1.K近邻算法的介绍:
K近邻算法是一个理论上比较成熟的分类算法,也是机器学习中的基本算法。该方法的思路为:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一类别,那么这个样本也属于这个类别。用官方的话来说,就是给定一个训练数据集,对新的输入实例,在训练数据集中找到K个最邻近的数据点,这K个数据点大多属于某一类,那么这个实例也属于这一类。基本的过程为:将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取出样本中最相似的分类标签,一般提取出的样本K不大于20,找出这K个中次数最多的分类,即作为这个数据的分类。不足之处就是计算量比较大。
2.算法的基本步骤:
1.计算已知类别数据集中的点与当前点的距离;
2.按照距离递增次序进行排序;
3.选取与当前距离最小的K个点;
4.确定前K个点所在类别的出现频率,
5.返回前K个点所出现频率最高的类别作为当前点的预测分类;
3.算法的举例:
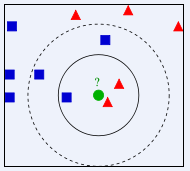
寻找中间绿色点为哪一类:
当 K=3时,绿色点的最近3个邻居是一个小蓝正方形和2个红小三角形,少数从属于多数,基于统计的方法,这个绿色待分类点属于红色小三角形一类。
当K= 5时,绿色点的最近5个邻居时两个小红三角形和三个小蓝正方形。还是少数从属于多数,这个绿色待分类点属于小蓝正方形。
当K为其他值时,方法依次类推,距离的计算公式一般为欧式距离的计算。

4.案例代码显示
# -*- coding: UTF-8 -*-
import numpy as np
import operator
"""
函数说明:创建数据集
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
Modify:
2017-07-13
"""
def createDataSet():
#四组二维特征
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四组特征的标签
labels = ['喜欢','喜欢','不喜欢','不喜欢']
return group, labels
"""
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
Modify:
2017-07-13
"""
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [101,20]
#kNN分类
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)分类器并不一定会得到百分百的结果,可以用检测数据来检测分类器的正确率。另外分类器的性能也会受到分类器设置和数据集的影响。错误率是常用的评估方法,主要用于分类器在某个数据集上的分类效果,错误率的范围一般在0和1之间,可以将训练集中的数据,大部分用于分类,小部分用于检测分类器的错误率。测试的数据应该是随机选择的。
import numpy as np
import operator
"""
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
Modify:
2017-03-24
"""
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
Modify:
2017-03-24
"""
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
arrayOLines = fr.readlines()
#得到文件行数
numberOfLines = len(arrayOLines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t')
#将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index,:] = listFromLine[0:3]
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
"""
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
Modify:
2017-03-24
"""
def autoNorm(dataSet):
#获得数据的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
#最大值和最小值的范围
ranges = maxVals - minVals
#shape(dataSet)返回dataSet的矩阵行列数
normDataSet = np.zeros(np.shape(dataSet))
#返回dataSet的行数
m = dataSet.shape[0]
#原始值减去最小值
normDataSet = dataSet - np.tile(minVals, (m, 1))
#除以最大和最小值的差,得到归一化数据
normDataSet = normDataSet / np.tile(ranges, (m, 1))
#返回归一化数据结果,数据范围,最小值
return normDataSet, ranges, minVals
"""
函数说明:分类器测试函数
Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
Modify:
2017-03-24
"""
def datingClassTest():
#打开的文件名
filename = "datingTestSet.txt"
#将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = file2matrix(filename)
#取所有数据的百分之十
hoRatio = 0.10
#数据归一化,返回归一化后的矩阵,数据范围,数据最小值
normMat, ranges, minVals = autoNorm(datingDataMat)
#获得normMat的行数
m = normMat.shape[0]
#百分之十的测试数据的个数
numTestVecs = int(m * hoRatio)
#分类错误计数
errorCount = 0.0
for i in range(numTestVecs):
#前numTestVecs个数据作为测试集,后m-numTestVecs个数据作为训练集
classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:],
datingLabels[numTestVecs:m], 4)
print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率:%f%%" %(errorCount/float(numTestVecs)*100))
"""
函数说明:main函数
Parameters:
无
Returns:
无
Modify:
2017-03-24
"""
if __name__ == '__main__':
datingClassTest()KNN算法不仅可以用于分类,还可以用于回归。通过找出该样本的K个最近距离,将这些K个样本的平均值赋给样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值,如权值与距离成反比。 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进