Xception (Extreme Inception)
卷积层的学习方式
在一层卷积中我们尝试训练的是一个 3-D 的 kernel,kernel 有两个 spatial dimension,H 和 W,一个 channel dimension,也就是 C。
这样一来,一个 kernel 就需要同时学习 spatial correlations 和 cross-channel correlations,我把这里理解为,spatial correlations 学习的是某个特征在空间中的分布,cross-channel correlations 学习的是这些不同特征的组合方式。
Inception的理念
首先通过一系列的 1x1 卷积来学习 cross-channel correlations,同时将输入的维度降下来;再通过常规的 3x3 和 5x5 卷积来学习 spatial correlations。这样一来,两个卷积模块分工明确。Inception V3 中的 module 如下图。

Inception的假设
corss-channels correlations 和 spatial correlations 是分开学习的,而不是在某一个操作中共同学习的。
Inception到Xception的转变
首先考虑一个简版的 Inception module,拿掉所有的 pooling,并且只用一层 3x3 的卷积来提取 spatial correlations,如 Figure2。

▲ 简版Inception
可以将这些 1x1 的卷积用一个较大的 1x1 卷积来替代(也就是在 channel 上进行 triple),再在这个较大卷积产生的 feature map 上分出三个不重叠的部分,进行 separable convolution,如 Figure3。

这样一来就自然而然地引出:为什么不是分出多个不重叠的部分,而是分出三个部分来进行 separable convolution 呢?如果加强一下 Inception 的假设,假设 cross-channel correlations 和 spatial correlations 是完全无关的呢?
沿着上面的思路,一种极端的情况就是,在每个 channel 上进行 separable convolution,假设 1x1 卷积输出的 feature map 的 channel 有 128 个,那么极端版本的 Inception 就是在每个 channel 上进行 3x3 的卷积,而不是学习一个 3x3x128 的 kernel,取而代之的是学习 128 个 3x3 的kernel。
将 spatial correlations 的学习细化到每一个 channel,完全假设 spatial correlations 的学习与 cross-channel correlations 的学习无关,如 Figure4 所示。

Xception Architecture
一种 Xception module 的线性堆叠,并且使用了 residual connection,数据依次流过 Entry flow,Middle flow 和 Exit flow。

顺便写一点读 Xception 时的小发现,Xception 的实验有一部分是关于应不应该在 1x1 卷积后面只用激活层的讨论,实验结果是:如果在 1x1 卷积后不加以激活直接进行 depthwise separable convolution,无论是在收敛速度还是效果上都优于在 1x1 卷积后加以 ReLU 之类激活函数的做法。
这可能是因为,在对很浅的 feature(比如这里的 1-channel feature)进行激活会导致一定的信息损失,而对很深的 feature,比如 Inception module 提取出来的特征,进行激活是有益于特征的学习的,个人理解是这一部分特征中有大量冗余信息。
DeepLab V3+
论文里,作者直言不讳该框架参考了 spatial pyramid pooling (SPP) module 和 encoder-decoder 两种形式的分割框架。前一种就是 PSPNet 那一款,后一种更像是 SegNet 的做法。
ASPP 方法的优点是该种结构可以提取比较 dense 的特征,因为参考了不同尺度的 feature,并且 atrous convolution 的使用加强了提取 dense 特征的能力。但是在该种方法中由于 pooling 和有 stride 的 conv 的存在,使得分割目标的边界信息丢失严重。
Encoder-Decoder 方法的 decoder 中就可以起到修复尖锐物体边界的作用。
关于Encoder中卷积的改进
DeepLab V3+ 效仿了 Xception 中使用的 depthwise separable convolution,在 DeepLab V3 的结构中使用了 atrous depthwise separable convolution,降低了计算量的同时保持了相同(或更好)的效果。
Decoder的设计
Encoder 提取出的特征首先被 x4 上采样,称之为 F1;
Encoder 中提取出来的与 F1 同尺度的特征 F2' 先进行 1x1 卷积,降低通道数得到 F2,再进行 F1 和 F2 的 concatenation,得到 F3;
为什么要进行通道降维?因为在 encoder 中这些尺度的特征通常通道数有 256 或者 512 个,而 encoder 最后提取出来的特征通道数没有这么多,如果不进行降维就进行 concate 的话,无形之中加大了 F2' 的权重,加大了网络的训练难度。
对 F3 进行常规的 3x3 convolution 微调特征,最后直接 x4 upsample 得到分割结果。

还有值得关注的一点是,论文提出了 Xception 的改良版,可以用来做分割:

与 Xception 不同的几点是:
- 层数变深了
- 所有的最大池化都被替换成了 3x3 with stride 2 的 separable convolution
- 在每个 3x3 depthwise separable convolution 的后面加了 BN 和 ReLU
作者也把 Xception 当作了 Encoder,没有使用 DeepLab V3 中的 multi-grid 方法,得到的效果是所有模型中最好的。
在 PASCAL VOC 2012 验证集上的表现:

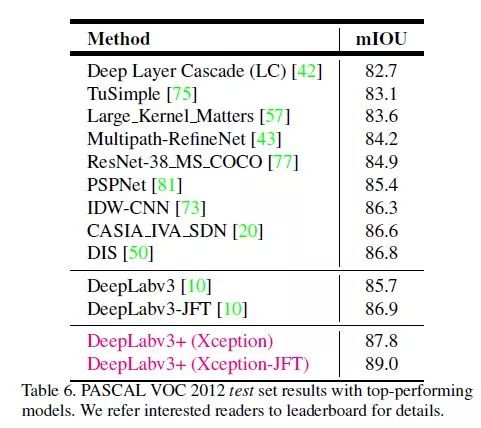
在 PASCAL VOC 2012 测试集上的表现:
一点总结
纵观语义分割的模型发展,从最初的 Encoder-Decoder 框架,到后来的 DeepLab、PSPNet 框架,到去年的 RefineNet 框架,每个框架都有其独到之处,但是 DeepLab V3+ 综合了 DeepLab、PSPNet 和 Encoder-Decoder,得到的效果是最好的,是思想的集大成者,或许在 RefineNet 类的框架和其他的框架之间也有可以探寻的结构。
相关链接
[1] Xception: Deep Learning with Depthwise Separable Convolutions
https://www.paperweekly.site/papers/1460
https://github.com/kwotsin/TensorFlow-Xception
[2] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
https://www.paperweekly.site/papers/1676
https://github.com/tensorflow/models/tree/master/research/deeplab
参考:http://www.sohu.com/a/226395640_500659