WAL是write ahead log的缩写,顾名思义,也就是在执行真正的写操作之前先写一个日志,可以类比redo log,和它相对的是WBL(write behind log),这些日志都会严格保证持久化,以保证整个操作的一致性和可恢复性。
etcd中对WAL的定义都包含在wal目录中。
WAL定义
WAL定义在wal.go文件中
// WAL(write ahead log) is a logical representation of the stable storage.
// WAL is either in read mode or append mode but not both.
// A newly created WAL is in append mode, and ready for appending records.
// A just opened WAL is in read mode, and ready for reading records.
// The WAL will be ready for appending after reading out all the previous records.
type WAL struct {
dir string // the living directory of the underlay files
// dirFile is a fd for the wal directory for syncing on Rename
dirFile *os.File
metadata []byte // metadata recorded at the head of each WAL
state raftpb.HardState // hardstate recorded at the head of WAL
start walpb.Snapshot // snapshot to start reading 从快照确定的位置之后开始读
decoder *decoder // decoder to decode records
readClose func() error // closer for decode reader
mu sync.Mutex
enti uint64 // index of the last entry saved to the wal
encoder *encoder // encoder to encode records
locks []*fileutil.LockedFile // the locked files the WAL holds (the name is increasing)
fp *filePipeline // 会预先创建一个锁定的文件
}WAL创建
WAL对外暴露的创建接口就是Create函数(位于wal.go中),完整定义如下:
// Create creates a WAL ready for appending records. The given metadata is
// recorded at the head of each WAL file, and can be retrieved(检索) with ReadAll.
func Create(dirpath string, metadata []byte) (*WAL, error) {
if Exist(dirpath) {
return nil, os.ErrExist
}
// keep temporary wal directory so WAL initialization appears atomic
// 先在.tmp临时文件上做修改,修改完之后可以直接执行rename,这样起到了原子修改文件的效果
tmpdirpath := filepath.Clean(dirpath) + ".tmp"
if fileutil.Exist(tmpdirpath) {
if err := os.RemoveAll(tmpdirpath); err != nil {
return nil, err
}
}
if err := fileutil.CreateDirAll(tmpdirpath); err != nil {
return nil, err
}
// dir/filename ,filename从walName获取 seq-index.wal
p := filepath.Join(tmpdirpath, walName(0, 0))
// 对文件上互斥锁
f, err := fileutil.LockFile(p, os.O_WRONLY|os.O_CREATE, fileutil.PrivateFileMode)
if err != nil {
return nil, err
}
// 定位到文件末尾
if _, err = f.Seek(0, io.SeekEnd); err != nil {
return nil, err
}
// 预分配文件,大小为SegmentSizeBytes(64MB)
if err = fileutil.Preallocate(f.File, SegmentSizeBytes, true); err != nil {
return nil, err
}
// 新建WAL结构
w := &WAL{
dir: dirpath,
metadata: metadata,// metadata 可为nil
}
// 在这个wal文件上创建一个encoder
w.encoder, err = newFileEncoder(f.File, 0)
if err != nil {
return nil, err
}
// 把这个上了互斥锁的文件加入到locks数组中
w.locks = append(w.locks, f)
if err = w.saveCrc(0); err != nil {
return nil, err
}
// 将metadataType类型的record记录在wal的header处
if err = w.encoder.encode(&walpb.Record{Type: metadataType, Data: metadata}); err != nil {
return nil, err
}
// 保存空的snapshot
if err = w.SaveSnapshot(walpb.Snapshot{}); err != nil {
return nil, err
}
// 重命名,之前以.tmp结尾的文件,初始化完成之后重命名,类似原子操作
if w, err = w.renameWal(tmpdirpath); err != nil {
return nil, err
}
// directory was renamed; sync parent dir to persist rename
pdir, perr := fileutil.OpenDir(filepath.Dir(w.dir))
if perr != nil {
return nil, perr
}
// 将上述的所有文件操作进行同步
if perr = fileutil.Fsync(pdir); perr != nil {
return nil, perr
}
// 关闭目录
if perr = pdir.Close(); err != nil {
return nil, perr
}
return w, nil
}WAL日志文件遵循一定的命名规则,由walName实现,格式为"序号--raft日志索引.wal"。
// 根据seq和index产生wal文件名
func walName(seq, index uint64) string {
return fmt.Sprintf("%016x-%016x.wal", seq, index)
}在创建的过程中,Create函数还向WAL日志中写入了两条数据,一条就是记录metadata,一条是记录snapshot,WAL中的数据都是以Record为单位保存的,结构定义如下:
// 存储在wal稳定存储中的消息一共有两种,这是第一种普通记录的格式
type Record struct {
Type int64 `protobuf:"varint,1,opt,name=type" json:"type"`
Crc uint32 `protobuf:"varint,2,opt,name=crc" json:"crc"`
Data []byte `protobuf:"bytes,3,opt,name=data" json:"data,omitempty"`
XXX_unrecognized []byte `json:"-"`
}其中Type字段表示该Record的类型,取值可以是以下几种:
const (
metadataType int64 = iota + 1
entryType
stateType
crcType
snapshotType
// warnSyncDuration is the amount of time allotted to an fsync before
// logging a warning
warnSyncDuration = time.Second
)对应于raft中的Snapshot(应用状态机的Snapshot),WAL中也会记录一些Snapshot的信息(但是它不会记录完整的应用状态机的Snapshot数据),WAL中的Snapshot格式定义如下:
// 存储在wal中的第二种Record消息,snapshot
type Snapshot struct {
Index uint64 `protobuf:"varint,1,opt,name=index" json:"index"`
Term uint64 `protobuf:"varint,2,opt,name=term" json:"term"`
XXX_unrecognized []byte `json:"-"`
}在保存Snapshot的(注意这里的Snapshot是WAL里的Record类型,不是raft中的应用状态机的Snapshot)SaveSnapshot函数中:
// 持久化walpb.Snapshot
func (w *WAL) SaveSnapshot(e walpb.Snapshot) error {
// pb序列化,此时的e可为空的
b := pbutil.MustMarshal(&e)
w.mu.Lock()
defer w.mu.Unlock()
// 创建snapshotType类型的record
rec := &walpb.Record{Type: snapshotType, Data: b}
// 持久化到wal中
if err := w.encoder.encode(rec); err != nil {
return err
}
// update enti only when snapshot is ahead of last index
if w.enti < e.Index {
// index of the last entry saved to the wal
// e.Index来自应用状态机的Index
w.enti = e.Index
}
// 同步刷新磁盘
return w.sync()
}一条Record需要先把序列化后才能持久化,这个是通过encode函数完成的(encoder.go),代码如下:
// 将Record序列化后持久化到WAL文件
func (e *encoder) encode(rec *walpb.Record) error {
e.mu.Lock()
defer e.mu.Unlock()
e.crc.Write(rec.Data)
// 生成数据的crc
rec.Crc = e.crc.Sum32()
var (
data []byte
err error
n int
)
if rec.Size() > len(e.buf) {
// 如果超过预分配的buf,就使用动态分配
data, err = rec.Marshal()
if err != nil {
return err
}
} else {
// 否则就使用与分配的buf
n, err = rec.MarshalTo(e.buf)
if err != nil {
return err
}
data = e.buf[:n]
}
lenField, padBytes := encodeFrameSize(len(data))
// 先写recode编码后的长度
if err = writeUint64(e.bw, lenField, e.uint64buf); err != nil {
return err
}
if padBytes != 0 {
// 如果有追加数据(对齐需求)
data = append(data, make([]byte, padBytes)...)
}
// 写recode内容
_, err = e.bw.Write(data)
return err
}从代码可以看到,一个Record被序列化之后(这里为JOSN格式),会以一个Frame的格式持久化。Frame首先是一个长度字段(encodeFrameSize完成,在encoder.go文件),64bit,其中MSB表示这个Frame是否有padding字节,接下来才是真正的序列化后的数据。
func encodeFrameSize(dataBytes int) (lenField uint64, padBytes int) {
lenField = uint64(dataBytes)
// force 8 byte alignment so length never gets a torn write
padBytes = (8 - (dataBytes % 8)) % 8
if padBytes != 0 {
// lenField的高56记录padding的长度
lenField |= uint64(0x80|padBytes) << 56 // 最高位为1用于表示含有padding,方便在decode的时候判断
}
return lenField, padBytes
}最终,下图展示了包含了两个WAL文件的示例图。
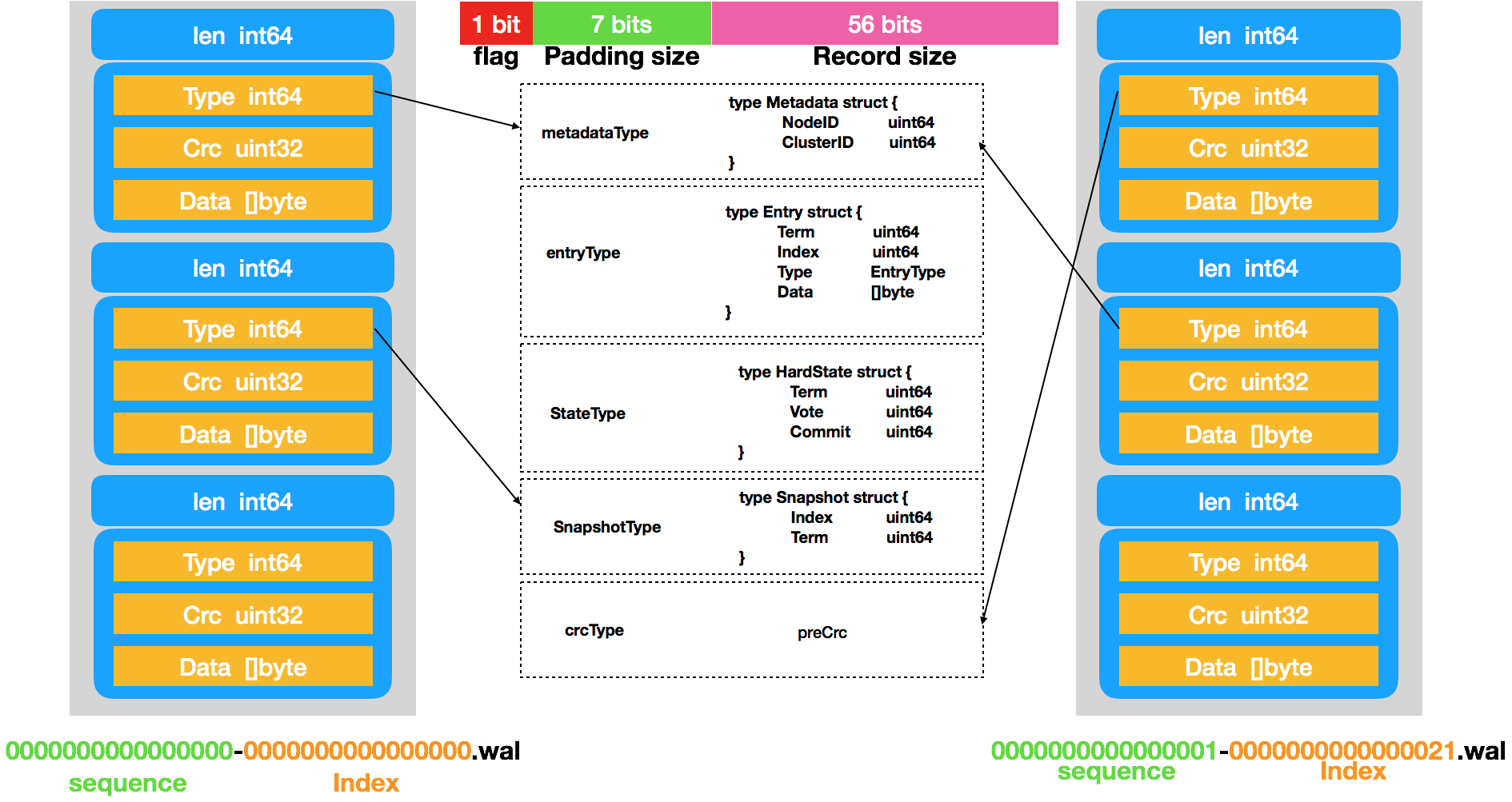
WAL存储
WAL主要是用来持久化存储日志的,当raft模块收到一个proposal时就会调用Save方法完成(定义在wal.go)持久化,这部分逻辑在后面的文章中会细化,本文关注Save本身,代码如下:
func (w *WAL) Save(st raftpb.HardState, ents []raftpb.Entry) error {
w.mu.Lock() // 上锁
defer w.mu.Unlock()
// short cut(捷径), do not call sync
// IsEmptyHardState returns true if the given HardState is empty.
if raft.IsEmptyHardState(st) && len(ents) == 0 {
return nil
}
// 是否需要同步刷新磁盘
mustSync := raft.MustSync(st, w.state, len(ents))
// TODO(xiangli): no more reference operator
// 保存所有日志项
for i := range ents {
if err := w.saveEntry(&ents[i]); err != nil {
return err
}
}
// 持久化HardState
if err := w.saveState(&st); err != nil {
return err
}
// 获取最后一个LockedFile的大小(已经使用的)
curOff, err := w.tail().Seek(0, io.SeekCurrent)
if err != nil {
return err
}
// 如果小于64MB
if curOff < SegmentSizeBytes {
if mustSync {
// 如果需要sync,就执行sync
return w.sync()
}
return nil
}
// 否则执行切割(也就是说明,WAL文件是可以超过64MB的)
return w.cut()
}MustSync用来判断当前的Save是否需要同步持久化,由于每台服务器上都必须无条件久化三个量:currentTerm、votedFor和log entries,因此只要log entries不为0,或者候选人id有变化或者是任期号有变化,都需要持久化。
// MustSync returns true if the hard state and count of Raft entries indicate
// that a synchronous write to persistent storage is required.
func MustSync(st, prevst pb.HardState, entsnum int) bool {
// Persistent state on all servers:
// (Updated on stable storage before responding to RPCs)
// currentTerm
// votedFor
// log entries[]
return entsnum != 0 || st.Vote != prevst.Vote || st.Term != prevst.Term
}
HardState表示服务器当前状态,定义在raft.pb.go,主要包含Term、Vote、Commit,具体意义可以参照Raft论文和下面的代码注释。
// the last known state
// Term:服务器最后一次知道的任期号
// Vote:当前获得选票的候选人的id
// Commit:已知的最大的已经被提交的日志条目的索引值(被多数派确认的)
type HardState struct {
Term uint64 `protobuf:"varint,1,opt,name=term" json:"term"`
Vote uint64 `protobuf:"varint,2,opt,name=vote" json:"vote"`
Commit uint64 `protobuf:"varint,3,opt,name=commit" json:"commit"`
XXX_unrecognized []byte `json:"-"`
}Entry就表示提交的日志条目了,定义在raft.pb.go中,成员如下:
// Term:该条日志对应的Term
// Index:日志的索引
// Type:日志的类型,普通日志和配置变更日志
// Data:日志内容
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
XXX_unrecognized []byte `json:"-"`
}
日志Entry的持久化由saveEntry完成,依然是先封装成一个Record,然后encode持久化。
func (w *WAL) saveEntry(e *raftpb.Entry) error {
// TODO: add MustMarshalTo to reduce one allocation.
b := pbutil.MustMarshal(e)
// 创建日志项类型的recode
rec := &walpb.Record{Type: entryType, Data: b}
if err := w.encoder.encode(rec); err != nil {
return err
}
// index of the last entry saved to the wal
w.enti = e.Index
return nil
}HardState的持久化由saveState完成,依然是先封装成一个Record,然后encode持久化。
func (w *WAL) saveState(s *raftpb.HardState) error {
if raft.IsEmptyHardState(*s) {
return nil
}
w.state = *s
b := pbutil.MustMarshal(s)
// 创建stateType类型的recode
rec := &walpb.Record{Type: stateType, Data: b}
return w.encoder.encode(rec)
}由前面的Save逻辑可以看出,当WAL文件超过一定大小时(默认为64MB),就需要进行切割,其逻辑在cut方法中实现(在wal.go中)
// cut closes current file written and creates a new one ready to append.
// cut first creates a temp wal file and writes necessary headers into it.
// Then cut atomically rename temp wal file to a wal file.
func (w *WAL) cut() error {
// close old wal file; truncate(截断) to avoid wasting space if an early cut
off, serr := w.tail().Seek(0, io.SeekCurrent)
if serr != nil {
return serr
}
// Truncate changes the size of the file. It does not change the I/O offset.
if err := w.tail().Truncate(off); err != nil {
return err
}
// 同步更新
if err := w.sync(); err != nil {
return err
}
// seq+1 ,index为最后一条日志的索引+1
fpath := filepath.Join(w.dir, walName(w.seq()+1, w.enti+1))
// create a temp wal file with name sequence + 1, or truncate the existing one
// 从filePipeline中获取一个预先打开的wal临时LockedFile
newTail, err := w.fp.Open()
if err != nil {
return err
}
// update writer and save the previous crc
// 将新文件添加到LockedFile数组
w.locks = append(w.locks, newTail)
// 计算当前文件的crc
prevCrc := w.encoder.crc.Sum32()
// 用新创建的文件创建encoder,并传入之前文件的crc,这样可以前后校验
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
// 保存crcType类型的recode
if err = w.saveCrc(prevCrc); err != nil {
return err
}
// metadata必须放在wal文件头
if err = w.encoder.encode(&walpb.Record{Type: metadataType, Data: w.metadata}); err != nil {
return err
}
// 保存HardState型recode
if err = w.saveState(&w.state); err != nil {
return err
}
// atomically move temp wal file to wal file
if err = w.sync(); err != nil {
return err
}
off, err = w.tail().Seek(0, io.SeekCurrent)
if err != nil {
return err
}
// 重命名
if err = os.Rename(newTail.Name(), fpath); err != nil {
return err
}
// 同步目录
if err = fileutil.Fsync(w.dirFile); err != nil {
return err
}
// reopen newTail with its new path so calls to Name() match the wal filename format
newTail.Close()
// 重新打开并上锁新的文件(重命名之后的)
if newTail, err = fileutil.LockFile(fpath, os.O_WRONLY, fileutil.PrivateFileMode); err != nil {
return err
}
if _, err = newTail.Seek(off, io.SeekStart); err != nil {
return err
}
// 重新添加到LockedFile数组(替换之前那个临时的)
w.locks[len(w.locks)-1] = newTail
// 获取上一个文件的crc
prevCrc = w.encoder.crc.Sum32()
// 用新文件重新创建encoder
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
plog.Infof("segmented wal file %v is created", fpath)
return nil
}WAL日志打开
// Open opens the WAL at the given snap.
// The snap SHOULD have been previously saved to the WAL, or the following
// ReadAll will fail.
// The returned WAL is ready to read and the first record will be the one after
// the given snap. The WAL cannot be appended to before reading out all of its
// previous records.
func Open(dirpath string, snap walpb.Snapshot) (*WAL, error) {
// 只打开最后一个seq小于snap中的index之后的所有wal文件(以写的方式打开)
w, err := openAtIndex(dirpath, snap, true)
if err != nil {
return nil, err
}
if w.dirFile, err = fileutil.OpenDir(w.dir); err != nil {
return nil, err
}
return w, nil
}
// OpenForRead only opens the wal files for read.
// Write on a read only wal panics.
func OpenForRead(dirpath string, snap walpb.Snapshot) (*WAL, error) {
return openAtIndex(dirpath, snap, false) // 只读打开
}
func openAtIndex(dirpath string, snap walpb.Snapshot, write bool) (*WAL, error) {
// 在指定目录下读取所有wal文件的名字
names, err := readWalNames(dirpath)
if err != nil {
return nil, err
}
// 返回name中最后一个小于或者等于snap.Index的索引
nameIndex, ok := searchIndex(names, snap.Index)
// 从nameIndex之后的文件名的seq必须是连续的
if !ok || !isValidSeq(names[nameIndex:]) {
return nil, ErrFileNotFound
}
// open the wal files
rcs := make([]io.ReadCloser, 0) // 封装了reader和closer
rs := make([]io.Reader, 0) // reader
ls := make([]*fileutil.LockedFile, 0)
// 循环打开nameIndex之后所有wal文件,并构造所有rcs、rs、ls
for _, name := range names[nameIndex:] {
// 组合wal文件路径
p := filepath.Join(dirpath, name)
if write {
// 以读写方式打开、并尝对文件加上排它锁,返回的l代表LockedFile
l, err := fileutil.TryLockFile(p, os.O_RDWR, fileutil.PrivateFileMode)
if err != nil {
closeAll(rcs...)
return nil, err // 有任何一个锁失败就整体失败
}
ls = append(ls, l) // 添加到LockedFile数组
rcs = append(rcs, l) // LockedFile肯定具有close和read方法
} else {// 以只读的方式打开(读的时候不需要枷锁),返回的rl为File
rf, err := os.OpenFile(p, os.O_RDONLY, fileutil.PrivateFileMode)
if err != nil {
closeAll(rcs...)
return nil, err
}
ls = append(ls, nil) // 五LockedFile
rcs = append(rcs, rf) // File肯定具有close和read方法
}
rs = append(rs, rcs[len(rcs)-1])
}// end for
// 函数式,循环调用每个文件的Close方法
closer := func() error { return closeAll(rcs...) }
// 根据以上信息创建一个已经继续可读的WAL
w := &WAL{
dir: dirpath,
start: snap,// 开始读取的位置
decoder: newDecoder(rs...),
readClose: closer,
locks: ls,
}
if write {// 如果是写的模式
// write reuses the file descriptors from read; don't close so
// WAL can append without dropping the file lock
w.readClose = nil
// Base returns the last element of path.
if _, _, err := parseWalName(filepath.Base(w.tail().Name())); err != nil {
closer()
return nil, err
}
// 会一直执行预分配,等待消费方消费
w.fp = newFilePipeline(w.dir, SegmentSizeBytes)
}
return w, nil
}WAL日志读取
// ReadAll reads out records of the current WAL.
// If opened in write mode, it must read out all records until EOF. Or an error
// will be returned.
// If opened in read mode, it will try to read all records if possible.
// If it cannot read out the expected snap, it will return ErrSnapshotNotFound.
// If loaded snap doesn't match with the expected one, it will return
// all the records and error ErrSnapshotMismatch.
// TODO: detect not-last-snap error.
// TODO: maybe loose the checking of match.
// After ReadAll, the WAL will be ready for appending new records.
func (w *WAL) ReadAll() (metadata []byte, state raftpb.HardState, ents []raftpb.Entry, err error) {
w.mu.Lock()
defer w.mu.Unlock()
rec := &walpb.Record{}
decoder := w.decoder
var match bool
for err = decoder.decode(rec); err == nil; err = decoder.decode(rec) {
// 根据recode的type进行不同处理
switch rec.Type {
case entryType:// 日志条目类型
// 反序列化
e := mustUnmarshalEntry(rec.Data)
// 如果这条日志条目的索引大于WAL应该读取的起始index
if e.Index > w.start.Index {
// 多减一就是为了append最后的e
ents = append(ents[:e.Index-w.start.Index-1], e)
}
// index of the last entry saved to the wal
w.enti = e.Index
case stateType:// HardState类型
state = mustUnmarshalState(rec.Data)
case metadataType:
if metadata != nil && !bytes.Equal(metadata, rec.Data) {
state.Reset()
return nil, state, nil, ErrMetadataConflict
}
metadata = rec.Data
case crcType:
crc := decoder.crc.Sum32()
// current crc of decoder must match the crc of the record.
// do no need to match 0 crc, since the decoder is a new one at this case.
if crc != 0 && rec.Validate(crc) != nil {
state.Reset() // 把sate设置为空
return nil, state, nil, ErrCRCMismatch
}
// 更新
decoder.updateCRC(rec.Crc)
case snapshotType:// walpb.Snapshot类型。记住这个不是状态机的快照,而是wal的快照
var snap walpb.Snapshot
pbutil.MustUnmarshal(&snap, rec.Data)
// start记录的是状态机的快照,如果和wal的快照index匹配
if snap.Index == w.start.Index {
if snap.Term != w.start.Term {
// 但是Term不匹配
state.Reset()
return nil, state, nil, ErrSnapshotMismatch
}
// index和Term都匹配,match为true
match = true
}
default:
state.Reset()
return nil, state, nil, fmt.Errorf("unexpected block type %d", rec.Type)
}
}
switch w.tail() {
case nil:
// We do not have to read out all entries in read mode.
// The last record maybe a partial written one, so
// ErrunexpectedEOF might be returned.
if err != io.EOF && err != io.ErrUnexpectedEOF {
state.Reset()
return nil, state, nil, err
}
default:
// We must read all of the entries if WAL is opened in write mode.
if err != io.EOF {
state.Reset()
return nil, state, nil, err
}
// decodeRecord() will return io.EOF if it detects a zero record,
// but this zero record may be followed by non-zero records from
// a torn write. Overwriting some of these non-zero records, but
// not all, will cause CRC errors on WAL open. Since the records
// were never fully synced to disk in the first place, it's safe
// to zero them out to avoid any CRC errors from new writes.
if _, err = w.tail().Seek(w.decoder.lastOffset(), io.SeekStart); err != nil {
return nil, state, nil, err
}
if err = fileutil.ZeroToEnd(w.tail().File); err != nil {
return nil, state, nil, err
}
}
err = nil
if !match {
// 没有匹配就说明没有snapshot
err = ErrSnapshotNotFound
}
// close decoder, disable reading
if w.readClose != nil {
w.readClose()
w.readClose = nil
}
// 置空
w.start = walpb.Snapshot{}
w.metadata = metadata
if w.tail() != nil {
// create encoder (chain crc with the decoder), enable appending
w.encoder, err = newFileEncoder(w.tail().File, w.decoder.lastCRC())
if err != nil {
return
}
}
w.decoder = nil
return metadata, state, ents, err
}
文件Pipeline
文件Pipeline的思想就是采用“饿汉式”,即提前创建一些文件备用,这样可以加快文件的创建速度。这个逻辑比较简单,此处不再赘述。
// filePipeline pipelines allocating disk space
type filePipeline struct {
// dir to put files
dir string
// size of files to make, in bytes
size int64
// count number of files generated
count int
filec chan *fileutil.LockedFile
errc chan error
donec chan struct{}
}
func newFilePipeline(dir string, fileSize int64) *filePipeline {
fp := &filePipeline{
dir: dir,
size: fileSize,
filec: make(chan *fileutil.LockedFile),
errc: make(chan error, 1),
donec: make(chan struct{}),
}
// 一直执行预分配
go fp.run()
return fp
}
// Open returns a fresh file for writing. Rename the file before calling
// Open again or there will be file collisions.
func (fp *filePipeline) Open() (f *fileutil.LockedFile, err error) {
select {
case f = <-fp.filec:
case err = <-fp.errc:
}
return f, err
}
func (fp *filePipeline) Close() error {
close(fp.donec)
return <-fp.errc
}
func (fp *filePipeline) alloc() (f *fileutil.LockedFile, err error) {
// count % 2 so this file isn't the same as the one last published 意思是 0.tmp 1.tpm 如此交替往复
fpath := filepath.Join(fp.dir, fmt.Sprintf("%d.tmp", fp.count%2))
if f, err = fileutil.LockFile(fpath, os.O_CREATE|os.O_WRONLY, fileutil.PrivateFileMode); err != nil {
return nil, err
}
// 预分配
if err = fileutil.Preallocate(f.File, fp.size, true); err != nil {
plog.Errorf("failed to allocate space when creating new wal file (%v)", err)
f.Close()
return nil, err
}
// 已经分配的文件个数
fp.count++
return f, nil
}
// goroutine
func (fp *filePipeline) run() {
defer close(fp.errc)
for {
// 预分配一个文件
f, err := fp.alloc()
if err != nil {
fp.errc <- err
return
}
select {
case fp.filec <- f: // 等待消费方从这个channel中取出这个预创建的被锁的文件
case <-fp.donec:
os.Remove(f.Name())
f.Close()
return
}
}
}本系列文章
2、etcd raft模块分析--raft snapshot
4、etcd raft模块分析--raft node
5、etcd raft模块分析--raft 协议
6、etcd raft模块分析--raft transport
7、etcd raft模块分析--raft storage
8、etcd raft模块分析--raft progress