版权声明:欢迎转载与留言提问 https://blog.csdn.net/qq_25439417/article/details/82532097




在机器学习中:
归一化:
为什么归一化能提高梯度下降法求解最优解的速度?
假定为预测房价的例子,自变量为面积大小和房间数,因变量为房价。那么可以得到的公式为:
y=θ1x1+θ2x2y=θ1x1+θ2x2
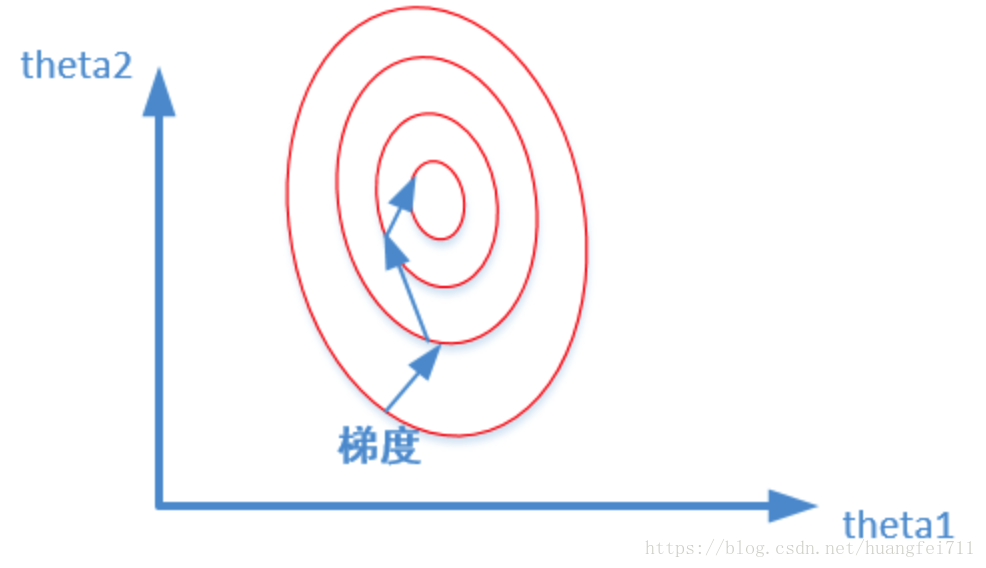
其中,x1x1代表房间数,θ1θ1代表x1x1变量前面的系数;x2x2代表面积,θ2θ2代表x2x2变量前面的系数。下面两张图(损失函数的等高线)代表数据是否归一化的最优解寻解过程:
未归一化:
归一化之后:
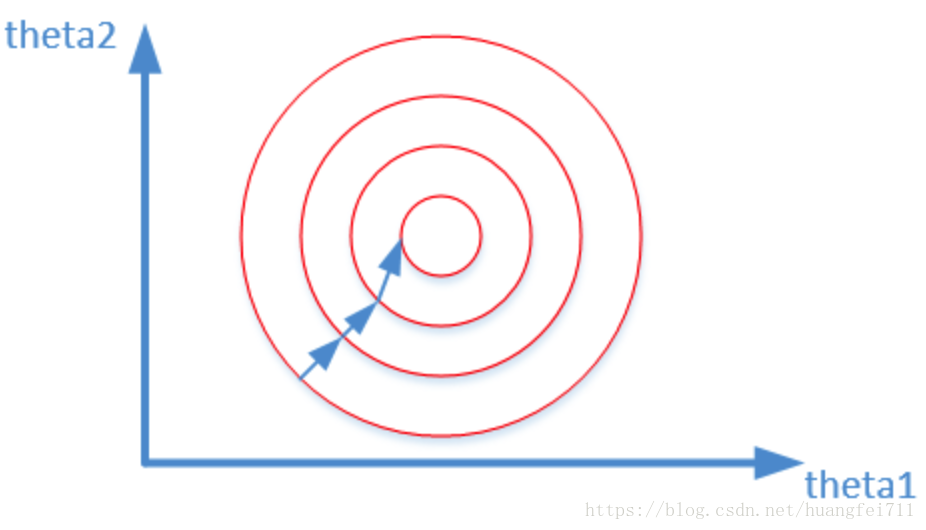
在寻找最优解的过程也就是在使得损失函数值最小的 θ1,θ2θ1,θ2。当数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。也就导致了等高面为长椭圆形,非常尖,因为变量前的系数大小相差很大,当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走)。而数据归一化后,损失函数变量前面的系数差距已不大,图像的等高面近似圆形,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
归一化有可能提高精度。加快收敛速度。
一些机器学习算法需要计算样本之间的距离(如欧氏距离),例如 KNN、K-means 等。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。

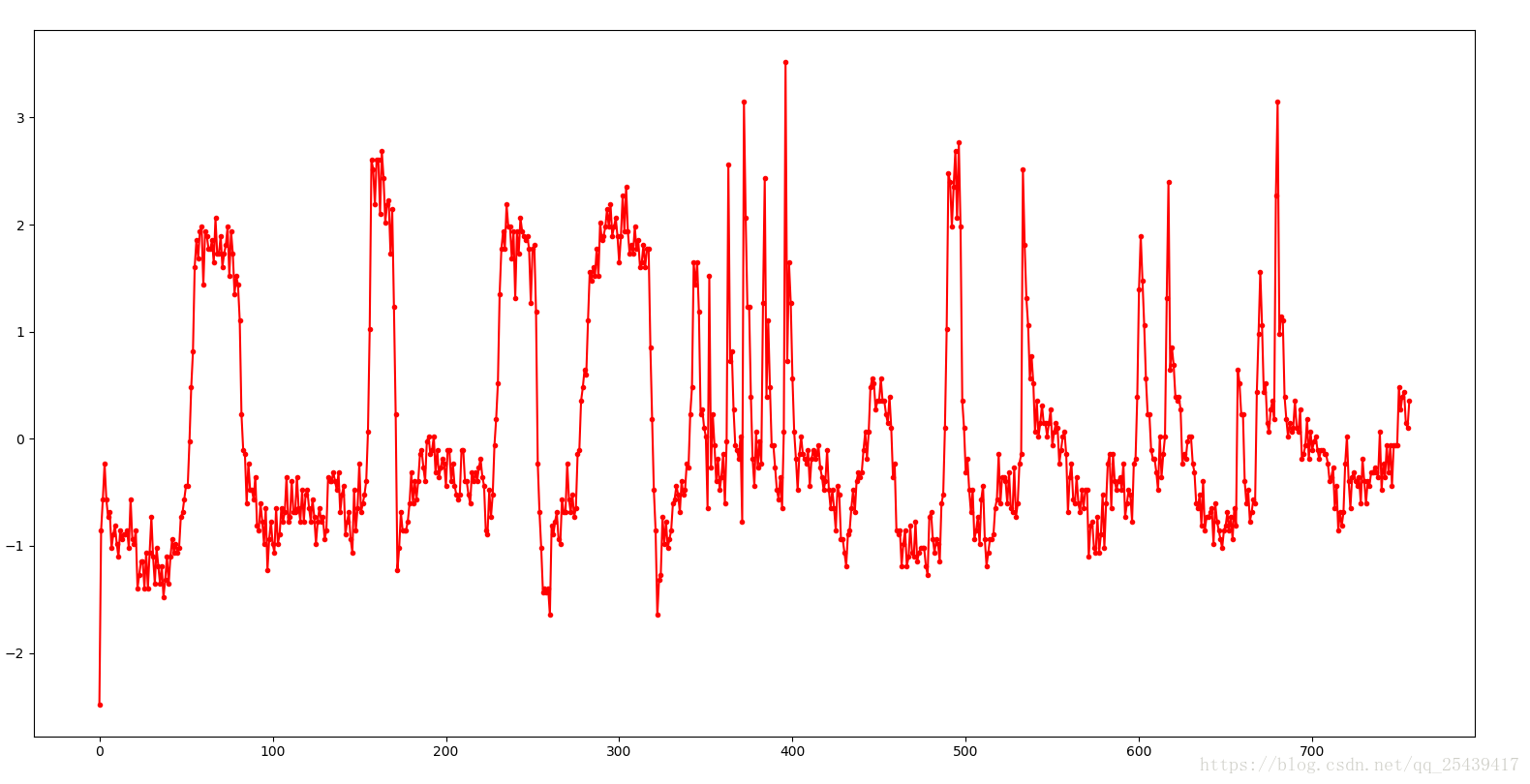
对之前眼部闭合数据进行了归一化,看到数据变落入了 更小的区间了 ,更利于后期数据分析了 了