文章目录
1.RNN的结构
- 1.1many-to-many 结构
- 1.2 many-to-one 结构
2. Encoder-Decoder
3. Attention 机制
参考文献
1.RNN的结构
1.1 many-to-many 结构
RNN 有多种结构如下图所示:
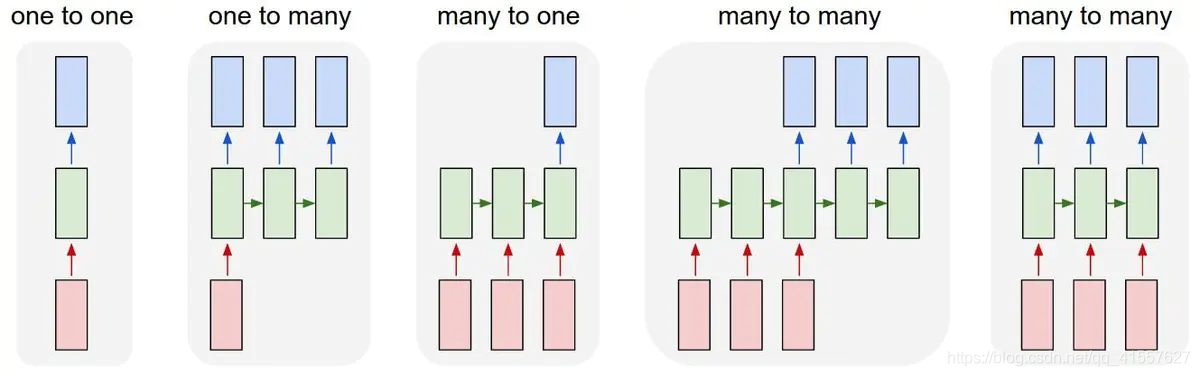
1.1many-to-many 结构
多对多是 RNN 中最经典的结构,其输入、输出都是等长的序列数据。假设输入 X=(x1, x2, x3, xi),每个 xi 为一个单词的词向量

RNN 中引入了隐藏层(hidden state),隐藏层的作用是用来对序列数据提取特征,接着再转换为输出。如下图所示,h1 的计算是由输入是 x1 和 h0,经过变换 Ux1 + Wh0 + b 和 激活函数 f 得到输出 h1。
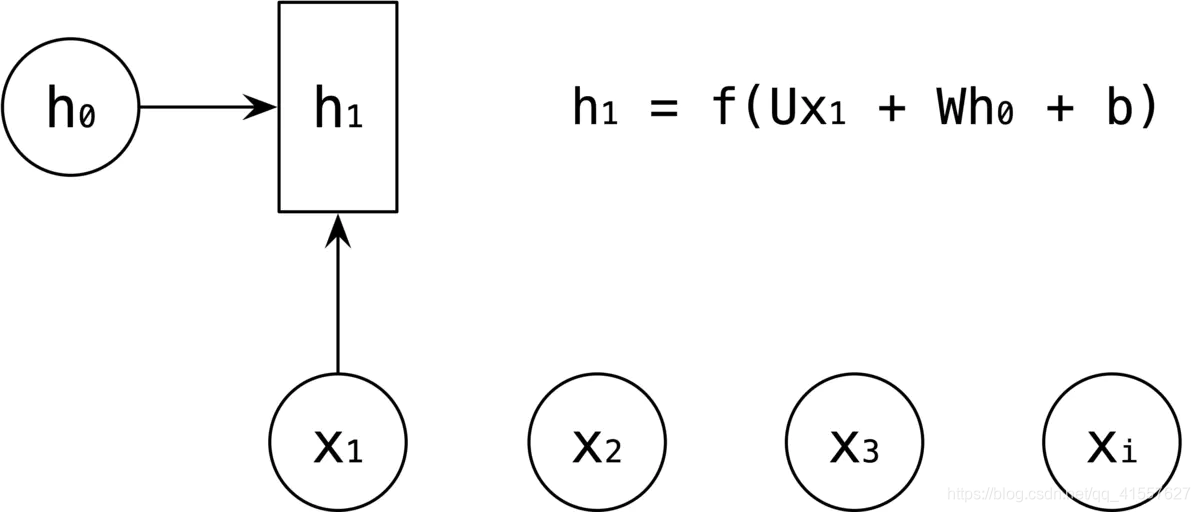
h2 的计算和 h1 类似,在计算时,每一步使用的参数 U、W、b 都是一样的,也就是说每个步骤的参数都是共享的,这就 RNN 的一个重要特点,参数共享。
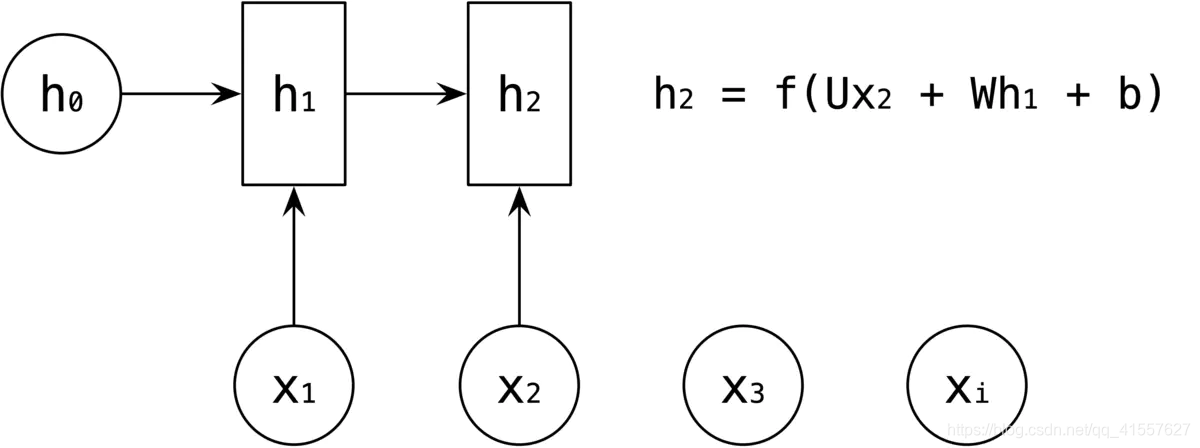
依次计算剩下的 h3、hi,使用相同的参数 U、W、b。
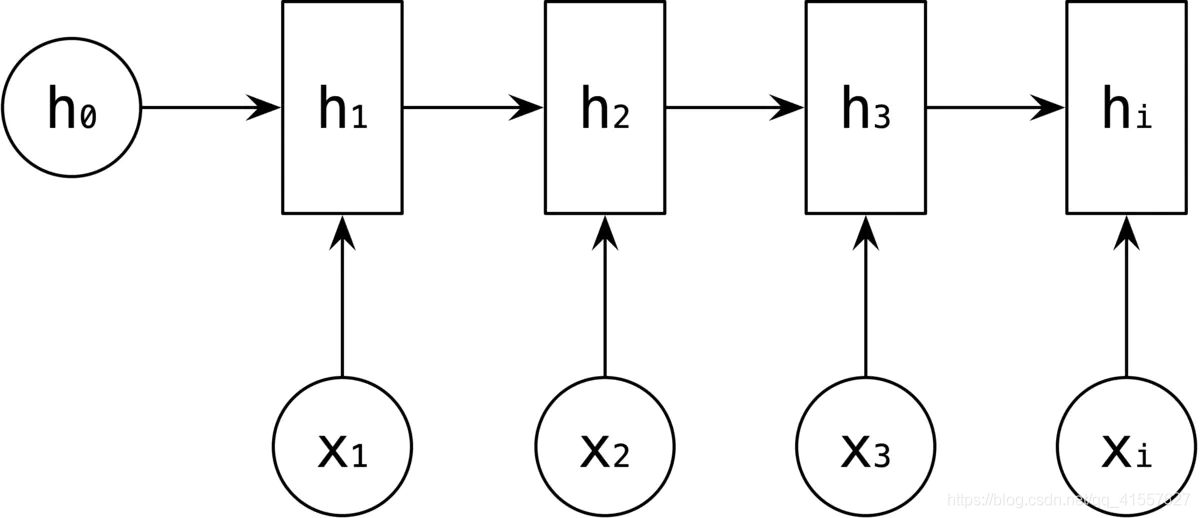
然后输出值的计算,是通过 h 进行计算,如 y1 的输出是通过对 h1 进行一次 Vh1 +c 变换和激活函数 Softmax 得到输出 y1。
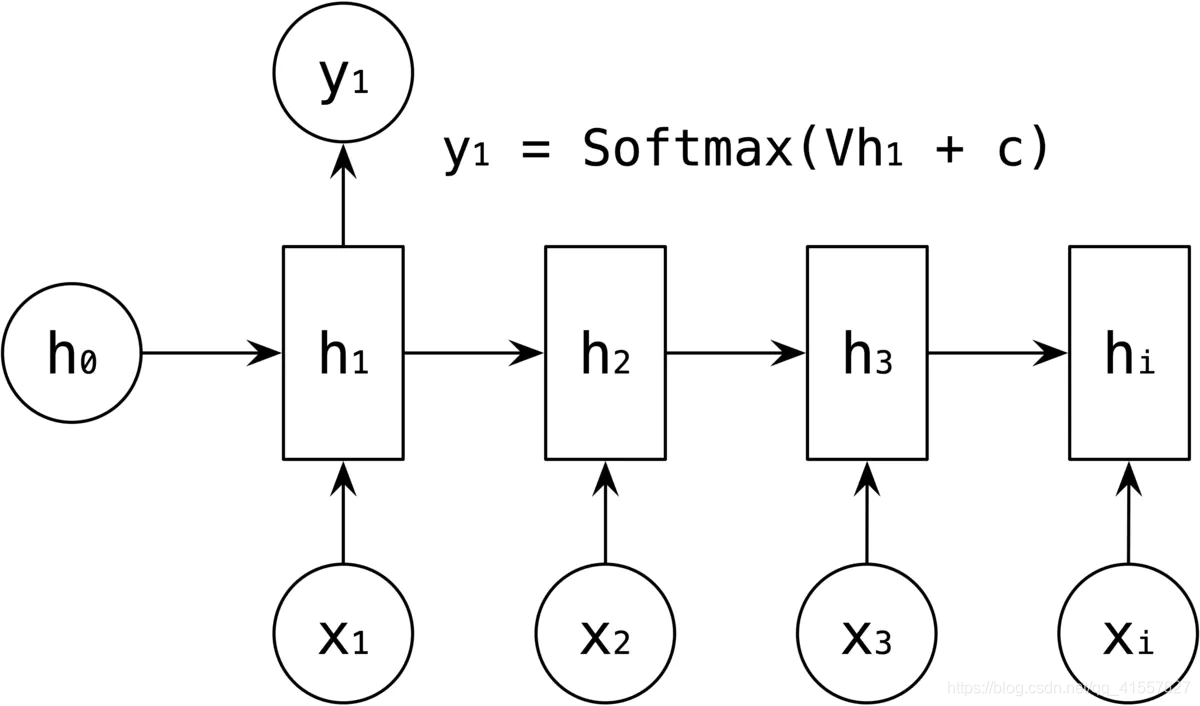
剩下的y2、y3、yi 的输出类似进行。
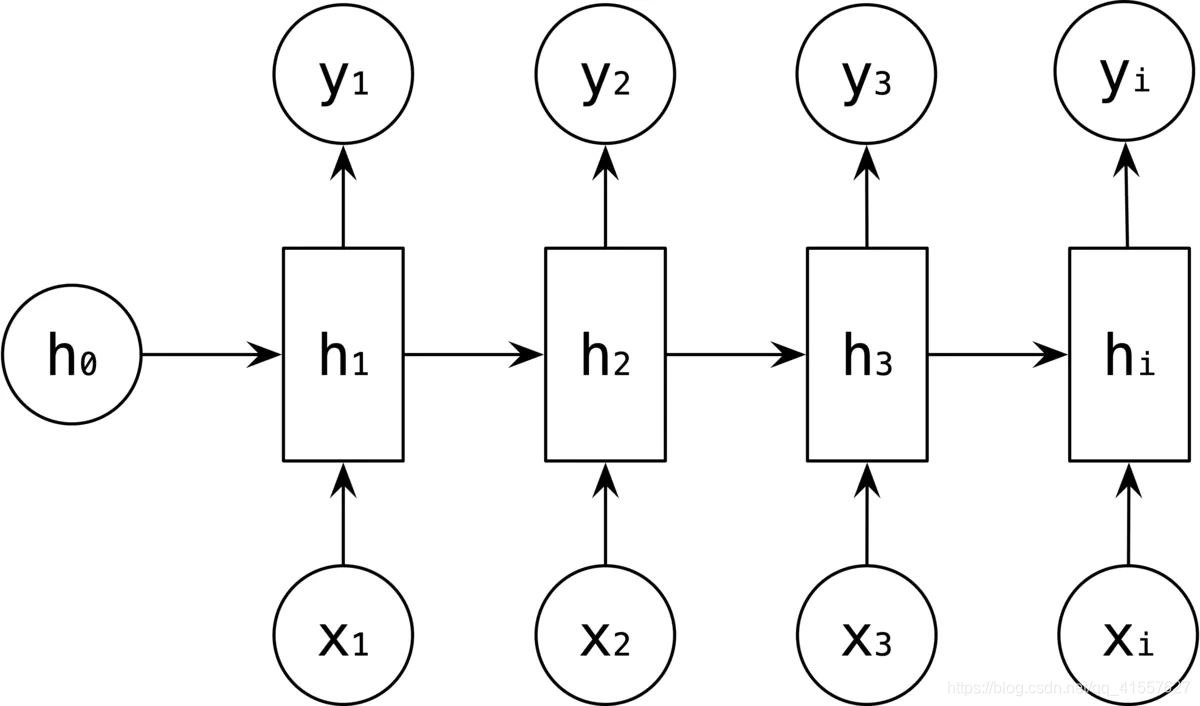
这就是最经典的 RNN 结构,它的输入和输出必须都是等长的。比如对计算视频中每一帧的分类标签,对每一帧进行计算,输入和输出序列等长。此外,因为RNN不能并行计算,容易梯度消失或爆炸的局限造成经典 RNN 的适用范围比较小。
1.2 many-to-one 结构
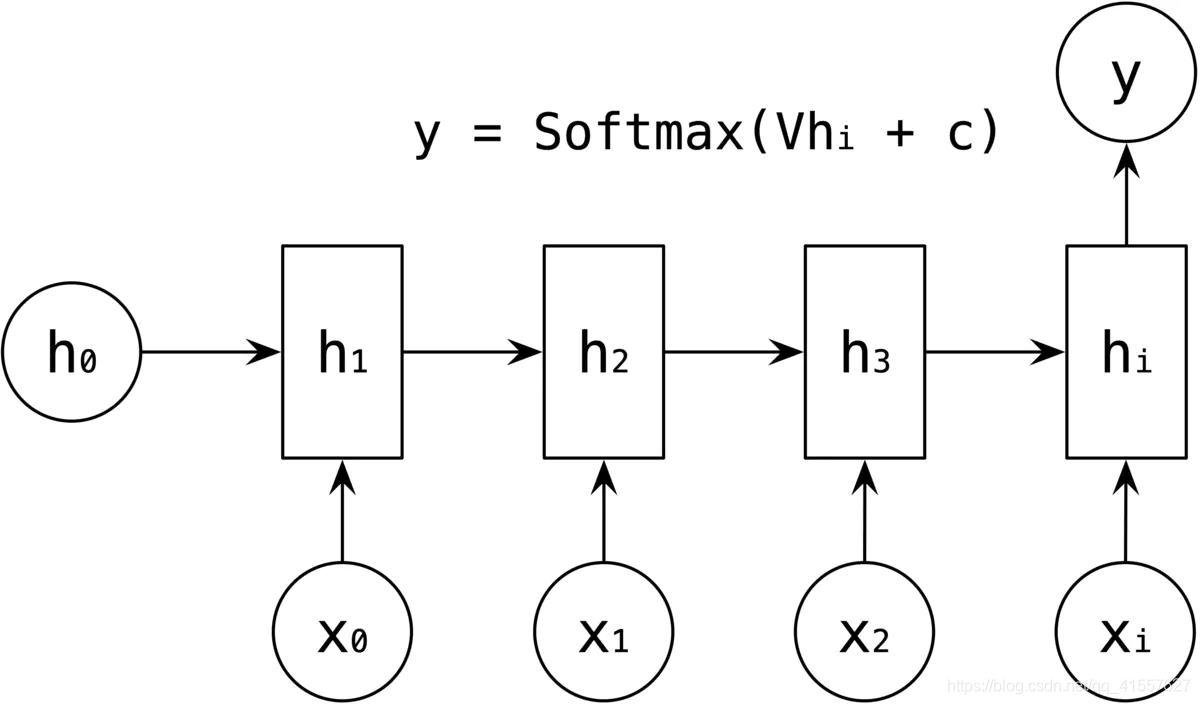
多对一结构是输入为一个序列,输出是一个单独的值。该结构通常应用于序列分类问题,比如输入是一个句子来判断其情感倾向,输入是一段视频来判断它的视频类别等。
2. Encoder-Decoder
在我们的实际应用中,输入和输出为不等长的序列情况更为常见。比如机器翻译中,输入是一段英文序列,输出是中文序列,输入和输出大部分情况都是不等长的。为此,Encoder-Decoder 就是为了解决这个问题的,它是 RNN 的一个重要变种,又叫 Seq2Seq 模型。
Encoder-Decoder 的基本思想是:Encoder 将输入序列转成固定长度的向量;Decoder 将固定长度的向量转成输出序列;Encoder 和 Decoder 可以独立使用,实际应用中两者经常一起使用。
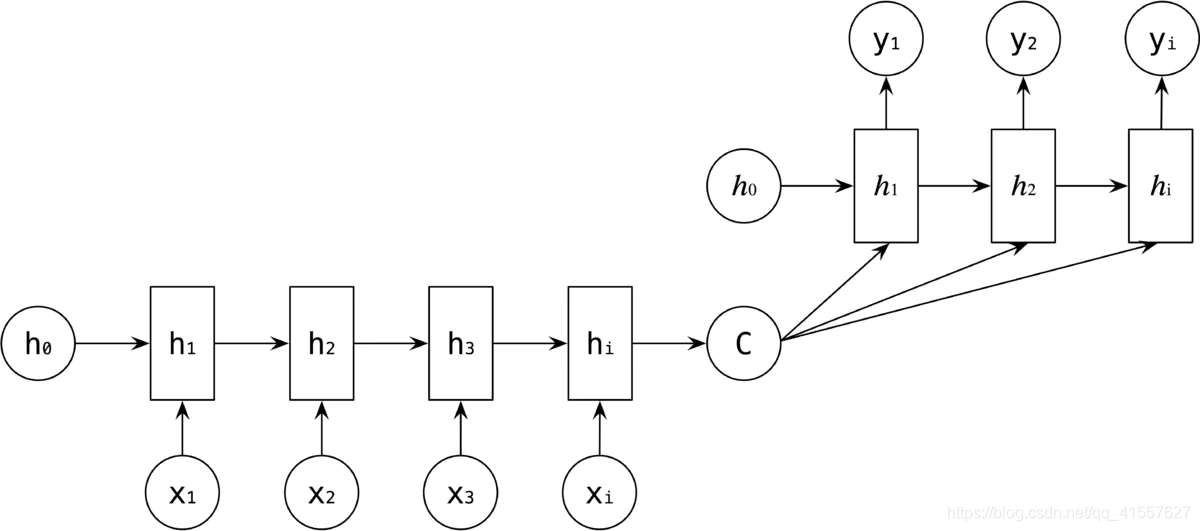
Encoder-Decoder 结构先将输入数据编码成一个上下文语义向量 C,语义向量 C 可以有种表达方式,最简单的就是将 Encoder 的最后一个隐藏状态值 hi 赋给 C,还可以对隐藏状态值 hi 做一个变换得到 C,也可以对所有的隐藏状态 h1 h2 h3 hi 做一个变换。
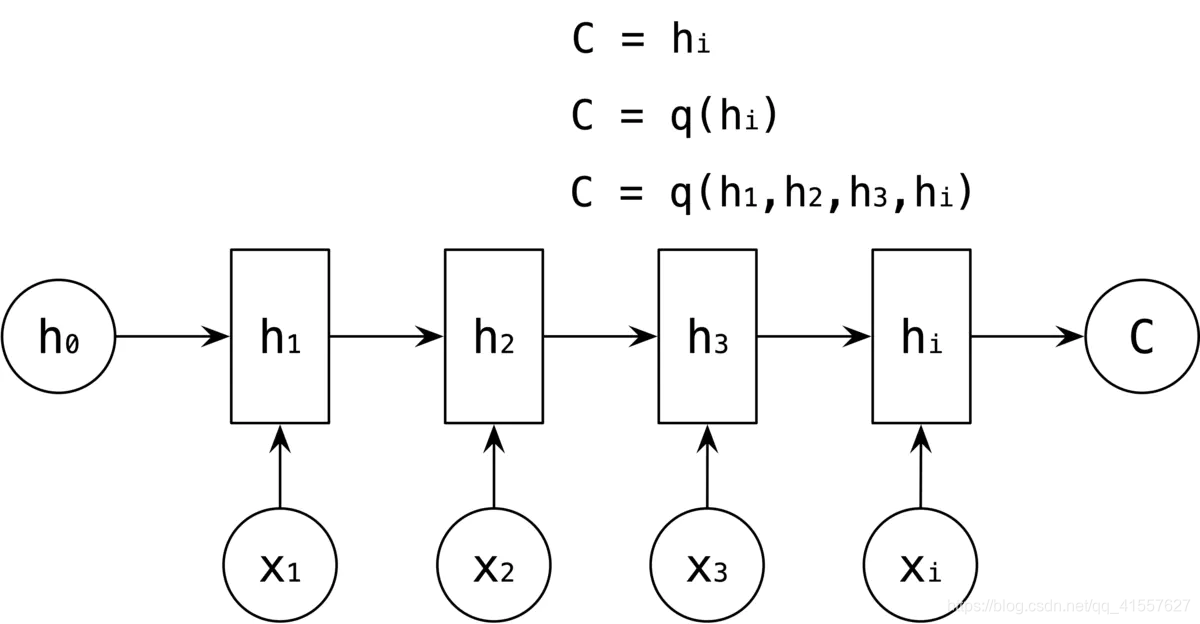
当拿到 C 之后,就用 RNN 的另一个网络 Decoder 对其进行解码,Decoder 的 RNN 可以与 Encoder 的一样,也可以不一样。此时,将 C 作为 Decoder 中的初始状态 h0 作为输入。
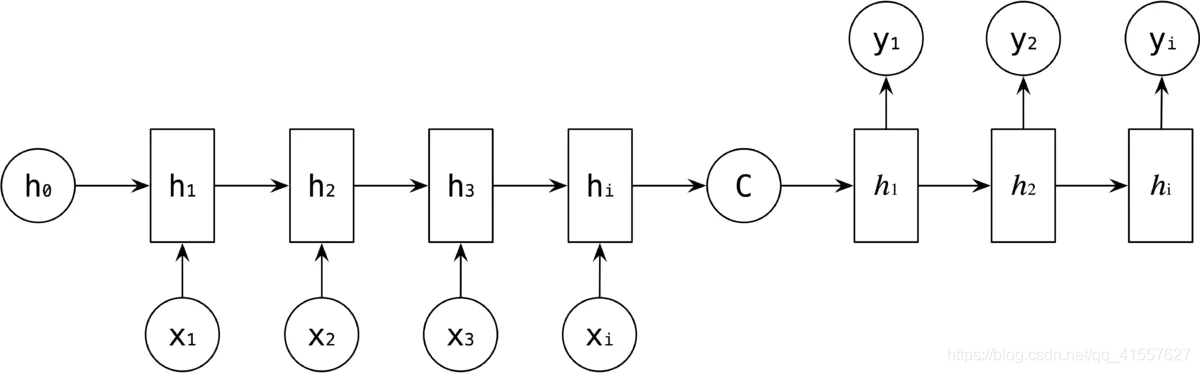
也可以将 C 作为每一步的输入。
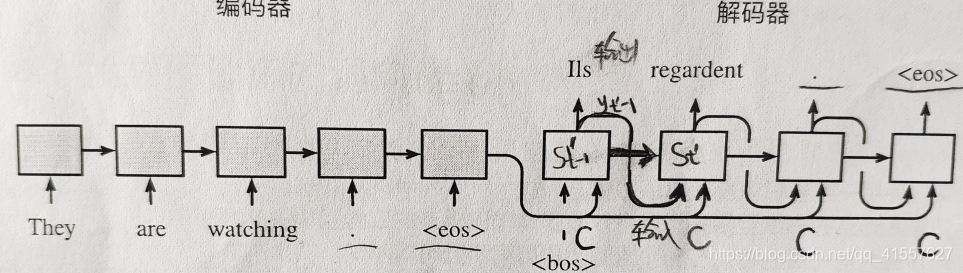
使用Encoder-Decoder将句子由英语翻译成法语。解码器在输出序列的时间步t ,解码器将使用
1.背景向量c
2.上个时间步的输出y
3.上个时间步的隐藏状态h作为输入。
注意:解码器在最初时间步的输入用到了一个表示序列开始的特殊符号
Encoder-Decoder 最大的局限性是编码和解码之间唯一的联系是固定长度的语义词量 C,编码把整个序列的信息压缩到一个固定长度的语义向量 C,正因为如此,语义向量 C 无法完全表达整个序列的信息,输入的序列越长,先输入的内容携带的信息,会被后输入的信息给稀释掉或者被覆盖,这样使得 Decoder 解码时候,一开始就没有获得足够的输入序列信息,解码效果不能得到有效保障。
基于这种现象,提出了 Attention 机制。注意力机制(Attention Mechanism)是对 Encoder-Decoder 的改良,Attention 机制通过在每个时间输入不同的 C 来解决这个问题。
3. Attention 机制
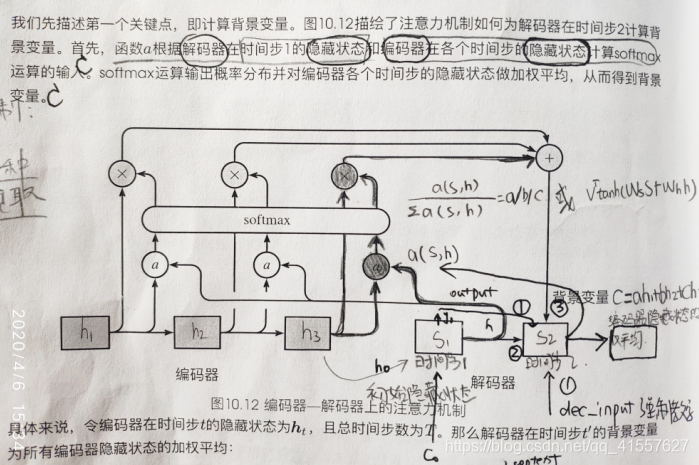
带有 Attention 机制的 Decoder 如下图所示:
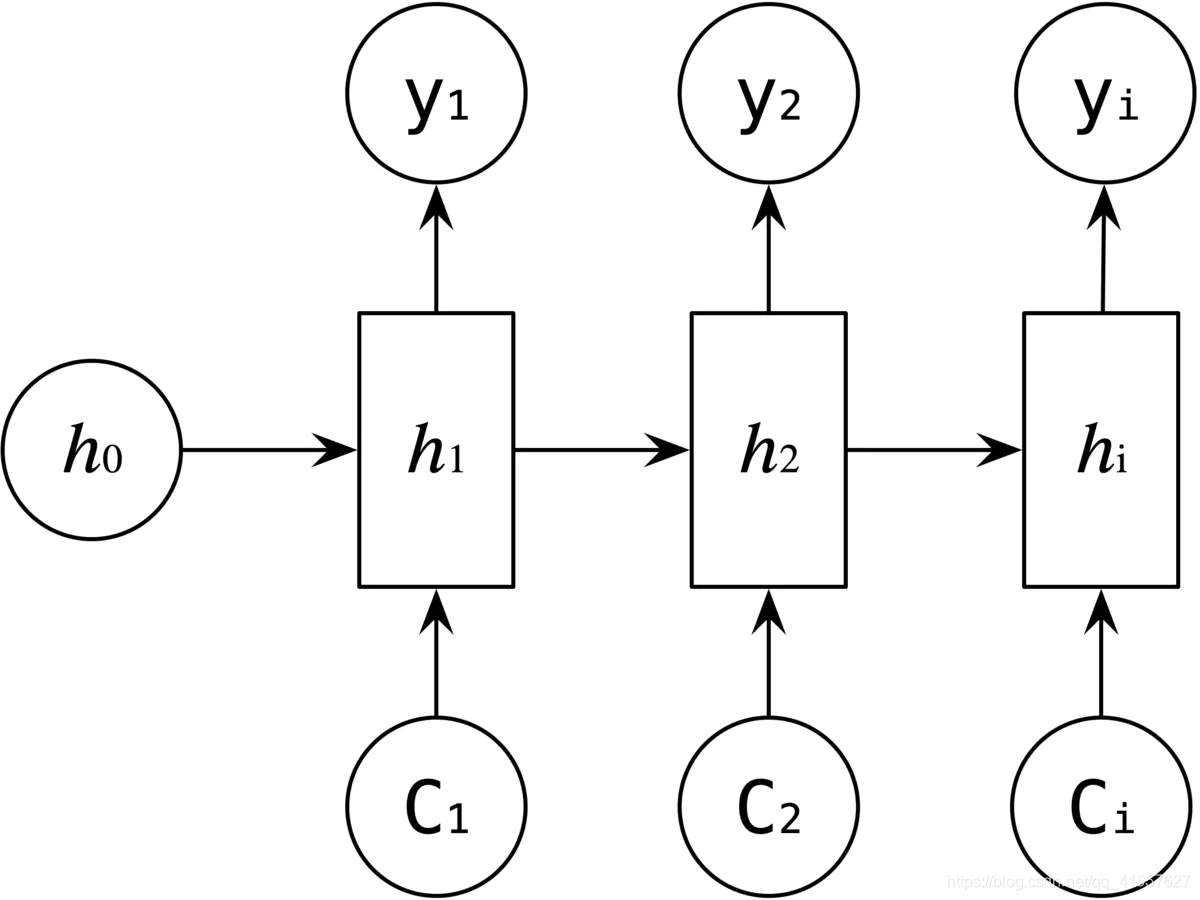
每个 C 会自动去选取与当前所要输出的 y 最合适的上下文信息,具体来说,我们使用 aij 衡量 Encoder 中第 j 阶段的 hj 和解码时第 i 阶段的相关性,最终 Decoder 中第 i 阶段的输入的上下文信息 Ci 就来自与所有 hj 对 aij 的加权和。
比如讲中文“我爱上海”翻译成英文“I love Shanghai”:
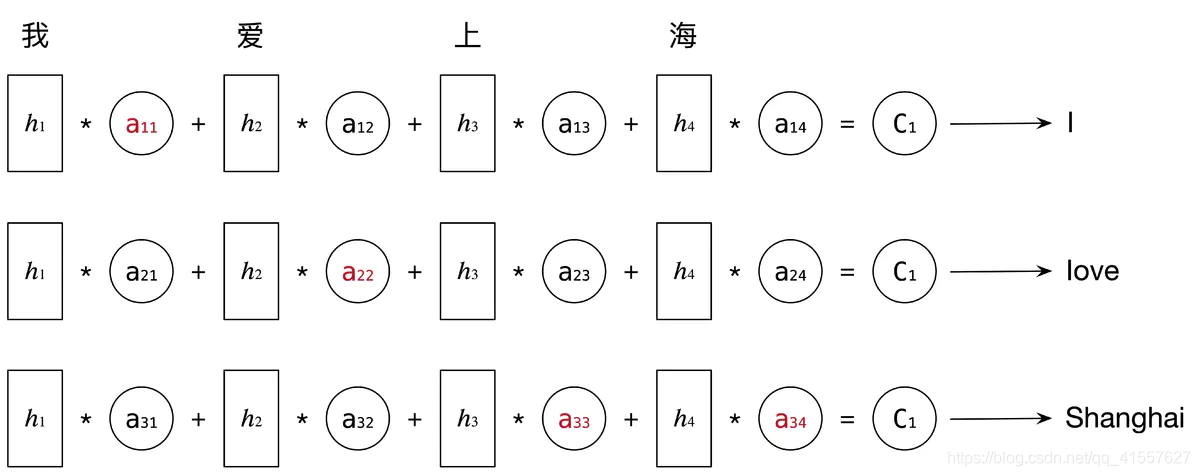
Attention 机制不要求编码器将所有信息全输入在一个固定长度的向量里,它是将输入编码成一个向量的序列,解码时,每一步选择性的从序列中挑选一个子集进行处理,在每个输出时,能够充分利用输入携带的信息,每个语义向量 Ci 不一样,注意力焦点就不一样。
解码器在输出序列的时间步t ,解码器将使用
1.可变的背景向量c
2.上个时间步的输出y
3.上个时间步的隐藏状态h作为输入。
参考文献
作者:桃子说AI
链接:https://www.jianshu.com/p/a1ee00b964f2
来源:简书
