上一篇介绍Etcd的Raft协议相关内容,本篇介绍Etcd另外一个核心内容-存储。
一、WAL文件
WAL的全称为Write Ahead Log(预写式日志),此文件格式采用grpc进行压缩保存在磁盘中(也用于传输数据)。1.1 基础格式

上面是一个Record结构,结构要求8字节对齐,一个wal文件包含多个Record字段。
字段名称 |
含义 |
占用大小 |
F |
是否存在补齐数据 0:表示没有补齐字段 1:表示存在补齐字段 |
1bit |
Pad |
表示补齐长度。在F为1时有效 |
7bit |
Length |
表示数据有效负载长度,不包括F、Pad自身长度、补齐字段。 |
56bit |
Type |
类型 |
int64,8字节,有符号 |
CRC |
校验 |
uint32,4字节,无符号 |
Data |
私有数据 |
Type取值如下,
metadataType int64 = iota + 1 entryType stateType crcType snapshotType
Etcd在定义这些数据结构,将Type,CRC,Data采用grpc方式对其进行数据压缩。数据结构定义在proto文件中,详细内容可参考:coreos/etcd/wal/walpb/record.proto。
1.2 文件格式
在上一小节中,介绍的数据格式,其实是内存中格式,当我们持久化到文件系统中,数据格式并不是上面介绍,而是grpc格式。对于grpc网上有很多介绍,大家可自行搜索,这里不在阐述。WAL文件以小端序方式存储,具体原因就不是很清楚了,可能是为了提升性能。
启动一个全新etcd,默认会在目录:/var/lib/etcd/default.etcd/member/wal/中生成一个.wal文件。首先从整体上来看一下文件结构,部分内容如下(已经格式化):
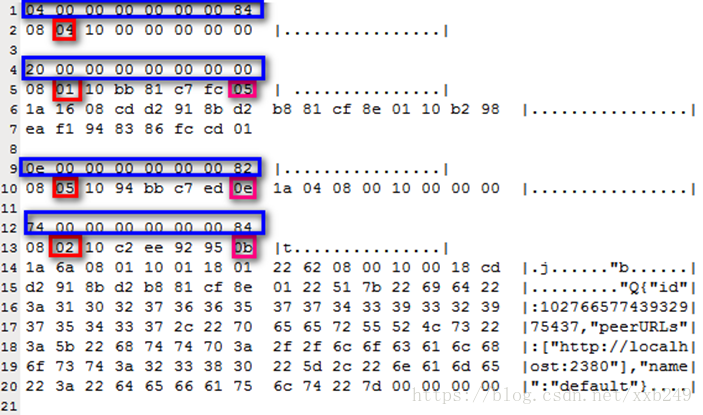
说明:
蓝色框:表示F、Pad以及Length
红色框:表示type
粉色框:当前类型type,最后一个数据字节。整个数据长度为:红框(不含)至粉色框(含)。
再次说明,wal文件内容是小端序存储方式。
上图中显示的4份数据,我们以第一份和最后一份数据进行说明
【举例1(以下为16进制)】:
04 00 00 00 00 00 00 84 转成大端序 84 00 00 00 00 00 0004,转成二进制,如下:

绿色框:代表F,1为存在补齐
黄色框:代表Pad,取值为4,说明存在补齐数据,长度为4
橘色框:代表Length,取值为4,说明数据长度是4
如上图所示,数据是8个字节,最后4个字节为补齐字段,因为数据字段要求是8字节对齐。
【备注】
我们的数据字段(playload)格式采用grpc的方式存储,这里简要说明一下,grpc是一个字节一个字节存储,所以在解析的时候,需要一个字节一个字节解析,不需要转换大小端。在grpc中,每个字节最高bit若为0表示数据结束,反之为1表示数据还没有结束,也就是说一个数据有效长度是7bit。
下面的解析规则,其实grpc的解析规则,具体解析原理,可自行查看grpc相关内容。
数据字段是按照Type、CRC、Data顺序进行数据压缩存储。
下面开始分解数据:
原始数据 |
原始数据二进制 |
操作 |
操作后二进制 |
含义 |
备注 |
0x08 |
0000 1000 |
右移3位 |
0000 0001 |
第一个字段,即代表Type |
表示后面的数据为Type |
0x04 |
0000 0100 |
和0x7F按位与(数据有效位是低7bit) |
0000 0100 |
4,表示crcType |
由于最高bit是0,表示此数据长度就是1字节 |
0x10 |
0001 0000 |
右移3位 |
0000 0010 |
表示第二字段,即CRC |
后面的数据是CRC字段 |
0x00 |
0000 0000 |
和0x7F按位与(数据有效位是低7bit) |
0000 0000 |
0,表示CRC为0 |
由于最高bit是0,表示此数据长度就是1字节 |
最后4个字节为补齐字段,不用解析 |
|||||
通过解析后,record各个数据填写如下:
record.Type = 4,record.Crc = 0,record.Data=[]
第二段数据,20 00 00 00 00 00 00 00(需要转成大端序),最高bit是0,说明不存在补齐,大家可自行解析。
【举例2】
现在分析最后一段数据,以便加深印象
74 00 00 00 0000 00 84 转成大端序,84 00 0000 00 00 00 74可知:存在补齐字段,长度为4,数据长度是0x74。
原始数据 |
原始数据二进制 |
操作 |
操作后二进制 |
含义 |
备注 |
0x08 |
0000 1000 |
(0x08&0x7F)>>3 |
0000 0001 |
1,第一个字段,即代表Type |
表示后面的数据为Type |
0x02 |
0000 0010 |
和0x7F按位与(数据有效位是低7bit) |
0000 0010 |
2,表示entryType |
由于最高bit是0,表示此数据长度就是1字节 |
|
|||||
0x10 |
0001 0000 |
(0x10&0x7F)>>3 |
0000 0010 |
表示第二字段,即CRC |
后面的数据是CRC字段 |
0xc2 |
1100 0010 |
和0x7F按位与(数据有效位是低7bit) |
0100 0010 |
0x42 |
由于最高bit是1,表示此数据未结束 |
0xee |
1110 1110 |
(0xee&0x7F)<<7 |
11 0111 0000 0000 |
0x3700 |
同上 |
0x92 |
1001 0010 |
(0x92 &0x7F)<<14 |
100 1000 0000 0000 0000 |
0x48000 |
同上 |
0x95 |
1001 0101 |
(0x95 &0x7F)<<21 |
10 1010 0000 0000 0000 0000 0000 |
0x2A00000 |
同上 |
0x0b |
0000 1011 |
(0x0b &0x7F)<<28 |
1011 0000 0000 0000 0000 0000 0000 0000 |
0xB0000000 |
由于最高bit是0,表示此段数据结束,即CRC字段结束 |
CRC=0x42&0x3700&0x48000&0x2A00000&0xB0000000=0xB2A4B742 |
|||||
0x1a |
0001 1010 |
(0x1a&0x7F)>>3 |
0000 0011 |
3,表示第三个字段,即data字段 |
表示后面的数据是data |
0x6a |
0110 1010 |
0x6a&0x7F |
0110 1010 |
106 表示后面数据长度是106 |
|
数据字段 |
|||||
私有数据为下图红色方框,私有数据的解析应该由上层应用负责,对于此处不负责解析且也不知道如何解析。

1.3 WAL相关
1)有两种模式,只读模式和追加模式(只写模式),这两种模式不能同时出现2)追加模式,代表只能在文件末端进行数据追加,不能修改之前数据
3)以上内容的编解码,可查看coreos/etcd/wal/decoder.go和coreos/etcd/wal/encoder.go
上述只是阐述了,文件解析过程,对于编码过程,与之相反。编解码代码比较简单,具体查看:coreos/etcd/wal/decoder.go和coreos/etcd/wal/encoder.go。这里不在介绍。
二、Snapshot
在/var/lib/etcd/default.etcd/member/目录中有两个子目录,snap和wal。那么为什么Etcd会有snap目录呢?主要有两个:
1)snapshot是wal快照,为了节约磁盘空间,当wal文件达到一定数据,就会对之前的数据进行压缩,形成快照。
2)snapshot另外一个原因,当新的节点加入到集群中,为了同步数据,就会把snapshot发送到新节点,这样能够节约传输数据(生成的快照文件比wal文件要小很多,5倍左右),使之尽快加入到集群中。
Snapshot格式为(内存中数据结构):

对应到snap文件,文件结构如下:
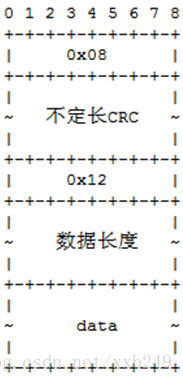
其中0x08表示第一个字段即CRC,0x12表示第二个字段即data。具体格式化代码,可参考etcd/snap/snappb/snap.pb.go。
三、静态存储Storage
所谓静态存储实际上是保存到磁盘中,Storage是对WAL和Snapshot的封装,由下数据结构可知:type storage struct {
*wal.WAL
*snap.Snapshotter
}
这部分内容比较简单,大家可自行阅读代码。
四、动态存储MemoryStorage
相对静态存储,来说保存在内存中数据就属于动态存储。这里着重介绍一下这个。// MemoryStorage implements the Storage interface backed by an
// in-memory array.
type MemoryStorage struct {
// Protects access to all fields. Most methods of MemoryStorage are
// run on the raft goroutine, but Append() is run on an application
// goroutine.
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
// ents[i] has raft log position i+snapshot.Metadata.Index
ents []pb.Entry
}
// NewMemoryStorage creates an empty MemoryStorage.
func NewMemoryStorage() *MemoryStorage {
return &MemoryStorage{
// When starting from scratch populate the list with a dummy entry at term zero.
ents: make([]pb.Entry, 1),
}
}
数据结构和初始化方法都比较简单,调用初始化方法,一共有三个地方,这里以startNode举例说明:
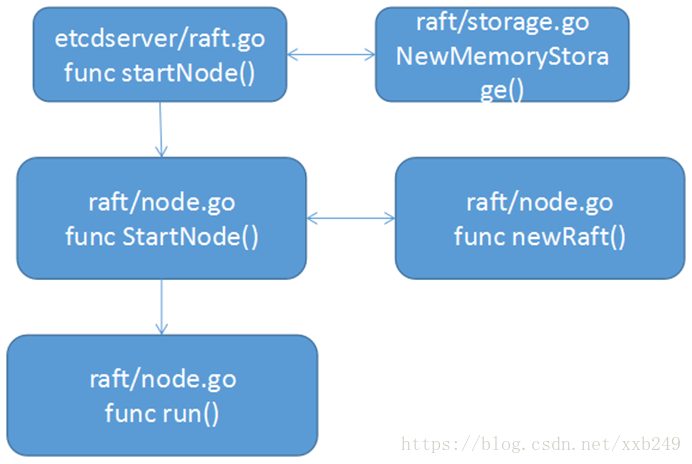
首先调用NewMemoryStorage进行初始化,然后在newRaft()中生成raftLog对象并且调用InitialState()进行状态初始化,最后在node中run方法接收数据。
本篇并没有介绍过多的代码,只是在文件结构上深入理解Etcd是如何存储数据的,下一篇以etcdctl命令行为入口,进行分析,etcd是如何一步一步存储。