1.首先需要调用NumPy和pandas
NumPy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas和numpy的关系:numpy是列表,pandas是字典,pandas基于numpy构建。
import pandas as pd
import numpy as np
2.读取表格并得到表格行列信息
表格如下
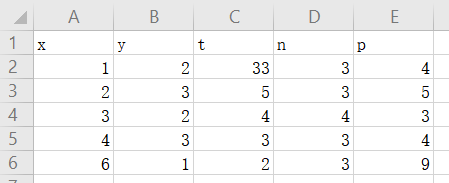
df=pd.read_excel('test.xlsx')
height,width = df.shape
print(height,width,type(df))#得到如下输出,为一个5行5列的数据块,为DataFrame格式:
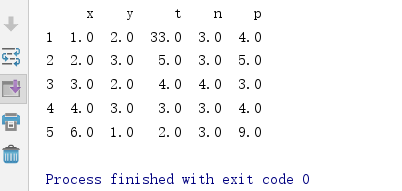
print(df)#直接print(df)得到的结果

对比结果和表格,很显然表格中的第一行(英文部分)被定义为数据块的列下标,而实际视作数据的是后四行;并且自动在表格第一列之前加了一个行索引{0,1,2,3,4}。
3.提取数据放入数组中
x = np.zeros((height,width))
for i in range(0,height):
for j in range(1,width+1): #遍历的实际下标,即excel第一行
x[i][j-1] = df.iloc[i,j-1]
print(x.shape)
print(x)
用np.zeros()方法定义一个初试值全为0的二维数组(需要导入numpy库),用df.iloc[i,j]读取数据并复制入二维数组中,其中for i in range(0,height)循环表示从下标0到下标height-1(不包含height),得到的输出如下:

3.将numpy数组写入Excel文件
将文件写入excel表格中
new_data = pd.DataFrame(x)
# 更改表的索引
new_data.columns = ['x','y','t','n','p'] #将第一行的0,1,2,...,9变成x,y,t,...
new_data.index = ['1','2','3','4','5']
# 将文件写入excel表格中
writer = pd.ExcelWriter('newTest.xlsx') #创建名称为newTest的excel表格
new_data.to_excel(writer,'sheet_1',float_format='%.5f') #float_format 控制精度,将new_data写到newTest表格的第一页中
writer.save()
print(new_data)
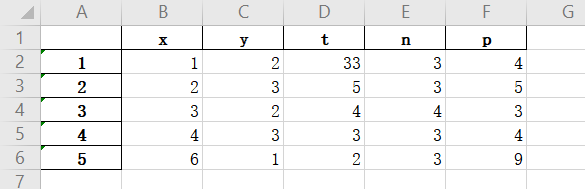
打开新的excel:
参考:
https://blog.csdn.net/kazhaxi/article/details/103238725
https://blog.csdn.net/qq_41938858/article/details/87867237
https://blog.csdn.net/qq_34392457/article/details/89093852