前言
本文基于chainer实现EfficientNet_V1网络结构,并基于torch的结构方式构建chainer版的,并计算EfficientNet_V1的参数量。
代码实现
注意此类就是EfficientNet_V1的实现过程,注意网络的前向传播过程中,分了训练以及测试。
训练过程中直接返回x,测试过程中会进入softmax得出概率
并且代码基于chainer实现drop_connect(droppath);SiLU激活函数
def drop_connect(inputs, p):
if not configuration.config.train:
return inputs
xp = backend.get_array_module(inputs)
keep_prob = 1 - p
batch_size = inputs.shape[0]
random_tensor = keep_prob
random_tensor += xp.random.uniform(size=[batch_size, 1, 1, 1])
binary_tensor = xp.floor(random_tensor)
output = (inputs / keep_prob) * binary_tensor
return output
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class SiLU(chainer.Chain):
def __init__(self):
super(SiLU, self).__init__()
def __call__(self, x):
out = x * F.sigmoid(x)
return out
class ConvBNActivation(chainer.Chain):
def __init__(self, in_planes: int, out_planes: int, kernel_size: int = 3, stride: int = 1, groups: int = 1, norm_layer = None, activation_layer = SiLU()):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = BatchNormalization
super(ConvBNActivation, self).__init__()
self.layers = []
self.layers += [('conv1',L.Convolution2D(in_channels=in_planes,out_channels=out_planes,ksize=kernel_size,stride=stride,pad=padding,groups=groups,nobias=True))]
self.layers += [('bn',norm_layer(out_planes))]
if activation_layer is not None:
self.layers += [('act',activation_layer)]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def __call__(self, x):
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x
class SqueezeExcitation(chainer.Chain):
def __init__(self, input_c: int, expand_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor
self.layers = []
self.layers += [('fc1',L.Convolution2D(in_channels=expand_c,out_channels=squeeze_c,ksize=1))]
self.layers += [('ac1',SiLU())]
self.layers += [('fc2',L.Convolution2D(squeeze_c, expand_c, 1))]
self.layers += [('_ac2',Sigmoid())]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
short_cut = x
x = F.average_pooling_2d(x, x.shape[2:], stride=1)
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x * short_cut
class InvertedResidualConfig:
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int, # 3 or 5
input_c: int,
out_c: int,
expanded_ratio: int, # 1 or 6
stride: int, # 1 or 2
use_se: bool, # True
drop_rate: float,
index: str, # 1a, 2a, 2b, ...
width_coefficient: float):
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c * expanded_ratio
self.out_c = self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels * width_coefficient, 8)
class InvertedResidual(chainer.Chain):
def __init__(self, cnf: InvertedResidualConfig, norm_layer):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
self.layers = []
activation_layer = SiLU() # alias Swish
# expand
if cnf.expanded_c != cnf.input_c:
self.layers += [('expand_conv',ConvBNActivation(cnf.input_c, cnf.expanded_c, kernel_size=1, norm_layer=norm_layer, activation_layer=activation_layer))]
# depthwise
self.layers += [('dwconv',ConvBNActivation(cnf.expanded_c, cnf.expanded_c, kernel_size=cnf.kernel, stride=cnf.stride, groups=cnf.expanded_c, norm_layer=norm_layer, activation_layer=activation_layer))]
if cnf.use_se:
self.layers += [('se',SqueezeExcitation(cnf.input_c, cnf.expanded_c))]
# project
self.layers += [('project_conv',ConvBNActivation(cnf.expanded_c, cnf.out_c, kernel_size=1, norm_layer=norm_layer, activation_layer=None))]
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = cnf.drop_rate
else:
self.dropout = None
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
short_cut = x
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
if self.dropout is not None:
x = drop_connect(x,self.dropout)
if self.use_res_connect:
x += short_cut
return x
class EfficientNet_V1(chainer.Chain):
cfgs={
'efficientnetv1_b0':{
'image_size':224,'width_coefficient':1.0, 'depth_coefficient':1.0, 'drop_connect_rate':0.2,'dropout_rate':0.2},
'efficientnetv1_b1':{
'image_size':240,'width_coefficient':1.0, 'depth_coefficient':1.1, 'drop_connect_rate':0.2,'dropout_rate':0.2},
'efficientnetv1_b2':{
'image_size':260,'width_coefficient':1.1, 'depth_coefficient':1.2, 'drop_connect_rate':0.2,'dropout_rate':0.3},
'efficientnetv1_b3':{
'image_size':300,'width_coefficient':1.2, 'depth_coefficient':1.4, 'drop_connect_rate':0.2,'dropout_rate':0.3},
'efficientnetv1_b4':{
'image_size':380,'width_coefficient':1.4, 'depth_coefficient':1.8, 'drop_connect_rate':0.2,'dropout_rate':0.4},
'efficientnetv1_b5':{
'image_size':456,'width_coefficient':1.6, 'depth_coefficient':2.2, 'drop_connect_rate':0.2,'dropout_rate':0.4},
'efficientnetv1_b6':{
'image_size':528,'width_coefficient':1.8, 'depth_coefficient':2.6, 'drop_connect_rate':0.2,'dropout_rate':0.5},
'efficientnetv1_b7':{
'image_size':600,'width_coefficient':2.0, 'depth_coefficient':3.1, 'drop_connect_rate':0.2,'dropout_rate':0.5}
}
def __init__(self,
model_name='efficientnetv1_b0',channels=3,
num_classes: int = 1000,batch_size=4,image_size=224,
block = None,
norm_layer = None,**kwargs
):
super(EfficientNet_V1, self).__init__()
self.model_name = model_name
self.image_size = image_size
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
default_cnf = [[3, 32, 16, 1, 1, True, self.cfgs[self.model_name]['drop_connect_rate'], 1],
[3, 16, 24, 6, 2, True, self.cfgs[self.model_name]['drop_connect_rate'], 2],
[5, 24, 40, 6, 2, True, self.cfgs[self.model_name]['drop_connect_rate'], 2],
[3, 40, 80, 6, 2, True, self.cfgs[self.model_name]['drop_connect_rate'], 3],
[5, 80, 112, 6, 1, True, self.cfgs[self.model_name]['drop_connect_rate'], 3],
[5, 112, 192, 6, 2, True, self.cfgs[self.model_name]['drop_connect_rate'], 4],
[3, 192, 320, 6, 1, True, self.cfgs[self.model_name]['drop_connect_rate'], 1]]
def round_repeats(repeats):
return int(math.ceil(self.cfgs[self.model_name]['depth_coefficient'] * repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(BatchNormalization, eps=1e-3)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_coefficient=self.cfgs[self.model_name]['width_coefficient'])
# build inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig, width_coefficient=self.cfgs[self.model_name]['width_coefficient'])
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf))
inverted_residual_setting = []
for stage, args in enumerate(default_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i > 0:
# strides equal 1 except first cnf
cnf[-3] = 1 # strides
cnf[1] = cnf[2] # input_channel equal output_channel
cnf[-1] = args[-2] * b / num_blocks # update dropout ratio
index = str(stage + 1) + chr(i + 97) # 1a, 2a, 2b, ...
inverted_residual_setting.append(bneck_conf(*cnf, index))
b += 1
# create layers
self.layers = []
# first conv
self.layers += [('stem_conv',ConvBNActivation(in_planes=channels, out_planes=adjust_channels(32), kernel_size=3, stride=2, norm_layer=norm_layer))]
output_size = int((self.image_size-3+2*((3-1)//2))/2+1)
# building inverted residual blocks
for cnf in inverted_residual_setting:
self.layers += [(cnf.index,block(cnf, norm_layer))]
output_size = math.ceil(output_size / cnf.stride)
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
self.layers += [('top',ConvBNActivation(in_planes=last_conv_input_c, out_planes=last_conv_output_c, kernel_size=1, norm_layer=norm_layer))]
output_size = int((output_size-1+2*((1-1)//2))/1+1)
self.layers += [('_avgpool',AveragePooling2D(ksize=output_size,stride=1,pad=0))]
self.layers += [('_reshape',Reshape((batch_size,last_conv_output_c)))]
if self.cfgs[self.model_name]['dropout_rate'] > 0:
self.layers += [("_dropout1",Dropout(self.cfgs[self.model_name]['dropout_rate']))]
self.layers += [('fc',L.Linear(last_conv_output_c, num_classes))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
for n, f in self.layers:
origin_size = x.shape
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
print(n,origin_size,x.shape)
if chainer.config.train:
return x
return F.softmax(x)
注意此类就是EfficientNet_V1的实现过程,注意网络的前向传播过程中,分了训练以及测试。
训练过程中直接返回x,测试过程中会进入softmax得出概率
调用方式
if __name__ == '__main__':
batch_size = 4
n_channels = 3
image_size = 224
num_classes = 123
model = EfficientNet_V1(num_classes=num_classes, channels=n_channels,image_size=image_size,batch_size=batch_size)
print("参数量",model.count_params())
x = np.random.rand(batch_size, n_channels, image_size, image_size).astype(np.float32)
t = np.random.randint(0, num_classes, size=(batch_size,)).astype(np.int32)
with chainer.using_config('train', True):
y1 = model(x)
loss1 = F.softmax_cross_entropy(y1, t)
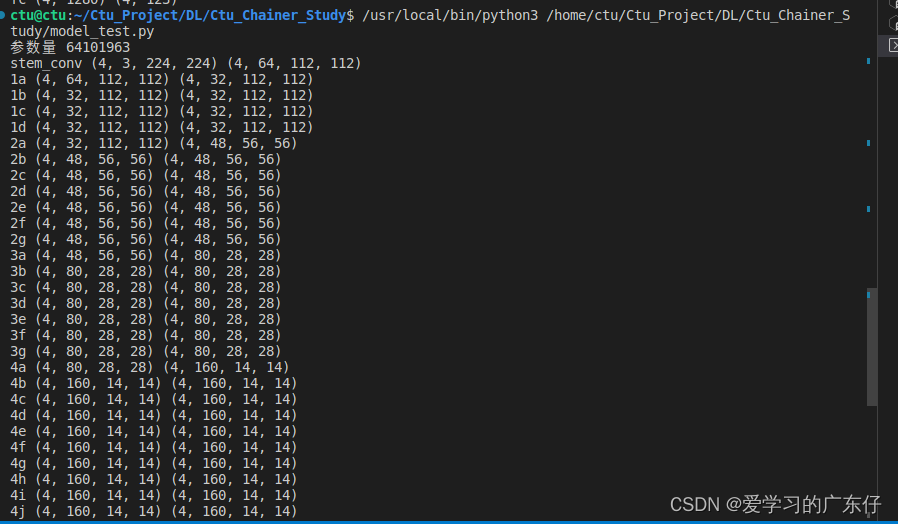
efficientnetv1_b0:一次前向传播参数量
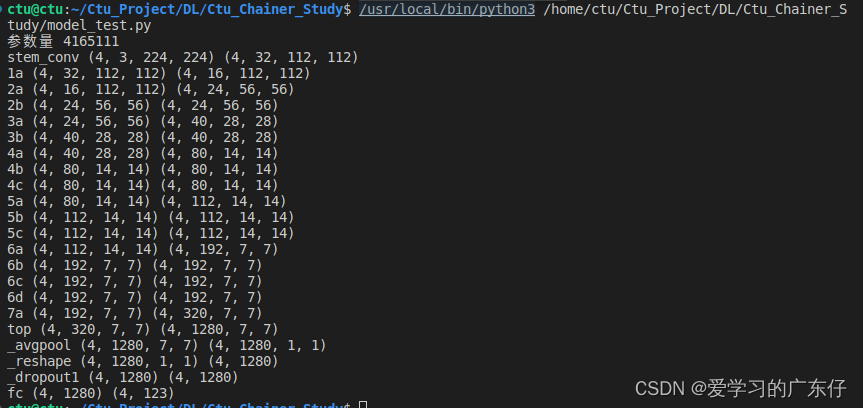
efficientnetv1_b7:一次前向传播参数量