готовый
1, Hadoop были развернуты (если нет ссылки: установка Centos7 Hadoop2.7 ), кластер не следует ( IP - адрес предыдущей статьи могут быть изменены ):
| имя хоста | IP-адрес | Планирование развертывания |
| node1 | 172.20.0.2 | NameNode, DataNode |
| node2 | 172.20.0.3 | DataNode |
| node3 | 172.20.0.4 | DataNode |
2, официальный сайт, чтобы скачать инсталляционный пакет: искровой 2.4.4-бен-hadoop2.7.tgz (Цинхуо рекомендуется открывать или зеркальные сайты USTC).
3, искра будет развернута в три уже существующем пути / MyData, настройте переменные окружения:
экспорт SPARK_HOME = / MYDATA / искровой 2.4. 4 экспорт PATH = $ {SPARK_HOME} / бен: $ {SPARK_HOME} / SBIN: $ PATH
местный режим
В node1 декомпрессии машины с искровым 2.4.4-бен-hadoop2.7.tgz к / MyData и переименовать /mydata/spark-2.4.4 папки.
В соответствии с Hadoop статьи, искровой версии выполнить задачу WordCount (версия Python) следующие действия:
Оболочка> ВИМ 1.txt # создать файл, написать что - то
Hadoop Hadoop
HBase HBase HBase
искра искра искра искра
оболочка> искрового $ SPARK_HOME Передать / примеры / SRC / основной / Python / wordcount.py 1.TXT # представить искру WordCount задача, статистика 1.TXT слов и число результатов являются
Спарк: 4
HBase: 3
Hadoop: 2
искра расчет двигатель, просмотреть файл wordcount.py можно увидеть достижение той же функции, ее код гораздо меньше , чем MapReduce, что значительно снижает сложность разработки больших данных.
режим Standalone
Может быть переведено в автономный режим, искра приходит к завершению в дополнении к кластеру хранения, следуя первую конфигурацию на node1:
Файл конфигурации искры находится в $ SPARK_HOME / конфе:
Копия искры-env.sh.template spark-env.sh
Из slaves.template копировальных рабов
#文件名spark-env.sh SPARK_MASTER_HOST = узел1 SPARK_LOCAL_DIRS = / MYDATA / данные / искровой / царапина SPARK_WORKER_DIR = / MYDATA / данные / искра / работа SPARK_PID_DIR = / MYDATA / данные / PID SPARK_LOG_DIR = / MYDATA / журналы / искра
#文件名рабы
node1
node2
node3
Поскольку start-all.sh и stop-all.sh конфликт с Hadoop под $ SPARK_HOME / SBIN, рекомендуется переименовать:
Оболочка> мв запуск всех. ш искровым пуск всех. ш оболочки > мв стоп-все. ш искровым стоп-всех. ш
После завершения настройки искры программных файлов копируются в два других:
оболочка> УПП -qr / MYDATA / искровым 2.4.4 / корень @ node2: / MYDATA / оболочка > УПП -qr / MYDATA / искровым 2,4 . 4 / корень @ node3: / MYDATA /
Затем запустите кластер node1:
Оболочка> искрового запуска всех. ш
| Процесс аутентификации с использованием JPS команды на node1 | Мастер, работник |
| Процесс аутентификации с использованием JPS команды на node2 | работник |
| Процесс аутентификации с использованием JPS команды на node3 | работник |
Может быть доступны через браузер HTTP: // node1: 8080 /:

Следующий файл 1.txt на несколько копий является 2.txt, затем ставятся на HDFS, и, наконец, через искровой кластер выполнить WordCount задачи:
оболочка> CP 1.txt 2.txt
оболочки> HDFS -mkdir DFS / TMP / WC /
раковина> HDFS ДФС -Положите 1.txt 2.txt / TMP / WC /
раковина> Искра-Submit --master Спарк: // node1 : 7077 $ SPARK_HOME / примеры / SRC / главная / Python / wordcount.py HDFS: // node1: 9000 / TMP / WC / *
оболочки> Искра-Отправить --master Спарк: // node1: 7077 $ SPARK_HOME / примеры / SRC 9 /main/python/pi.py # прохождения теста вычислительных задач пи, позицией 9 обозначен последний срез (Перегородки) номер, вывод , подобный этому: Пи примерно 3,137564
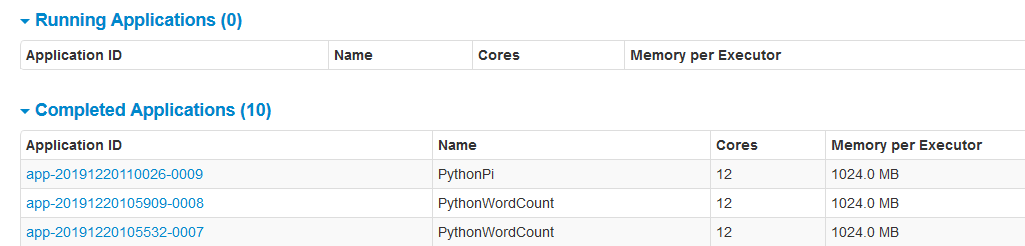
В HTTP: // node1: вы можете увидеть задачи, выполняемые 8080 / на:
режим пряжи
Фактическое использование, как правило, путем получения их запуска, чтобы зажечь существующий кластер, такие как использование Hadoop собственной пряжи для планирования ресурсов.
искра на нити не требует искры кластера, так что остановить его:
Оболочка> искровой стоп-всех. ш
Конфигурация очень просто, чтобы иметь эту переменную окружения:
экспорт HADOOP_CONF_DIR = $ {HADOOP_HOME} / и т.д. / Hadoop
Тем не менее, для удобства просмотра истории и журналов, здесь для настройки истории сервера искровой, и связанный с jobhistory Hadoop из:
В каталоге $ SPARK_HOME / конф, с копией искрового defaults.conf.template искрового defaults.conf:
# 文件名 spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:9000/spark/history spark.history.fs.logDirectory hdfs://node1:9000/spark/history spark.yarn.historyServer.allowTracking true spark.yarn.historyServer.address node1:18080
进入目录 $HADOOP_HOME/etc/hadoop,在 yarn-site.xml 中添加一下内容:
# 文件名 yarn-site.xml <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs/</value> </property>
在hdfs创建必要的路径:
shell> hdfs dfs -mkdir -p /spark/history
将hadoop和spark的配置同步更新到其他所有节点(勿忘)。
下面在node1重启yarn,并且启动spark history server:
shell> stop-yarn.sh
shell> start-yarn.sh
shell> start-history-server.sh # 启动后通过jps可以看到多出一个HistoryServer
执行下面的命令,通过yarn及cluster模式执行wordcount任务:
shell> spark-submit --master yarn --deploy-mode cluster $SPARK_HOME/examples/src/main/python/wordcount.py hdfs://node1:9000/tmp/wc/*
浏览器访问 http://node1:18080/ 可以看到spark的history:
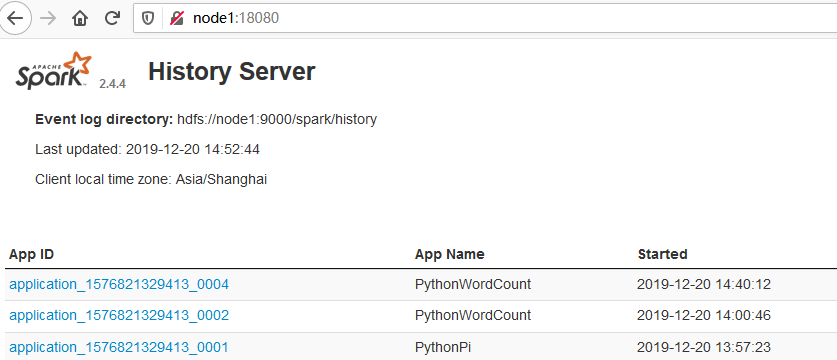
点击 App ID 进入,然后定位到 Executors ,找到 Executor ID 为driver的,查看它的stdout或stderr:

即可看到日志和计算结果:

同样,可以通过yarn命令访问日志:
shell> yarn logs -applicationId [application id]
over