Параллельная архитектура данных
https://csruiliu.github.io/blog/20170323-parallel-db-arch/
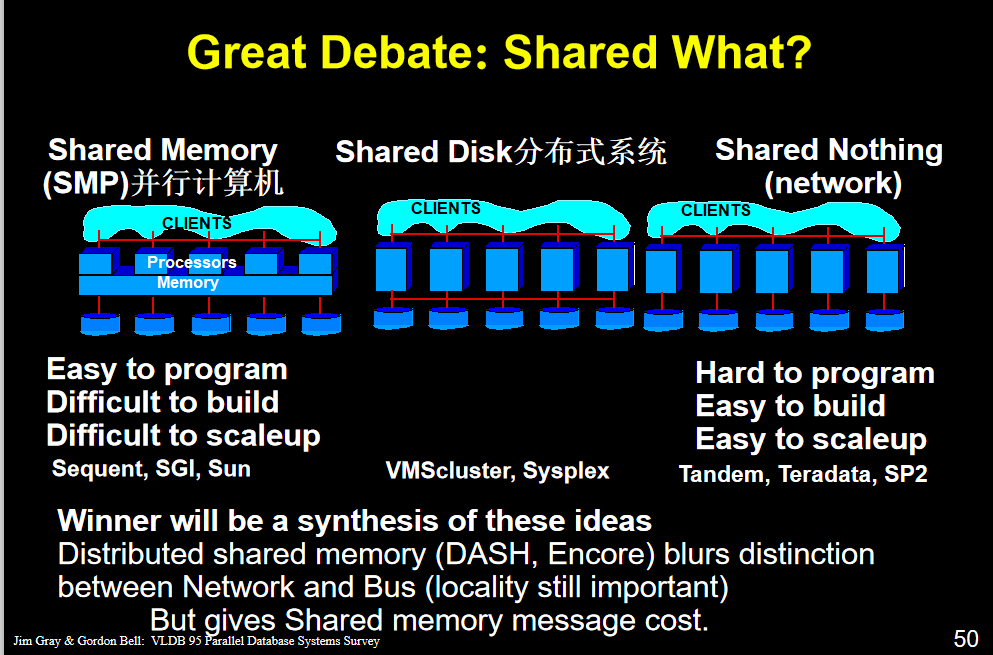
совместно используемая память
АВ два различных процесса к описанию долю памяти, то же физической памяти отображается на другой AB адресное пространство процесса. А Б может быть время, чтобы увидеть изменения в общей памяти
Преимущества: обмен данными между процессами, так что трафик очень удобно, интерфейс функции также является относительно простым.
Данные межпроцессный не передаются, но прямой доступ к памяти, эффективность улучшилась.
Недостаток: scability слишком плохой узел будет конкурировать
Отказоустойчивость не хороший сбой памяти или ошибка, то вся система будет иметь проблемы
Общий диск
Диск обмен несколько узлов, но каждый имеет свою собственную память
Повышение отказоустойчивости из-за всей параллельной системы баз данных может работать каждый узел имеет свою собственную память или несколько проблем вниз
scability но и повысить узкое место из памяти на диск на диск многократным узел конкуренции
НЕТ Поделиться
ShareMachine подключается только через сеть
«Shared-ничего» означает архитектуру , что каждый компьютер система имеет свои собственные выделенные памяти и выделенный диск .
Каждый процессор имеет свой собственный диск и память.
Затраты на строительство намного меньше, чем первые два
Узел связи накладные расходы между несколькими крупной партии, принести много накладных расходов для координации этих узлов
Она нуждается в своем собственном графике, самостоятельно рассмотреть, как в полной мере использовать ресурсы
(Лучший способ к каждому из данных на раздел диска, а затем объединить это гарантирует, что каждый узел может работать)
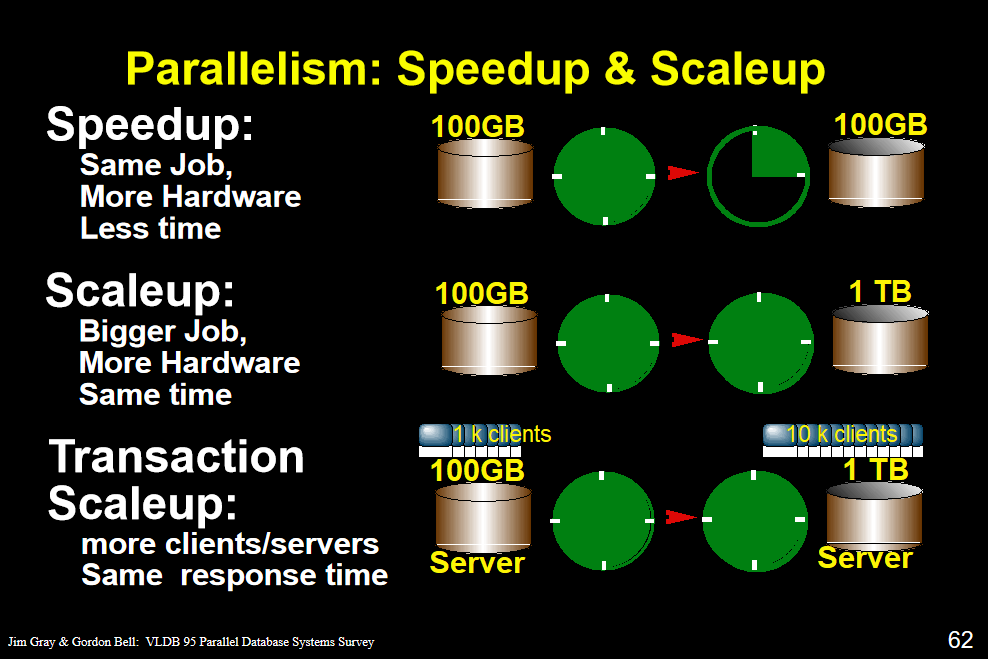
убыстрение данные остаются неизменными, то же количество задач расширения компьютера завершается за меньшее время
увеличение данных scaleup, также увеличилось количество компьютеров, чтобы выполнить больше задач одновременно
Люди увеличивает доступ к транзакции scaleup, аппаратные инвестиции, чтобы увеличить постоянное время отклика
Сервер подключен к клиенту больше
3.speedup запуск и почти линейный
Параллельно повышения производительности системы, близкой к линейной
Два человека делает почти в два раза скорости человека
После двух подзадач сделать до того, как люди, чтобы сделать задачу не параллельно тотальную проверку
4.


第二张图 加了硬件性能仍然没有提升 说明算法的问题 或协调额外开销成本过大
第三张图 最后的弯曲 每个任务被分成的大小过小 导致协调成本过高 性能会掉一点
time sharing 每台机器同时响应多个人 当前有请求的人排队,每个时间片给当前有请求的人
时间片循环 服务总人数=时间片*队列长度
从一个人切换到另一个人发生了context switch
context switch timer发一个中断 进入kernel mode
保存当前运行CPU的状态
将接下来的进程载入CPU rip指向新进程接下来要执行的指令
再从kernel mode切换回user mode
当time slice的大小接近于context switch的时间 机器感觉大部分时间都在context switch
额外开销抵充了并行提高的效率 并行系统性能下降

scanf取一条记录,count计数,最后汇总
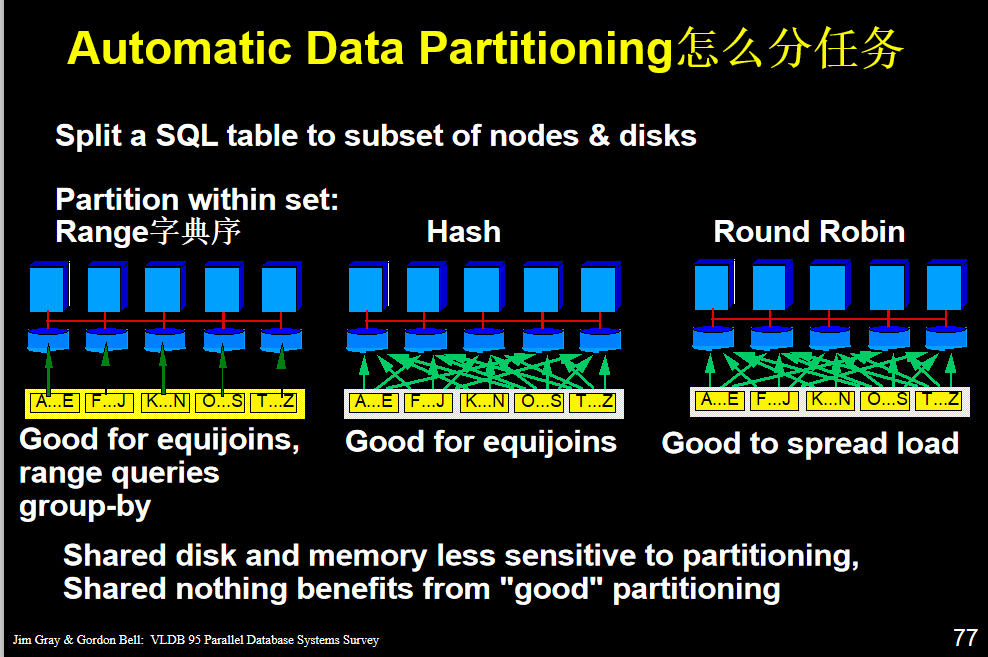
范围 分区根据您为每个分区建立的分区键值范围将数据映射到分区。
hash分区 对您标识的分区键应用的哈希算法将数据映射到分区。 哈希算法将行平均分配给分区,从而使分区的大小大致相同。 散列分区是在设备之间平均分配数据的理想方法。
好处 空间使用均与 取一个大素数的模 减少冲突(冲突意味着映射不均匀)
坏处 不适用于连续的数 将连续的学号分布到不同的地方 找起来麻烦
轮循分区

