文章目录
一、部署规划
1.1 版本说明
| 软硬件信息 | 参数 |
|---|---|
| 配置 | 2C2G |
| 操作系统版本 | CentOS Linux release 7.7.1908 (Core) |
| java版本 | java version “1.8.0_251” |
| Hadoop版本 | Hadoop 3.3.0 |
| spark版本 | spark 3.0.0 |
1.2 服务器规划
| 服务器 | IP | 角色 |
|---|---|---|
| node1 | 192.168.137.86 | zk、namenode、zkfc、datanode、nodemanager、journalnode、spark |
| node2 | 192.168.137.87 | zk、namenode、zkfc、datanode、nodemanager、resourcemanager、journalnode、spark |
| node3 | 192.168.137.88 | zk、datanode、nodemanager、resourcemanager、journalnode、spark |
二、spark部署
2.1 解压安装包并配置环境变量
tar xf spark-3.0.0-bin-hadoop3.2.tgz -C /usr/local/
mv /usr/local/spark-3.0.0-bin-hadoop3.2/ /usr/local/spark
chown -R hadoop.hadoop /usr/local/spark/
cat>>/etc/profile <<EOF
PATH=/usr/local/spark/bin:/usr/local/spark/sbin:$PATH
export PATH
EOF
source /etc/profile
2.2 修改核心配置文件
[hadoop@node1 conf]$ cd /usr/local/spark/conf/
[hadoop@node1 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@node1 conf]$ cp slaves.template slaves
2.2.1 配置 spark-env.sh
[hadoop@node1 conf]$ cat spark-env.sh
#!/usr/bin/env bash
export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64
#export SCALA_HOME=/usr/share/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"
2.2.2 配置 slaves
[hadoop@node1 conf]$ cat slaves
node1
node2
node3
2.2.3 配置 server.properties
[hadoop@node1 config]$ cat consumer.properties
zookeeper.connect=192.168.137.86:2181,192.168.137.87:2181,192.168.137.88:2181
2.2.4 将安装包分发给其他节点
scp -r /usr/loca/spark/* node2:/usr/local/spark
scp -r /usr/loca/spark/* node3:/usr/local/spark
2.3 启动spark
#master需要各节点手动启动
[hadoop@node1 ~]$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out
[hadoop@node1 ~]$ start-slaves.sh
node3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out
[hadoop@node1 sbin]$ jps
13938 NodeManager
25059 Worker
24886 Master
18808 NameNode
25224 Jps
1961 QuorumPeerMain
2426 DataNode
2827 DFSZKFailoverController
2669 JournalNode
[hadoop@node2 ~]$ jps
20784 Worker
2401 JournalNode
15553 NameNode
2275 DataNode
1958 QuorumPeerMain
20967 Jps
10600 ResourceManager
10683 NodeManager
2479 DFSZKFailoverController
20623 Master
[hadoop@node3 ~]$ jps
16208 Worker
1969 QuorumPeerMain
2354 JournalNode
2246 DataNode
6822 ResourceManager
6907 NodeManager
16061 Master
16383 Jps
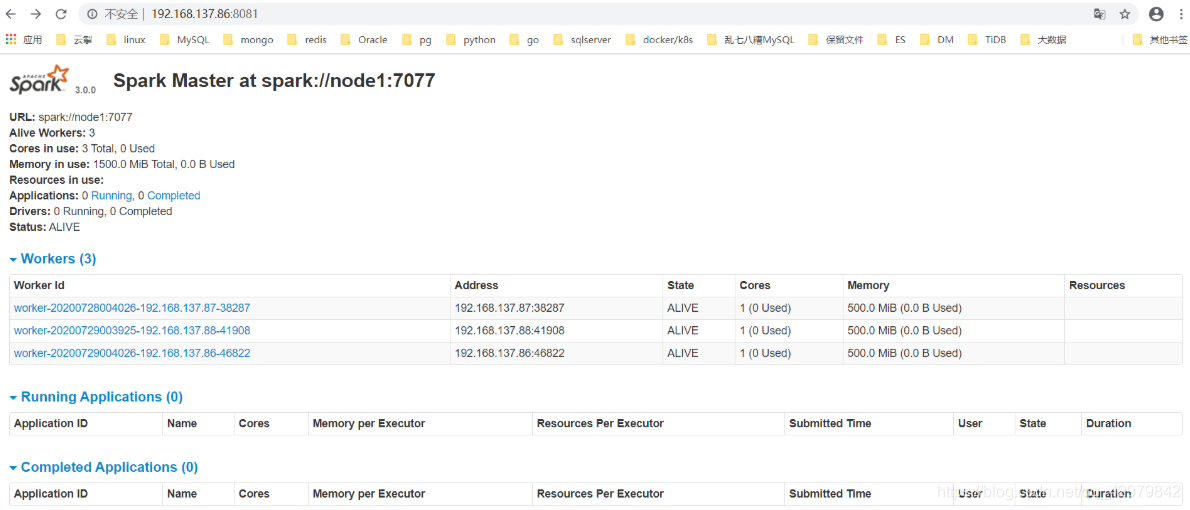
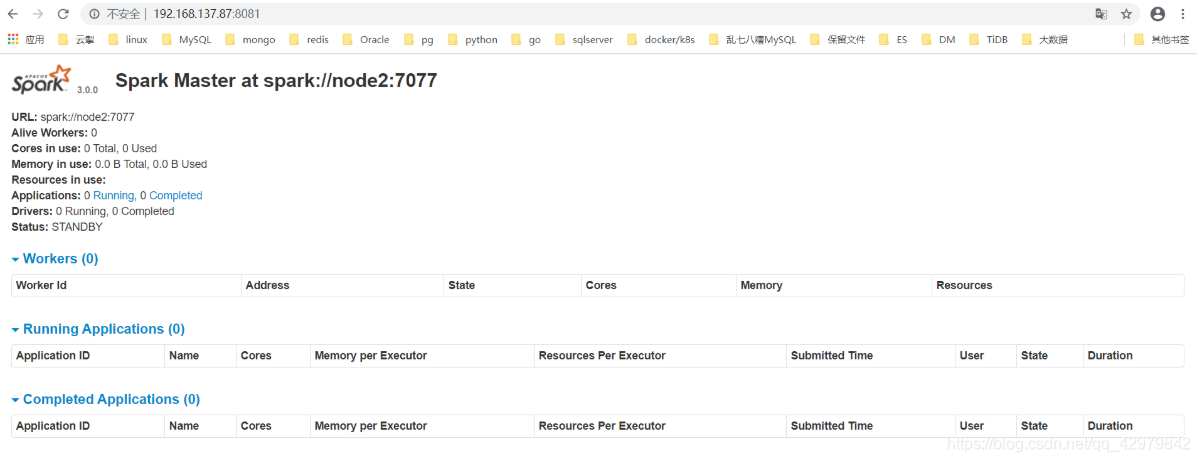
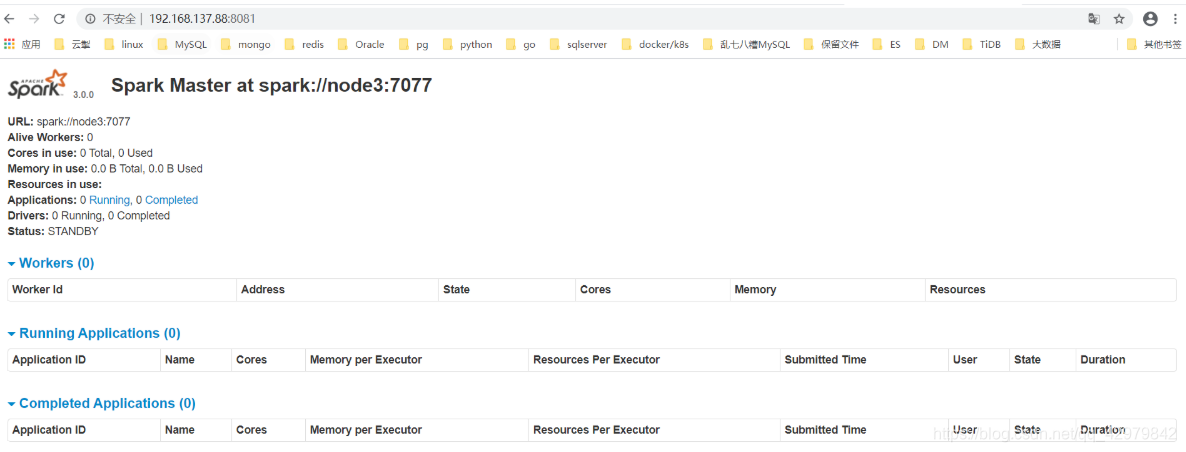
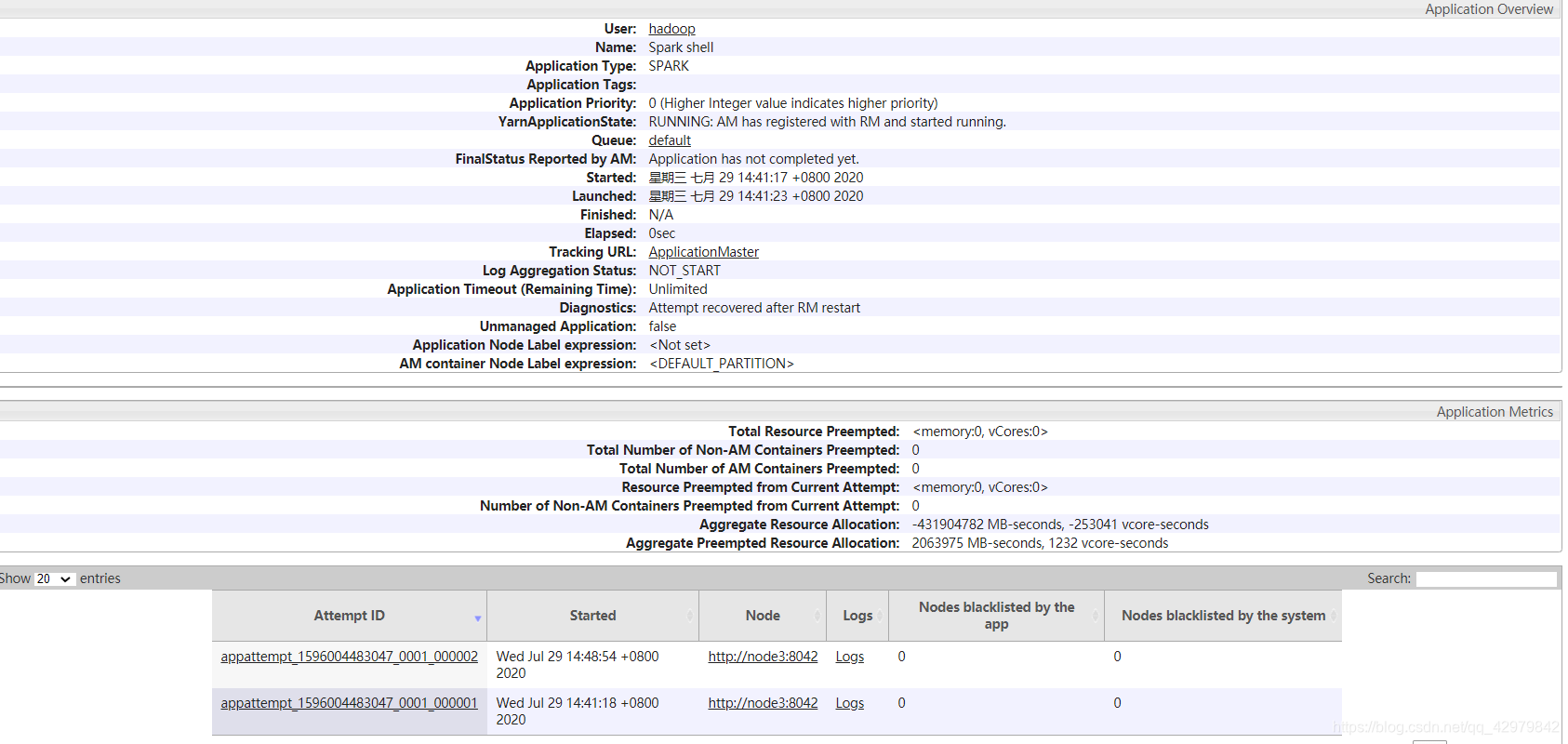
2.4 spark on yarn
[hadoop@node1 sbin]$ spark-shell --master yarn
2020-07-29 00:58:09,799 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2020-07-29 00:58:19,420 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = yarn, app id = application_1595954718957_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_251)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val array = Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd = sc.makeRDD(array)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:26
scala> rdd.count
res0: Long = 5