

Благодаря углубленному изучению приложений крупномасштабных моделей технология поисковой дополненной генерации получила широкое внимание и применялась в различных сценариях, таких как вопросы и ответы в базе знаний, юридические консультанты, помощники по обучению, роботы веб-сайтов и т. д.
Однако многие друзья не совсем понимают взаимосвязь и технические принципы векторных баз данных и RAG. Эта статья даст вам глубокое понимание новой векторной базы данных в эпоху RAG.
01.
Широкий спектр применения RAG и его уникальные преимущества
Типичную структуру RAG можно разделить на две части: Retriever и Generator. Процесс поиска включает в себя сегментацию данных (например, документы), внедрение векторов (вложение) и построение индексов (фрагменты векторов), а затем соответствующие результаты вызываются посредством векторного поиска. , а процесс генерации использует расширенный запрос на основе результатов поиска (Контекст) для активации LLM для генерации ответов (Результат).
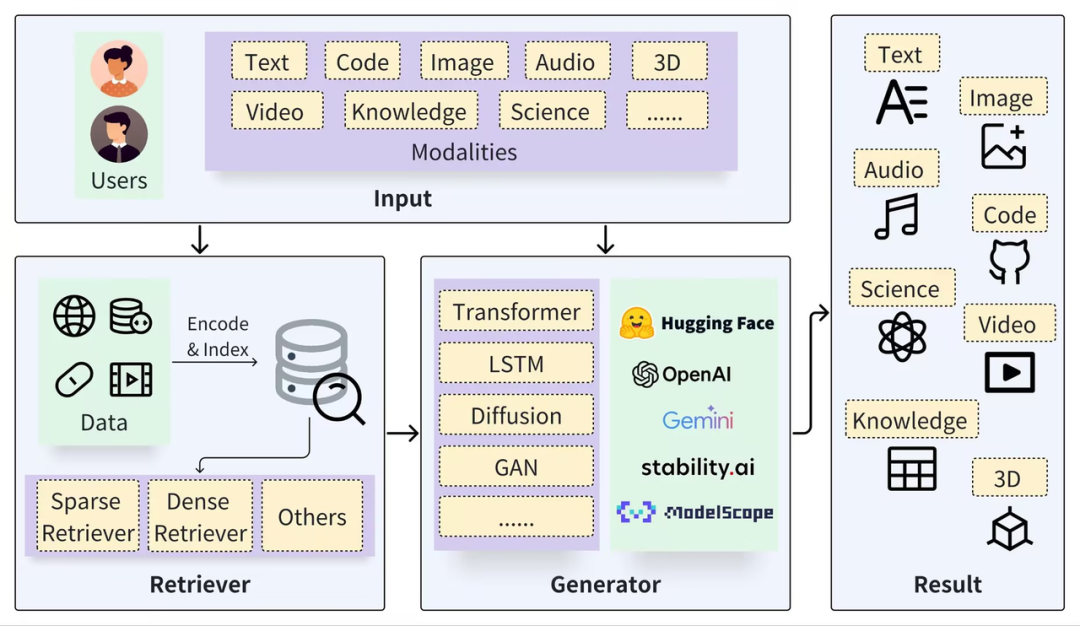
https://arxiv.org/pdf/2402.19473
Ключом к технологии RAG является то, что она сочетает в себе лучшее из обоих подходов: поисковую систему, которая предоставляет конкретные, актуальные факты и данные, и генеративную модель, которая гибко строит ответы и включает более широкий контекст и информацию. Эта комбинация делает модель RAG очень эффективной при обработке сложных запросов и генерации информативных ответов, что очень полезно в системах ответов на вопросы, диалоговых системах и других приложениях, требующих понимания и генерации естественного языка. По сравнению с собственными крупномасштабными моделями сочетание с RAG может дать естественные дополнительные преимущества:
Избегайте проблем «галлюцинаций»: RAG помогает крупным моделям отвечать на вопросы, получая внешнюю информацию в качестве входных данных. Этот метод может значительно уменьшить количество вопросов о неточной сгенерированной информации и повысить отслеживаемость ответов.
Конфиденциальность и безопасность данных: RAG может использовать базу знаний в качестве внешнего приложения для управления частными данными предприятия или учреждения, чтобы предотвратить неконтролируемую утечку данных после обучения модели.
Характер информации в режиме реального времени: RAG позволяет извлекать информацию в режиме реального времени из внешних источников данных, что позволяет получить новейшие знания по конкретной предметной области и решить проблему своевременности знаний.
Хотя передовые исследования крупномасштабных моделей также направлены на решение вышеупомянутых проблем, таких как точная настройка на основе частных данных и улучшение возможностей обработки длинных текстов самой модели, эти исследования помогают способствовать развитию крупномасштабных моделей. Технология масштабных моделей. Однако в более общих сценариях RAG по-прежнему остается стабильным, надежным и экономически эффективным выбором, главным образом потому, что RAG имеет следующие преимущества:
Модель белого ящика : по сравнению с эффектом «черного ящика» тонкой настройки и обработки длинного текста, связь между модулями RAG более четкая и тесная, что обеспечивает более высокую работоспособность и интерпретируемость при настройке эффектов, кроме того, при высоком качестве и уверенности; (Надежность) полученного и вызванного контента не высока, система RAG может даже запретить вмешательство LLM и прямо ответить «не знаю» вместо того, чтобы выдумывать ерунду.
Стоимость и скорость ответа: RAG имеет преимущества короткого времени обучения и низкой стоимости по сравнению с точно настроенными моделями по сравнению с обработкой длинного текста, имеет более высокую скорость ответа и гораздо более низкую стоимость вывода; На этапе исследований и экспериментов эффект и точность являются наиболее привлекательными, но с точки зрения промышленности и промышленного внедрения стоимость является решающим фактором, который нельзя игнорировать;
Управление частными данными. Отделяя базу знаний от крупных моделей, RAG не только обеспечивает безопасную и реализуемую практическую основу, но также может лучше управлять существующими и новыми знаниями предприятия и решать проблему зависимости от знаний. Другой связанный с этим аспект — контроль доступа и управление данными, что легко сделать для базовой базы данных RAG, но сложно для больших моделей.
Поэтому, на мой взгляд, по мере углубления исследований крупномасштабных моделей технология RAG не будет заменена, наоборот, она еще долго будет сохранять важную позицию. В основном это связано с его естественной взаимодополняемостью с LLM, что позволяет приложениям, созданным на основе RAG, проявить себя во многих областях. Ключом к улучшению RAG является с одной стороны улучшение возможностей LLM, а с другой стороны оно опирается на различные улучшения и оптимизации поиска (Retrival).
02.
Основа для поиска RAG: векторные базы данных
В отраслевой практике поиск RAG обычно тесно интегрирован с векторными базами данных, что также привело к появлению решения RAG на основе ChatGPT + Vector Database + Prompt, называемого стеком технологий CVP. Это решение использует базы данных векторов для эффективного извлечения соответствующей информации для улучшения больших языковых моделей (LLM). Преобразуя запросы, сгенерированные LLM, в векторы, система RAG может быстро находить соответствующие записи знаний в базе данных векторов. Этот механизм поиска позволяет LLM использовать самую последнюю информацию, хранящуюся в базе данных векторов, при возникновении конкретных проблем, эффективно решая проблемы задержки обновления знаний и иллюзий, присущих LLM.
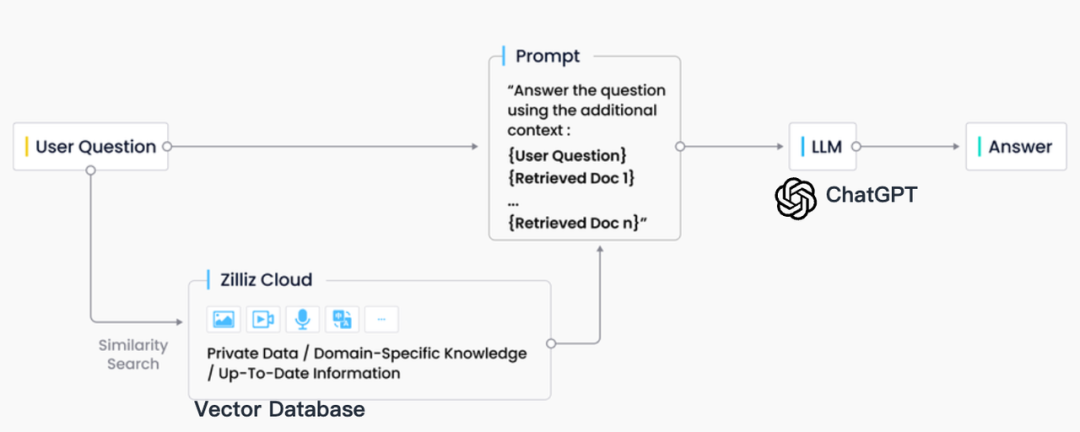
Хотя в области поиска информации существует множество технологий хранения и поиска, включая поисковые системы, реляционные базы данных, базы данных документов и т. д., векторные базы данных стали первым выбором в отрасли в сценариях RAG. За этим выбором стоит превосходная способность векторных баз данных эффективно хранить и извлекать большое количество встроенных векторов. Эти векторы внедрения генерируются моделями машинного обучения и способны не только характеризовать несколько типов данных, таких как текст и изображения, но также собирать их глубокую семантическую информацию. В системе RAG поисковой задачей является быстрый и точный поиск информации, наиболее соответствующей семантике входного запроса, а векторные базы данных выделяются существенными преимуществами при обработке многомерных векторных данных и выполнении быстрого поиска по сходству.
Ниже приводится горизонтальное сравнение векторных баз данных, представленных векторным поиском, с другими техническими вариантами, а также анализ ключевых факторов, которые делают их основным выбором в сценариях RAG:
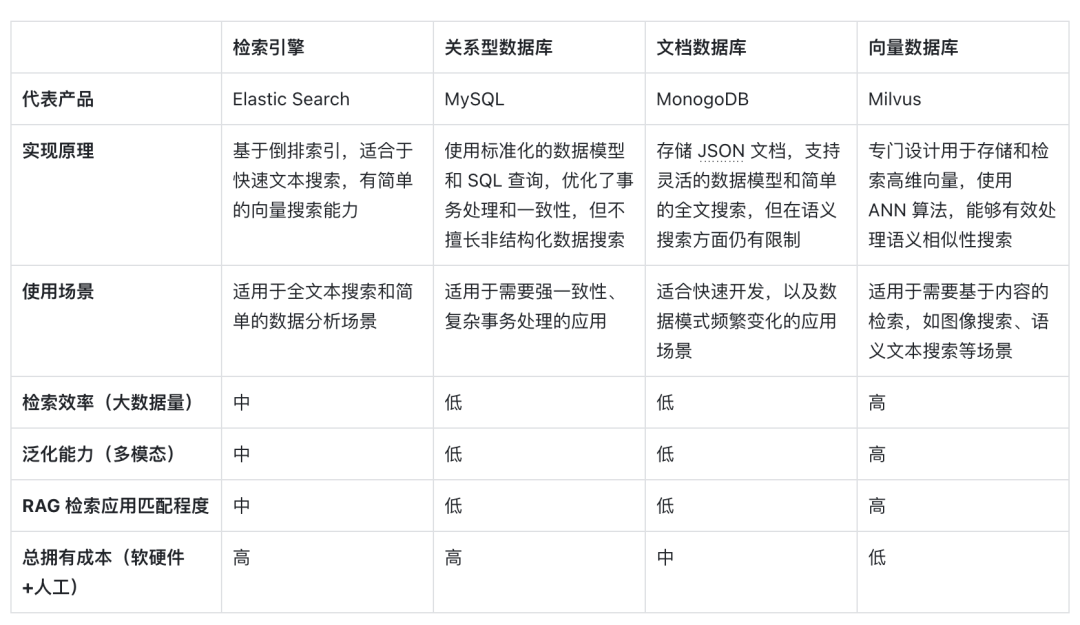
Прежде всего, с точки зрения принципов реализации , векторы представляют собой форму кодирования семантического значения модели. Векторные базы данных могут лучше понимать семантическое содержание запросов, поскольку они используют способность моделей глубокого обучения кодировать значение текста, а не только сопоставление ключевых слов. . Благодаря развитию моделей ИИ семантическая точность, лежащая в основе этого метода, также постоянно улучшается. Использование сходства на векторном расстоянии для выражения семантического сходства превратилось в основную форму НЛП. Поэтому идеографическое внедрение стало первым выбором для обработки носителей информации.
Во-вторых, с точки зрения эффективности поиска , поскольку информация может быть выражена в виде многомерных векторов, к векторам можно добавить специальные методы оптимизации индексов и количественной оценки, что может значительно повысить эффективность поиска и сократить затраты на хранение. Базу данных векторов можно расширять по горизонтали, сохраняя время ответа на запрос, что крайне важно для систем RAG, которым необходимо обрабатывать огромные объемы данных, поэтому базы данных векторов лучше справляются с обработкой очень крупных неструктурированных данных.
Что касается способности к обобщению , большинство традиционных поисковых систем, реляционных или документальных баз данных могут обрабатывать только текст и имеют плохие возможности обобщения и расширения. Векторные базы данных не ограничиваются текстовыми данными, но также могут обрабатывать изображения, аудио и другие неструктурированные данные. . тип вектора внедрения, который делает систему RAG более гибкой и универсальной.
Наконец, с точки зрения общей стоимости владения , по сравнению с другими вариантами, векторные базы данных более удобны в развертывании и проще в использовании. Они также предоставляют богатые API-интерфейсы, что позволяет легко интегрировать их с существующими платформами и рабочими процессами машинного обучения, поэтому они популярны. среди них Фаворит среди многих разработчиков приложений RAG.
Векторный поиск стал идеальным средством извлечения RAG в эпоху больших моделей благодаря своей способности к семантическому пониманию, высокой эффективности поиска и поддержке обобщения для мультимодальностей. С дальнейшим развитием искусственного интеллекта и моделей внедрения эти преимущества могут стать более заметными. в будущем.
03.
Требования к векторным базам данных в сценариях RAG
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
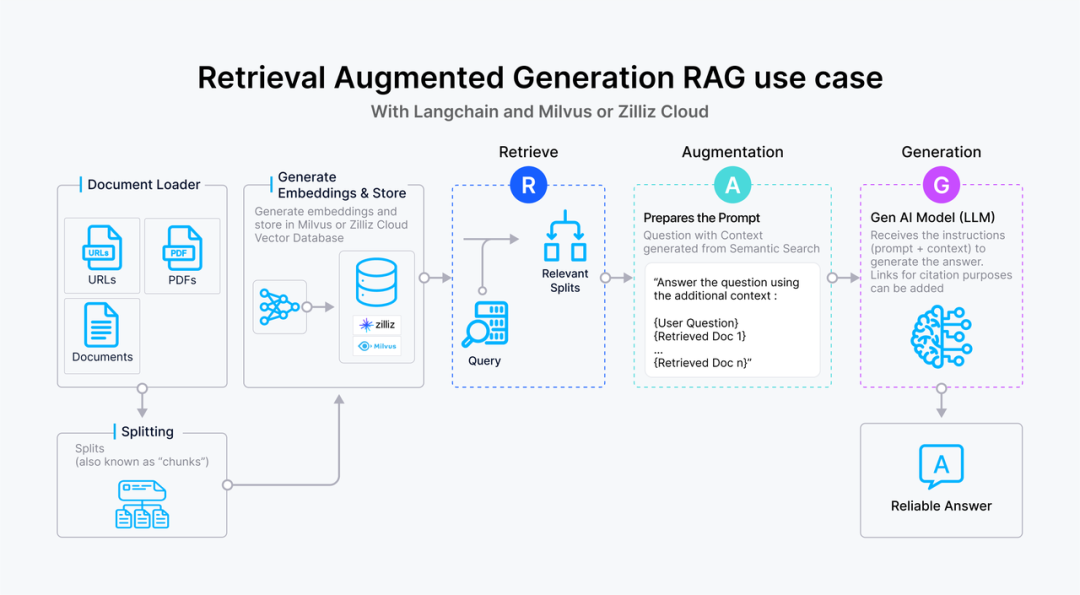
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。