k近邻算法是几个机器学习算法中最简答的,很好理解也很容易实现。
它的工作原理是:
就不自己总结了,拿到博友的一段解释吧。原博客见:https://blog.csdn.net/weixin_41571493/article/details/82695010
存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
举个简单的例子,我们可以使用k-近邻算法分类一个电影是爱情片还是动作片。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 电影1 | 1 | 101 | 爱情片 |
| 电影2 | 5 | 89 | 爱情片 |
| 电影3 | 108 | 5 | 动作片 |
| 电影4 | 115 | 8 | 动作片 |
表1.1 每部电影的打斗镜头数、接吻镜头数以及电影类型
表1.1就是我们已有的数据集合,也就是训练样本集。这个数据集有两个特征,即打斗镜头数和接吻镜头数。除此之外,我们也知道每个电影的所属类型,即分类标签。用肉眼粗略地观察,接吻镜头多的,是爱情片。打斗镜头多的,是动作片。以我们多年的看片经验,这个分类还算合理。如果现在给我一部电影,你告诉我这个电影打斗镜头数和接吻镜头数。不告诉我这个电影类型,我可以根据你给我的信息进行判断,这个电影是属于爱情片还是动作片。而k-近邻算法也可以像我们人一样做到这一点,不同的地方在于,我们的经验更”牛逼”,而k-邻近算法是靠已有的数据。比如,你告诉我这个电影打斗镜头数为2,接吻镜头数为102,我的经验会告诉你这个是爱情片,k-近邻算法也会告诉你这个是爱情片。你又告诉我另一个电影打斗镜头数为49,接吻镜头数为51,我”邪恶”的经验可能会告诉你,这有可能是个”爱情动作片”,画面太美,我不敢想象。 (如果说,你不知道”爱情动作片”是什么?请评论留言与我联系,我需要你这样像我一样纯洁的朋友。) 但是k-近邻算法不会告诉你这些,因为在它的眼里,电影类型只有爱情片和动作片,它会提取样本集中特征最相似数据(最邻近)的分类标签,得到的结果可能是爱情片,也可能是动作片,但绝不会是”爱情动作片”。当然,这些取决于数据集的大小以及最近邻的判断标准等因素。
1.2 距离度量
我们已经知道k-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签。那么,如何进行比较呢?比如,我们还是以表1.1为例,怎么判断红色圆点标记的电影所属的类别呢?如图1.1所示。
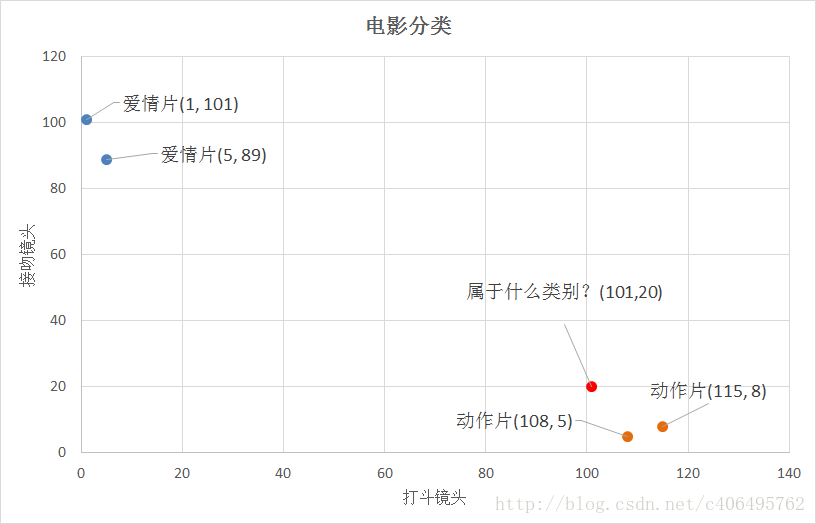
图1.1 电影分类
我们可以从散点图大致推断,这个红色圆点标记的电影可能属于动作片,因为距离已知的那两个动作片的圆点更近。k-近邻算法用什么方法进行判断呢?没错,就是距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用我们高中学过的两点距离公式计算距离,如图1.2所示。
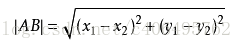
图1.2 两点距离公式
通过计算,我们可以得到如下结果:
- (101,20)->动作片(108,5)的距离约为16.55
- (101,20)->动作片(115,8)的距离约为18.44
- (101,20)->爱情片(5,89)的距离约为118.22
- (101,20)->爱情片(1,101)的距离约为128.69
通过计算可知,红色圆点标记的电影到动作片 (108,5)的距离最近,为16.55。如果算法直接根据这个结果,判断该红色圆点标记的电影为动作片,这个算法就是最近邻算法,而非k-近邻算法。那么k-邻近算法是什么呢?k-近邻算法步骤如下:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点所出现频率最高的类别作为当前点的预测分类。
比如,现在我这个k值取3,那么在电影例子中,按距离依次排序的三个点分别是动作片(108,5)、动作片(115,8)、爱情片(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以该红色圆点标记的电影为动作片。这个判别过程就是k-近邻算法。
2. 距离的计算有多重方法
1. 常见的欧式距离

dist为xi和yi之间的距离,假设x、y为n维。
2.曼哈顿距离:

3.算法步骤
1.选取k,
2. 计算待分类的数据与每个一样本的距离,按距离降序排列
3. 选取前k个距离,并记住每个的分类
4. k个分类占最多的类别标签即为最终的分类。