五, 聚类模型的介绍与创建 (clustering Model)
什么是聚类分析:
聚类是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。在数据挖掘中,聚类也是很重要的一个概念。
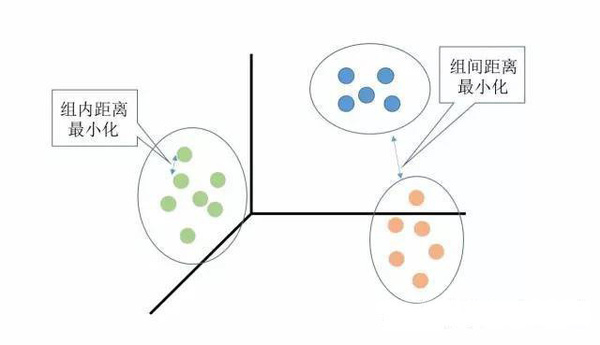
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化而组间距离最大化,如下图所示:
更多介绍请参考:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/machine-learning-initialize-model-clustering
https://baike.baidu.com/item/%E8%81%9A%E7%B1%BB%E5%88%86%E6%9E%90%E6%B3%95/4812805?fr=aladdin
下面介绍如何在Azure 的Machine Learning 中创建聚类模型:
- 按照之前介绍的方式,把Blood donation data.csv 上传到数据集里,把数据集控件拖到中间功能区域内进行操作。
- 之后再增加一个Select Columns in Dataset 控件,因为这里只对最近数据、鲜血频繁度、,所有做如下配置。
- 在Select Columns 选择 Recency,Frequency,Monetary和time
- 然后增加一个normalize data 控件,把一些不需要的数据过滤掉。
- Transformation method 的值选择ZScore。
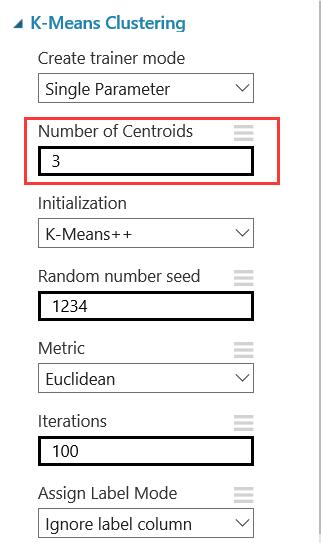
- 然后增加一个K-Means Clustering 控件,找出献血的群里是否相似。这里分了三个组,要分析三种不同类型的捐赠者。
- 增加train clustering model 这里要训练的是全部数据
- 然后运行。配置完成如下图。
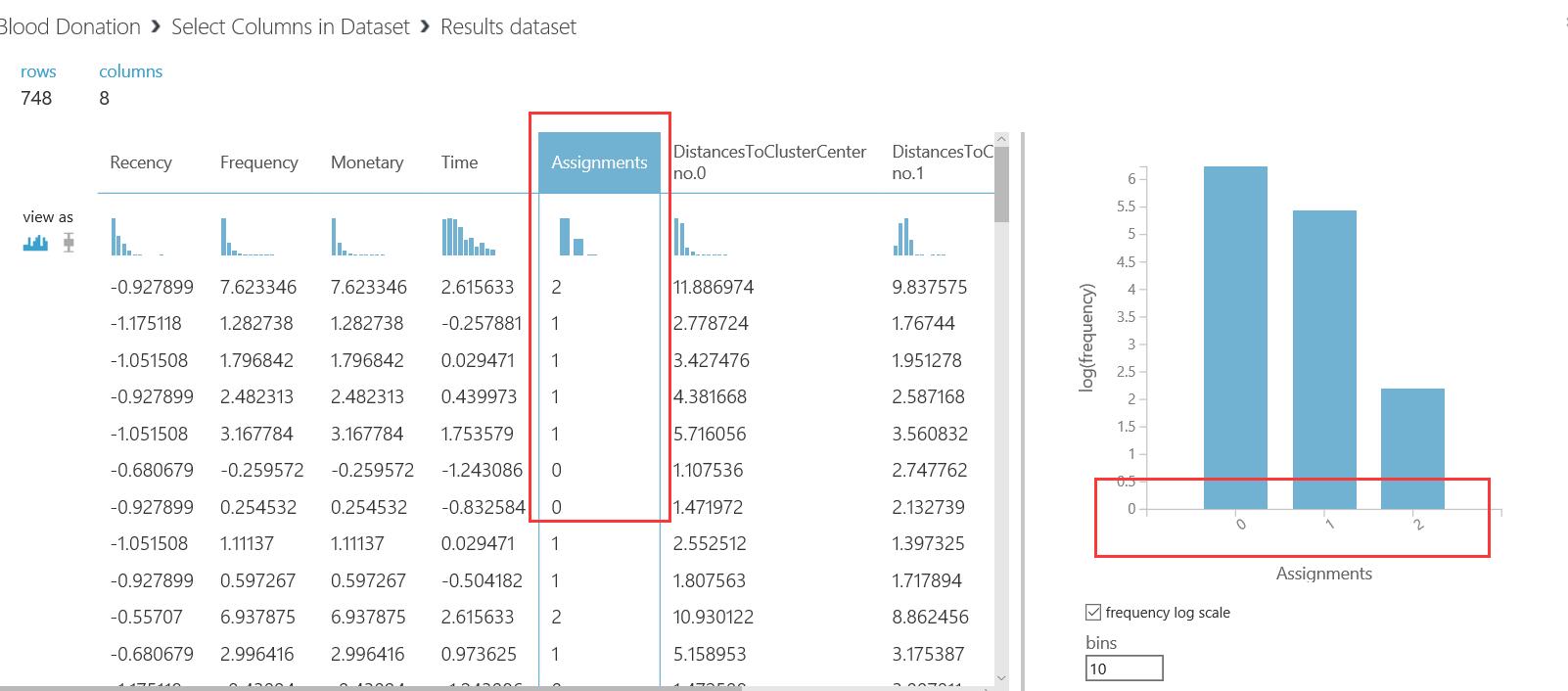
- 完成所有操作之后,看看执行结果。在Select Columns in Dataset 处单击,在下拉框里选择:Visualize
- 这是在K-Means Clustering 分的三个类别(0,1,3)
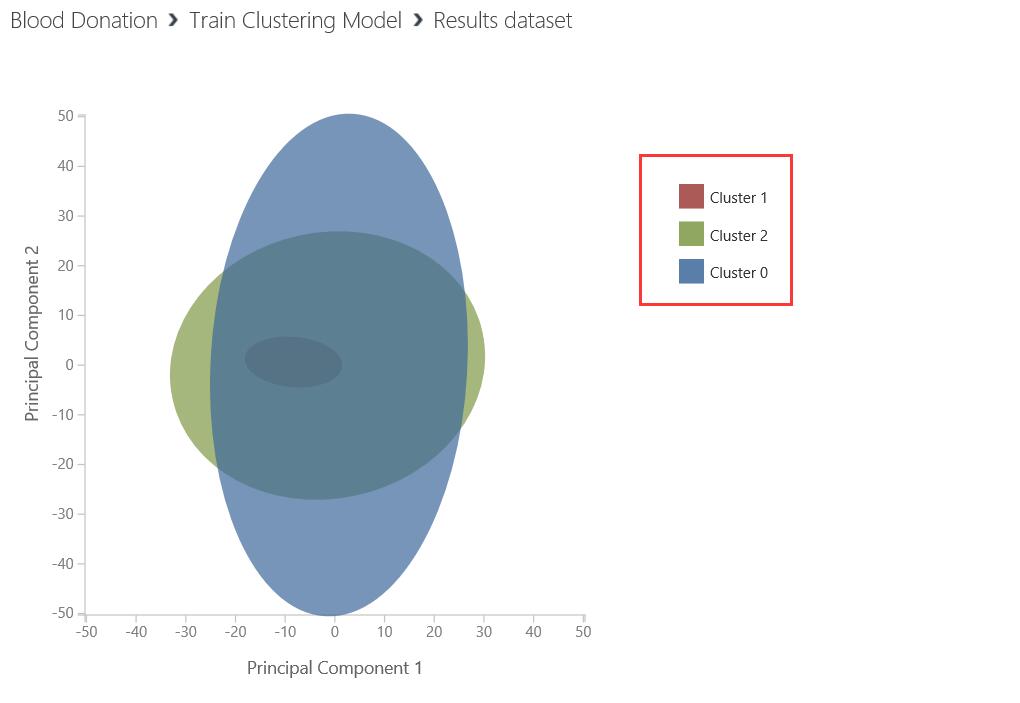
- Ok,再来看看训练后,想要得到聚类模块的输出。
- 从输出的结果来看,Cluster1 少,而且非常模糊。从这个结果来看,这些数据并不适合分成3个组。修改成2个组试试。所以继续调整K-Means Clustering 把Number of centroids 改成2个。
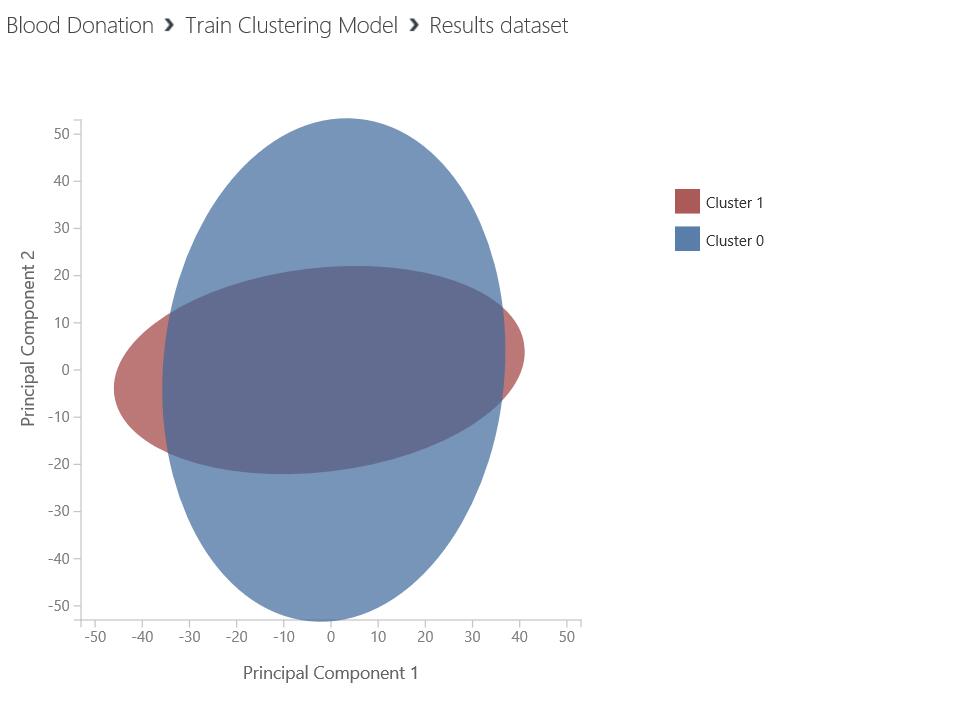
- 修改运行之后,再看结果
- 这样就看到了2个相交的椭圆,从结果来看,分成2个比较合适。鲜血人群可以分为两个类型。