ITIL 4的监控管理
在DevOps风行的当下,人们越来越关注自动化运维。其中,监控预告警、监控自愈越发流行起来。在《DevOps实践指南》和《持续交付 发布可靠软件的系统方法》两本书中(DevOps的教科书级别),都有涉及讲解监控管理和实施。其实,监控早不是什么新概念,运维界无论在理论还是工具中,一直在不断探索。监控管理虽然在ITIL V2 中未曾提交,但在ITIL V3的《服务运营》中作为运营活动来介绍,将监控相关的事件管理,作为一个独立的流程讲解的。在ITIL 4中,监控管理和事件管理,共同组成了一个服务管理实践(Practice)-"监控和事件管理实践"。
监控在ITIL 4中是如何讲解的?
很多人熟悉各种监控工具,但是却无法从更高的流程层面来归纳和解释监控管理的活动。在这方面,我们可以看看ITIL 4的讲解。
1. 监控和事件管理密不可分。需要注意的是,这里的“事件”并不等于“故障”。事件的含义是:
事件:对服务或其他配置项(CI)的管理具有重要意义的任何状态更改。
ITIL 4中有专门讲解“监控和事件”的管理实践。该实践的目的是系统地观察服务和服务组件,并记录和报告确定为事件的状态变化。此实践可识别基础结构、服务、业务流程和信息安全事件并确定其优先级,并建立对这些事件的适当响应,包括对可能导致潜在故障或事件的情况作出响应。
监控部分侧重于服务和配置项(CI),以检测潜在重要的条件,跟踪和记录服务程序和CI的状态,并将此信息提供给相关人员。而事件管理实践部分侧重于那些被组织定义为事件的状态变化的监控,确定它们的重要性,并识别和启动对它们的正确响应。有关事件的信息也会被记录、存储并提供给相关人员。简单来说,监控是来生产监控数据和信息的,而事件是来消费这些数据和信息,并制定相应的响应方案。
2. 监控和事件管理的主要流程:
监测和事件管理实践活动形成三个过程:
●监控规划过程:向监控中添加监控项的过程,定义监控项的优先级,选择要监测的特征,确定事件分类的指标和阈值,将事件与负责的行动计划和团队对应起来。
●事件处理流程
●监控和事件管理审查:该流程是针对重大事件事后分析、筛选和关联分析的更新、服务“健康模型”、自动化和可操作性监控的改进而计划或触发的审查流程。
具体活动见下图: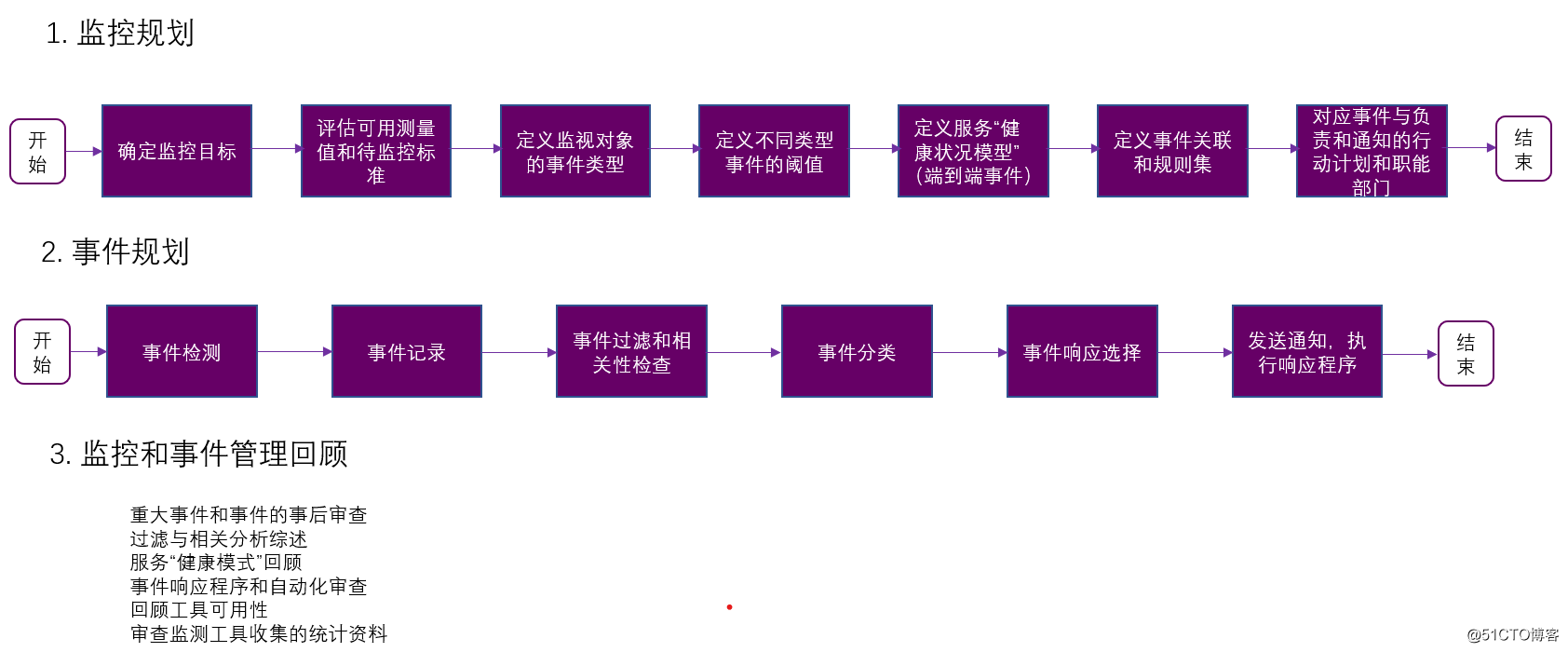
3. 为监控的输出信息分级:
我们需要注意的是,监控是事件管理所必需的,但并非所有监控结果都会检测到事件。阈值和其他标准决定了哪些状态更改将被视为事件。同样,需要注意的是,并非所有事件都具有相同的重要性或需要相同的响应。我们需要为发生的事件类别定义分类标准。典型的类别,按照重要性的增加顺序,是信息性事件、警告性事件和异常事件。
信息:不需要任何措施,也不代表异常情况的事件,一般用于检查设备或者服务的状态,或者确认活动或任务完成。比如:设备成功接入网络,交易成功完成等。
警告:当服务或者设备接近设定的阈值产生的事件,旨在通知相关的人员、流程或者工具,以便检查这种情况,并采取相应措施,以防发生异常情况。例如:服务器的内存从65%持续升高到75%,服务器的响应时间长到令人无法接受,将会违反OLA;网络上的冲突率在过去一小时,提高了15%。
异常:服务或设备当前运行异常,违反了OLA或者SLA。需要注意,异常情况不总是表现为故障。比如,网络中发现了未被授权的设备,这是异常情况。根据故障和变更管理流程,这些异常可以通过故障和变更进行处理。
我们需要将事件按照预先定义的顺序,匹配一系列标准和规则,也称为业务规则,用来判断业务影响的级别和类型。根据业务规则,我们还需要确定触发程序和响应措施。响应措施里面可以包括记录事件、自动响应、告警和人工干预、故障、问题或者变更等,这些响应措施也产生了和其他实践(流程)的接口。
4. 和其他实践的接口:
如表2.1所示,以下活动与监控和事件管理密切相关。请记住,ITIL实践只是价值流环境中使用的工具的集合,应该根据情况在必要时进行组合。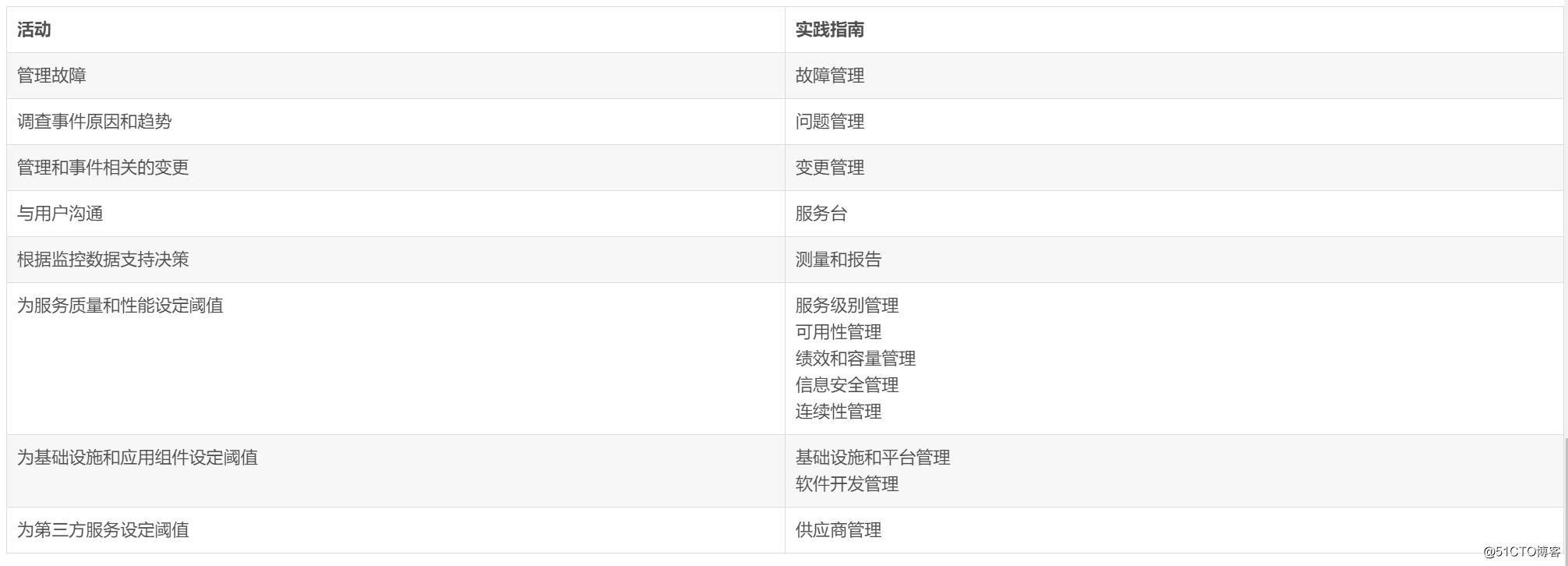
监控管理的落地
ITIL 4虽然讲解了监控管理的框架,但是并没有给出可以落地的工具和实现方法,当然这也是ITIL 一如既往的风格。我在工作中接触到的监控工具包括,Zabbix, Nagios, ELK+Grafana. 网上有很多介绍这些工具的文章,在此就赘述了。