1.什么是归一化,它与标准化的区别是什么
其他
2020-03-29 16:32:17
阅读次数: 0
不同点
| 对比点 |
归一化 |
标准化 |
| 概念 |
将数值规约到(0,1)或(-1,1)区间 |
将对应数据的分布规约在均值为0,标准差为1的分布上 |
| 侧重点 |
数值的归一,丢失数据的分布信息,对数据之间的距离没有得到较好的保留,但保留了权重 |
数据分布的归一,较好的保留了数据之间的分布,也即保留了样本之间的距离,但丢失了权值 |
| 形式 |
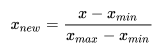 |
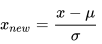 |
| 缺点 |
1.丢失样本间的距离信息;2.鲁棒性较差,当有新的样本加入时最大值与最小值很容易受异常点影响 |
1.丢失样本间的权重信息; |
| 适合场景 |
1.小数据/固定数据的使用;2.不涉及距离度量、协方差计算、数据不符合正态分布的时候;3.进行多指标综合评价的时候; |
1.在分类、聚类算法中,需要使用距离来度量相似性;2.有较好的鲁棒性,有产出取值范围的离散数据或对最大值最小值未知的情况下; |
| 缩放方式 |
先使用最小值平移,后使用最值差缩放 |
先使用均值u平移,之后用标准差进行缩放 |
| 目的 |
便于消除量纲,将各个指标的数据纳入到综合评价中; |
便于后续的梯度下降和激活函数对数据的处理。因为标准化后,数据以0为中心左右分布,而函数sigmoid,Tanh,Softmax等也都以0为中心左右分布; |
相同点及其联系
- 联系:归一化广义上是包含标准化的,以上主要是从狭义上区分两者。
- 本质上都是进行特征提取,方便最终数据的比较。
- 都是为了缩小范围,便于后续的数据处理。
- 作用:加快梯度下降,损失函数收敛; 提升模型精度; 防止梯度爆炸(消除因为输入差距过大而带来的输出差距过大,进而在反向传播的过程当中导致梯度过大,从而形成梯度爆炸)
发布了371 篇原创文章 ·
获赞 36 ·
访问量 6万+
转载自blog.csdn.net/strawqqhat/article/details/105143942
