
每一个分区都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
一个分区在文件系统里存储为一个文件夹。文件夹里包含日志文件和索引文件。其文件名是其包含的offset的最小的条目的offset。

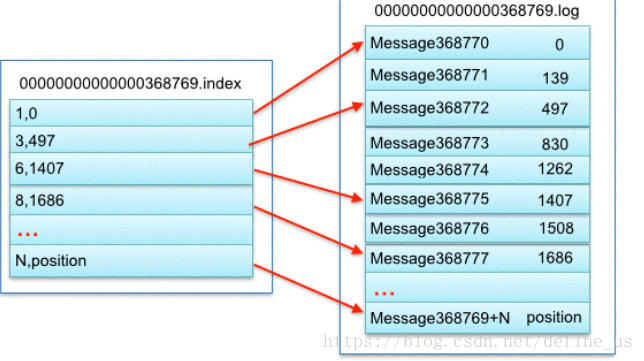
每个文件是一个segment。
在broker的log存储文件下,除了存储这各个topic的文件夹,还存在这几个checkpoint文件。分别是
-
recovery-point-offset-checkpoint 负责记录topic已经被写入磁盘的offset。
-
replication-offset-checkpoint 用来存储每一个replica的HighWatermark。由ReplicaManager负责写。参考下面关于HW定义,也就是那些已经成功被复制给其他broker消息的offset。
__consumer_offsets存储各个topic的消费者offset。但是,他的只有一份。
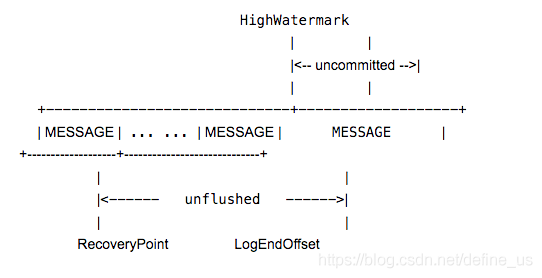
一些常见的offset
-
HighWatermark 最后committed消息的起始偏移。它后面的消息在目前还是uncommited的状态。
-
logStartOffset 日志段集合中第一个日志段(segment)的基础位移,也就是这个日志对象的基础位移
-
LogEndOffset 下一条将要被加入到日志的消息的位移。注意,这个offset未必在硬盘中,可能目前只在内存中还没有被flush到硬盘。
-
recovery-point-offset-checkpoint 已经被确认写入磁盘的offset
-
replication-offset-checkpoint 已经确认复制给其他replica的offset。也就是HW。
失败的follower开始恢复时,会首先将自己的日志截断到上次的checkpointed时刻的HW。然后,向leader拉去消息。
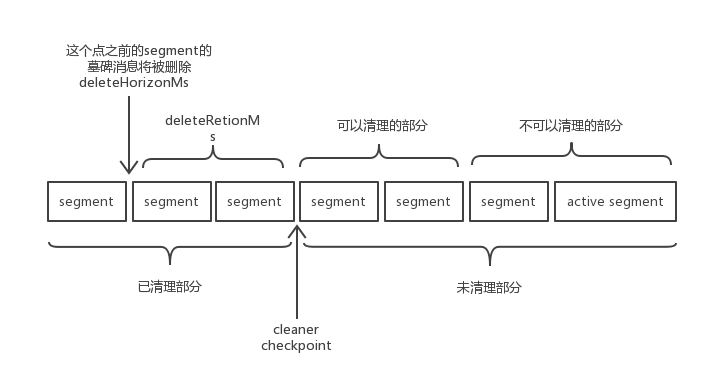
同时,kafka有日志清理机制,日志清理主要是用于缩减日志的大小,如清理重复的key等等。min.compaction.lag.ms配置不满足的最近segment和activesegment显然是不能清理的。
FAQ
Resetting first dirty offset of __consumer_offsets
例如,重复报错信息如下,这显然是清理线程在一直遇到麻烦。
[2018-06-01 13:46:27,156] WARN Resetting first dirty offset of __consumer_offsets-18 to log start offset 44 since the checkpointed offset 42 is invalid. (kafka.log.LogCleanerManager$)
val lastCleanOffset: Option[Long] = lastClean.get(topicPartition) // If the log segments are abnormally truncated and hence the checkpointed offset is no longer valid; // reset to the log starting offset and log the error val logStartOffset = log.logSegments.head.baseOffset val firstDirtyOffset = { val offset = lastCleanOffset.getOrElse(logStartOffset) if (offset < logStartOffset) { // don't bother with the warning if compact and delete are enabled. if (!isCompactAndDelete(log)) warn(s"Resetting first dirty offset of ${log.name} to log start offset $logStartOffset since the checkpointed offset $offset is invalid.") logStartOffset } else { offset } }
我们可以看见,清理线程试图获取一个partition的最后清理的位移(lastCleanOffset),并同时获取了该partition中现存的所有segment中最小的头部offset(logStartOffset)。但是,却发现lastCleanOffset比logStartOffset还要小。清理线程自然会反应,那些我没有清理的数据跑哪里去了呢?抱怨完后,其将firstDirtyOffset置为logStartOffset,准备下一次从这里开始清理。报错中令人迷惑的checkpointed offset是指lastCleanOffset。
val dirtyNonActiveSegments = log.logSegments(firstDirtyOffset, log.activeSegment.baseOffset)
kafka本来应该是在完成清理后将lastCleanOffset提高,但是问题在于,如果此时没有可清理的segment,lastCleanOffset也就将保持不变。则线程下一次循环时仍然会遇到这个问题。
解决方案中最快捷的是清空kafka的data目录。或者忽略这个问题,等待大量数据灌入。一旦产生可以清理的segment,这个问题就会解决。