I. Предпосылки больших методов данных
1. Компьютер и информационные технологии ( в частности , мобильный Интернет) быстрое развитие и популяризация , прикладная система быстро расширяются (количество пользователей и сценариев приложений, такие как Facebook, Taobao, микро-канал, CUP, 12306 и т.д.) производств, промышленное применение данные показали взрывной рост .
2. PB легко достигать нескольких сотен или даже EB (1EB = 1024PB = 1024 * 1024TB) размером данных было далеко за пределы традиционной вычислительной мощности компьютеров и информационных систем.
методы обработка, методы и инструменты 3. Эффективных большие данные стали насущной потребностью .
Тройка Google, закладываются в разработке больших объемов данных базы очень важно .
Google Тройка (очень важна): три документа ---> идеи, принципы
1, GFS: Google файловой системы --- > HDFS: Hadoop Distributed File System
является распределенной файловой системой для решения больших данных проблемы хранения.
Что такое перевернутая индекс? Восстановлено Index
инвертированный индекс:
Если вы хотите, чтобы «большие данные», если только передний указатель, это может занять ключевое слово в поиске много времени сканирования всей таблицы, то запись ключевого слово «большие данные», огромное количество данных в случае этого медленного процесса люди не сделали,
Таким образом, с перевернутым индексом, поисковая система будет перестраивать вперед индекс является инвертированным индекс, который соответствует файлу ID картографирования ключевых слов преобразовать в ключевые слова отображения файл идентификатор каждого ключевого слова соответствует серии документы, которые возникли это ключевое слово.
Популярные сказал:
Благодаря данных, поиск адреса
2, MapReduce модель расчета: источник задачи PageRank (первым разделен на множество малых вычислительных задач, а затем агрегируется)
3, BigTable большой стол ----> базы данных NoSQL: HBase (жертвоприношение пространство в обмен на время)
II. Сценарии больших объемов данных
перемещения населения Baidu праздник Весна, китайский Новый год 2014, Baidu начали «Baidu миграцию», использование технологий Big Data, свои LBS вычислительного анализа (на основе определения местоположения услуг) большие данные, а также использование инновационных «визуальных» презентации , первый в отрасли для достижения полного, динамичного, в режиме реального времени, наглядно демонстрируют траекторию и характеристики до и после китайского нового года миграция большого населения, как показано на рисунке 1-3. (URL запроса: HTTP :. //Qianxi.baidu.com/)

(1) данные , хранящиеся: Распределенная файловая система (GFS, HDFS и т.д.)
вычисляется (2) данные: распределенная вычислительная модель (MapReduce, Спарк RDD и т.д.)
в двух направлениях: рассчитано на форуме: Hadoop MapReduce, Спарк сердечника, Flink DataSet
расчет в режиме реального времени: Шторм, Искра Streaming, Flink DataStream
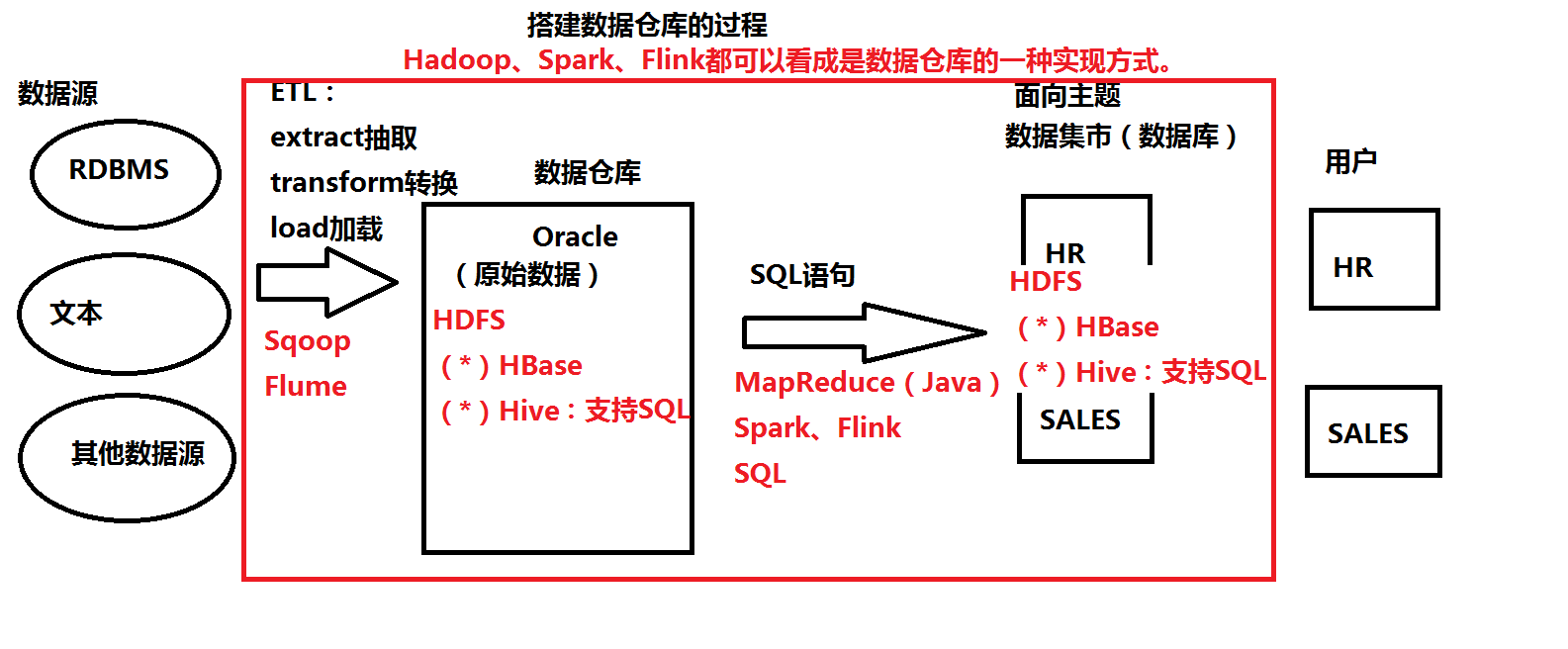
IV. Хранилища данных
Традиционные хранилища данных: Oracle, MySQL и т.д.
Большие данные: Hadoop, Спарк, Flink можно рассматривать как реализацию хранилища данных
概念:OLTP与OLAP
数据仓库又是一种OLAP的系统
OLTP:online transaction processing 联机事务处理
insert update delete commit rollback
特点:ACID 原子性、一致性、持久性、隔离性 -----> 关系型数据库
OLAP:online analytic processing 联机分析处理
一般:select
不关心事务
五.Hadoop生态圈的体系机构(Apache 简单版)
