
1. История
ZooKeeper (ZK) — это служба координации распределенных приложений, созданная в 2007 году. Хотя по каким-то особым историческим причинам во многих бизнес-сценариях все еще приходится полагаться на него. Например, Kafka, планирование задач и т. д. Особенно когда Flink совмещал развертывание и развязку ETCD, бизнес-сторона требовала абсолютной стабильности и настоятельно рекомендовала не использовать собственный ZooKeeper. Из соображений стабильности используется MSE-ZK от Alibaba. С момента его использования в сентябре 2022 года техническая команда Dewu не столкнулась с какими-либо проблемами со стабильностью, а надежность SLA действительно достигла 99,99%.
В 2023 году некоторые предприятия использовали самостоятельно созданные кластеры ZooKeeper (ZK), а затем ZK испытал несколько колебаний во время использования. Затем Dewu SRE начала брать на себя некоторые самостоятельно созданные кластеры и предприняла несколько попыток повышения стабильности. В ходе процесса поглощения было обнаружено, что после работы ZooKeeper в течение определенного периода времени использование памяти будет продолжать увеличиваться, что может легко привести к проблемам нехватки памяти (OOM). Техническая группа Dewu была очень заинтересована этим явлением и поэтому приняла участие в процессе исследования, чтобы решить эту проблему.
2. Разведка и анализ
2.1 Определитесь с направлением
При устранении проблемы мне очень повезло найти место неисправности в тестовой среде. Два узла в кластере оказались в пограничном состоянии OOM.

В случае с места неисправности до успешной конечной точки обычно остается только 50%. Память находится на верхней стороне. По прошлому опыту либо она некучная, либо проблема в куче. Из графика пламени и jstat можно подтвердить, что это проблема в куче.

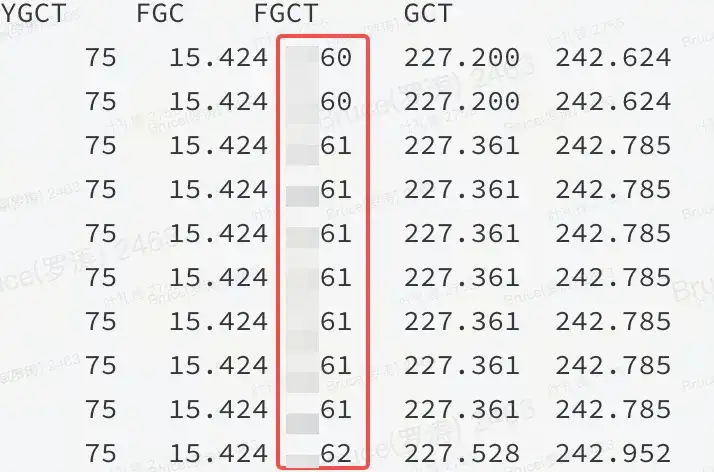
Как показано на рисунке: Это означает, что определенный ресурс в куче JVM занимает большой объем памяти, и FGC не может его освободить.
2.2 Анализ памяти
Чтобы изучить распределение использования памяти в куче JVM, техническая группа Dewu немедленно сделала дамп кучи JVM. Анализ показал, что память JVM сильно занята дочерними наблюдениями и наблюдениями за данными.
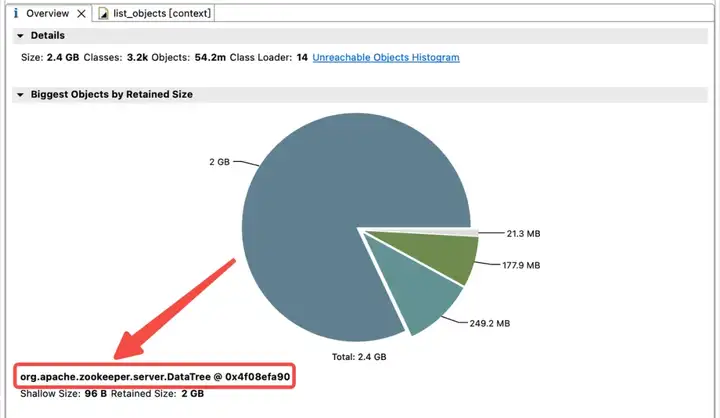
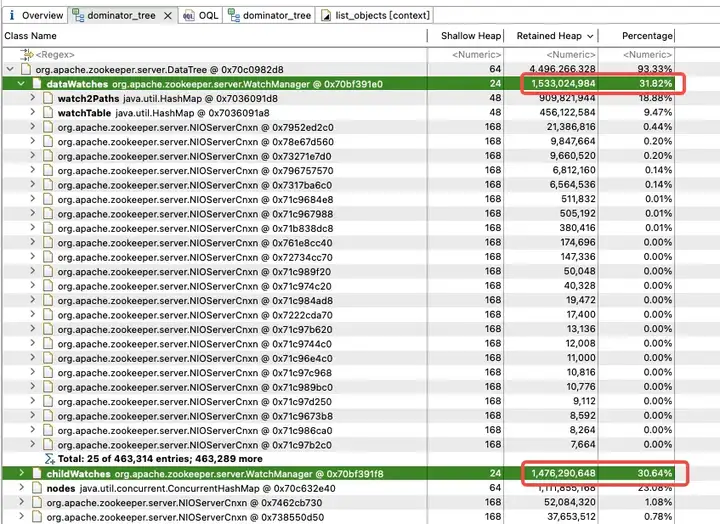
dataWatches: отслеживание изменений в данных узла znode.
childWatches: отслеживайте изменения в структуре узла znode (дереве).
childWatches и dataWatches происходят из WatcherManager.
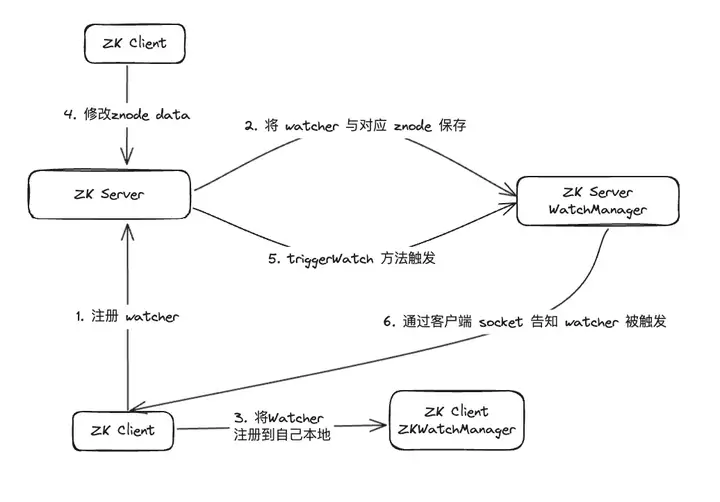
После исследования данных выяснилось, что WatcherManager в основном отвечает за управление Watcher. Клиент ZooKeeper (ZK) сначала регистрирует наблюдателей на сервере ZooKeeper, а затем сервер ZooKeeper использует WatcherManager для управления всеми наблюдателями. Когда данные Znode изменяются, WatchManager запускает соответствующий Watcher и связывается с сокетом клиента ZooKeeper, подписанного на Znode. Впоследствии диспетчер Watch клиента инициирует соответствующий обратный вызов Watcher для выполнения соответствующей логики обработки, тем самым завершая весь процесс публикации/подписки данных.
Дальнейший анализ WatchManager показывает, что соотношение памяти переменных-членов Watch2Path и WatchTables достигает (18,88+9,47)/31,82 = 90%.
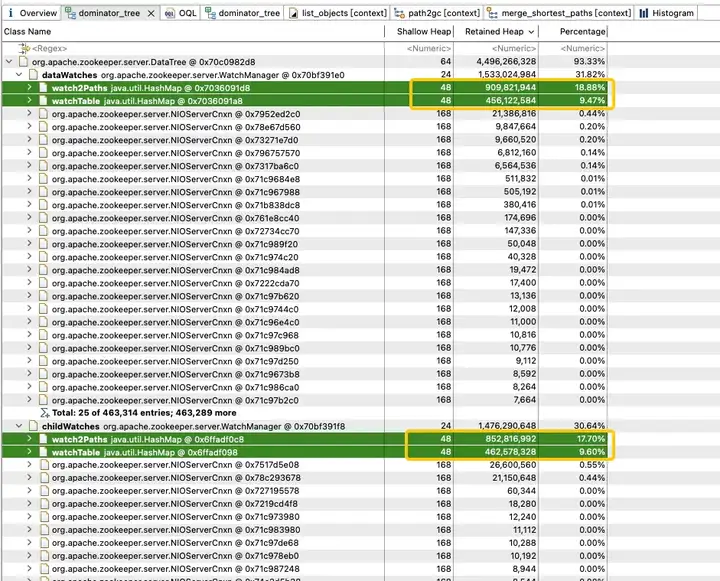
WatchTables и Watch2Path хранят точные отношения сопоставления между ZNode и Watcher, как показано на диаграмме структуры хранения:
WatchTables [таблица прямого запроса] HashMap>
Сценарий: при изменении ZNode наблюдатель, подписанный на ZNode, получит уведомление.
Логика: используйте этот ZNode, чтобы найти все соответствующие списки Watcher через WatchTables, а затем отправлять уведомления одно за другим.
Watch2Paths [таблица обратных запросов]
Сценарий HashMap
: подсчитайте, на какие ZNodes подписан определенный наблюдатель.
Логика: используйте этот наблюдатель, чтобы найти все соответствующие списки ZNode через Watch2Paths.
Watcher — это, по сути, NIOServerCnxn, который можно понимать как сеанс соединения.
Если количество ZNodes и Watcher относительно велико, и клиент подписывается на большее количество ZNodes, даже на полную подписку. Отношения, записанные в этих двух хэш-таблицах, будут расти в геометрической прогрессии и в конечном итоге достигнут заоблачного объема!
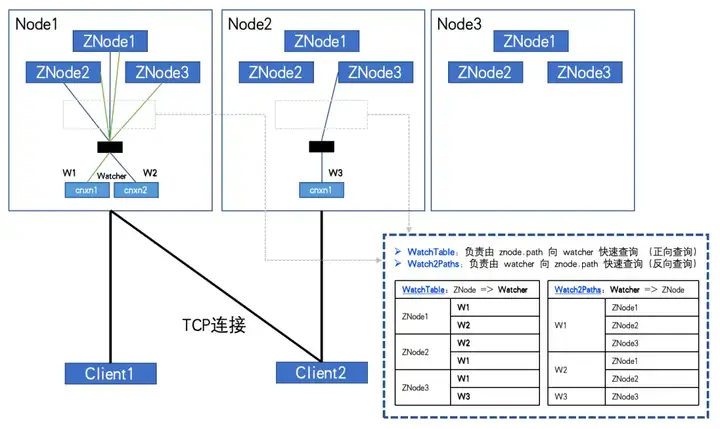
При полной подписке, как показано на рисунке:
Когда количество ZNodes: 3, количество Watcher: 2, WatchTables и Watch2Paths будут иметь по 6 связей.
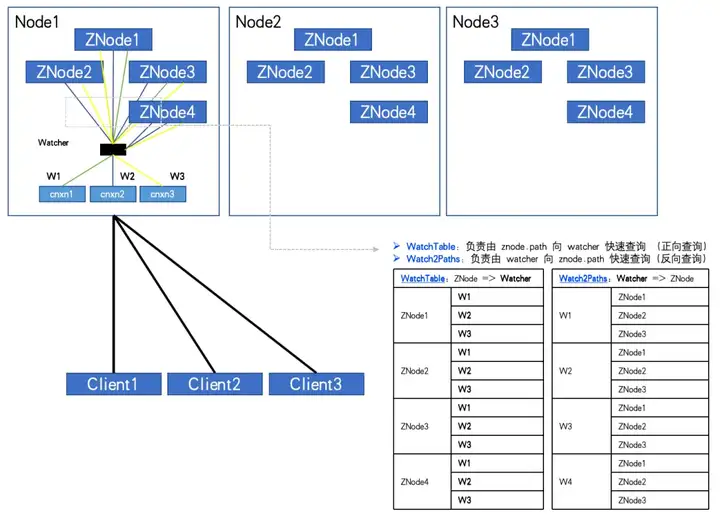
Когда количество ZNodes: 4, количество Watcher: 3, WatchTables и Watch2Paths будут иметь по 12 связей.
В ходе мониторинга был обнаружен аномальный ZK-узел. Количество ZNodes составляет около 20 Вт, а количество Watcher — 5000. Число связей между Watcher и ZNode достигло 100 миллионов.
Если для хранения каждой связи требуется один HashMap&Node (32 байта), поскольку существует две таблицы отношений, удвойте ее. Тогда не рассчитывайте ничего больше. Одна только эта «оболочка» требует 2*10000^2*32/1024^3 = 5,9 ГБ недопустимых затрат памяти.
2.3 Неожиданное открытие
Из приведенного выше анализа мы можем понять, что необходимо избегать полной подписки клиента на все ZNodes. Однако реальность такова, что многие бизнес-коды имеют такую логику, позволяющую проходить все узлы ZNodes, начиная с корневого узла ZTree, и полностью подписываться на них.
Возможно, удастся убедить некоторых деловых партнеров внести улучшения, но нельзя заставить ограничить использование всех деловых сторон. Поэтому решение этой проблемы заключается в мониторинге и профилактике. Однако, к сожалению, сам ZK не поддерживает такую функцию, что требует модификации исходного кода ZK.
Путём отслеживания и анализа исходного кода было установлено, что корень проблемы указывал на WatchManager, а логические детали этого класса были тщательно изучены. После более глубокого понимания я обнаружил, что качество этого кода было похоже на то, что его написал недавний выпускник, и было много нецелесообразного использования потоков и блокировок. Просматривая записи Git, мы обнаружили, что эта проблема возникла еще в 2007 году. Однако что интересно, в этот период времени появился WatchManagerOptimized (2018). Путем поиска информации сообщества ZK был обнаружен [ZOOKEEPER-1177]. То есть в 2011 году сообщество ZK осознало, что большое количество. Часы вызвали проблему с объемом памяти и, наконец, нашли решение в 2018 году. Именно из-за этого WatchManagerOptimized кажется, что сообщество ZK его уже оптимизировало.
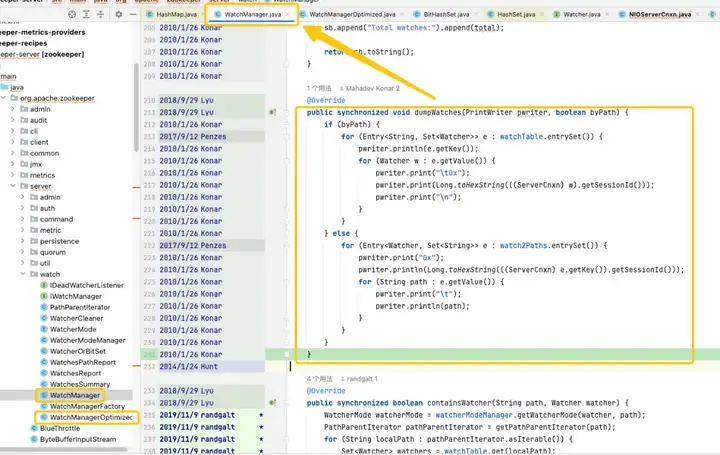
Интересно, что ZK не включает этот класс по умолчанию, даже в последней версии 3.9.X WatchManager по-прежнему используется по умолчанию. Возможно, из-за того, что ZK настолько стар, люди постепенно обращают на него меньше внимания. Опрос коллег из Alibaba подтвердил, что MSE-ZK также включил WatchManagerOptimized, что еще раз подтвердило, что техническая команда Dewu сосредоточила внимание в правильном направлении.
2.4 Исследование оптимизации
Оптимизация блокировки
В версии по умолчанию используемый HashSet не является потокобезопасным. В этой версии связанные методы операций, такие как addWatch, RemoveWatcher и TriggerWatch, реализованы путем добавления к методам синхронизированных тяжелых блокировок. В оптимизированной версии используется комбинация ConcurrentHashMap и ReadWriteLock для более совершенного использования механизма блокировки. Таким образом, можно добиться более эффективных операций в процессе добавления и запуска Watch.
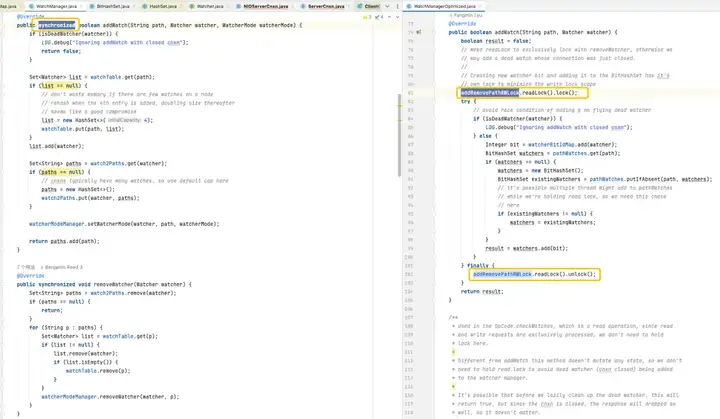
Оптимизация хранилища
Это фокус. Из анализа WatchManager мы видим, что эффективность хранения при использовании WatchTables и Watch2Paths невысока. Если у ZNode много отношений подписки, будет использовано большое количество дополнительной недопустимой памяти.
Удивительно, но WatchManagerOptimized использует здесь «черную технологию» -> растровое изображение.
Реляционное хранилище сильно сжимается с использованием растровых изображений для оптимизации уменьшения размерности.
Основные возможности Java BitSet:
- Экономия места: BitSet использует битовые массивы для хранения данных, требуя меньше места, чем стандартные логические массивы.
- Быстрая обработка: выполнение побитовых операций (таких как AND, OR, XOR, переворот) часто происходит быстрее, чем соответствующие логические операции.
- Динамическое расширение: размер BitSet может динамически увеличиваться по мере необходимости для размещения большего количества битов.
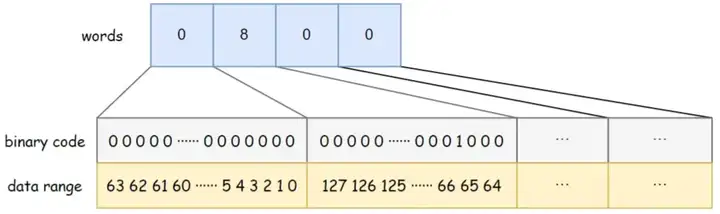
BitSet использует слова long[] для хранения данных. Тип long занимает 8 байт и составляет 64 бита . Каждый элемент массива может хранить 64 фрагмента данных. Порядок хранения данных в массиве — слева направо, от младшего к старшему. Например, разрядность BitSet на рисунке ниже равна 4, слова [0] от низкого к высокому указывают, существуют ли данные 0–63, слова [1] от низкого к высокому указывают, существуют ли данные 64–127, и так на. Среди них слова [1] = 8, а соответствующий двоичный бит 8 равен 1, что указывает на то, что в данный момент в BitSet хранятся данные {67}.
WatchManagerOptimized использует BitMap для хранения всех наблюдателей. Таким образом, даже если есть 1W Watcher. Потребление памяти растровым изображением составляет всего 8 байт * 1 Вт/64/1024 = 1,2 КБ . При замене на HashSet потребуется не менее 32 байт * 10000/1024 = 305 КБ, а эффективность хранения будет отличаться почти в 300 раз.
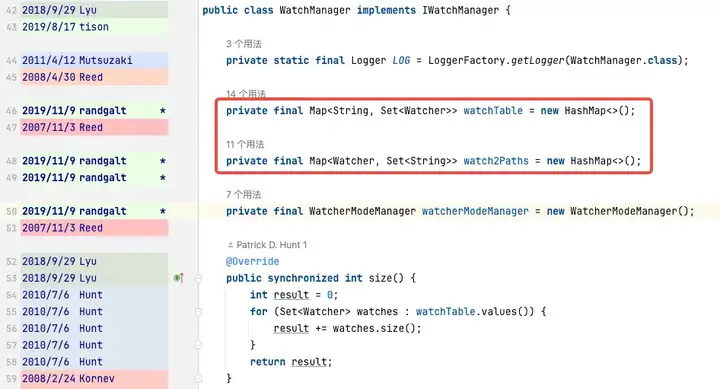
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
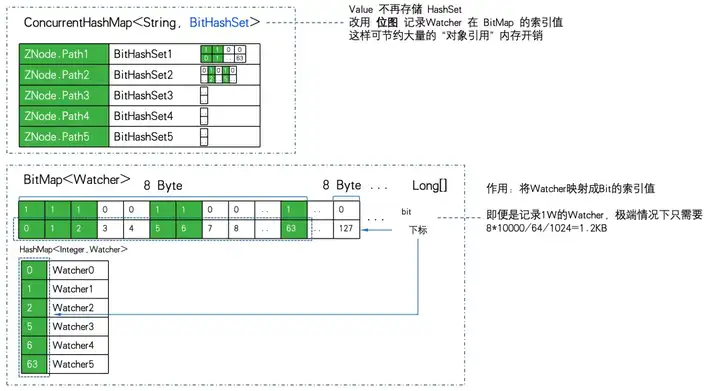
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();Хранилище сопоставлений с ZNode на Watcher изменено с Map на ConcurrentHashMapBitHashSet>. То есть набор больше не сохраняется, а растровое изображение используется для хранения значения индекса растрового изображения.
Используйте 1W ZNode, 1W Watcher и перейдите к крайней точке полной подписки (все наблюдатели подписываются на все ZNodes), чтобы обеспечить эффективность хранения PK:

Вы можете видеть, что 11,7 МБ ПК 5,9 ГБ , разница в эффективности хранения данных составляет: 516 раз .
Оптимизация логики
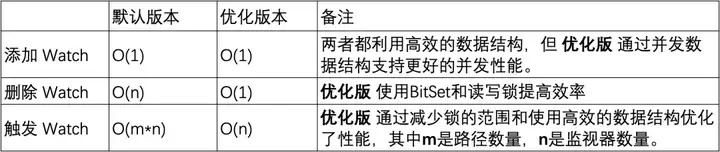
Добавление монитора: обе версии могут выполнять операции за постоянное время, но оптимизированная версия обеспечивает лучшую производительность одновременного выполнения за счет использования ConcurrentHashMap .
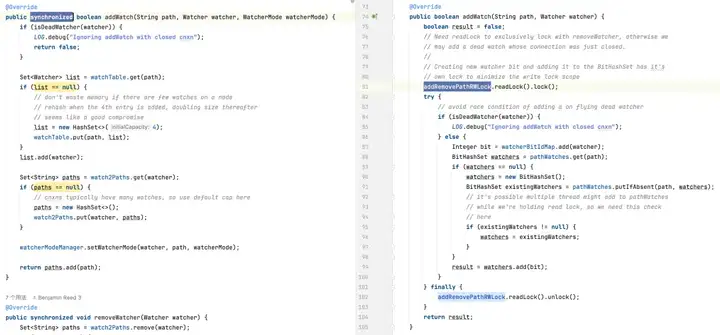
Удаление монитора: версии по умолчанию может потребоваться просмотреть всю коллекцию мониторов, чтобы найти и удалить монитор, что приводит к временной сложности O(n). Оптимизированная версия использует BitSet и ConcurrentHashMap для быстрого поиска и удаления мониторов в большинстве случаев за O(1).
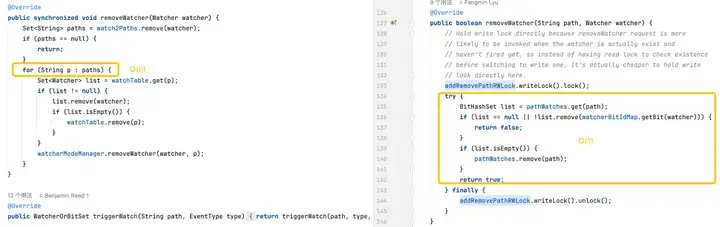
Запуск мониторов. Версия по умолчанию более сложна, поскольку требует операций на каждом мониторе на каждом пути. Оптимизированная версия оптимизирует производительность мониторов триггеров за счет более эффективных структур данных и сокращения использования блокировок.
3. Стресс-тест производительности
3.1 Микробенчмарк JMH
Компиляция исходного кода ZooKeeper 3.6.4, стресс-тест JMH micor WatchBench.
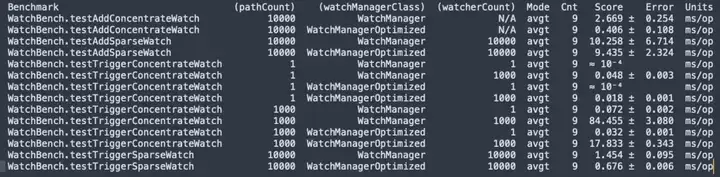
pathCount: указывает количество путей ZNode, использованных в тесте. watchManagerClass: представляет класс реализации WatchManager, использованный в тесте.
watcherCount: указывает количество наблюдателей (наблюдателей), использованных в тесте.
Режим: указывает тестовый режим, здесь avgt, который указывает среднее время работы.
Cnt: указывает количество запусков тестов.
Оценка: указывает оценку теста, то есть среднее время выполнения.
Ошибка: указывает диапазон ошибок оценки.
Единицы измерения: единица измерения оценки, здесь — миллисекунды/операция (мс/оп).
- Между ZNode и Watcher имеется 1 миллион подписок. Версия по умолчанию использует 50 МБ, а оптимизированная версия требует только 0,2 МБ, и она не будет увеличиваться линейно.
- Если добавить Watch, оптимизированная версия (0,406 мс/опер) будет в 6,5 раз быстрее версии по умолчанию (2,669 мс/опер).
- Запускается большое количество часов, а оптимизированная версия (17,833 мс/опер) работает в 5 раз быстрее, чем версия по умолчанию (84,455 мс/опер).
3.2 Стресс-тест производительности
Затем на машине (32C 60G) был собран набор трехузлового ZooKeeper 3.6.4, а оптимизированная версия и версия по умолчанию использовались для сравнения производительности в стресс-тестах.
Сценарий 1: короткий путь znode мощностью 20 Вт.
Короткий путь Znode: /demo/znode1

Сценарий 2: длинный путь znode мощностью 20 Вт.
Длинный путь Znode: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- Использование контрольной памяти связано с длиной пути ZNode.
- Количество Watches линейно увеличивается в версии по умолчанию и работает очень хорошо в оптимизированной версии, что является очевидным улучшением оптимизации использования памяти.
3.3 Тест оттенков серого
На основе предыдущего эталонного теста и теста емкости оптимизированная версия имеет очевидную оптимизацию памяти в большом количестве сценариев наблюдения. Затем мы начали проводить тестовые наблюдения по обновлению в оттенках серого на кластере ZK в тестовой среде.
Первый кластер ZooKeeper и преимущества
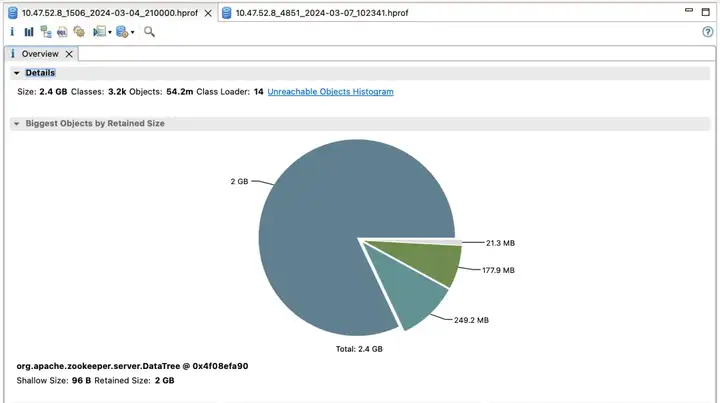
Версия по умолчанию
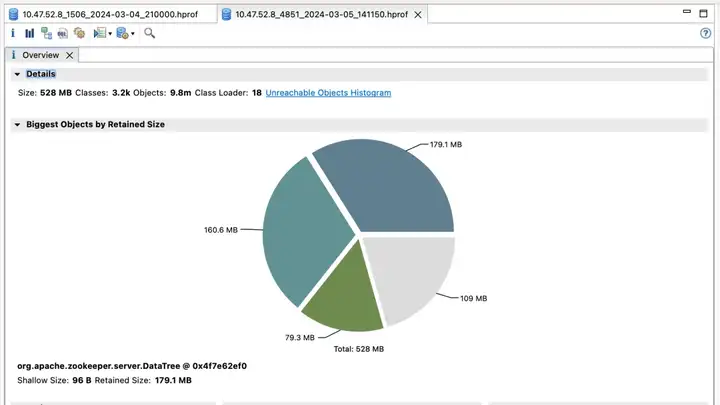
Оптимизированная версия


Доход от эффекта:
- Election_time (время выборов): уменьшено на 60%
- fsync_time (время синхронизации транзакций): уменьшено на 75%.
- Использование памяти: уменьшено на 91 %
Второй кластер ZooKeeper и преимущества
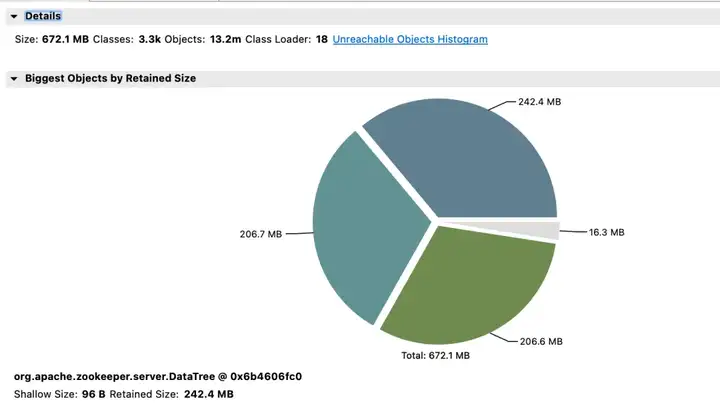
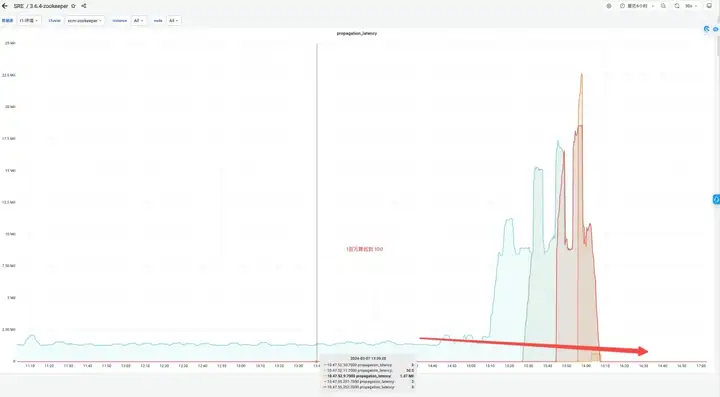


Доход от эффекта:
- Память: до изменения ответ JVM Attach не отвечал и не удалось собрать данные.
- Election_time (время выборов): уменьшено на 64%.
- max_latency (задержка чтения): уменьшена на 53%.
- Offer_latency (задержка предложения при обработке выборов): 1400000 мс --> 43 мс.
- propagation_latency (задержка распространения данных): 1400000 мс --> 43 мс.
Третий набор кластера и преимуществ ZooKeeper
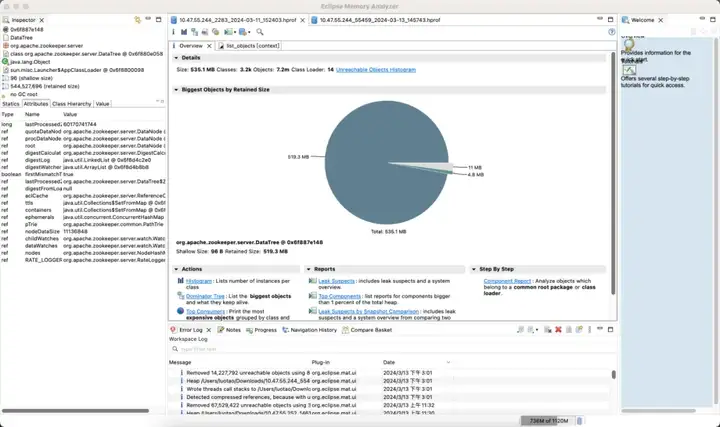
Версия по умолчанию
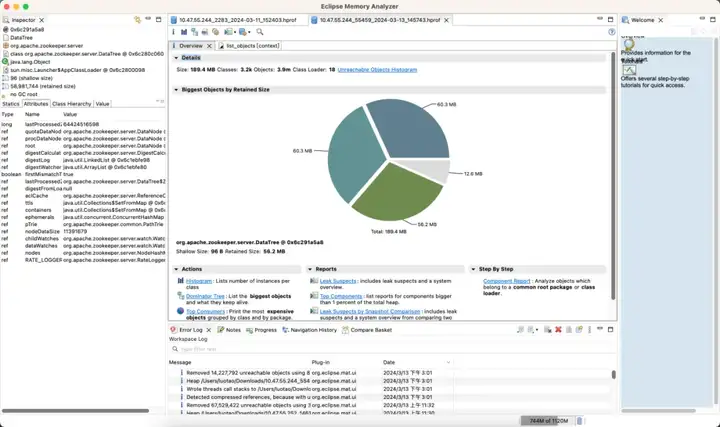
Оптимизированная версия
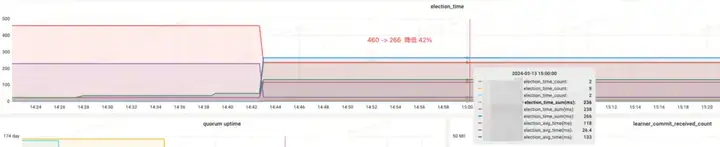

Доход от эффекта:
- Память: сэкономьте 89%
- Election_time (время выборов): уменьшено на 42%
- max_latency (задержка чтения): уменьшено на 95 %.
- Offer_latency (задержка предложения обработки выборов): 679999 мс --> 0,3 мс
- propagation_latency (задержка распространения данных): 928000 мс --> 5 мс
4. Резюме
В ходе предыдущих тестов производительности, стресс-тестов производительности и тестов оттенков серого был обнаружен WatchManagerOptimized ZooKeeper. Эта оптимизация не только экономит память, но и значительно улучшает такие показатели, как выборы и синхронизация данных между узлами, за счет оптимизации блокировок, тем самым повышая согласованность ZooKeeper. Мы также провели углубленный обмен мнениями со студентами из Alibaba MSE, каждый из которых моделировал стресс-тестирование в экстремальных сценариях, и пришли к единому мнению: WatchManagerOptimized значительно повышает стабильность ZooKeeper. В целом, эта оптимизация на порядок улучшает соглашение об уровне обслуживания ZooKeeper.
ZooKeeper имеет множество вариантов конфигурации, но в большинстве случаев никаких настроек не требуется. Для повышения стабильности системы рекомендуется выполнить следующие оптимизации конфигурации:
- Подключите dataDir (каталог данных) и dataLogDir (каталог журнала транзакций) к разным дискам соответственно и используйте высокопроизводительное блочное хранилище.
- Для ZooKeeper версии 3.8 рекомендуется использовать JDK 17 и включить сборщик мусора ZGC, для версий 3.5 и 3.6 рекомендуется использовать JDK 8 и включить сборщик мусора G1; Для этих версий просто настройте -Xms и -Xmx.
- Измените значение параметра SnapshotCount по умолчанию от 100 000 до 500 000, что может значительно снизить нагрузку на диск, когда ZNode изменяется на высоких частотах.
- Используйте оптимизированную версию Watch Manager WatchManagerOptimized.
Эта статья является оригинальным контентом Alibaba Cloud и не может быть воспроизведена без разрешения.
Старшеклассники создают свой собственный язык программирования с открытым исходным кодом в качестве церемонии совершеннолетия – резкие комментарии пользователей сети: Опираясь на защиту, Apple выпустила чип M4 RustDesk. Внутренние услуги были приостановлены из-за безудержного мошенничества. Юнфэн ушел из Alibaba. В будущем он планирует выпустить независимую игру на платформе Windows Taobao (taobao.com). Возобновить работу по оптимизации веб-версии, место назначения программистов, Visual Studio Code 1.89 выпускает Java 17, наиболее часто используемую версию Java LTS, в Windows 10 есть доля рынка составляет 70%, Windows 11 продолжает снижаться. Open Source Daily | Google поддерживает Hongmeng, чтобы взять на себя управление; Rabbit R1 с открытым исходным кодом поддерживает телефоны Android. Microsoft Haier Electric закрыла открытую платформу;