Документы адрес
Основная идея PER с традиционным армированием обучения внутри приоритезированного Подметания в основном то же самое. Это образец из буфера воспроизведения, когда образец в соответствии с приоритетом, приоритет перехода с TD-ошибки представлены. переход TD-ошибки, тем больше потребность в улучшении обучения.
Но детали, специфичные к образцу. Тем не менее необходимо принять к сведению.
жадный приоритезация TD-ошибка
, очевидно , в соответствии с размером TD-ошибка мала до всеобщих выборов. Очевидно , что это проблематично, позади TD-ошибка всегда меньше , чем выборы, низкая эффективность использования данных. Затем еще один недостаток не достаточно стабильна. TD-ошибка является очень шумным.Приоритезация Стохастический
, с вероятностью , пропорциональной для выбора в соответствии с TD-ошибки. \ (\ Альфа \) , чтобы изменить приоритет в конце концов , сколько играть роль.
\ [Р (я) = \ гидроразрыва {p_i ^ \ альфа} {\ sum_k p_k ^ {\ альфа}} \]
\ (P_i \) может быть \ (| \ delta_i | + \ Эпсилон \) (Пропорциональный вариант), или \ (. \ FRAC 1 {{} ранг (\ delta_i)} \) (Ранг вариант)
В памяти воспроизведения, если вы хотите использовать для выборки варианты ранга
В варианте воспроизведения памяти в образце, если вы хотите использовать пропорциональный
используются структуры данных сумм дерева
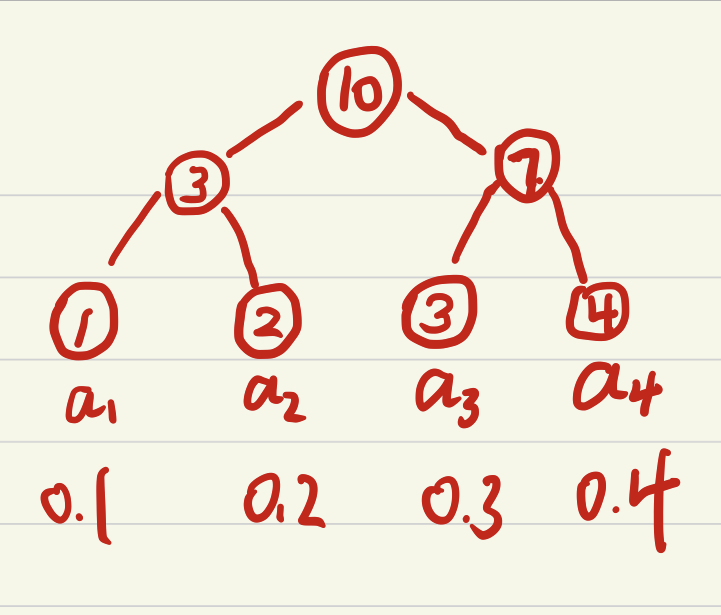
Сумма дерево обеспечивает очень элегантную реализацию на вес образца, все данные в узел листа, право на вес без листьев узлов является суммой всех дочерних узлов. корень Веса вес весь узел листьев и \ (из P_ {Все} \) , так что \ ([0; Р- {все }] \) в случайно выбранных весах затем суммы дерева находится в соответствующем листе узле Он будет иметь возможность завершить случайную долю случайной выборки. (Найти соответствующие веса \ (ш \) правил узла листа тяжелее , чем право ребенка слева \ (W_L \) мало, идите левый ребенок, больше левого ребенок, \ (W = W-W_L \) и затем право ребенка)
На самом деле в соответствии с приоритетом выборки веса разбить исходные данные распределения. Ресэмплирование нужно исправить
\ [W_i = (\ гидроразрыва {1} {N} \ CDOT \ гидроразрыва {1} {Р (я)}) ^ {- \ бета} \]
Соответствует \ (норма E_ {} [X] = E_p [\ FRAC. 1 {N} {} \ CDOT \ FRAC. 1 {} {Р (Х) Х}] \) , \ (\ Бета \) используется для регулировки степень коррекции начальной неустойчивости, \ (\ Бета \) меньше, знать окончательный подход к 1. Например, образец этого \ (Р ( х ) = 1 \) (невозможно), \ (w_i \) необходимости маленький, чтобы уменьшить влияние этого образца, \ (N = w_i ^ \ Beta \) . Так \ (\ беты \) малая и большая коррекция. Реализация \ (w_j = w_j / \ подпирать {я} {макс} w_i \) , чтобы нормализовать. Но бумага говорит , что это взвешенное. Немного смущает?
Бумага псевдо-код, предоставленный:
