Использование политики градиента решения задачи дискретного действия пространства.
А, импортировать пакет, определить гипер параметр
импорт тренажерный зал импортировать tensorflow в ТФ импортировать NumPy в нп из коллекции импорта Deque ################# параметры гипер ################, #discount фактор ГАММА = 0,95 LEARNING_RATE = 0,01
Конструктор Два, PolicyGradient Агент:
1, при условии, размеров пространства, государственных операции пространственной размерности;
2, из последовательности структуры для хранения образцов;
3, вызов функции для создания функции политики приближения нейронных сетей, tensorflow сеанс, начальный или нейронные сети веса и смещение.
Защиту __init__ (я, ENV): # self.time_step = 0 # состояние измерения self.state_dim = env.observation_space.shape [0] # измерение действия self.action_dim = env.action_space.n # пример списка self.ep_obs, самостоятельно. ep_as, self.ep_rs = [], [], [] # создание сетевой политики self.create_softmax_network () self.session = tf.InteractiveSession () self.session.run (tf.global_variables_initializer ())
В-третьих, создать нейронную сеть:
Как использовано в данном описании, кросс-энтропии функции ошибки, вычисления градиента функции потерь с использованием нейронной сети. Выход вероятность Софтмакса каждой операции выходного слоя.
tf.nn.sparse_softmax_cross_entropy_with_logits логит вероятность того, функция первого процесса для получения SoftMax нормализации будет Lables одной горячей обработки вектора, а затем найти логит-анализ пересекают энтропию меток:
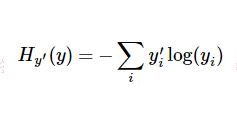
В котором 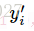
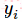
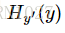
Поэтому, где вы можете получить хорошее понимание (мое понимание): Когда время шага-я момент, более подобные стратегии, если выход вероятности действия вектора сети и время шага я момент выборки, то крест энтропии Это будет меньше. Минимизация кросс-энтропия ошибки будет иметь возможность принимать политические решения ближе к действию нашей сети выборки. И, наконец, умноженная на соответствующем вознаграждении кросса энтропии временного шаге, награда будет размером функции потерь вводятся, энтропийные * вознаграждение больших параметры регулировки, рассчитанные в ходе нейронной сети будут больше в направлении градиента направления.
Защиту create_softmax_network (самостоятельно): W1 = self.weight_variable ([self.state_dim, 20 ]) b1 = self.bias_variable ([20 ]) W2 = self.weight_variable ([20 , self.action_dim]) b2 = self.bias_variable ([self.action_dim]) # Входной слой self.state_input = tf.placeholder (tf.float32, [Отсутствует, self.state_dim]) self.tf_acts = tf.placeholder (tf.int32, [Отсутствует,], имя = ' actions_num ' ) self.tf_vt = tf.placeholder (tf.float32, [Отсутствует,], имя = " actions_value " ) # скрытый слой h_layer = tf.nn.relu (tf.matmul (self.state_input, W1) + b1) # SoftMax слой self.softmax_input = tf.matmul (h_layer, W2) + b2 # SoftMax выход self.all_act_prob = tf.nn.softmax (self.softmax_input, имя = ' act_prob ' ) # кросс энтропии функции потерь self.neg_log_prob = tf.nn. sparse_softmax_cross_entropy_with_logits (логит - анализ = self.softmax_input, лейблы = self.tf_acts) self.loss = tf.reduce_mean (self.neg_log_prob * self.tf_vt) # награда направляется потеря self.train_op = tf.train.AdamOptimizer (LEARNING_RATE) .minimize (self.loss) Защиту weight_variable (самость, форма): начальные = tf.truncated_normal (форма) # усечен нормальное распределение возврат tf.Variable (начальный) Защиту bias_variable (самость, форма): Начальный = tf.constant (0.01, форма = форма) возвращает tf.Variable (начальный)
В-четвертых, последовательность выборки:
Защиту store_transition (я, с, а, г): self.ep_obs.append (ы) self.ep_as.append (а) self.ep_rs.append (г)
В-пятых, модель обучения:
, Нейронная сеть настраивается с помощью полной последовательности выборки Монте-Карло.
Защита узнать (самостоятельно): # оценить стоимость всех государств в настоящее время эпизода discounted_ep_rs = np.zeros_like (self.ep_rs) running_add = 0 для т в обратном (диапазоне (0, LEN (self.ep_rs))): running_add = running_add * ГАММА + self.ep_rs [т] discounted_ep_rs [т] = running_add #normalization discounted_ep_rs - = np.mean (discounted_ep_rs) discounted_ep_rs / = np.std (discounted_ep_rs) # Поезд эпизод self.session.run (self.train_op, feed_dict = { self.state_input: np.vstack (self.ep_obs), self.tf_acts: np.array (self.ep_as), self.tf_vt: discounted_ep_rs, }) self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # пустой эпизод данных
Шесть обучения:
# Hyper Параметры ENV_NAME = ' CartPole-V0 ' ЭПИЗОД = 3000 # Эпизод ограничение ШАГ = 3000 # Шаг ограничение в эпизоде TEST = 10 # Количество теста эксперимента каждый эпизод 100 Защиту главное (): # инициализация OpenAI Gym ENV и DQN агента ENV = gym.make (ENV_NAME) агент = Policy_Gradient (ENV) для эпизода в диапазоне (ЭПИЗОД): # инициализация задачи состояния = env.reset () # Поезд для шага в диапазоне (STEP): действие = agent.choose_action (состояние) # е жадного действия на поезд # принять меры next_state, вознаграждение, сделано, _ = env.step (действие) # образца agent.store_transition (состояние, действие, награда) состояние = next_state если сделано: # печать ( «палка для» шаг, «шаги») # модель обучения после полного образца agent.learn () перерыв # Тест каждые 100 эпизодов , если эпизод% 100 == 0: total_reward = 0 для I в диапазоне (ТЕСТ): состояние = env.reset () для J в диапазоне (ШАГ): env.render () действие = agent.choose_action (состояние) # прямое действие для испытания состояния, награды, сделано, _ = env.step (действие) total_reward + = вознаграждение , если сделано: перерыв ave_reward = total_reward / TEST печать ( ' эпизод: ' , эпизод, ' Оценка Средняя Награда: ' , ave_reward) если __name__ == ' __main__ ' : главный()
ссылка:
https://www.cnblogs.com/pinard/p/10137696.html
https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/policy_gradient.py