论文:2307.Improving Latent Diffusion Models for High-Resolution Image Synthesis(改进的用于高分辨图像合成的隐变量扩模模型)

相关链接与解读
Code: https://github.com/Stability-AI/generative-models
官网模型说明: https://huggingface.co/stabilityai/
【SDXL0.9本地安装部署教程】 https://www.bilibili.com/video/BV1oV4y18791
【模型下载】https://pan.baidu.com/s/1wuOibq3dYW_e_LrIgnr2Jg?pwd=0710 提取码:0710
一、概述
SDXL, DeepFloyd IF, DALLE-2, Bing, Midjourney v5.2
从左到右每一列对应一个生成模型或软件

1.1 改善性能
1.SDXL在
用户偏好效果方面似乎大大**超过了v1.5和v2.1,甚至与midjourney v5.1并列!!
2.SDXL很大(2.6B Unet 参) --> 比以前的SD更慢+更多的VRAM
3.两个CLIP txt-encoders,而不是一个调节向量串联,拥有更好的文本图片对齐(更听话)
4.略有改进的VAE
5.处理低分辨率训练图像(以图像尺寸为条件的模型)、随机裁剪(以裁剪位置为条件的模型)和非方形图像(以长宽比为条件的模型)的更好方法
6.SDXL有一个可选的细化阶段,专门对高质量图像的少量噪声(当已经有很多信息时)进行去噪训练。
from:B站青龙圣者
1.2 具体开源模型
SD-XL 0.9-base:基础模型在具有1024x1024 分辨率的图像上,以多种宽高比进行训练。基础模型使用OpenCLIP-ViT/G和CLIP-ViT/L进行文本编码,而改进模型仅使用OpenCLIP模型。
SD-XL 0.9-refiner (細化器模型):改进模型经过训练,用于去噪高质量数据中的小噪声水平,因此不适用于作为文本到图像模型;相反,它只应用于图像到图像的模型。
二、原文简介
2.1 摘要
提出了SDXL (Stable Diffusion 的 XL码),一种用于文本到图像合成(text-to-image synthesis.)的潜在扩散模型(a latent diffusion model)。
与之前的稳定扩散版本相比,SDXL利用了一个三倍大的UNet骨干网络(s a three times larger UNet backbone),模型参数的增加主要来自于:
- 更多的注意力块(attention blocks)
- 使用了
第二个文本编码器(a second text encoder.),获得一个更大的交叉注意力上下文( cross-attention :指在多个输入之间共享注意力机制的一种技术), - 我们设计了多种新颖的条件方案(conditioning schemes),并在多个宽高比(aspect ratios) 上训练SDXL。
- 我们还引入了一种
改进模型(a refinement model),用于通过事后(post-hoc)图像到图像技术提高SDXL生成样本的视觉保真度。
证明了与之前的稳定扩散版本相比,SDXL显示出了显著改进的性能(drastically improved performance),并取得了与最先进的黑盒图像生成器相媲美的结果。为了推动开放研究并促进大型模型训练和评估的透明度,我们提供了代码和模型权重的访问权限。
2.2 模型结构
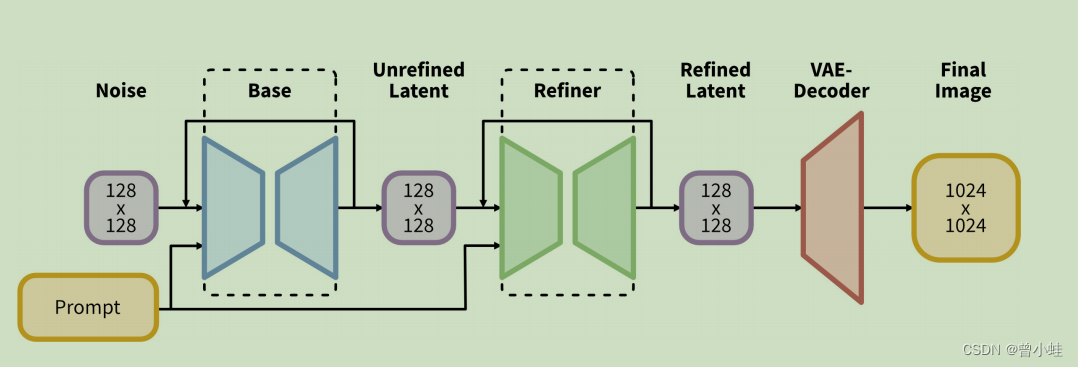
我们使用SDXL生成大小为128×128的初始潜变量。然后,我们利用专门的高分辨率改进模型,并在第一步生成的潜变量上应用SDEdit [28],使用相同的提示信息。SDXL和改进模型使用相同的自编码器。
2108.SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations: 使用随机微分方程进行引导式图像合成和编辑。
2.3 SDXL 与 SD1.5 / SD2.0的比较
模型组件和参数

相同提示的效果

三、未来的工作 (待优化的地方)
• 单阶段(Single stage):目前,我们使用两阶段的方法从SDXL生成最佳样本,并使用额外的改进模型。这导致需要将两个大型模型加载到内存中,限制了可访问性和采样速度。未来的工作应该探索提供同等或更好质量的单阶段方法的方式。
• 文本合成(Text synthesis):尽管规模和更大的文本编码器(OpenCLIP ViT-bigG [19])有助于改善文本渲染能力,但结合字节级标记器[52, 27]或将模型扩展到更大规模[53, 40]可能进一步改善文本合成。
• 架构(Architecture):在探索阶段,我们简要尝试了基于Transformer的架构,如UViT [16]和DiT [33],但未发现立即的好处。然而,我们保持乐观,认为经过仔细的超参数研究将最终实现对更大规模以Transformer为主导的架构的扩展。
•蒸馏(Distillation):尽管我们对原始的稳定扩散模型进行了显著的改进,但代价是推理成本的增加(包括VRAM和采样速度)。因此,未来的工作将专注于减少推理所需的计算量,并提高采样速度,例如通过引导式[29]、知识式[6, 22, 24]和渐进蒸馏[41, 2, 29]等方法。
• 我们的模型是根据 2006.Denoising Diffusion Probabilistic Models 中的离散时间公式进行训练的,并需要偏移噪声以获得美观的结果。Karras等人的EDM框架**2206.Elucidating the Design Space of Diffusion BasedGenerative Models**是未来模型训练的一个有希望的候选方案,因为它在连续时间下的表述允许增加采样的灵活性,并且不需要噪声调度校正。
重要英文解释:
Two-stage approach: 两阶段方法
Text synthesis: 文本合成
Architecture: 架构
Distillation: 蒸馏
Offset-noise: 偏移噪声
EDM-framework: EDM框架(等时离散化的公式)
Continuous time: 连续时间
Noise-schedule corrections: 噪声调度校正