Советы: Эта статья не описывает содержимое, связанное с регистрами с плавающей точкой, узнать самоконтроль (в конце концов, я не знаю)
Основная концепция планировщика
TencentOS tinyЭто при условии , что планировщик задача является приоритетной основой упреждающего планирования переполненно, система работает, когда есть более готовы , чем текущий приоритет задачи, текущая задача немедленно 切出, приоритетная задача 抢占процессор работает.
TencentOS tinyЯдро также позволяет создать ту же самую приоритетную задачу. Первоочередные задачи , используя один и тот же режим циклического планирования (которые часто говорят , планирование разделения времени), о планировании циклического не является в настоящее время системы не более высокого приоритет готов задачей , чтобы быть эффективными в случае.
Для обеспечения системы в режиме реального времени, система максимально возможной степени, чтобы обеспечить приоритетную задачу для запуска. Принцип планирования задача состоит в том, как только статус задачи изменяется, и в настоящее время работает приоритетной задачей является менее приоритетных задач в очереди с наивысшим приоритетом, немедленно задача переключения (если текущая система не находится в состоянии обработчика прерываний или отключить переключатель задач) ,
Планировщик операционной системы 核心, ее основная функция заключается в 实现任务的切换том , что готовый список , из которого 找到приоритетной задачей высшей, а затем перейти к 执行задаче.
Начало Планировщик
Планировщик инициируется cpu_sched_startдля завершения функции, то она будет tos_knl_startвызвана функция , которая в основном две вещи, сначала readyqueue_highest_ready_task_getприобретая текущую системную функцию на наивысший приоритет готовой задачи и назначить его , чтобы указать на текущий блок управления задачей указатель k_curr_task, а затем установить состояние системы о режиме работы KNL_STATE_RUNNING.
Конечно, самое главное, чтобы вызывать функции , написанные на ассемблере , cpu_sched_startчтобы запустить планировщик, функцию в исходном arch\arm\arm-v7mкаталоге port_s.Sпри сборке файлов, TencentOS tinyподдержка многоядерных чипов, как M3/M4/M7другие различные способы для достижения различных чипов , которые функционируют, port_s.Sно и в TencentOS tinyкачестве программного обеспечения связано с аппаратными средствами центрального процессора 桥梁. М4 , чтобы cpu_sched_startпривести пример:
__API__ k_err_t tos_knl_start(void)
{
if (tos_knl_is_running()) {
return K_ERR_KNL_RUNNING;
}
k_next_task = readyqueue_highest_ready_task_get();
k_curr_task = k_next_task;
k_knl_state = KNL_STATE_RUNNING;
cpu_sched_start();
return K_ERR_NONE;
}port_sched_start
CPSID I
; set pendsv priority lowest
; otherwise trigger pendsv in port_irq_context_switch will cause a context swich in irq
; that would be a disaster
MOV32 R0, NVIC_SYSPRI14
MOV32 R1, NVIC_PENDSV_PRI
STRB R1, [R0]
LDR R0, =SCB_VTOR
LDR R0, [R0]
LDR R0, [R0]
MSR MSP, R0
; k_curr_task = k_next_task
MOV32 R0, k_curr_task
MOV32 R1, k_next_task
LDR R2, [R1]
STR R2, [R0]
; sp = k_next_task->sp
LDR R0, [R2]
; PSP = sp
MSR PSP, R0
; using PSP
MRS R0, CONTROL
ORR R0, R0, #2
MSR CONTROL, R0
ISB
; restore r4-11 from new process stack
LDMFD SP!, {R4 - R11}
IF {FPU} != "SoftVFP"
; ignore EXC_RETURN the first switch
LDMFD SP!, {R0}
ENDIF
; restore r0, r3
LDMFD SP!, {R0 - R3}
; load R12 and LR
LDMFD SP!, {R12, LR}
; load PC and discard xPSR
LDMFD SP!, {R1, R2}
CPSIE I
BX R1Cortex-M ядро от прерывания обучения
Из приведенной выше коды сборки, я хочу , чтобы ввести Cortex-Mядро прерывания отключить инструкции, увы ~ чувствует себя немного неприятности!
Для быстрого переключения прерывания, Cortex-М создан специально ядро CPS 指令для работы PRIMASKрегистра с FAULTMASKрегистром, два регистра Маскируется прерывания , связанные с, в дополнении к Cortex-Mсердцевине есть BASEPRIрегистр , связанный с прерыванием также между прочим расскажите нам об этом.
CPSID I ;PRIMASK=1 ;关中断
CPSIE I ;PRIMASK=0 ;开中断
CPSID F ;FAULTMASK=1 ;关异常
CPSIE F ;FAULTMASK=0 ;开异常| Регистрация | функция |
|---|---|
| PRIMASK | 1 после того, как было установлено, отключить все маскируемое исключение, только в ответ ОГО и HardFault FAULT |
| FAULTMASK | Когда он установлен в 1, только NMI может, все остальные исключения не в состоянии ответить (включая HardFault FAULT) |
| BASEPRI | Это зарегистрировать до девяти (число битов, выражающих приоритетное решение). Она определяет приоритет маскируется порог. Когда он установлен на значение, все числа, большие или равные к этому приоритета прерываний повернуты значение (чем больше приоритет номер, тем ниже приоритет). Однако, если установлено значение 0, то прерывание не не выключается |
Более подробное описание см моей предыдущей статьи: RTOS критических разделы знаний: https: //blog.csdn.net/jiejiemcu/article/details/82534974
Вернуться к теме
В ядре планировщика для запуска процесса необходимо настроить PendSVуровень прерывания приоритета является самым низким, то есть, чтобы NVIC_SYSPRI14(0xE000ED22)написать адрес NVIC_PENDSV_PRI(0xFF). Поскольку PendSVбудет включать в себя планирование системы, приоритет планирования системы к 低于другому приоритету прерываний аппаратных средств системы, что система приоритетов реагирования внешних аппаратным прерываний, так PendSV прерывания приоритета Чтобы настроить низкие, или, скорее всего , в контексте прерывания генерируются планирования задач.
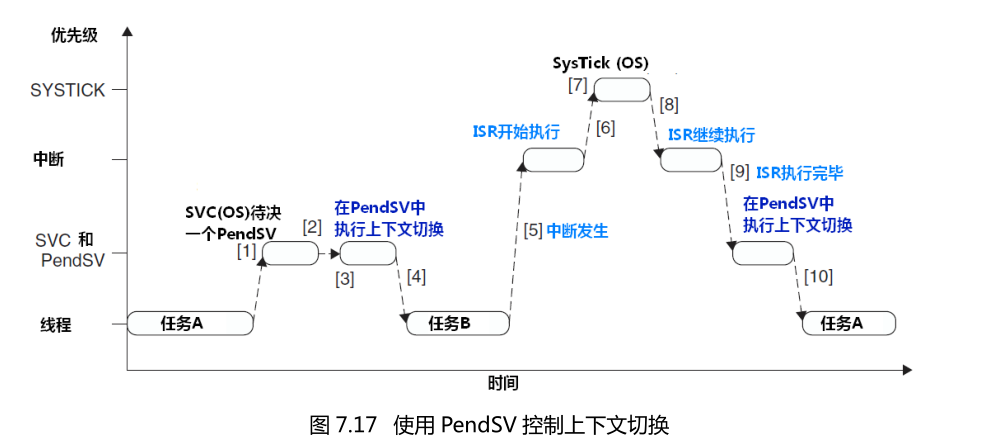
PendSVАномальные переключение контекста будет автоматически задержать запроса , пока другие ISRне завершило лечение после освобождения. Для достижения этого механизма, мы должны PendSVбыть запрограммированы до самого низкого приоритета исключения. Если OSобнаружен ISRбыть активным, он висит от PendSVисключения, для того , чтобы выполнить переключение контекста приостановлено. Другими словами, до тех пор , пока PendSVприоритет до самого низкого, SysTick даже прервал IRQ, это будет не переключение контекста сразу, но ждать , пока ISRне выполняется, PendSVподпрограмма обслуживания начал выполнять, и выполнить переключение контекста на внутренней , Как показано в процедуре фиг:
тогда вы получите MSPадрес указателя основного стека, в Cortex-Mсередине, адрес регистра, который хранится начальный адрес таблицы векторов.0xE000ED08SCB_VTOR
Нагрузка k_next_taskуказует на блок управления задачей R2, первый известный член блока управления задачей является указателем стека из предыдущей статьи, поэтому в данном случае R2равного указателя стеки.
пс: При запуске планировщика,
k_next_taskиk_curr_taskтак же , как (k_curr_task = k_next_task)
Загруженный R2в R0, то указатель стека R0обновления pspуказателя стека используется , когда выполнение задачи является psp.
пс:
spPointer два, соответственноpspиmsp. (Может быть просто понимать как: использование в контексте миссииpsp, использование контекста прерыванияmsp, не обязательно правильно, это мое личное понимание)
В R0базовый адрес, стек растет вверх в 8загрузке содержимого регистров процессора слов R4~R11, в то время как R0будет следовать самовозбуждение
Затем вам необходимо загрузить R0 ~ R3、R12以及LR、 PC、xPSRв наборы регистров процессора, PC является указателем на нити к исчерпанию, а LR регистр точек выхода к задаче. 因为这是第一次启动任务,要全部手动把任务栈上的寄存器弹到硬件里,才能进入第一个任务的上下文,因为一开始并没有第一个任务运行的上下文环境,而在进入PendSV的时候需要上文保存,所以需要手动创造任务上下文环境(将这些寄存器加载到CPU寄存器组中)Во- первых ассемблер , когда функция входа, зр является верхней частью стеки точек задач для выбранного ( k_curr_task).
Посмотрите на инициализацию стека задачи
Из приведенного выше понимания, обратите внимание на задачи инициализации стека, может быть немного более глубокое впечатление. В основном, чтобы понять следующие моменты:
- Возвращает указатель стека
stk_base[stk_size]высокий адрес,Cortex-Mстек ядра向下增长в. R0、R1、R2、R3、R12、R14、R15和xPSR的位24CPU будет自动загружен и сохранен.- xPSR из
bit24必须置1этого 0x01000000. - запись запись решения задачи, а именно
PC - R14 (
LR) является выход решения задачи, поэтому задача , как правило , бесконечный цикл безreturn - R0: Параметр Arg является основной задачей
- Инициализация указателя стека зр декрементируется
__KERNEL__ k_stack_t *cpu_task_stk_init(void *entry,
void *arg,
void *exit,
k_stack_t *stk_base,
size_t stk_size)
{
cpu_data_t *sp;
sp = (cpu_data_t *)&stk_base[stk_size];
sp = (cpu_data_t *)((cpu_addr_t)(sp) & 0xFFFFFFF8);
/* auto-saved on exception(pendSV) by hardware */
*--sp = (cpu_data_t)0x01000000u; /* xPSR */
*--sp = (cpu_data_t)entry; /* entry */
*--sp = (cpu_data_t)exit; /* R14 (LR) */
*--sp = (cpu_data_t)0x12121212u; /* R12 */
*--sp = (cpu_data_t)0x03030303u; /* R3 */
*--sp = (cpu_data_t)0x02020202u; /* R2 */
*--sp = (cpu_data_t)0x01010101u; /* R1 */
*--sp = (cpu_data_t)arg; /* R0: arg */
/* Remaining registers saved on process stack */
/* EXC_RETURN = 0xFFFFFFFDL
Initial state: Thread mode + non-floating-point state + PSP
31 - 28 : EXC_RETURN flag, 0xF
27 - 5 : reserved, 0xFFFFFE
4 : 1, basic stack frame; 0, extended stack frame
3 : 1, return to Thread mode; 0, return to Handler mode
2 : 1, return to PSP; 0, return to MSP
1 : reserved, 0
0 : reserved, 1
*/
#if defined (TOS_CFG_CPU_ARM_FPU_EN) && (TOS_CFG_CPU_ARM_FPU_EN == 1U)
*--sp = (cpu_data_t)0xFFFFFFFDL;
#endif
*--sp = (cpu_data_t)0x11111111u; /* R11 */
*--sp = (cpu_data_t)0x10101010u; /* R10 */
*--sp = (cpu_data_t)0x09090909u; /* R9 */
*--sp = (cpu_data_t)0x08080808u; /* R8 */
*--sp = (cpu_data_t)0x07070707u; /* R7 */
*--sp = (cpu_data_t)0x06060606u; /* R6 */
*--sp = (cpu_data_t)0x05050505u; /* R5 */
*--sp = (cpu_data_t)0x04040404u; /* R4 */
return (k_stack_t *)sp;
}Найти задачу с наивысшим приоритетом
Если только одна операционная система имеет высокий приоритет задача а может 立即получить процессоры и с характеристиками реализации, то это еще не операционная система реального времени. Из - за этого находит самый высокий процесс планирования приоритетной задачей определяет , является ли детерминированный время, он просто может быть использован , 时间复杂度чтобы описать его, если система находит наивысший приоритет задачу времени O(N), поэтому на этот раз изменяться в зависимости от числа задач увеличивает рост, что не желательно, TencentOS tinyвремя сложность , O(1)что обеспечивает два способа найти задачу с наивысшим приоритетом, по TOS_CFG_CPU_LEAD_ZEROS_ASM_PRESENTопределению определяет макрос.
- Первый общий метод состоит в использовании, в соответствии с готовым список
k_rdyq.prio_mask[]определяется , является ли соответствующий бит установлен переменным. - Второй способ представляет собой специальный метод, с помощью ведущего нуля рассчитывается инструкции
CLZнепосредственноk_rdyq.prio_mask[]на32нарисованной позиции с наивысшим приоритетом битов , в которых переменные непосредственно, этот метод является более эффективным , чем обычным способом,但受限于平台(ведущий ноль инструкции требуется оборудование, в STM32, мы можем использовать этот метод).
Процесс реализации следует, рекомендуется , чтобы увидеть readyqueue_prio_highest_getфункцию, его реализация все еще очень тонкий ~
__STATIC__ k_prio_t readyqueue_prio_highest_get(void)
{
uint32_t *tbl;
k_prio_t prio;
prio = 0;
tbl = &k_rdyq.prio_mask[0];
while (*tbl == 0) {
prio += K_PRIO_TBL_SLOT_SIZE;
++tbl;
}
prio += tos_cpu_clz(*tbl);
return prio;
}__API__ uint32_t tos_cpu_clz(uint32_t val)
{
#if defined(TOS_CFG_CPU_LEAD_ZEROS_ASM_PRESENT) && (TOS_CFG_CPU_LEAD_ZEROS_ASM_PRESENT == 0u)
uint32_t nbr_lead_zeros = 0;
if (!(val & 0XFFFF0000)) {
val <<= 16;
nbr_lead_zeros += 16;
}
if (!(val & 0XFF000000)) {
val <<= 8;
nbr_lead_zeros += 8;
}
if (!(val & 0XF0000000)) {
val <<= 4;
nbr_lead_zeros += 4;
}
if (!(val & 0XC0000000)) {
val <<= 2;
nbr_lead_zeros += 2;
}
if (!(val & 0X80000000)) {
nbr_lead_zeros += 1;
}
if (!val) {
nbr_lead_zeros += 1;
}
return (nbr_lead_zeros);
#else
return port_clz(val);
#endif
}Реализация переключения задач
Мы также знаем , с фронта, переключение задачи PendSVосуществляется в прерывание, прерывание осуществляется как обобщение содержания сущности слова выше сохранить, переключатель ниже , прямой взгляд на исходный код:
PendSV_Handler
CPSID I
MRS R0, PSP
_context_save
; R0-R3, R12, LR, PC, xPSR is saved automatically here
IF {FPU} != "SoftVFP"
; is it extended frame?
TST LR, #0x10
IT EQ
VSTMDBEQ R0!, {S16 - S31}
; S0 - S16, FPSCR saved automatically here
; save EXC_RETURN
STMFD R0!, {LR}
ENDIF
; save remaining regs r4-11 on process stack
STMFD R0!, {R4 - R11}
; k_curr_task->sp = PSP
MOV32 R5, k_curr_task
LDR R6, [R5]
; R0 is SP of process being switched out
STR R0, [R6]
_context_restore
; k_curr_task = k_next_task
MOV32 R1, k_next_task
LDR R2, [R1]
STR R2, [R5]
; R0 = k_next_task->sp
LDR R0, [R2]
; restore R4 - R11
LDMFD R0!, {R4 - R11}
IF {FPU} != "SoftVFP"
; restore EXC_RETURN
LDMFD R0!, {LR}
; is it extended frame?
TST LR, #0x10
IT EQ
VLDMIAEQ R0!, {S16 - S31}
ENDIF
; Load PSP with new process SP
MSR PSP, R0
CPSIE I
; R0-R3, R12, LR, PC, xPSR restored automatically here
; S0 - S16, FPSCR restored automatically here if FPCA = 1
BX LR
ALIGN
ENDPSPЗначение , сохраненное R0. При входе PendSVC_Handler, операционная среда на задаче , которая является: xPSR,PC(任务入口地址),R14,R12,R3,R2,R1,R0регистры процессора будут 自动сохранены в стеке задания, в этом случае указатель был обновлен автоматически PSP. В то время как все остальные r4~r11нужно 手动сохранить, и именно поэтому вы хотите PendSVC_Handlerсохранить выше ( _context_save) из основных причин не будет автоматически загружать сохраненные регистры процессора, который был вдавлен в стеке задачи.
Затем найти задачу , которая будет выполняться в следующем k_next_task, он будет загружен в стек задачах R0, новой задаче , а затем вручную укладывает содержимое ( в данном описании означает R4~R11) загружают в CPUнабор регистров, это переключение контекста, конечно, нет других содержание метода сохраняется автоматически загружаются вручную в CPUбанк регистров. После загрузки по эксплуатации, на этот раз R0был обновлен, обновленное значение выхода PSP, PendSVC_Handlerпрерывание, будет pspиспользоваться в качестве базового адреса, задача стеки остальной части контента ( xPSR,PC(任务入口地址),R14,R12,R3,R2,R1,R0) автоматически загружаются в регистры процессора.
В самом деле, когда происходит исключение, R14 сохраняется ненормальный возврат флаг, в том числе возвращения после входа в режиме режима задачи или процессора, использовать PSP указателя стека или указатель стек MSP. В этом случае равна R14 0xFFFFFFFD, задний наиболее задача обратно в аномальном режиме (после того, как PendSVC_Handlerприоритет является наименьшим, возвращается к задаче), ИП PSP в качестве указателя стека в стек, стек после завершения PSPуказывает на верхней части задачи стека. Когда команда вызова BX R14, система , PSPкак SPуказатель стека, стек задача новой задачи для запуска следующей загрузки в оставшемся содержимое регистров процессора: R0、R1、R2、R3、R12、R14(LR)、R15(PC)和xPSRпереключиться на новую задачу.
SysTick
инициализация SysTick
SysTick основана система, и это ядро часы, до тех пор , как M0/M3/M4/M7ядро будет представлять systickсобой часы, и он запрограммирован быть сконфигурирован, что обеспечивает большое удобство для миграции операционной системы.
TencentOS tinyБудет ли cpu_initв функции systickинициализации, то есть, он вызывает cpu_systick_initфункцию, таким образом , нет необходимости писать USER- systickинициализации соответствующий код.
__KERNEL__ void cpu_init(void)
{
k_cpu_cycle_per_tick = TOS_CFG_CPU_CLOCK / k_cpu_tick_per_second;
cpu_systick_init(k_cpu_cycle_per_tick);
#if (TOS_CFG_CPU_HRTIMER_EN > 0)
tos_cpu_hrtimer_init();
#endif
}__KERNEL__ void cpu_systick_init(k_cycle_t cycle_per_tick)
{
port_systick_priority_set(TOS_CFG_CPU_SYSTICK_PRIO);
port_systick_config(cycle_per_tick);
}SysTick прерывание
SysTickПрерывание функции обслуживания является необходимостью писать наши собственные, чтобы называться внутри смотреть на TencentOS tinyфункцию , связанные, обновление системы для запуска базы, систем привода от SysTick_Handlerфункции трансплантата выглядит следующим образом :
void SysTick_Handler(void)
{
HAL_IncTick();
if (tos_knl_is_running())
{
tos_knl_irq_enter();
tos_tick_handler();
tos_knl_irq_leave();
}
}В основном нужно вызывать tos_tick_handlerфункцию обновления базовой системы конкретного смотрите:
__API__ void tos_tick_handler(void)
{
if (unlikely(!tos_knl_is_running())) {
return;
}
tick_update((k_tick_t)1u);
#if TOS_CFG_TIMER_EN > 0u && TOS_CFG_TIMER_AS_PROC > 0u
timer_update();
#endif
#if TOS_CFG_ROUND_ROBIN_EN > 0u
robin_sched(k_curr_task->prio);
#endif
}Должно сказать , что TencentOS tinyреализация исходного кода очень проста 我非常喜欢, в tos_tick_handler, сначала определить , что система была запущена, если не работает непосредственно возвращать Если вы запускали, а затем вызвать tick_updateфункцию для обновления базовой системы, если включено TOS_CFG_TIMER_ENпредставление макросов использовать программный таймер, вам необходимо обновить соответствующее лечение, в настоящее время , не говоря уже здесь. Если вы включите TOS_CFG_ROUND_ROBIN_ENмакросы, необходимо также обновить соответствующую временную переменную ломтика, объясню позже.
__KERNEL__ void tick_update(k_tick_t tick)
{
TOS_CPU_CPSR_ALLOC();
k_task_t *first, *task;
k_list_t *curr, *next;
TOS_CPU_INT_DISABLE();
k_tick_count += tick;
if (tos_list_empty(&k_tick_list)) {
TOS_CPU_INT_ENABLE();
return;
}
first = TOS_LIST_FIRST_ENTRY(&k_tick_list, k_task_t, tick_list);
if (first->tick_expires <= tick) {
first->tick_expires = (k_tick_t)0u;
} else {
first->tick_expires -= tick;
TOS_CPU_INT_ENABLE();
return;
}
TOS_LIST_FOR_EACH_SAFE(curr, next, &k_tick_list) {
task = TOS_LIST_ENTRY(curr, k_task_t, tick_list);
if (task->tick_expires > (k_tick_t)0u) {
break;
}
// we are pending on something, but tick's up, no longer waitting
pend_task_wakeup(task, PEND_STATE_TIMEOUT);
}
TOS_CPU_INT_ENABLE();
}tick_updateОсновная функция , чтобы функционировать k_tick_count +1, и судите сами , когда базовый список k_tick_listли задача (она также может быть список задержки) тайм - аут, если тайм - аут , то просыпаются задачу, иначе прямой выход. График работы на листе очень проста, а остальные переменные квант времени задачи timesliceминус один, а затем уменьшается до нуля , когда переменная, переменная вес нагрузки timeslice_reload, и переключение задач knl_sched(), причем этот способ заключается в следующем:
__KERNEL__ void robin_sched(k_prio_t prio)
{
TOS_CPU_CPSR_ALLOC();
k_task_t *task;
if (k_robin_state != TOS_ROBIN_STATE_ENABLED) {
return;
}
TOS_CPU_INT_DISABLE();
task = readyqueue_first_task_get(prio);
if (!task || knl_is_idle(task)) {
TOS_CPU_INT_ENABLE();
return;
}
if (readyqueue_is_prio_onlyone(prio)) {
TOS_CPU_INT_ENABLE();
return;
}
if (knl_is_sched_locked()) {
TOS_CPU_INT_ENABLE();
return;
}
if (task->timeslice > (k_timeslice_t)0u) {
--task->timeslice;
}
if (task->timeslice > (k_timeslice_t)0u) {
TOS_CPU_INT_ENABLE();
return;
}
readyqueue_move_head_to_tail(k_curr_task->prio);
task = readyqueue_first_task_get(prio);
if (task->timeslice_reload == (k_timeslice_t)0u) {
task->timeslice = k_robin_default_timeslice;
} else {
task->timeslice = task->timeslice_reload;
}
TOS_CPU_INT_ENABLE();
knl_sched();
}Я хотел бы сосредоточиться на нем!

Соответствующий номер кода можно получить в общественном фоне.
Для получения дополнительной информации , пожалуйста , концерн «Развитие вещи IoT,» общественность номер!