可以去对这几个搜索去做一下这个深入的研究。但你可以直接在网上去搜索相应的名字,就可以找到具体的算法那具体他是怎么工作的你就可以一目了然了,ok那这里呢我就不再展开讲了。
好那我们实际上边儿通过这个宏块的查找这个整个的过程其实就是运动估计
了解了上面的中间压缩技术之后呢。我们看几个实际的这个例子啊。


6-6 H264无损压缩及编解码处理流程
那么经过无损压缩之后。它的数据量会进一步变小这样呢。将整个的一个码流降到更低的,对吧。ok
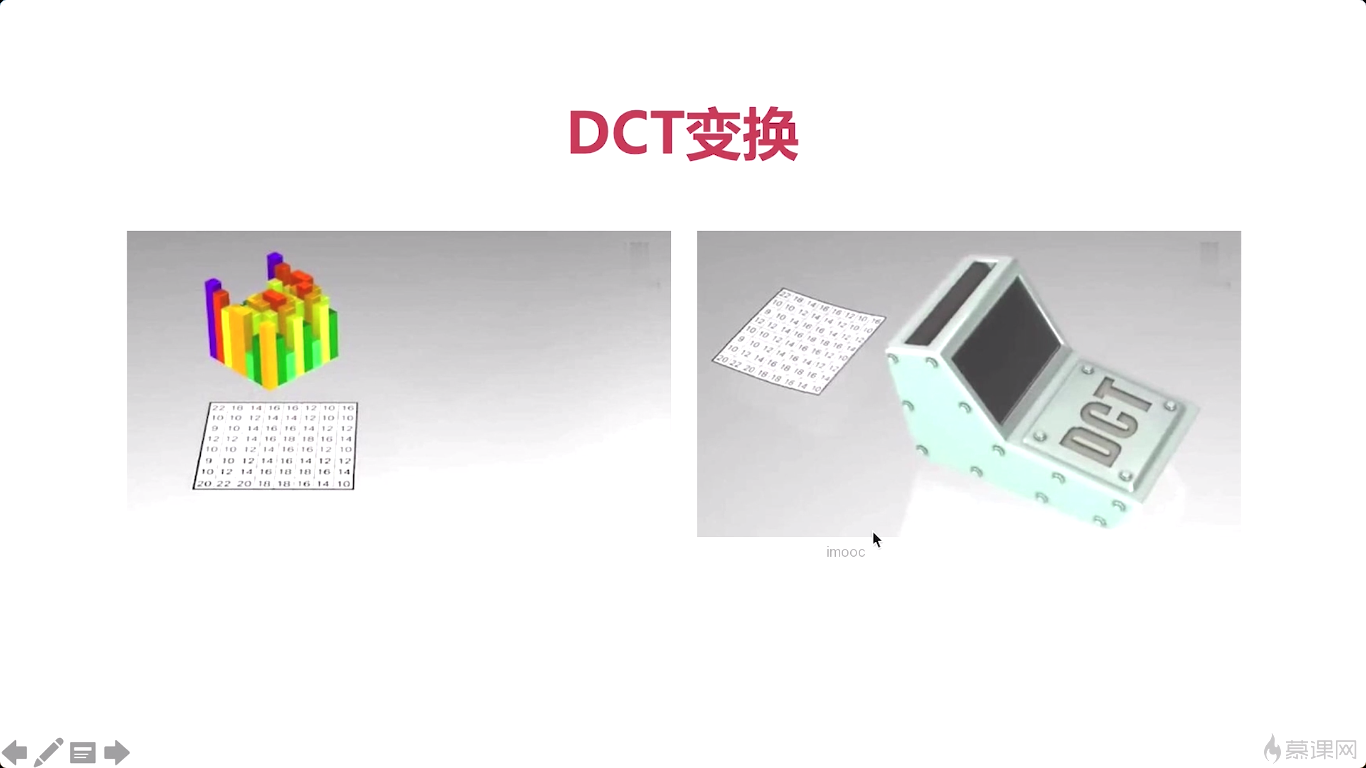

但对于无损压缩他有几个步骤,来一看一下,他第一步呢,就是我们要经过一个DCT变换。这个DCT变换它的作用是什么呢,就是我们经过有损压缩之后,这个数据呢是分散在我们的这个就是二维图表中的各个节点上的,对吧各个点上的,那么这个数据比较分散的时候呢,我们进行压缩就比较困难。通过DCT变换之后,形成了一个滤波,经过这个滤波处理之后,所有的就是分散的数据就被集中到了一块儿。集中到了某一个角,对吧要不是左上角要不是右下角。将所有数据集中到一块儿之后,我们再进行无损压缩的时候呢,就会非常的方便。那整个DCT变换其实就是起到了一个数据从分散的变成集中的这样一个过程,就是他的这个物理含义,DCT如何实现这一点的呢?这需要你有很好的一个数学背景当然。也不是很困难, 对吧,它无非就是一些二维数组的一个转换而已,通过程序,非常的方便。

常见的无损压缩方法一种是VLC,这属于MFPEG2使用到这个技术,另外一种呢是CBAC,它的压缩率会更高。
首先呢,VLC就是可变长的编码。举了一个例子,比如26个字母a到z,如果a的使用率是最高的,频率最高,所以呢给他一个短码。z的使用率非常低,就给他一个长码,高频字符越多,压缩率越好。那这里的a呢就是一个代替,这里是a的字符那你可以把它换成任何一个数据块啊,对吧。对一个不常用的数据块,我们用一个长码进行表示,那我们就可以进行这个无损压缩了。这就是VLC的一个基本的概念。

那第二种呢是CABAC。就是上下文适配的(binary)二进制的算术编码。这张图呢就是VLC与CABAC的一个对比图,VLC,这属于MFPEG2,CABAC属于H264,通过这张图我们可以看到啊。这左边呢是很多的图片对吧经过压缩之后。她变得非常小了,通过VLC,而通过CABAC呢,前边儿他都是类似的,都是很大的块,随着时间的推移,后面的数据,他因为有上下文,对吧,所以呢后边儿的块呢非常小,就是它的压缩率会非常高。
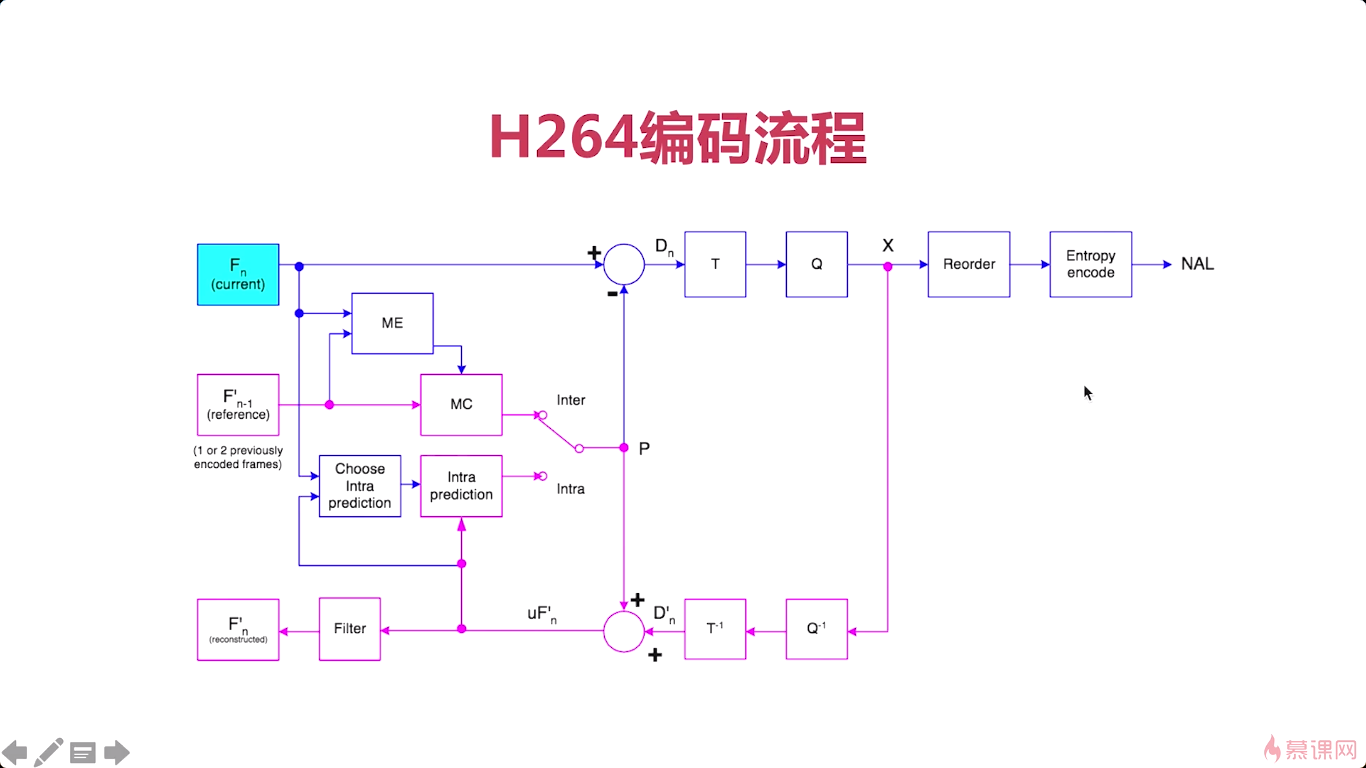
介绍完我们上边的这个无损压缩之后呢。这张图呢就是整个h264编码的一个流程图。
左上角是当前帧Fn,然后我们选择帧内预测模式,
帧间编码,就要看Fn-1
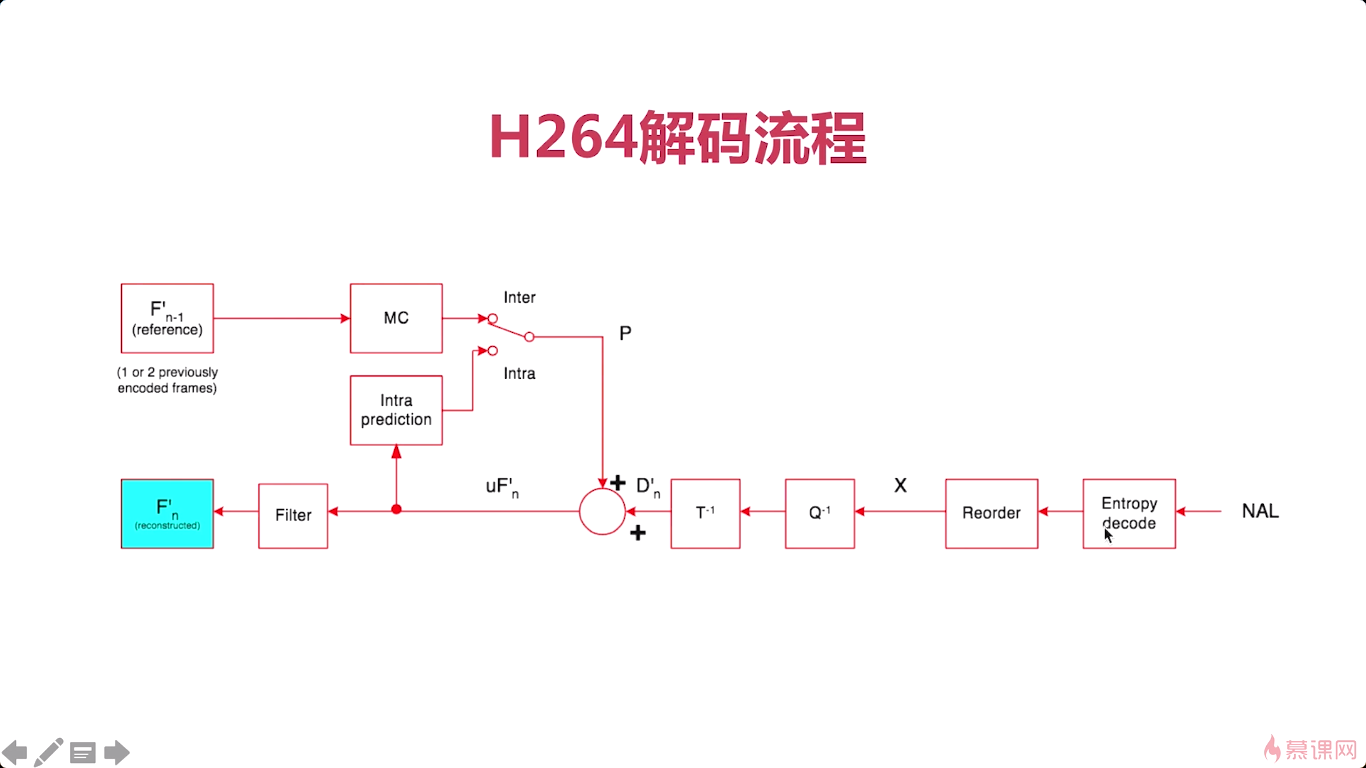
解码就是反向的过程。

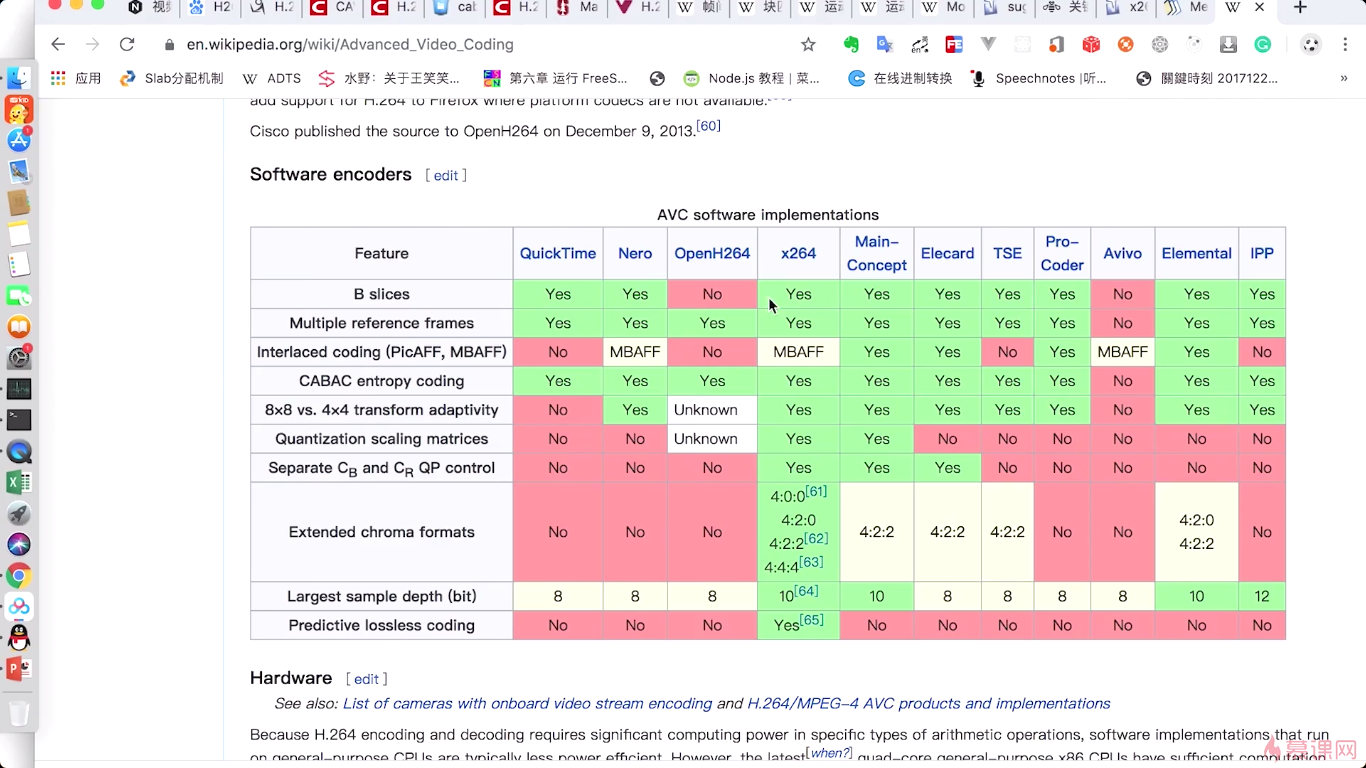
那这里呢我还有两个参考资料大家可以去网上查一下,那第一个呢就是H264整个编解码过程,是在白皮书里有详细的介绍,那么另外一个呢,这个网址呢实际是介绍了整个h264它不同的编码级别,它的区别是什么,以及我们现有的一些H264的具体实现,那哪个功能更强,都有一个特别好的介绍.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MjF0umnc-1610356447614)(https://uploader.shimo.im/f/mc09NTjNt86taRZg.png!thumbnail?fileGuid=Xk3wQdKCdtV3twqC)]](https://img-blog.csdnimg.cn/20210303215401766.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1MDU0NTM1,size_16,color_FFFFFF,t_70)
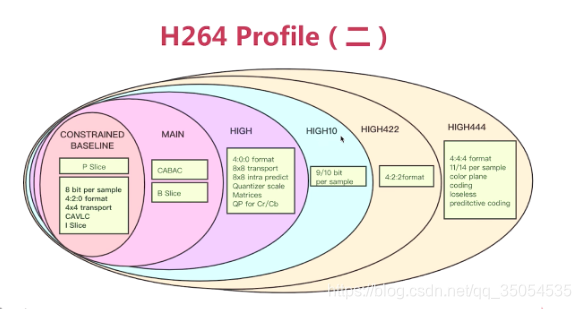
从第二个网站中,我们可以看到,H264的BP(baseline profile),是没有B帧的。而在我们实时通讯中呢,一般使用的都是BP,他之所以不使用B帧,就是为了减少这个延迟,对吧,那如果我们是一个非常这个要求压缩率非常高的时候呢。我们最好选择这个Hi444P profile,这个时候呢,他的这个B帧都是支持的,它还支持什么CABAC.这个可以作为我们的一个参考,另外一个呢就是我们实际意义比较大的就是我们不同的具体实现,比如这里有很多实现,那在这些具体实现里面,大家为什么选择x264作为h264的编码器呢,就是因为它这个功能实现的特别全,性能特别优越,在这里通过这张图表呢我们可以发现几乎所有的功能它都支持。
6-7 H264码流结构
之前讲述了整个H264它的编码的一个处理流程。结束之后他输出的结果是什么呢。实际上就是我们今天所要讲的是h264码流对吧,拿到这个码流之后呢,我们既可以把它保存成这个多媒体文件,也可以把这个码流呢,直接通过网络进行一个传输,在传输给对方之后呢。组包解码最终呢还原回原始的数据,进行一个播放,是吧这就是他整个的一个处理过程。

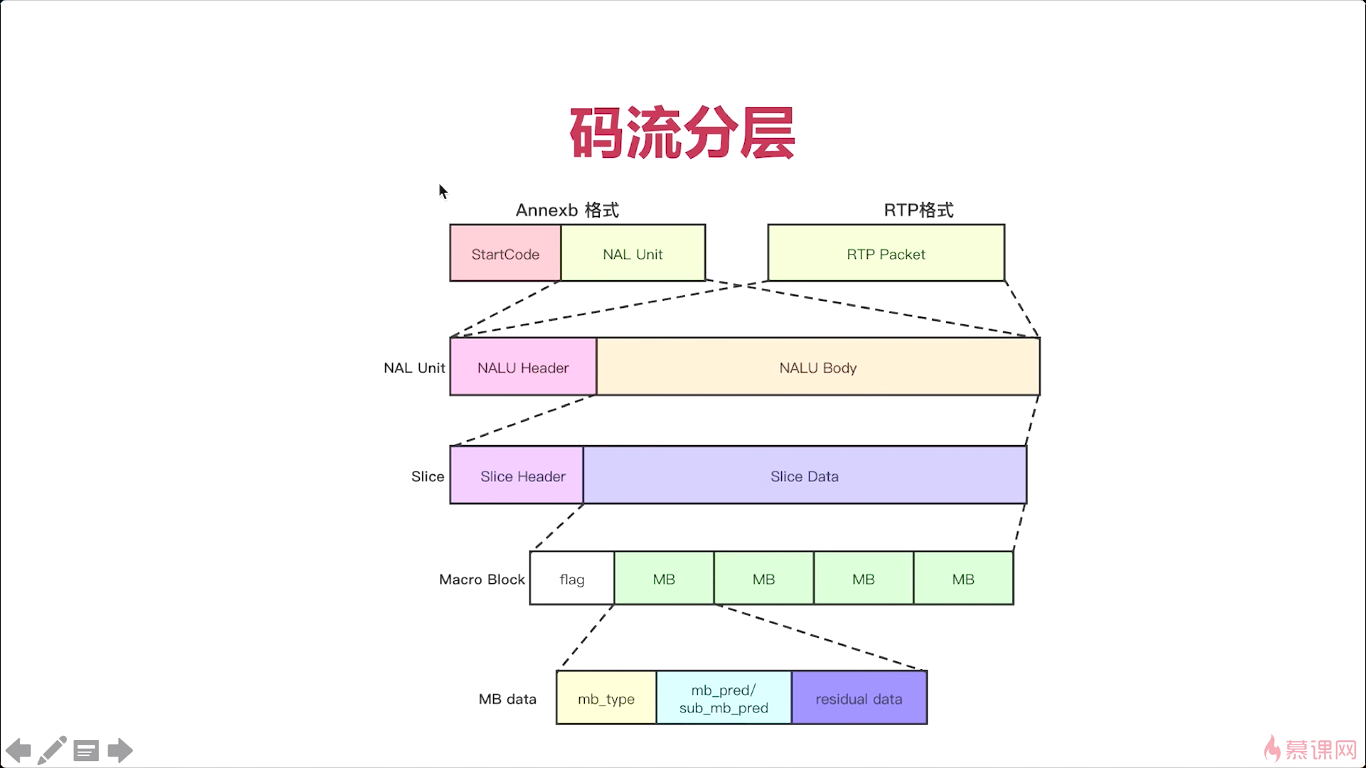
ok。这个输出的码流,它的格式是什么样的,那首先我们要知道。H264码流它是按分层存储的。那到底他是怎么分层呢,我们就来看一看。在整个分层的过程中啊,他的第一层称为NAL层,那什么是NAL层呢,实际就是网络抽象层对吧。这一层的作用是什么呢?方便我们在网络上传输视频流,因为我们在网上传输的时候,经常会发现有这个丢包啊延迟啊乱序啊。那如果我们没有NAL层的话,只是传输二进制的数据,无论你是音频也好,视频也好,那么在这里我们当然主要讲的就是视频了,如果你传这些二进制的视频数据。如果出现乱序重传丢包,我们怎么解决?实际上我们没法解决,没有一个纠错的能力,怎么才能有纠错能力呢?这个H264码流增加NAL层的最主要的一个原因。那么有了这个NAL层之后,你就可以在网上顺畅地进行传输了,当然他也会丢包也会乱序,也会有重复的包。但是由于你有了NAL层,那在接收端接收到这个数据的时候,他就能区分出这些数据到底有没有丢失,有没有乱序,有没有重传。当它检测完之后呢,他就可以根据各种的情况进行相应的处理,比如说你发生丢包了,我知道的是丢了哪个包,我就可以告诉对方说这个包儿丢了你再从新给我传一下。如果是乱序了那他可以根据NAL层的序号,然后重新进行一个重排,当然这个序号并不保存在NAL层,对吧,他是跟RTP层有一个紧密的关系。但是在NAL层,他是知道这个包的起始和结束的。再配合RTP数据包的,这个 sequence number,也就是顺序号,那就知道你这个数据是在前面还是后面。
NAL层,就是H264码流中用于网络传输的协议层,那如果没有这层的话,我们在网络上传输就会遇到很多问题,而且是无法解决的。
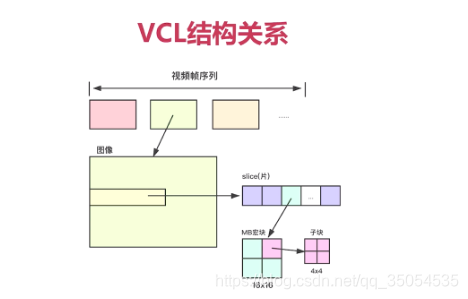
还有第二层就是VLC层,就是视频编码层,实际就是我们前面所讲的帧内、帧间、熵编码啊,所有的这些东西都打包成一块。输出的数据呢,就是VCL层,所以呢对于H264码流来说。它分成了两层码流,那第一层呢是主要用于网络传输的,那么第二层呢是vcl层是视频编码层。
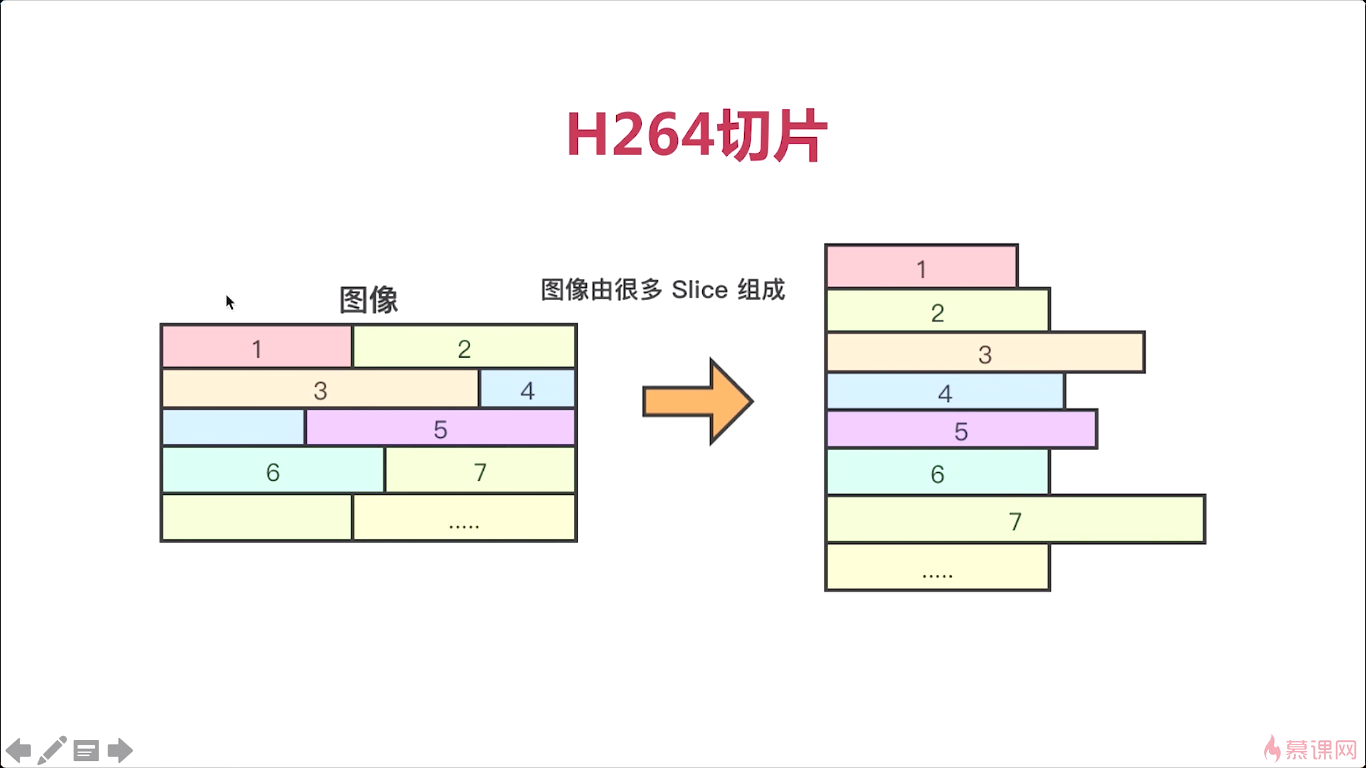
那么我们知道了这个H264,这个码流分层之后呢,我们再看看VCL逻辑关系,各个结构之间的逻辑关系是什么样子的。上半部分呢,它表述的是编码后的一帧一帧的视频帧,对吧,他们是一个从左到右的一个顺序关系,一个视频有很多的视频帧,其中的每一个被压缩后的视频帧是由什么组成的呢。是由slice组成的,会有很多的slice组合成一个压缩的图像,对吧,那当然了如果你对这个H264码流熟悉,或者说你经常分析H264码流的话。你会发现实际一般情况下,一个slice就对应的整个图像,但是在H264的官方文档上。那么它的一个图像中呢,是可以分很多的slice的,那这个slice是起到一个什么作用呢。其实他是想通过这个编解码器将它分成很多的小块儿,更方便于我们网上传输。这样处理的时候呢,他的灵活度更高,但实际情况呢,一般呢都是一张图片对应一个slice,除非你强制说我把它拆成很多的slice。这就涉及到很多的编码原理上的一个东西了,对吧,如果你想对这块更深入的研究,去看看官方文档就行。实际无论怎样,我们现在只要知道一个图像无论你是由一个slice组成,两个slice组成的。他都是应该可以包含多个slice的,对吧。ok
好,再下来呢,就是每一个slice呢,它是由很多的小块组成的,这些小块是什么呢,实际就是宏块对吧。

再下来呢,我们要介绍几个码流的基本概念,那我们在网上去看h264相关的概念的时候呢。其实经常会遇到这个概念,如果你对这几个概念不清楚的话,对于你理解H264码流会有很多的困难。那首先我们要知道一个最基本的,SODB,二进制数据串,那什么是二进制数据串呢一会儿我们在来介绍,那么第二个,RBSP,原始字节的顺序payload,这payload其实也就是负载数据了,对吧。就是按字节存储的原始数据。
第三个呢,是MALU单元,那这三个概念是非常关键的三个概念。
这三个概念它分别代表了什么含义。所谓的SODB实际就是原始数据比特流,我们也叫它二进制数据串。那这个二进制数据串是由谁产生的呢?就是VCL层。也就是我们前面所介绍的帧间、帧内、熵编码出来之后的,没有做任何处理的一个二进制数据串,对吧这个数据串都是以位码在一起的。每一位都可能代表着某种含义对吧,这样压缩率高。按位码的时候,就会出现问题,就是它的长度有可能不是八的整数倍,为什么要用八的整数倍,因为一个字节是8位,我们计算机最底层的,尽量是以字节为单位,这样呢,才好处理,对吧,如果你都是位来计算的话,计算机也很麻烦。所以为了压缩的关系,使用字节。但是为了后面我们便于处理呢,最好让所有的数据呢,都是按照八的整数倍来处理。我们用这个VCL层所产生的这个数据呢,就是SODB。它不一定是8的整数倍,所以需要补齐。所以就产生了一个叫做RBSP。它有一个基本的算法。比如说我们后边差三位,那么我们先补一个一,后边补两个零。就是这样一个补位的方式,差五位,就是补一个1,4个零,这样我们就能理解了,对吧,所以SODB和RBSP他们之间的关系你就非常清楚了。
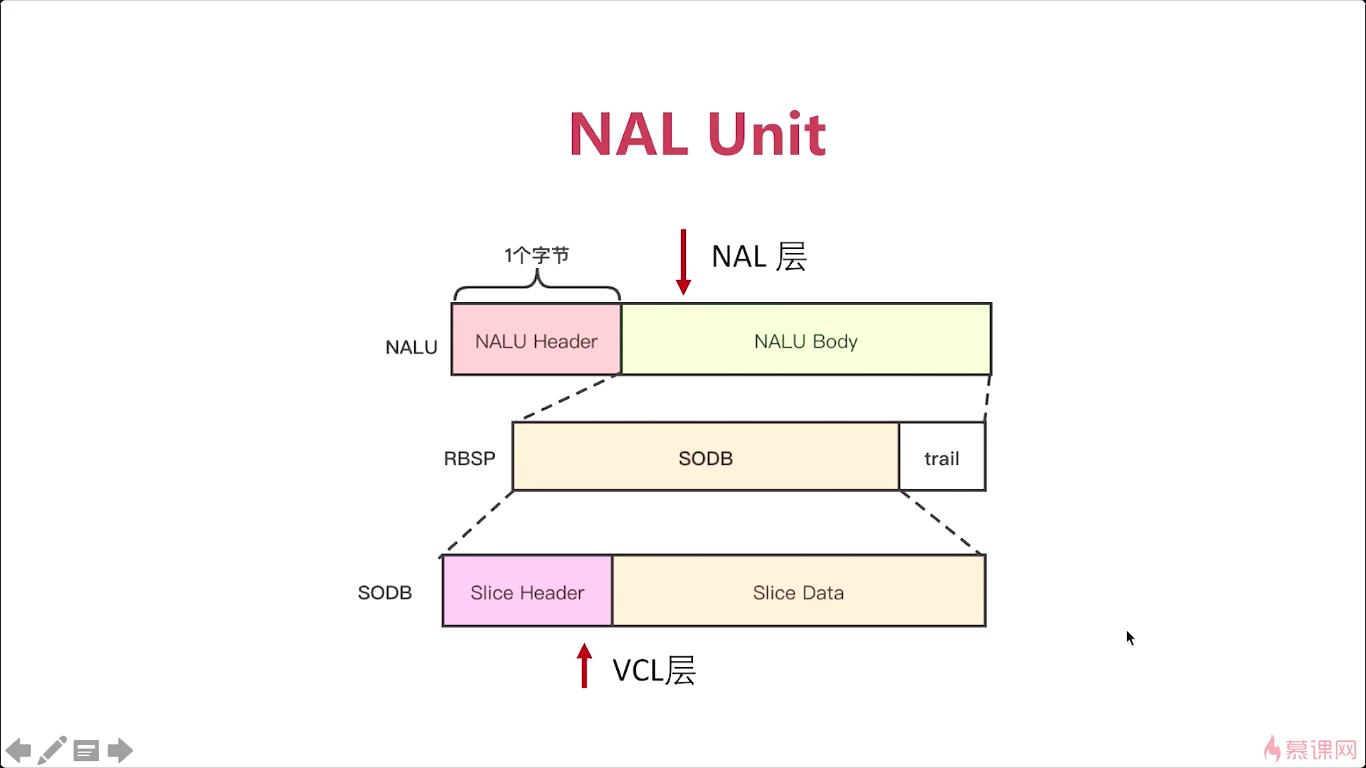
最后我们再来看NAL单元,实际是由一个nal_header还得加上RBSP,跟我们前面所介绍的这个分层又对应起来了,对吧,那我们整个H264码流是分成两层的一个是NAL层。一个是VCL层,实际上NAL层呢,就是这一个字节的header。加上我们用h264编码器编出的这个RBSP,这样就形成了NALU。
通过H264的这个分析工具你就可以看到整个的逻辑关系就非常清楚了。
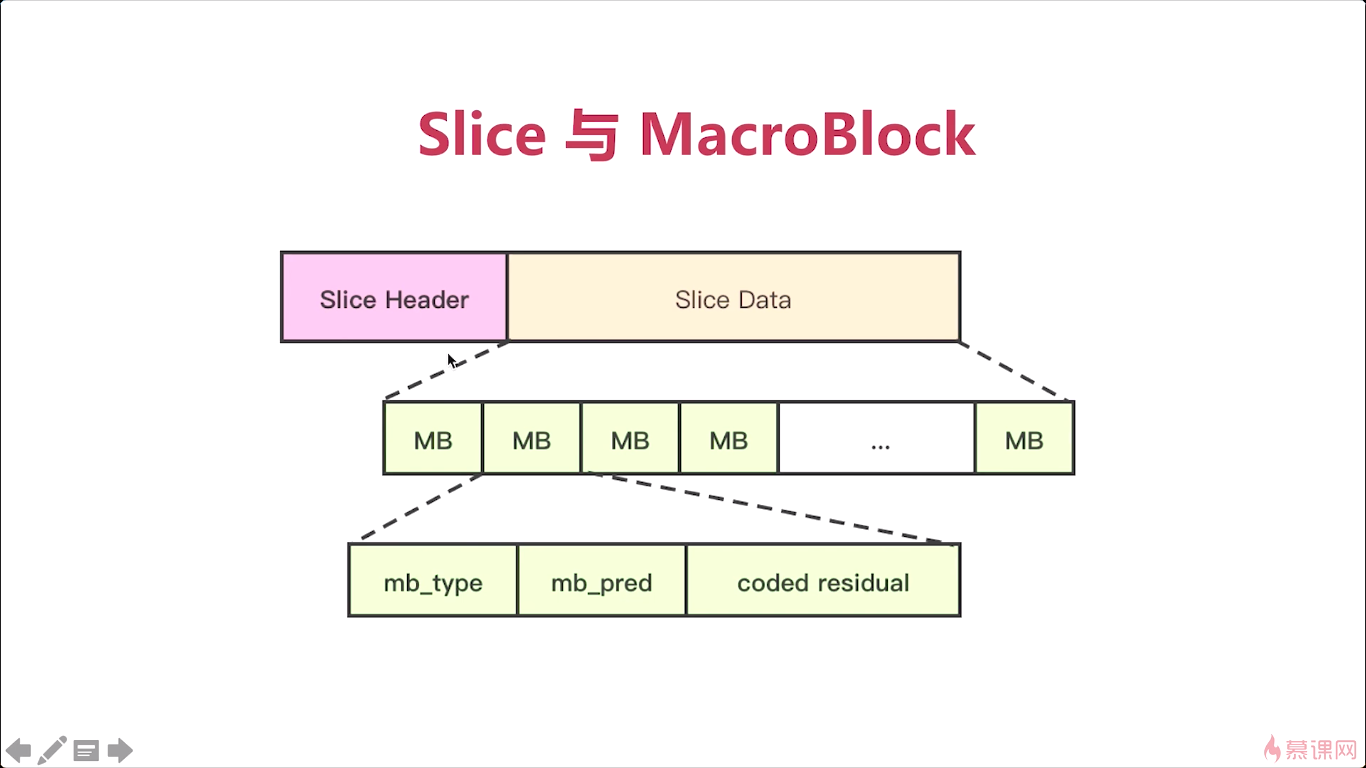
MB:宏块 mb_type宏块的类型 mb_pred宏块的预测值 coded residual残差值
第一种呢就是说我们,在文件中保存的它一般是什么情况呢。就是每一个单元前面都加一个start_code。就是00000001或者是000001。RTP传输不需要start code.
7 H264中的参数
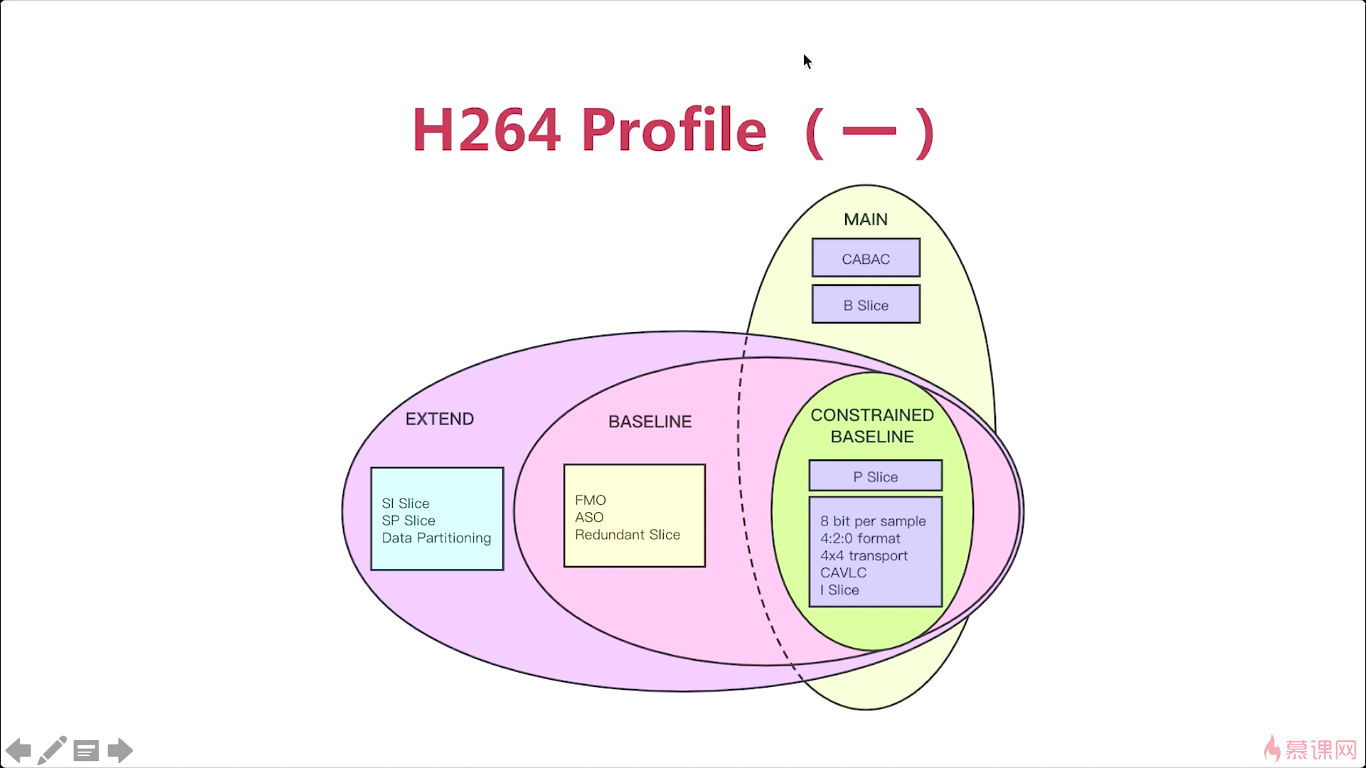
7-1 H264中的profile和level
那我们主要介绍一下sps中呢。第一个呢是h264_profile,第二个呢是h264_level,这两个参数它的含义是什么呢来里面看一下。



7-2 H264SPS中的重要参数


7-3 H264PPS与Slice-Header

7-4 H264分析工具1


8 RTMP和FLV
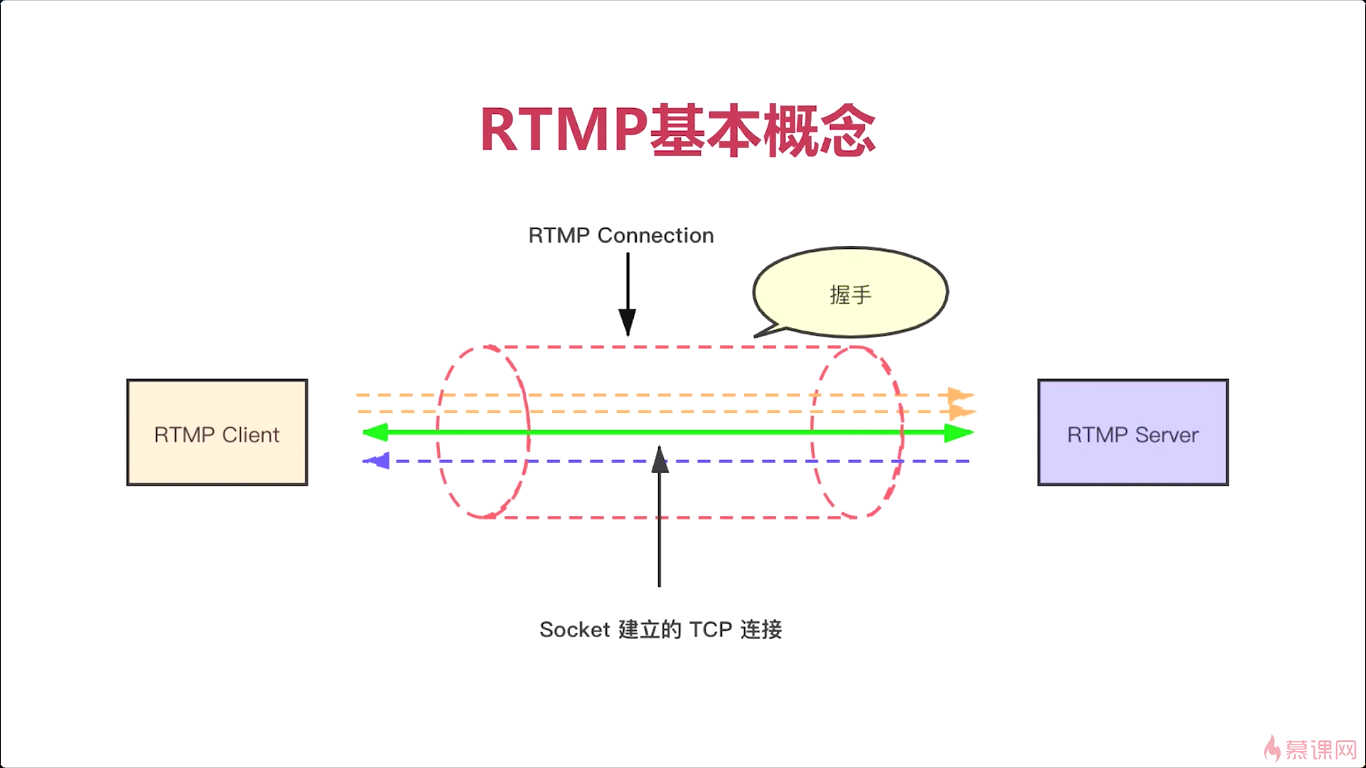
8-1 RTMP连接的建立
对于RTMP协议来说呢,我相信很多同学都对他有一定的了解。对吧,它主要应用在娱乐直播这个传输协议,或者是说点播的这种传输上,那与之对应的呢实际上还有另外一个协议称为hls协议,那它是由苹果公司推出的。它推出的主要目的是什么呢,就是为了替代RTMP协议。那虽然这个苹果公司啊他的想法是很好,并且adobe公司也因为苹果公司推出的HLS协议宣布今后不再对RTMP支持。但实际的应用场景中,尤其是在国内。让大家主要应用的还是RTMP。分析其中的原因呢,我认为有两个主要的原因第一个原因呢就是RTMP协议在传输的这种效率以及实时性上呢,要比HLS要高很多。有兴趣的同学呢,可以进一步去了解一下这两种传输协议的具体实现,那这样你就能分析出这样一个结果了。那么第二点呢是因为rtmp协议啊它存活的时间比较长了,那个厂商呢,尤其是云厂商在之前呢都是花了大量的这个财力物力人力,时间去把它进行一个推广应用,这个技术呢其实非常的成熟嗯,这时候你有了一个HLS对吧,你要替换RTMP协议。对于很多厂商来说呢,他又要花很多的人力物力时间去做这件事,但实际对于任何一家公司来说,他主要还是为了这个盈利为目的,的对吧,那你替换这样一个传输协议的话,对他来说成本是非常高的,所以呢,这主要基于这两种原因,那目前来说RTMP协议的是很难被替换掉的。更可能的一种情况是两者并存,
ok那我们再往后设想啊,就是说在若干年之后那有没有可能就是说hls替换rtmp呢,但我认为实际上这两种协议啊都有可能被替换掉,那会被什么替换掉呢,会被一种新的这种传输协议,那这种传输协议呢就不是依赖于tcp的传输协议了而是依赖于udp的,那现在我们可以看到整个这个传输界,那越来越多的人,已经这个认识了或者是在推进这个tcp可以替换掉的这一个过程,对吧,用什么替换呢就用udp来替换掉,对因为tc p他效率太低了,而且是太冗余了。在整个的连接过程中它会花费很长的时间,一旦说网络出现问题的时候。这种策略太复杂,还不如什么好呢,就是udp,可以用UDP重新做一个这种类似于tcp的一个更薄的,这种可靠的传输协议,这样来代替这个tcp,从而达到更高效的一种传输,这是未来的一种趋势了,我们就不再继续深入的讨论了。回到我们的这个课程中来。也就是说在未来的几年呢,rtmp还是有它这很大的优势,对吧相对于hls来说,所以呢我们必须要对这个协议有一些深刻的理解
RTMP是在TCP连接之上的。
绿色的线称为TCP。
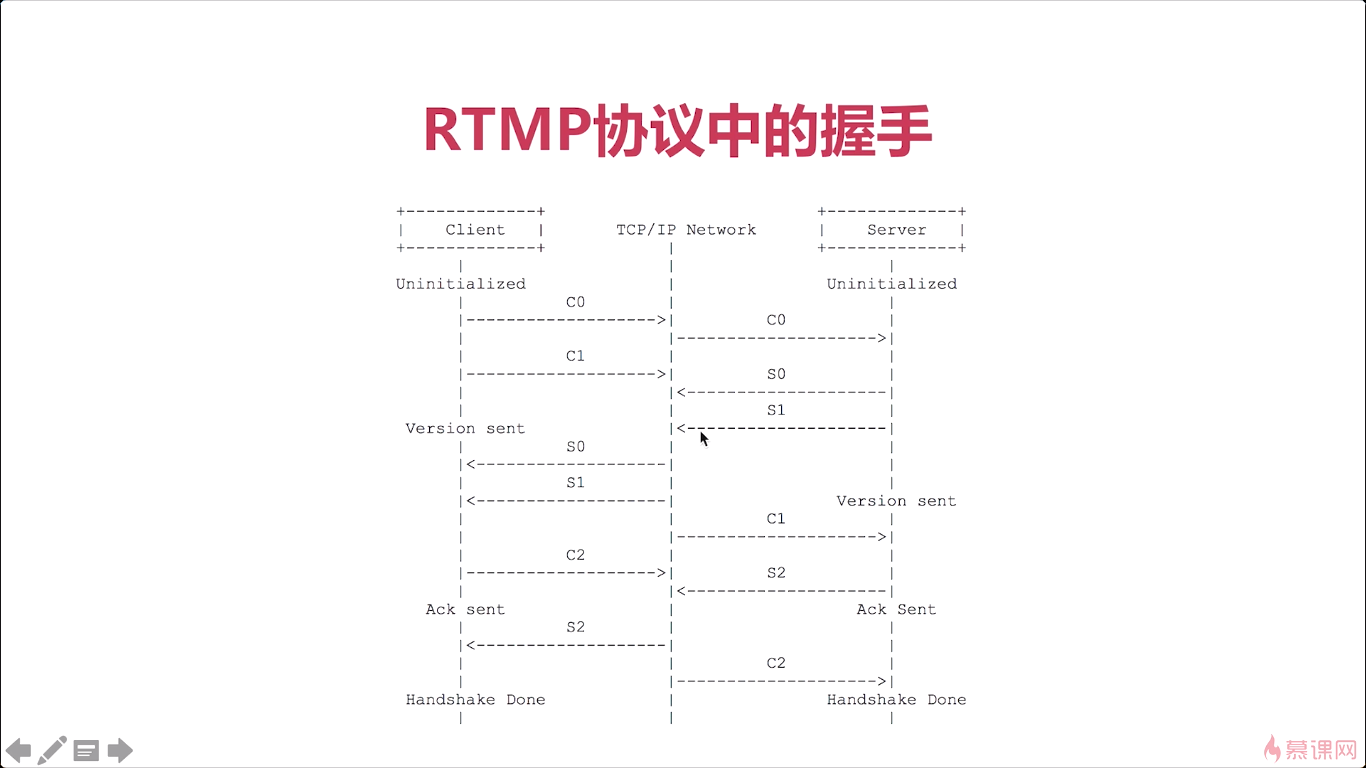
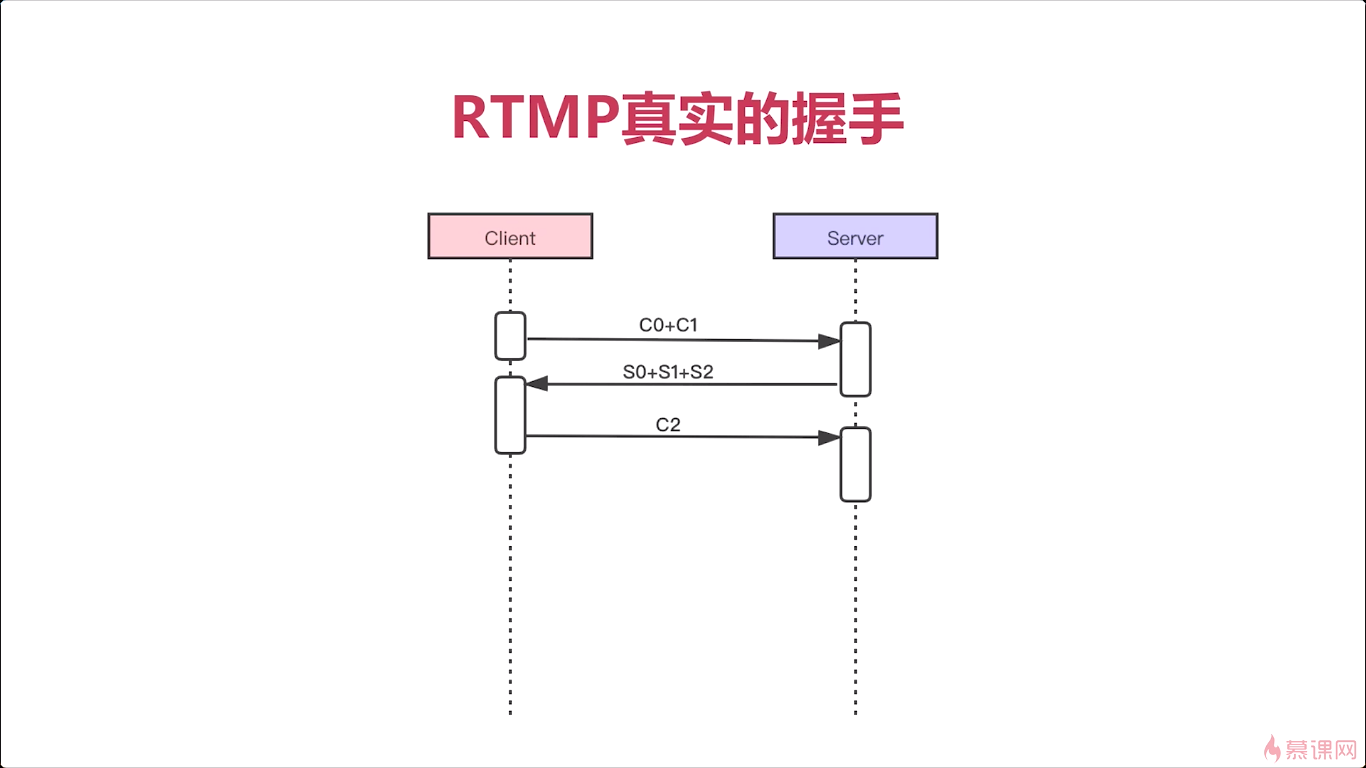
所以我们看文档与真实的情况还是有很大差别的,实际最早Adobe公司推出FMS(flash_communication)就是通讯的服务器是吧。很多人,抓起包然后分析它这个服务器相应的响应,最终总结出来一个真正的、它的具体实现是怎么做的,很多人就是根据这个他里边儿的实现,然后自己又实现了一遍,就是没有完全按照文档去实现。而且他文章写得特别罗嗦,有很多表述不清的地方,大家以后看这个文档的时候呢一定要注意。ok这是真实的握手,非常简单对吧

文档中:

实际上:
8-2 创建RTMP流
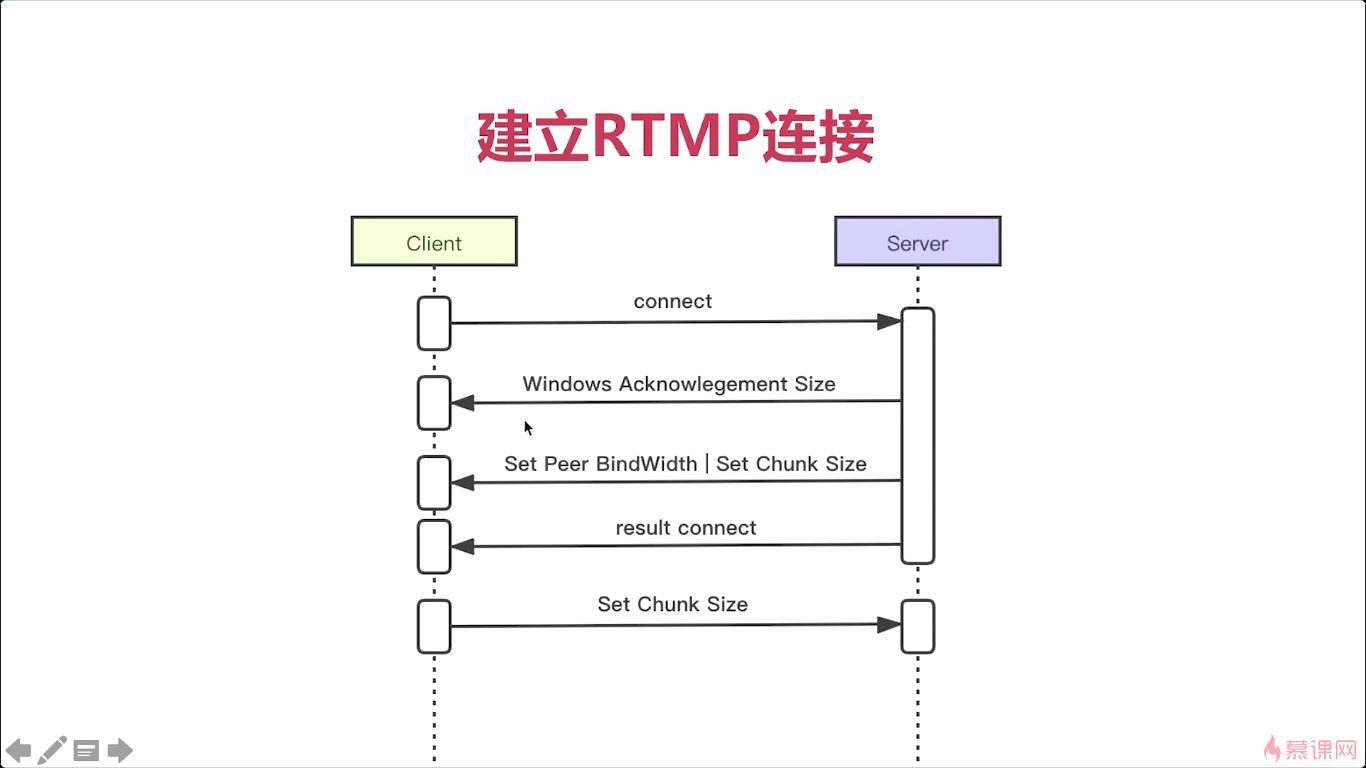
今天呢我们来介绍一下如何通过RTMP创建流。首先来看一下协议中RTMP流的创建,那在这里呢其实非常的简单对吧。那对于客户端来说来说呢,向服务端发送一个create the stream转一个命令消息。服务端收到消息然后返回结果也就是create the stream response。然后客户端收到消息之后,整个流就算创建成功了。

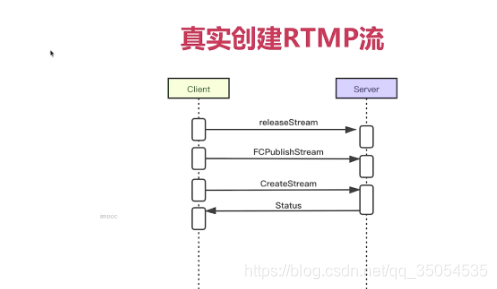
实际的情况,远非如此。通过我们抓包工具抓包呢,你就可以看到。在客户端与服务端创建流之前。其实他做了好几个这个消息的发送,对吧。第一步实际他应该调用一个release_stream,告诉服务端,如果你有这个流的话,你要先释放掉。第二步fc_publish_stream,那至于这个消息他起的具体作用是什么呢,实际上就是大家都不太清楚,但是还是一定要有这个消息。FC他如何去理解呢,实际就是这个flash_communication的一个缩写 后边是publish_stream,那具体这个消息从哪儿来的呢,这个就是大家通过抓包工具抓取的adobe公司官方发布的这个f ms这个服务器上他的一个消息,所以这个fc呢说明的就是在真实的实现过程中,然后具有的一个消息,实际有没有这个消息,从服务端的这个业务逻辑上来看,没有什么太大的作用,对吧,但是呢为了与这个官方的兼容。所以大家呢还是发这个消息。所以第一步你要花release_stream。第二步呢 要发 fc_publish_stream,那第三部呢才真正的是create_stream,服务端在收到这三个消息之后。返回一个status,在实际这个status呢就是create the stream的一个response。收到这个status之后,整个流就算创建成功了。
说所以我们可以看到这个协议文档,跟真实的实现,还是有很大差别的,也就是说对于Adobe公司来说,他的那份文档呢。并没有根据后来的具体实现,做变更,没有进行更新对吧,所以很多东西啊,你光看那个文档,还不足以满足你的这个真正去使用它去开发rtmp客户端或者是服务端
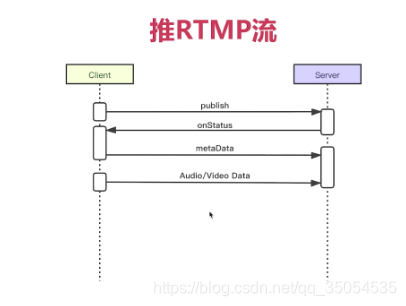
ok好那下一个呢,流创建成功之后呢,作为客户端、作为主播端,他就要推流,所谓推流就是把自己的音频和视频发送出去,那他是怎样一个过程呢,那这里我们就不看协议了。直接看我们真实的情况。
这个meta data里边存放的是什么数据呢,就是我们后边要发送的音频或者是视频的一些基本信息,比如说对于视频来说就包括了分辨率和帧率对吧宽多少高多少每秒钟多少帧。一些基本的信息, 要发送过去,对于音频来说呢就是采样大小采样率通道数啊,
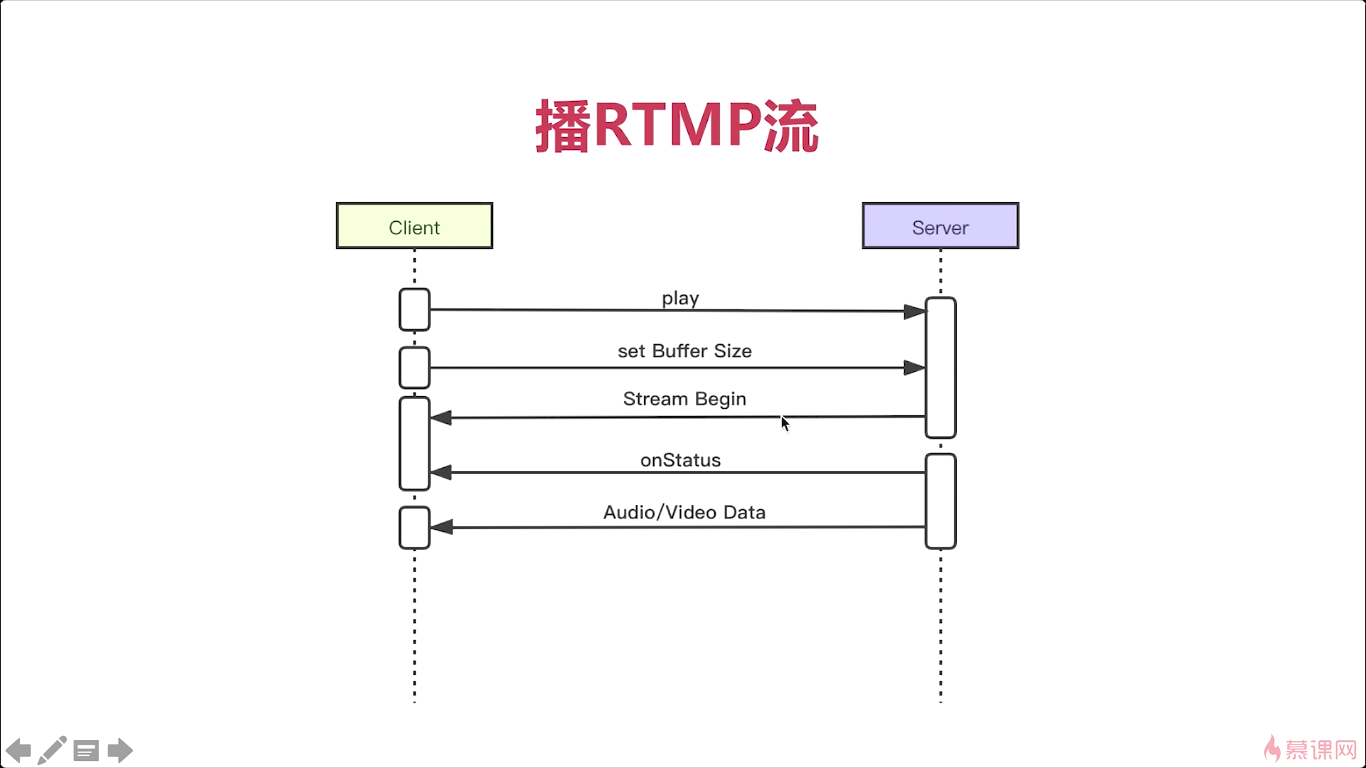
拉流:set_buffer_size,也就是设置缓冲区的大小,这个缓冲区呢就可以让你播放的更平滑,不会出现卡顿。那你buffer设置越大,这个平滑性越好。
8-3 RTMP消息
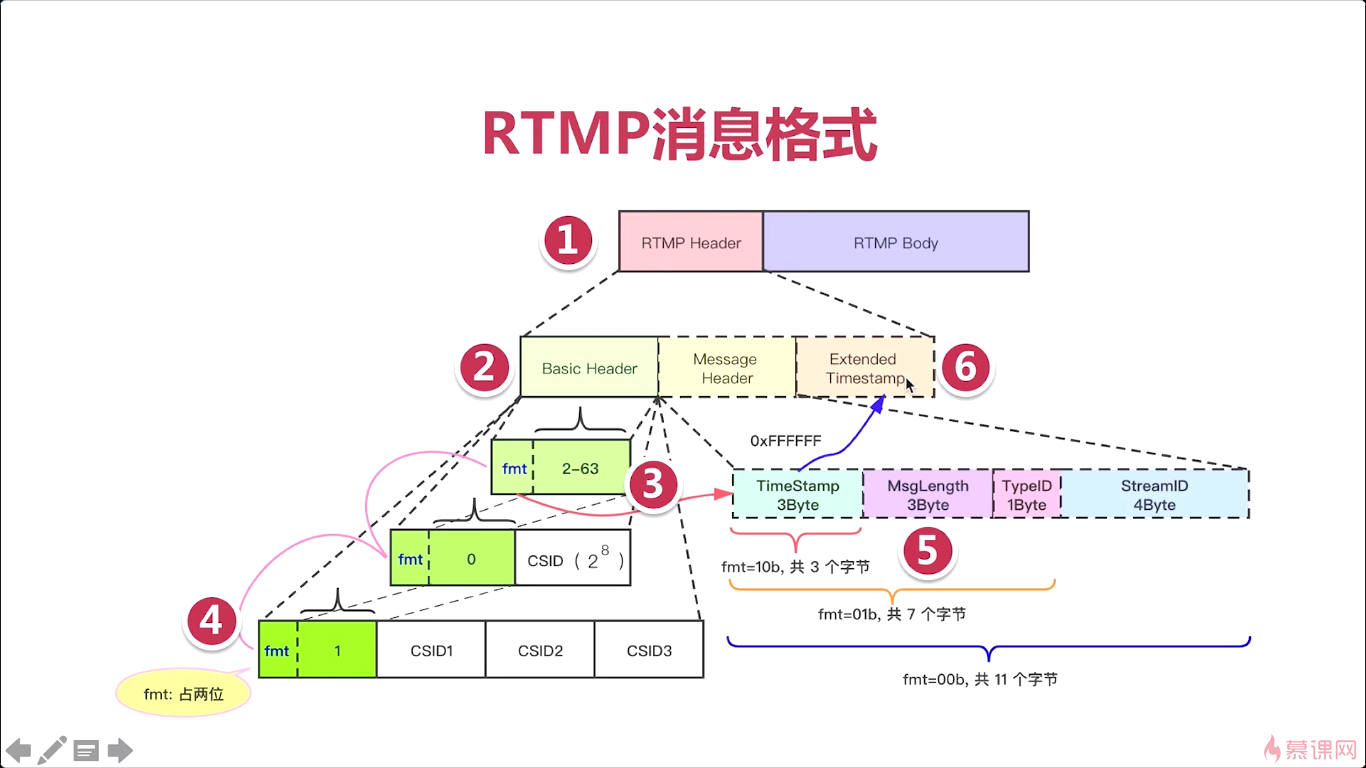
第2部分,虚线部分的Message Header和Extended Timestamp是可有可无的。实线部分的Basic Header是必须要有的。
第三部分: 如果fmt,csid号是2到63,则占一个字节(一般推流,64个id足够用了,云服务可能用下面的大的)
如果fmt,csid号是0,2的8次方+64开始,范围是2的8次方
如果fmt,csid号是1,2的24次方+2的8次方+64,范围是2的24次方
csid(chunk stream id)
第五部分,主要看fmt,如果fmt为01,则3个字节,其他看图。
第六部分:当Timestamp为全F,则需要拓展时间戳。
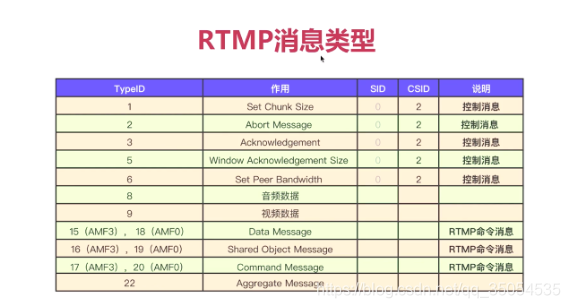
8-4 RTMP抓包分析
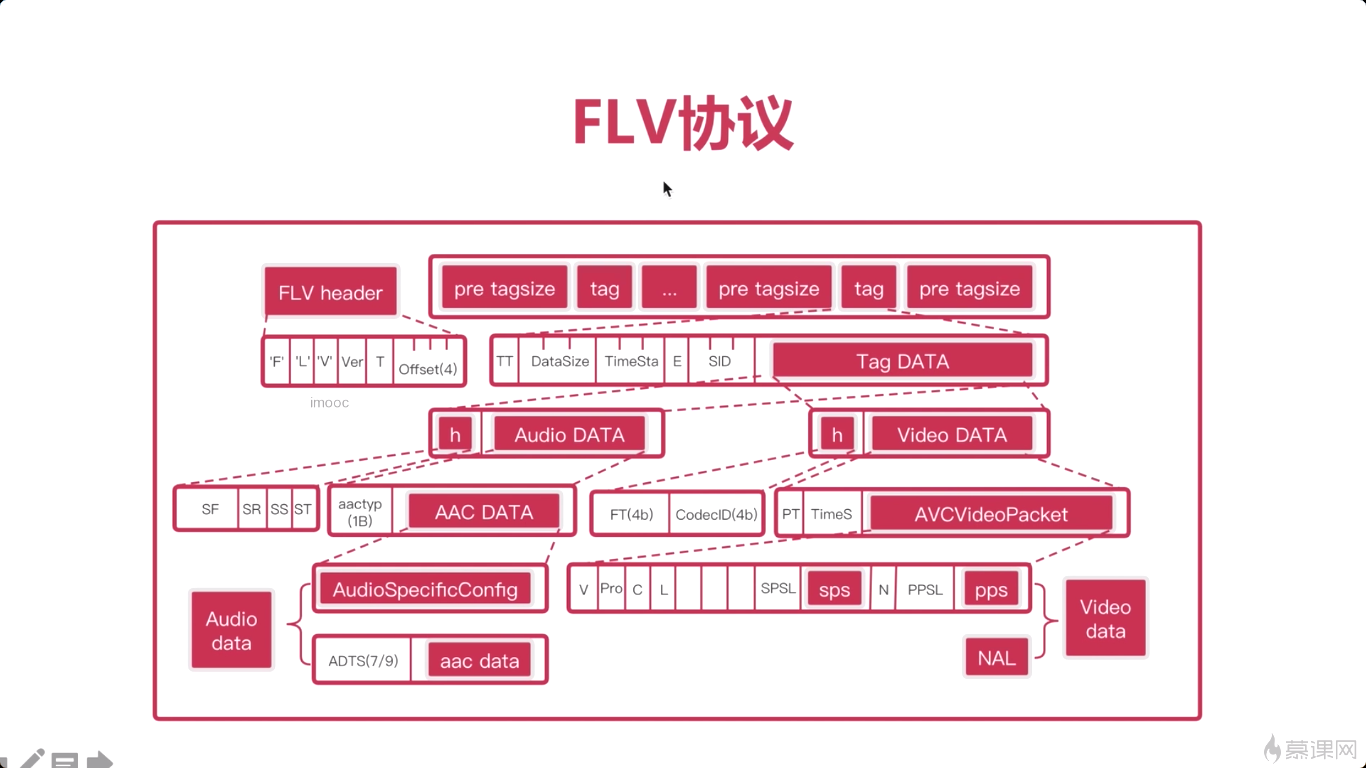
8-5 FLV协议
那为什么要介绍flv协议呢?其实主要的原因就是flv协议呢与RTMP协议有着密切的关系。实际上你基本上就可以把RTMP认为是FLV。最大的区别,就是在于所有的RTMP的数据,在FLV中要加一个头。我们称为Tag。
FLV文件格式如图
8-6 FLV协议分析器
雷神的(雷霄骅),FLV格式分析器
github上有很多。
C、C++的库都有
8-7 推流程序的骨架

