灰色关联分析
可以在数据量比较少的情况下,分析出主要因素、次要因素等
(1) 数理统计传统方法的问题
- 回归分析、方差分析、主成分分析的不足之处
- 要求数据量比较大,数据量较少就难以找出统计规律。
- 要求样本服从某个典型分布,但通常比较难满足。
- 可能出现量化结果与定性分析结果不符的现象,比如符号不同,由内生性导致。
(2) 灰色关联分析
1. 基本思想
- 根据序列曲线的几何形状的相似程度来判断特征的联系是否紧密,曲线越接近相应序列之间的关联度就越大,反之越小。
- 本质是在找系统行为的映射量,用映射量来间接地表征系统行为。
2. 进行系统分析
假设数据一共有 n n n 个样本, p p p 个指标:
X = [ x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n p ] X=\left[ \begin{matrix} x_{11}&x_{12}&\dotsb&x_{1p}\\ x_{21}&x_{22}&\dotsb&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{n1}&x_{n2}&\dotsb&x_{np}\\ \end{matrix} \right] X=⎣⎢⎢⎢⎡x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp⎦⎥⎥⎥⎤
反映所有指标的总的序列为: y = ( y 1 , y 2 , … , y n ) T \boldsymbol{y}=(y_1,y_2,\dots,y_n)^T y=(y1,y2,…,yn)T
① ① ① 确定分析数列
- 母序列:能反应系统行为特征的数据序列,类似于因变量的定义。
- 子序列:影响系统行为的因素组成的数据序列,类似于自变量的定义。
② ② ② 对变量进行预处理
- 目的:去量纲并且缩小指标的范围。
- 对母序列和子序列中的每个值进行处理:先求出每个指标的均值,再用该指标中的每个元素都除以其均值。
- 假设预处理之后的序列为
- 母序列: y = ( y ( 1 ) , y ( 2 ) , … , y ( n ) ) T \boldsymbol{y}=(y(1),y(2),\dots,y(n))^T y=(y(1),y(2),…,y(n))T
- 子序列:
x 1 = ( x 1 ( 1 ) , x 1 ( 2 ) , … , x 1 ( n ) ) T x 2 = ( x 2 ( 1 ) , x 2 ( 2 ) , … , x 2 ( n ) ) T ⋮ x p = ( x p ( 1 ) , x p ( 2 ) , … , x p ( n ) ) T \begin{aligned} \boldsymbol{x_1}&=(x_1(1),x_1(2),\dots,x_1(n))^T\\ \boldsymbol{x_2}&=(x_2(1),x_2(2),\dots,x_2(n))^T\\ \vdots\\ \boldsymbol{x_p}&=(x_p(1),x_p(2),\dots,x_p(n))^T\\ \end{aligned} x1x2⋮xp=(x1(1),x1(2),…,x1(n))T=(x2(1),x2(2),…,x2(n))T=(xp(1),xp(2),…,xp(n))T
③ ③ ③ 计算子序列中各个指标与母序列的关联系数
a = min i min k ∣ y ( k ) − x i ( k ) ∣ a=\min\limits_i\min\limits_k|y(k)-x_i(k)| a=iminkmin∣y(k)−xi(k)∣ (两极最小差)
b = max i max k ∣ y ( k ) − x i ( k ) ∣ b=\max\limits_i\max\limits_k|y(k)-x_i(k)| b=imaxkmax∣y(k)−xi(k)∣ (两极最大差)
y ( k ) y(k) y(k) 与 x i ( k ) x_i(k) xi(k) 的关联系数
ϵ i ( k ) = a + ρ b ∣ y ( k ) − x i ( k ) ∣ + ρ b ( i = 1 , 2 , … , p ; k = 1 , 2 , … , n ) \epsilon_i(k)=\dfrac{a+\rho b}{|y(k)-x_i(k)|+\rho b}~~(i=1,2,\dots,p;k=1,2,\dots,n) ϵi(k)=∣y(k)−xi(k)∣+ρba+ρb (i=1,2,…,p;k=1,2,…,n)
ρ \rho ρ 称为分辨系数,值越小,分辨力越大,一般 ρ ρ ρ 的取值区间为 ( 0 , 1 ) (0,1) (0,1),具体取值可视情况而定。当 ρ ≤ 0.5463 \rho\le0.5463 ρ≤0.5463 时,分辨力最好,通常取 ρ = 0.5 ρ = 0.5 ρ=0.5。
④ ④ ④ 计算关联度
计算 y \boldsymbol{y} y 与 x i \boldsymbol{x}_i xi 之间的关联度
r i = 1 n ∑ k = 1 n ϵ i ( k ) r_i=\dfrac{1}{n}\sum_{k=1}^n\epsilon_i(k) ri=n1k=1∑nϵi(k)
3. 用于综合评价模型
① ① ① 对指标进行正向化,就是在 TOPSIS 中的处理方法。
② ② ② 对正向化后的矩阵进行预处理,得到矩阵
Z = [ z 11 z 12 ⋯ z 1 p z 21 z 22 ⋯ z 2 p ⋮ ⋮ ⋱ ⋮ z n 1 z n 2 ⋯ z n p ] Z=\left[ \begin{matrix} z_{11}&z_{12}&\dotsb&z_{1p}\\ z_{21}&z_{22}&\dotsb&z_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ z_{n1}&z_{n2}&\dotsb&z_{np}\\ \end{matrix} \right] Z=⎣⎢⎢⎢⎡z11z21⋮zn1z12z22⋮zn2⋯⋯⋱⋯z1pz2p⋮znp⎦⎥⎥⎥⎤
③ ③ ③ 构造虚拟母序列:取矩阵 Z Z Z 中每一行的最大值构成母序列。
④ ④ ④ 计算各个指标与母序列间的灰色关联度 r i ( i = 1 , 2 , … , p ) r_i~~(i=1,2,\dots,p) ri (i=1,2,…,p)
⑤ ⑤ ⑤ 计算各个指标的权重: w i = r i ∑ i = 1 p r i ( i = 1 , 2 , … , p ) w_i=\dfrac{r_i}{\displaystyle\sum_{i=1}^pr_i}~~(i=1,2,\dots,p) wi=i=1∑priri (i=1,2,…,p)
⑥ ⑥ ⑥ 第 k k k 个评价对象的得分 S k = ∑ i = 1 p z k i w i ( k = 1 , 2 , … , n ) S_k=\sum_{i=1}^pz_{ki} w_i~~(k=1,2,\dots,n) Sk=i=1∑pzkiwi (k=1,2,…,n)
⑦ ⑦ ⑦ 对得分进行归一化
S k ′ = S k ∑ k = 1 p S k S'_k=\dfrac{S_k}{\displaystyle\sum_{k=1}^pS_k} Sk′=k=1∑pSkSk
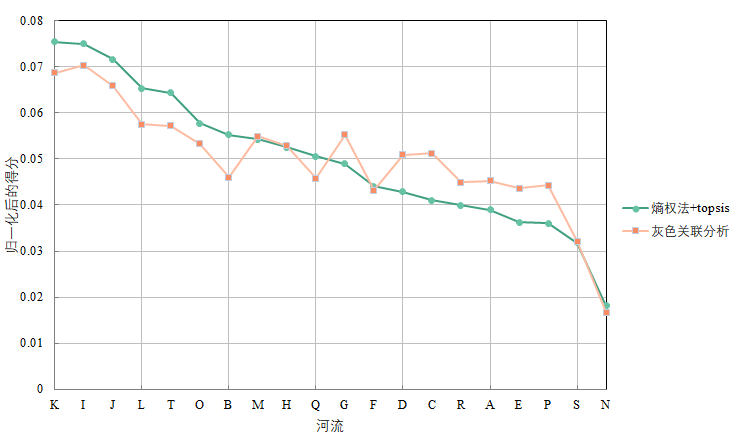
下图是分别使用灰色关联分析和熵权法+topsis得到的结果,可以看出基本相同。