点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
近几年来,Text-to-Image 领域取得了巨大的进展,特别是在 AIGC(Artificial Intelligence Generated Content)的时代。随着 DALL-E 模型的兴起,学术界涌现出越来越多的 Text-to-Image 模型,例如 Imagen,Stable Diffusion,ControlNet 等模型。然而,尽管 Text-to-Image 领域发展迅速,现有模型在稳定地生成包含文本的图像方面仍面临一些挑战。
尝试过现有 sota 文生图模型可以发现,模型生成的文字部分基本上是不可读的,类似于乱码,这非常影响图像的整体美观度。

现有 sota 文生图模型生成的文本信息可读性较差
经过调研,学术界在这方面的研究较少。事实上,包含文本的图像在日常生活中十分常见,例如海报、书籍封面和路牌等。如果 AI 能够有效地生成这类图像,将有助于辅助设计师的工作,激发设计灵感,减轻设计负担。除此之外,用户可能只希望修改文生图模型结果的文字部分,保留其他非文本区域的结果。
因此,研究者希望设计一个全面的模型,既能直接由用户提供的 prompt 生成图像,也能接收用户给定的图像修改其中的文本。目前该研究工作已被NeurIPS 2023接收。

论文地址:https://arxiv.org/abs/2305.10855
项目地址:https://jingyechen.github.io/textdiffuser/
代码地址:https://github.com/microsoft/unilm/tree/master/textdiffuser
Demo地址:https://huggingface.co/spaces/microsoft/TextDiffuser
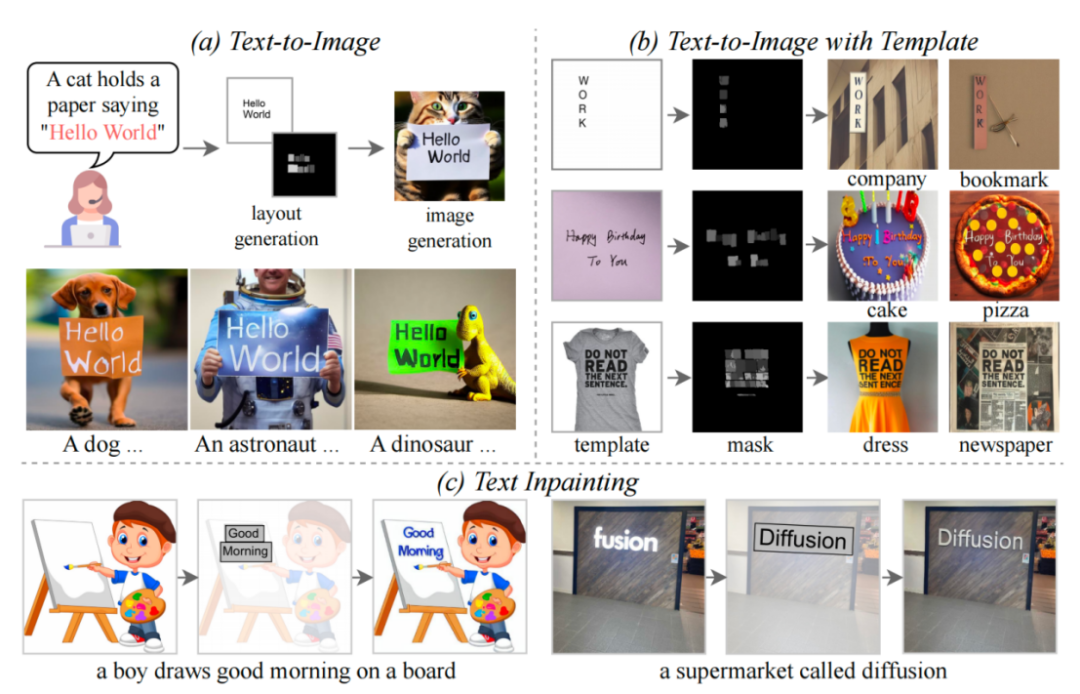
TextDiffuser 的三个功能
本文提出了 TextDiffuser 模型,该模型包含两个阶段,第一阶段生成 Layout,第二阶段生成图像。
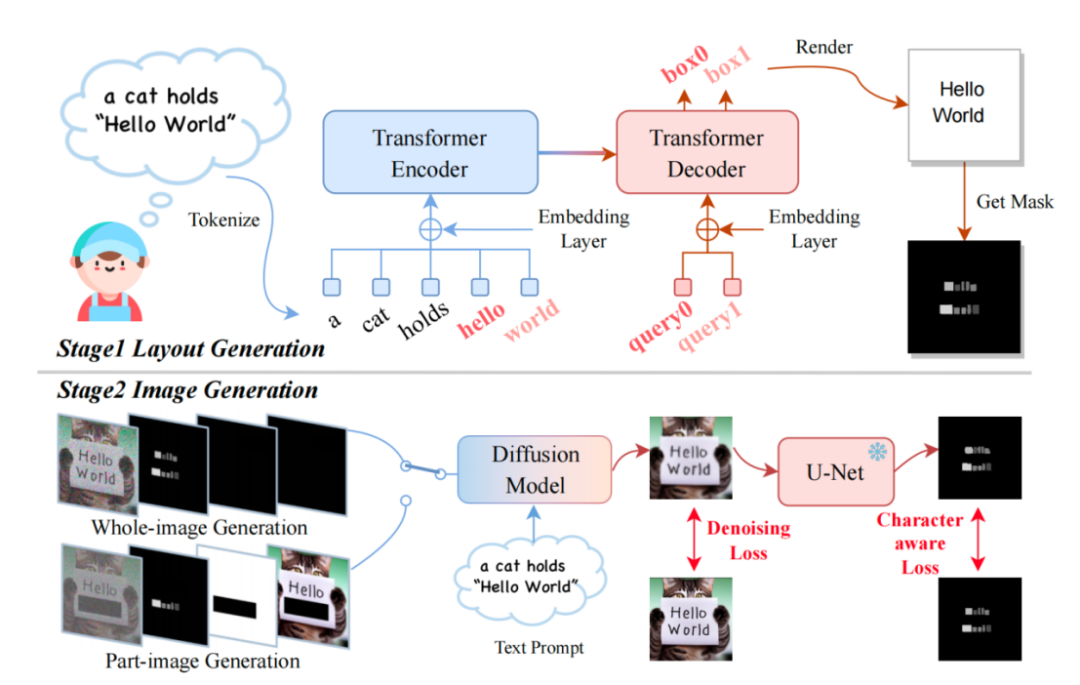
TextDiffuser框架图
模型接受一段文本 Prompt,然后根据 Prompt 中的关键词确定每个关键词的 Layout(也就是坐标框)。研究者采用了 Layout Transformer,使用编码器-解码器的形式自回归地输出关键词的坐标框,并用 Python 的 PILLOW 库渲染出文本。在这个过程中,还可以利用 Pillow 现成的 API 得到每个字符的坐标框,相当于得到了字符级别的 Box-level segmentation mask。基于此信息,研究者尝试微调 Stable Diffusion。
他们考虑了两种情况,一种是用户想直接生成整张图片(称为 Whole-Image Generation)。另一种情况是 Part-Image Generation,在论文中也称之为 Text-inpainting,指的是用户给定一张图像,需要修改图里的某些文本区域。
为了实现以上两种目的,研究者重新设计了输入的特征,维度由原先的 4 维变成了 17 维。其中包含 4 维加噪图像的特征,8 维字符信息,1 维图像掩码,还有 4 维未被 mask 图像的特征。如果是 Whole-image generation,研究者将 mask 的区域设为全图,反之,如果是 part-image generation,就只 mask 掉图像的一部分即可。扩散模型的训练过程类似于 LDM,有兴趣的伙伴可以参考原文方法部分的描述。
在 Inference 阶段,TextDiffuser 非常灵活,有三种使用方式:
根据用户给定的指令生成图像。并且,如果用户不大满意第一步 Layout Generation 生成的布局,用户可以更改坐标也可以更改文本的内容,这增加了模型的可控性。
直接从第二个阶段开始。根据模板图像生成最终结果,其中模板图像可以是印刷文本图像,手写文本图像,场景文本图像。研究者专门训练了一个字符集分割网络用于从模板图像中提取 Layout。
同样也是从第二个阶段开始,用户给定图像并指定需要修改的区域与文本内容。并且,这个操作可以多次进行,直到用户对生成的结果感到满意为止。

构造的 MARIO 数据
为了训练 TextDiffuser,研究者搜集了 1000 万张文本图像,如上图所示,包含三个子集:MARIO-LAION, MARIO-TMDB 与 MARIO-OpenLibrary。
研究者在筛选数据时考虑了若干方面:例如在图像经过 OCR 后,只保留文本数量为 [1,8] 的图像。他们筛掉了文本数量超过 8 的文本,因为这些文本往往包含大量密集文本,OCR 的结果一般不太准确,例如报纸或者复杂的设计图纸。除此之外,他们设置文本的区域大于 10%,设置这个规则是为了让文本区域在图像的比重不要太小。
在 MARIO-10M 数据集训练之后,研究者将 TextDiffuser 与现有其他方法做了定量与定性的对比。例如下图所示,在 Whole-Image Generation 任务中,本文的方法生成的图像具有更加清晰可读的文本,并且文本区域与背景区域融合程度较高。
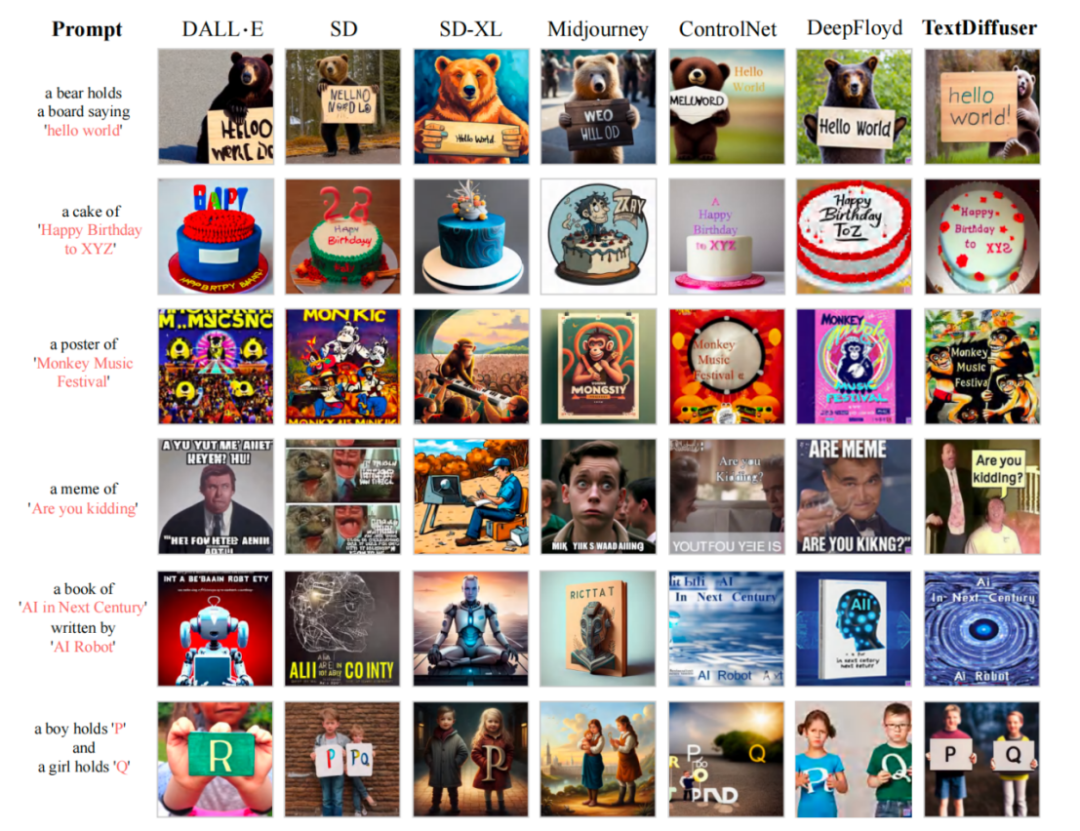
与现有工作比较文本渲染性能
研究者还做了定性的实验,如表 1 所示,评估指标有 FID,CLIPScore 与 OCR。尤其是 OCR 指标,本文方法相对于对比方法有很大的提升。
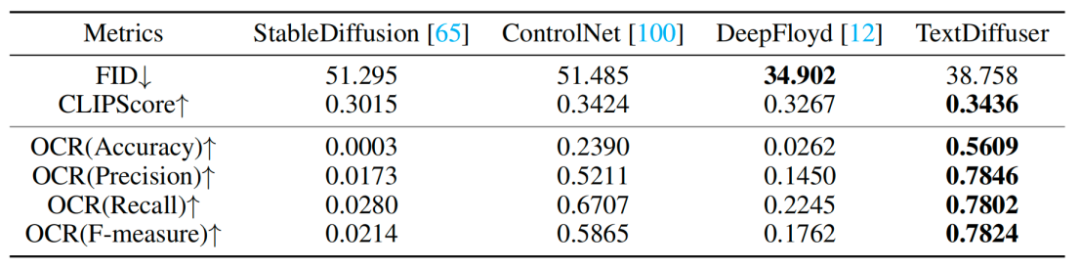
表1:定性实验
对于 Part-Image Generation 任务,研究者尝试着在给定的图像上增加或修改字符,实验结果表明 TextDiffuser 生成的结果很自然。

文本修复功能可视化
总的来说,本文提出的 TextDiffuser 模型在文本渲染领域取得了显著的进展,能够生成包含易读文本的高质量图像。未来,研究者将进一步提升 TextDiffuser 的效果。
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看