用Python分析:红葡萄酒质量分析(数据探索)
数据集:winemag-data_first150k.csv
先来导入数据
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.formula.api import ols, glm# 将数据集读入到pandas数据框中
wine = pd.read_csv('C:\\Machine-Learning-with-Python-master\\data\\winemag-data_first150k.csv', sep=',', header=0)
wine.columns = wine.columns.str.replace(' ', '_')
print(wine.head())
查看数据集的行和列信息
#查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(wine.shape[0],wine.shape[1])) wine.columns
解释一下列的含义:
| 列名 | 含义 |
| country | 葡萄酒来自的国家 |
| description | 描述葡萄酒的味道、气味、外观、感觉等 |
| designation | 酿酒厂内的葡萄园,酿造葡萄酒的葡萄来自葡萄园 |
| points | Wine Enthusiast 对葡萄酒的评分为 1-100 (尽管他们说他们只对评分>=80的葡萄酒发表评论) |
| price | 一瓶葡萄酒的成本 |
| province | 葡萄酒来自的产地 |
| region_1 | 葡萄酒来自的产地 |
| region_2 | 葡萄酒来自的产地 |
| variety | 用于酿造葡萄酒的葡萄种类 |
| winery | 生产葡萄酒的酿酒厂 |
显示数据集中的记录

检查数据集中列信息的空值

各个Column内容的描述性统计

关注 price 的描述性统计信息
wine['province'].value_counts().head(10).plot.bar()
从上图中可以看出California的产量远远高于世界其他省份的产量,我们可能会问,California葡萄酒占总葡萄酒的百分比是多少?这个柱形图告诉我们绝对值,但知道相对比例更有用。

从上图可以得知California出产的葡萄酒几乎占葡萄酒杂志评论的三分之一。
柱形图非常灵活:高度可以表示任何东西,只要它是一个数字。每个栏可以代表任何东西,只要它是一个分类。
上例的中省份分类是一个定类数据(没有内在固有大小或高低顺序),还有一种分类数据是定序数据,它相对于定类数据类型来说存在一种程度有序现象,例如下例中葡萄酒不同评分的评论数量。

从上图可看到,每个葡萄酒的总分都在80到100分之间。有20个分数值类别,柱状图刚好可以完全展示这些值。如果评分是0-100呢?恐怕无法完全展示每个类别的情况,这时,我们需要使用折线图。

使用面积图
当只绘制一个变量时,面积图和折线图之间的区别主要是可视化的。在这种情况下,它们可以互换使用。

每个样本都有得分从1到10的质量评分,以及若干理化检验的结果

直方图是用一系列等宽不等高的长方形来绘制,宽度表示数据的范围间隔,高度表示频数或者频率。
查看葡萄酒价格分布


从上图看价格主要分布在0~200,由于高位价格偏差,导致价格区间过大,看不出问题。
len(wine[wine['price'] > 200])/len(wine) 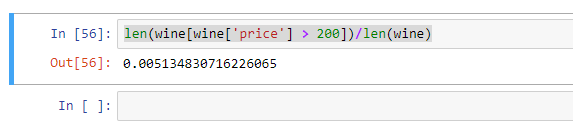
通过计算,发现价格在200以上的占比只有 0.005,可以忽略,处理一下数据偏差,重新查看price<200时的价格数量分布







这图似乎过于普通,图表标题也没有,x轴上标签字号也有点小,下面我们来改造一下。
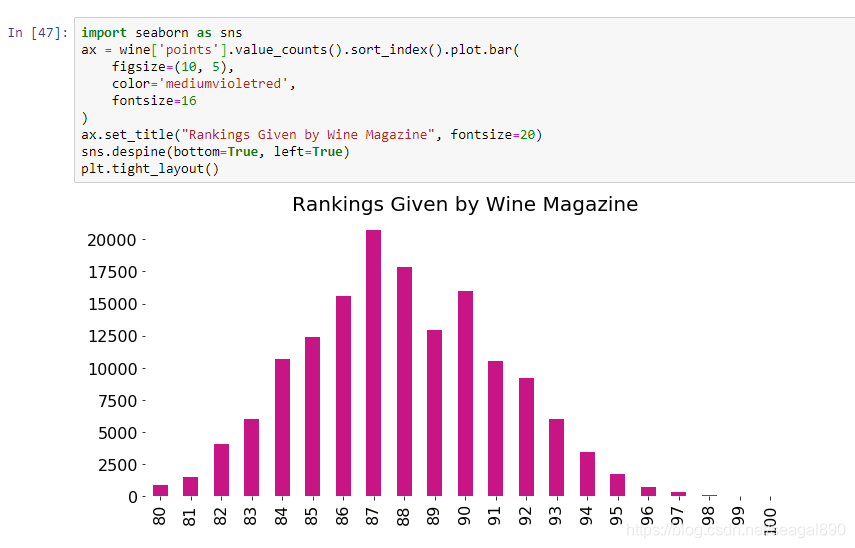
调整之后,比我们开始的时候更清晰,能更好地把分析结果传达给读者,下面逐一说明一下参数。
1.图表大小,使用figsize(width, height)参数 figsize=(10, 5)
2.修改颜色 ,使用 color 参数 color='mediumvioletred'取值表见文末链接
3.设置标签文字大小 ,使用fontsize参数 fontsize=16
4.设置标题和大小 plot.bar(title='xxx')
但是标题文字大小的设置,pandas没有给出设置参数。在底层,panda数据可视化工具是基与matplotlib的,这里可以借助matplotlib的 set_title函数实现
ax = xxx.plot.bar()
ax.set_title('title', fontsize=20)变量ax 是一个AxesSubplot对象。
5.去掉图表黑色边框sns.despine(bottom=True, left=True)
这里引入一个新的库seaborn ,后续会专门介绍。
6.图形完整显示,有时候图表标签会被遮挡plt.tight_layout()仅仅检查坐标轴标签、刻度标签以及标题的部分。
7.带中文的图表需要设置字体,本文中未使用,特单独说明
import matplotlib
font = {
'family': 'SimHei'
}
matplotlib.rc('font', **font)散点图是以一个变量为横坐标,另一个变量为纵坐标,利用散点(坐标点)的分布形态反映变量关系的一种图形。
下面查看一下葡萄酒价格和评分之间的关系:

看到图中全是点,基本看不出来葡萄酒价格和评分之间的关系。由于散点图不能有效的处理映射相同位置的点,为了更好的表示两者之间的关系,我们需要对数据进行抽样,抽取100个点重新进行展示:

从上图可以看出价格更高的葡萄酒在评论时会获得更高的评分。由此可见散点图对于相对较小的数据集和具有大量惟一值的变量最有效。
处理多重复数据点导致的覆盖绘制,除了抽样数据,还可以使用Hexplot。
六边形图将空间中的点聚合成六边形,然后根据六边形内部的值为这些六边形上色。
wine[wine['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15)
有测试price<200 的情况,发现图形集中在0-100价格区间(此处未展示图片),故调整过滤条件为price<100。
从上图中,看到了散点图未告知的信息,我们可以看到葡萄酒杂志上评论的葡萄酒的价格集中在87.5分左右,在20美元左右。
堆积图是一种把变量一个放在另一个上面的图表。
回顾一下上一篇文章中的单变量柱形图,这里可以简单使用一个stacked 参数,达到多个柱形的叠加。
原文是引入新的数据集,这里我们在源数据上进行一下处理,获得top5葡萄酒不同评价分数的次数数据:
#top5酒厂
winery = wine['winery'].value_counts().head(5)
wine_counts = pd.DataFrame({'points': range(80, 101)})
for name in winery.index:
winery_grouped = wine[wine['winery'] == name]
points_series = winery_grouped['points'].value_counts().sort_index()
df = pd.DataFrame({'points': points_series.index, name: list(points_series)})
wine_counts = wine_counts.merge(df, on='points',how='left').fillna(0)
wine_counts.set_index('points', inplace=True)wine_counts.plot.bar(stacked=True)
堆积条形图具有单变量条形图的优点和缺点。它们最适用于定类数据或少量定序数据。
另一个简单的例子是堆积面积图。
wine_counts.plot.area()
与单变量面积图一样,多变量面积适用于展示定类数据或区间数据。
堆积图在视觉上非常漂亮。但是它们有两个主要局限性。
第一个局限性: 堆积图的第二个变量必须是一个可能值数量非常有限的变量。8有时被称为建议的上限。有许多数据集字段不符合这个准则,需要进一步进行数据处理。
第二个局限性:可读性差,难以区分具体的值。例如,看上面的图,你能告诉我在得分值为87.5的时候,哪一种葡萄酒得分更高:Testarossa(橙色),williams(蓝色),还是DFJ(绿色)? 这真的很难讲!
Bivariate line chart 多变量折线图
wine_counts.plot.line()
这种方式使用折线图弥补了堆积图可读性的局限。在这个图表中,我们可以很容易地回答上一个例子中的问题:分值为87.5的时候,哪一种葡萄酒得分更高?我们可以看到Columbia Crest最高。
