Создать и поддерживать поисковую систему миллиардного уровня непросто, и не существует раз и навсегда оптимального метода управления. Эта статья является результатом непрерывного обучения и практического обобщения. В ней рассказывается, как создать систему поиска, которая может поддерживать продукты от десятков миллионов до сотен миллионов, а также реализовать увеличение общего количества запросов QPS с сотен до тысяч, а также написать. общее количество QPS Процесс повышения от уровня 100 до уровня 10 000. Среди них расширение ресурсов ES имеет важное значение, но, кроме того, в этой статье также будут рассмотрены некоторые проблемы производительности ES, которые не могут быть решены путем расширения. Я надеюсь, что благодаря этой статье вы сможете получить больше данных и ссылок на сценарии использования ES. Из-за ограниченности места часть, посвященная управлению стабильностью, будет представлена в следующей статье.
Введение в бизнес
Система управления инвестициями платформы обслуживает инвестиционный сценарий деятельности платформы электронной коммерции Douyin с участием нескольких субъектов. Она будет собирать и выбирать продукты через инвестиционную платформу, а затем распределять продукты по различным системам C-side. Субъекты, привлекающие инвестиции, также очень разнообразны, включая помещения для прямых трансляций, инвестиции в продукты, купонные инвестиции и т. д. Среди них инвестиции в продукты являются нашей крупнейшей инвестиционной организацией.
Структура обслуживания инвестиционной платформы
Дата центр
Центр обработки данных — это служба поиска на базе ES, которая предоставляет настраиваемые, масштабируемые и универсальные услуги по сбору и оркестрации данных. Это универсальная служба, поддерживающая запросы данных на инвестиционной платформе.
Ключевые понятия, которые нужно понять:
-
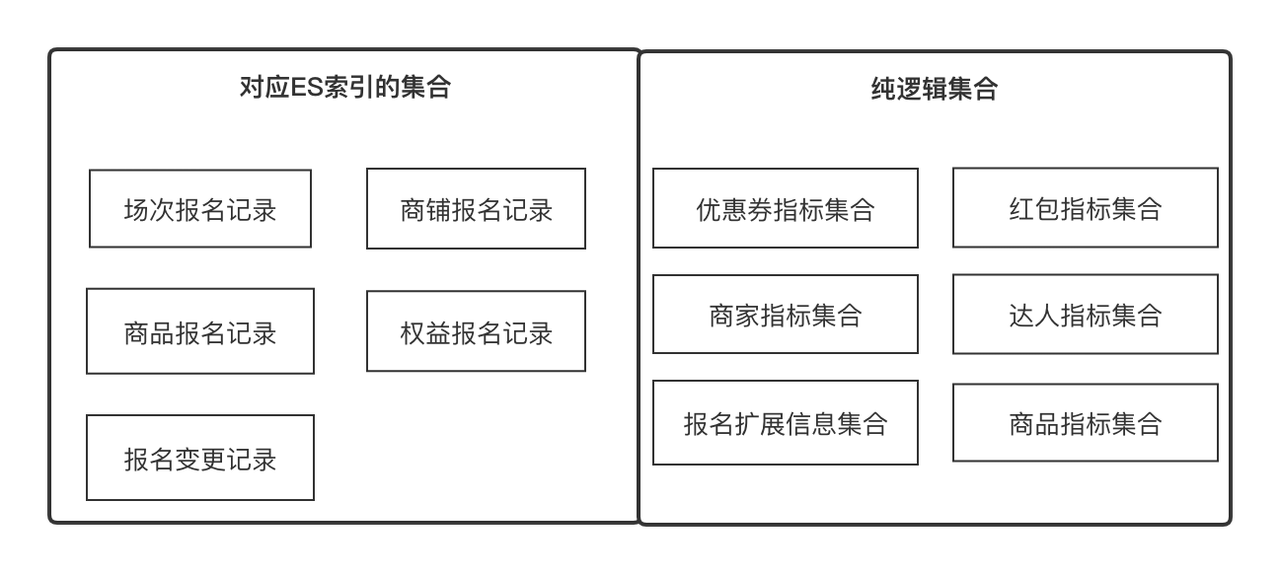
Индикаторы
: Индикаторы — это метаданные, которые мы используем для описания атрибута сущности или объекта, например, названия продукта, оценки качества магазина, экспертного уровня, идентификатора регистрационной записи. В то же время это также может быть минимальное обновление и получение идентификатора. объект. Единица измерения, например информация о сравнении цен на продукты. Мы можем определить все поля с четкой семантикой как индикаторы
.
-
Набор
: представляет собой набор, который можно объединить по некоторой общности, например, набор атрибутов продукта и набор атрибутов магазина, которые можно получить по идентификатору продукта и идентификатору магазина соответственно. Это также может быть коллекция записей о регистрации продукта, которую можно получить с помощью. Идентификатор регистрационной записи. В бизнес-терминах он выражает набор связанных индикаторов, которые находятся в отношении «один-ко-многим».
-
Решение
: Решение для сбора данных. Мы абстрагируем две концепции индикаторов и коллекций, чтобы данные можно было получать в наименьших единицах и постоянно расширять по горизонтали. Решение помогает нам абстрагироваться от того, как получать индикаторы из разных коллекций.
-
Пользовательский заголовок
: Пользовательский заголовок относится к заголовку, который будет отображаться в любом двумерном списке данных строки. Он имеет отношение «один ко многим» с индикатором;
-
Элемент фильтра
: элемент фильтра относится к элементу фильтра, который необходимо использовать в любом двумерном списке данных строки. Он может указывать на отношение 1 к 1;
-
Представление аудита
. Представление аудита относится к странице аудита, которая может динамически отображаться на основе набора настраиваемых заголовков и набора элементов фильтра в бизнес-сценарии аудита.
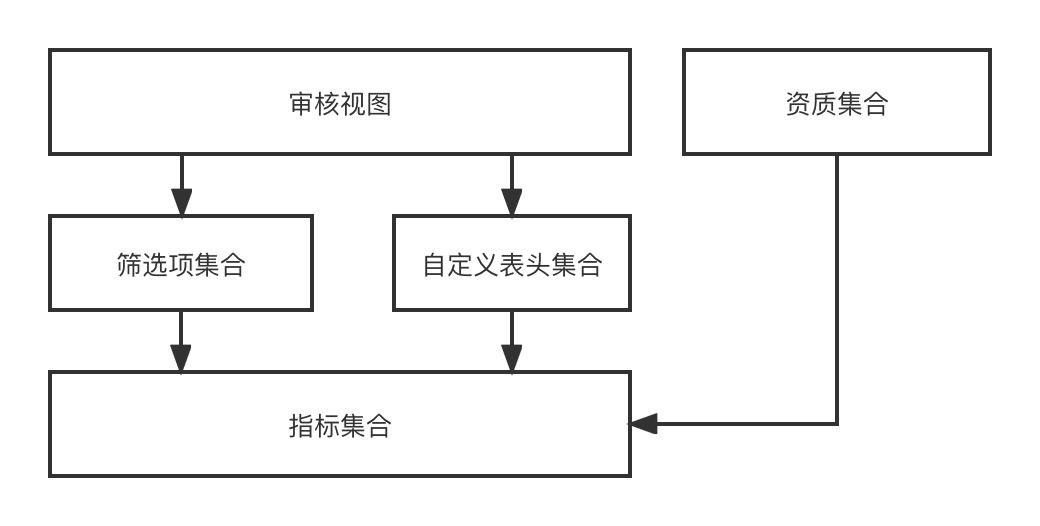
В функциональном дизайне через индикатор -> [Элементы фильтра, пользовательский заголовок] -> Представление аудита -> процесс окончательной динамической визуализации страницы аудита. Поскольку мы привлекаем инвестиции с помощью нескольких объектов и нескольких сценариев, разных объектов. имеют разные сценарии. Требуются разные представления аудита, поэтому разработанная нами серия возможностей может динамически комбинировать любые необходимые эффекты представления аудита.
Центр обработки данных предоставляет общие возможности сбора данных для предприятий верхнего уровня, включая синхронизацию данных и запрос данных. В настоящее время существует два источника данных, внешний интерфейс RPC и регистрационная запись ES. Центр обработки данных объединяет два набора решений по сбору данных и совершенно не осведомлен о внешнем мире, то есть ему нужно только получить какие показатели данных при каком сборе. .
Целью создания ES является поддержка возможностей проверки и статистики записей регистрации инвестиций и вывод содержимого данных, которое необходимо для бизнеса верхнего уровня.
Постройте ES-кластер от 0 до 1
Чтобы построить систему от 0 до 1 на основе удовлетворения основных потребностей бизнеса, стабильность должна поддерживать следующие два пункта:
-
Базовый механизм аварийного восстановления означает, что, когда на производительность системы влияют изменения в основных компонентах и трафике чтения и записи, бизнес может вовремя приспособиться.
-
Окончательная согласованность данных означает, что регистрационная запись DB --> ES данные многомашинного помещения является полной.
Программа исследований
Оценка потенциала кластера ES
Оценка мощности кластера ES призвана гарантировать, что кластер может предоставлять стабильные услуги в течение определенного периода времени после его создания. В основном он должен быть способен решать следующие проблемы:
-
Сколько шардов следует установить для каждого индекса, сколько ожидается последующего приращения данных, а также оценки трафика чтения и записи;
-
Сколько экземпляров данных следует настроить в одном кластере и какие спецификации следует использовать для одного экземпляра данных;
-
Поймите разницу между вертикальным и горизонтальным расширением, какова наша стратегия реагирования в случае неожиданного увеличения объема данных или неожиданного увеличения трафика и как следует спроектировать аварийное восстановление кластера ES.
Ключевые решения:
-
После того как количество сегментов индекса ES установлено, его нельзя изменить, поэтому важно определить количество сегментов. Обычно количество сегментов является целым числом, кратным экземпляру ES, чтобы обеспечить балансировку нагрузки;
-
Размер одного сегмента относительно разумен: от 10 до 30 ГБ. Чрезмерное индексирование повлияет на производительность запросов;
-
Всплеск трафика можно решить путем расширения емкости, а всплеск данных можно решить путем удаления старых данных или увеличения количества сегментов, и его необходимо развернуть с помощью плана аварийного восстановления с несколькими машинными комнатами, чтобы друг друга; представляет собой катастрофоустойчивое машинное помещение.
Выбор канала синхронизации данных
В основном он решает, как синхронизировать записи регистрации БД с ES, как записать в ES другие связанные индикаторы, а также как обновить и обеспечить согласованность данных.
-
БД -> ES должна быть потоком данных квазиреального времени, а изменения в регистрационных записях и другой информации должны быть доступны для поиска в квазиреальном времени;
-
Помимо собственных полей, регистрационная запись также должна дополнять свои поля атрибутов, такие как зарегистрированные продукты, магазины и эксперты. Она также записывается в ES и
может поддерживать частичные обновления
, поэтому методом записи ES может быть только метод Upsert. ;
-
Обновления индивидуальных регистрационных записей должны быть в порядке и не должны противоречить друг другу.
Обзор базовой конфигурации индекса ES
Понимание основных основ и конфигураций ES.
-
{"dynamic": false} позволяет избежать автоматического расширения сопоставлений es или добавления неожиданных типов индексов;
-
index.translog.durability=async, асинхронное обновление транслога поможет повысить производительность записи, но существует риск потери данных;
-
Интервал обновления ES по умолчанию составляет 1 с, что означает, что данные можно найти уже через одну секунду после успешной записи.
Решение для синхронизации данных
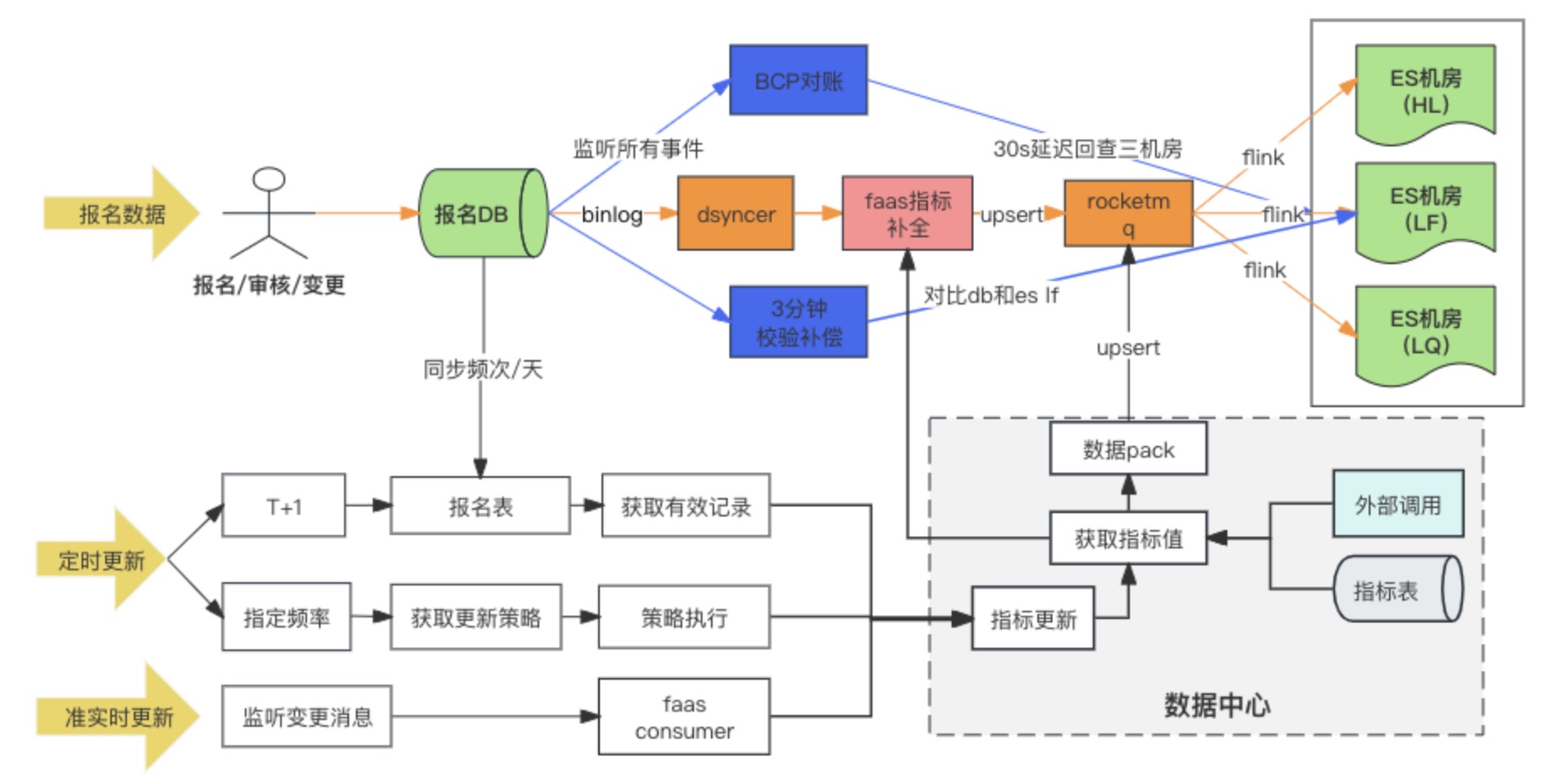
Схема канала синхронизации данных
Решение для синхронизации данных DB -> ES в конечном итоге использует метод синхронной записи разнородных данных в RocketMQ + Flink для использования в многомашинном помещении. В то же время, когда регистрационная запись записывается впервые, расширенные индикаторы заполняются. через пользовательский сценарий преобразования Faas, а зависимости обновления расширенных индикаторов — изменить два метода прослушивания сообщений и запланированных задач. В ходе исследования фактически было три варианта многокомпьютерной комнаты БД -> ES. В итоге мы выбрали третий вариант. Здесь мы сравним различия между тремя вариантами:
Решение 1. Непосредственная запись в многомашинное помещение ES посредством синхронизации гетерогенных данных (Dsyncer).
недостаток:
-
Прямая запись не соответствует требованиям ES по одновременному развертыванию нескольких компьютерных залов, поскольку она не может гарантировать успешную запись в нескольких компьютерных залах одновременно. Можно ли развертывать несколько разнородных данных и записывать их отдельно? Да, то есть нагрузка увеличивается втрое примерно до десятка индексов.
-
Возможности прямой массовой записи относительно слабы, и всплески записи будут более очевидными по мере колебаний трафика, что ухудшает производительность записи ES.
-
Прямая запись не может гарантировать упорядоченное обновление одной регистрационной записи, если в ES имеется несколько записей обновления. Могу ли я увеличить глобальную версию? Да, но слишком тяжелый.
Преимущества:
кратчайший путь зависимости, низкая задержка записи и минимальный системный риск. Это абсолютно не проблема для предприятий с небольшим трафиком и предприятий с простыми сценариями синхронизации.
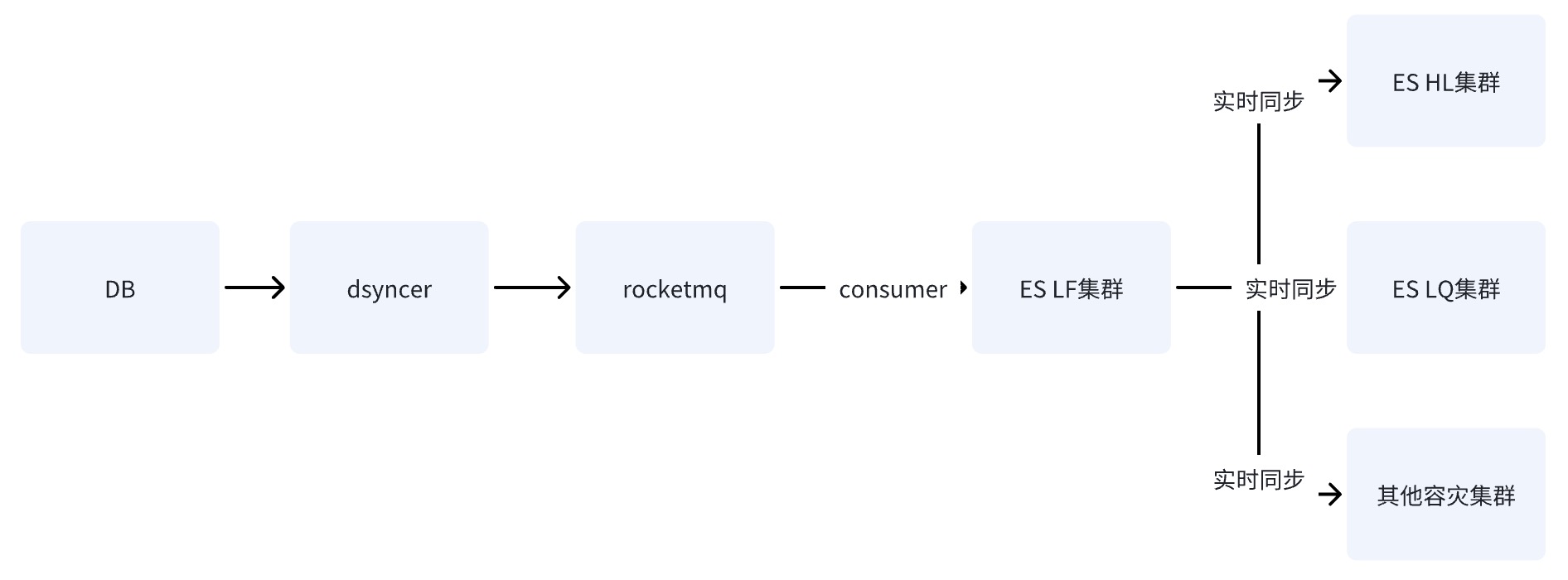
Вариант 2. Напишите ES для одной компьютерной комнаты через RocketMQ.
После того как БД записывает данные в один компьютерный зал ES через RocketMQ, данные синхронизируются с другими компьютерными залами посредством возможности репликации данных между кластерами, предоставляемой ES.
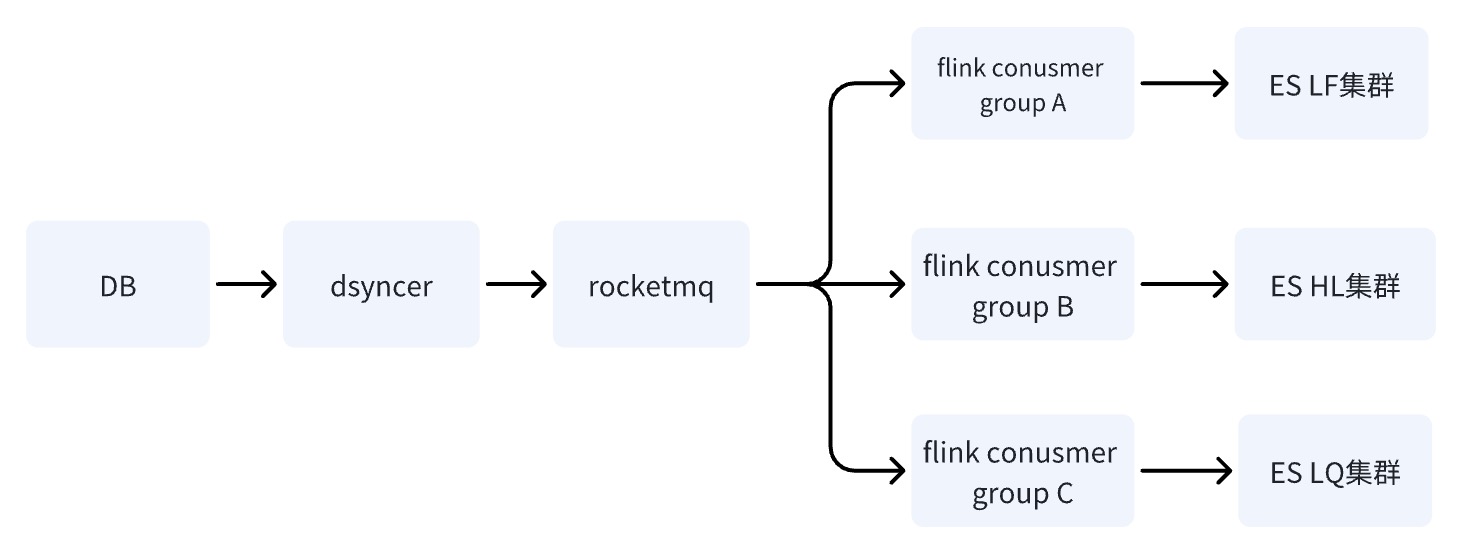
Вариант 3: Написать многомашинную комнату ES через RocketMQ + Flink ✅
Когда БД записывает данные в кластер ES через RocketMQ, запускается несколько независимых задач группы потребителей. Система может использовать распределенную систему Flink для записи данных в несколько компьютерных залов.
Есть только одно различие между схемой два и схемой три: способ записи в несколько компьютерных залов различен. Вторая схема заключается в записи в один компьютерный зал, а затем синхронизация данных с другими компьютерными залами в квазиреальном времени, в то время как схема. третий — записать несколько независимых потребителей отдельно.
Недостатки второго и третьего вариантов одинаковы: путь зависимости самый длинный, а на задержку записи легко влияет дрожание базовых компонентов. Однако фатальный недостаток второго варианта заключается в том, что
в нем есть единственная точка риска.
Если предположить, что данные синхронизируются с HL и LQ через LF, то после зависания LF система станет непригодной для использования .
Преимущество третьего варианта заключается в том, что ссылки на запись в нескольких компьютерных залах независимы друг от друга. По сравнению со вторым вариантом, если какая-либо ссылка имеет проблемы, это не создаст рисков для бизнеса; RocketMQ может легко решить проблему последовательного обновления одного ключа. ,
что также нежелательно по первой причине
.
Почему написание через RocketMQ может решить проблему нарушения порядка и конфликтов?
-
Прежде всего, запись ES контролируется оптимистической блокировкой на основе номера версии. Если одна и та же запись обновляется одновременно, то версия, которую мы получаем в одно и то же время, будет одинаковой, если предположить, что она равна 1, тогда все будут одинаковы. обновите версию 2 для записи, возникнут конфликты, а конфликты всегда будут вызывать проблему потери обновлений;
-
Общие бизнес-сценарии требуют упорядоченного использования на основе порядка ключей и разделов. Упорядоченное использование требует двух необходимых условий: когда сообщения хранятся, они должны соответствовать порядку, в котором они отправляются, они должны соответствовать порядку; в котором они хранятся.
Следовательно, если бизнес хочет получать сообщения упорядоченным образом, ему необходимо гарантировать, что сообщения, отправленные с одним и тем же ключом, отправляются в один и тот же раздел, а потребляемые сообщения гарантируют, что сообщения с одним и тем же ключом всегда будут использоваться тот же Потребитель. Но на самом деле два упомянутых выше необходимых условия являются идеальными. В некоторых случаях они не могут быть полностью гарантированы, например, при записи определенного экземпляра брокера. Причины и решения будут проанализированы ниже.
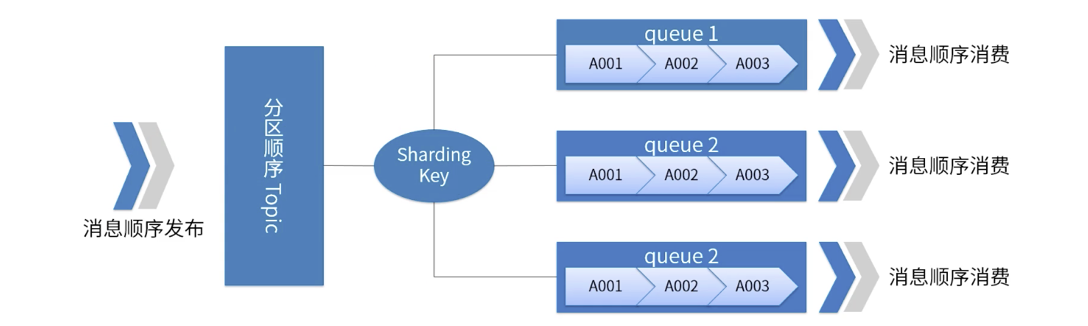
На рисунке показан порядок разделов RocketMQ.
-
Для указанной темы все сообщения делятся на несколько (очередей) в соответствии с Sharding Key.
-
Сообщения в одной очереди публикуются и потребляются в строгом порядке FIFO.
-
Sharding Key — это ключевое поле, используемое для различения разных разделов в последовательных сообщениях. Это совершенно другая концепция, чем ключ обычных сообщений.
-
Применимые сценарии: высокие требования к производительности. Определите, в какую очередь отправляется сообщение, на основе ключа сегментирования в сообщении. Как правило, упорядоченное секционирование может удовлетворить наши бизнес-требования и обеспечить высокую производительность.
Здесь необходимо отметить,
что
RocketMQ, возможно, помог бизнесу решить 99% проблем с нарушением порядка, но это не 100%. В крайних случаях сообщения все еще могут иметь проблемы с нарушением порядка использования, например как явление ABA, например, когда происходит сбой Partiton, сообщение повторно отправляется в другие очереди разделов и т. д., поэтому согласование согласованности имеет важное значение.
Многоуровневый механизм согласования
Механизм согласования решает проблему согласованности данных DB->ES. Как упоминалось ранее, DB -> ES представляет собой поток данных квазиреального времени, и ссылка зависимости является относительно длинной. стратегии сверки и компенсации для обеспечения окончательной согласованности данных.
Здесь мы выполнили трехуровневую сверку. Мы используем платформу сверки для достижения сверки на минутном уровне и автономной сверки. Причины необходимости многоуровневой сверки будут объяснены один за другим.
Диаграмма анализа сбоев канала синхронизации БД ES
Платформа бизнес-верификации ( BCP ) — сверка второго уровня
Обратившись к приведенному выше рисунку, вы обнаружите, что синхронизация DB --> ES зависит от многих зависимых компонентов. В этом случае нам необходимо
согласование с глобальной точки зрения
для обнаружения проблем с каналом синхронизации, то есть согласование BCP в реальном времени.
Согласование BCP — это однопотоковое согласование, которое отслеживает Binlog и непосредственно проверяет согласование нескольких машинных помещений ES. Оно опирается только на поток Binlog. Задержки синхронизации данных или блокировки в промежуточных каналах могут быть быстро обнаружены посредством согласования BCP; обнаружит, что если Binlog отключен, и выверка BCP не может быть исправлена, как решить эту ситуацию, будет обсуждаться позже, но, по крайней мере, видно, что, за исключением DB->DBus, выверки BCP достаточно, чтобы обнаружить большую часть задержки синхронизации. проблемы. Почему один поток вместо нескольких потоков?
-
Избегайте неконтролируемых проблем с задержками, вызванных длинными каналами потока данных для многопотоковой сверки, что приводит к низкой точности проверки.
-
Затраты на обслуживание выверки BCP будут значительно снижены, поскольку при использовании многопоточности нам необходимо поддерживать несколько выверок BCP для выверки нескольких машинных помещений, которая опирается на более базовые компоненты для обслуживания.
Запись базы данных сверки BCP всегда запускает запросы ES Get, которые потребляют определенные ресурсы запросов в ES, но запросы Get — это методы запросов с очень хорошей производительностью. Например, у нас нет проблем с записью в пределах 1000 QPS.
В запросе Get необходимо обратить внимание на параметр Realtime, для которого при запросе должно быть установлено значение False, иначе при каждом запросе будет запускаться операция обновления, что повлияет на производительность записи системы.
mgetReq := EsClient.MultiGet().
В реальном времени(ложь)
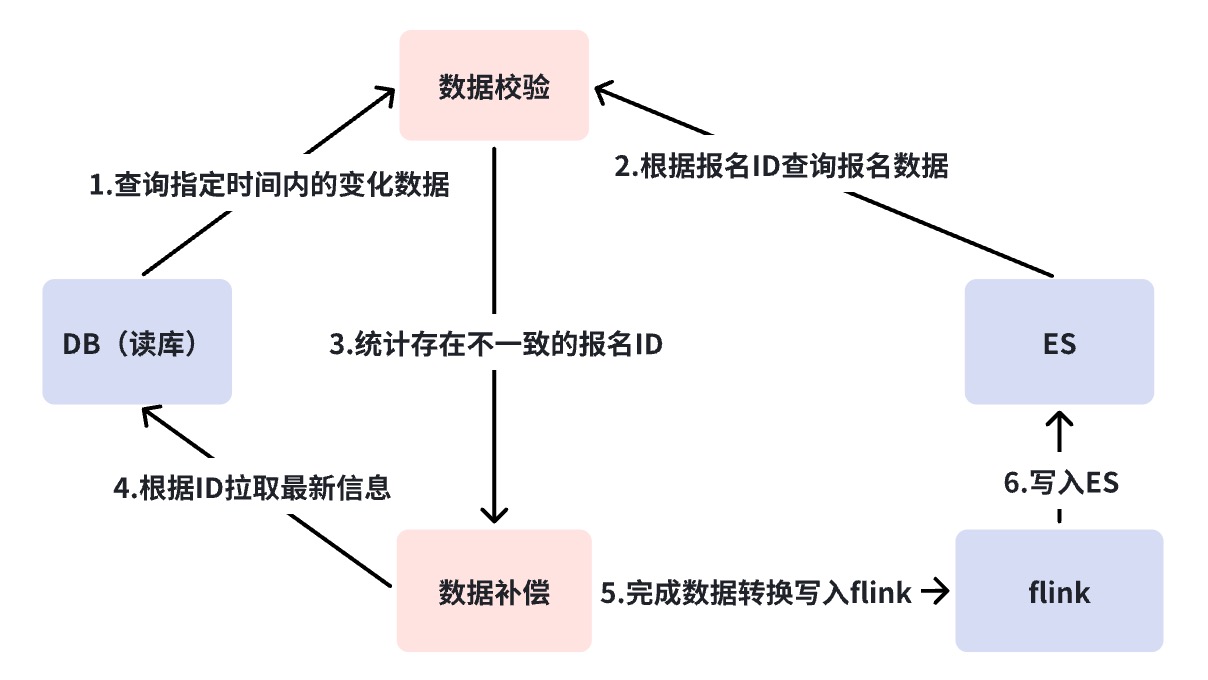
Сверка на минутном уровне
Как упоминалось в предыдущем разделе, путь, который не может быть охвачен сверкой Business Verification Platform (BCP), — это DB->DBus, что представляет собой ситуацию, когда Binlog отключен. Обычно сбой в работе Binlog мог означать более серьезную аварию, но мы должны сделать все возможное.
Согласование на минутном уровне напрямую запрашивает сверку у БД и ES, не полагаясь на какие-либо компоненты. При возникновении несоответствий выполняется автоматическая компенсация. С одной стороны, сверка на минутном уровне компенсирует недостатки сверки BCP, а второй момент – добавить механизм компенсации. Причина, по которой BCP не компенсирует, заключается в том, что BCP в основном предназначен для обнаружения проблем, поэтому он должен оставаться легким и быстрым. Кроме того, он по-прежнему опирается на базовые компоненты, такие как RocketMQ и DBus. Этот вид компенсации по-прежнему не может охватывать все нештатные сценарии.
По умолчанию мы будем считать, что функция компонента не повреждена для сверки каждые три минуты, но небольшая задержка в узле вызывает компенсацию. Если сигналы компенсации возникают часто, нам необходимо дополнительно проанализировать, в чем проблема со ссылкой. На данный момент в нашем сценарии я разделю ссылку на две и подтвержу, существует ли проблема с предыдущей ссылкой RocketMQ или проблема с RocketMQ и последующими ссылками потребления. С помощью диаграммы анализа ошибок, если возникает проблема со ссылкой перед RocketMQ, например, прерывание Binlog, зависание компонента платформы синхронизации гетерогенных данных и т. д., данные компенсации будут записаны непосредственно в RocketMQ и использованы в нескольких компьютерных залах. время поток чтения не нужно отключать, и он может обеспечить согласованность данных в нескольких компьютерных залах. Но если RocketMQ зависнет, он будет писать напрямую в ES. Поскольку в настоящее время мы не можем гарантировать, что несколько компьютерных залов могут быть успешно записаны одновременно, поэтому наше решение — писать только в один компьютерный зал и переключить весь трафик на него. единственный компьютерный зал.
Зависание RocketMQ — это очень плохой сигнал, и здесь ситуация сложнее. Из-за прямой записи в ES, если трафик записи высок, система в это время теряет защиту, ограничивающую ток, и ES может быть не в состоянии выдержать ее, а отдельный компьютерный зал может не выдержать весь трафик чтения; в то же время, если конфликты записи происходят часто, необходимо понизить версию порта деловой записи. Поэтому, если RocketMQ зависает, можно понять, что центральная система канала записи парализована.
Это последнее, что вы хотите видеть, поэтому SLA RocketMQ — это основа бизнеса.
Офлайн-выверка Т+1
Автономная сверка предназначена для ежедневной синхронизации данных БД и ES с Hive. Инкрементальные данные проверяют окончательную согласованность. В случае несоответствия автоматически инициируется автономная сверка, которая является итогом обеспечения согласованности данных в канале синхронизации. данные должны быть не позднее T +1, компенсация успешна.
Подведем итог
Выше мы завершили первый этап построения, развертывание аварийного восстановления, согласование согласованности и основные стратегии реагирования на системные исключения. В настоящее время ES может поддерживать запросы на чтение и запись для десятков миллионов индексов продуктов. Трафик одного компьютерного зала колеблется от 500 до 100 QPS, а трафик записи в основном поддерживается на уровне около 500 QPS.
Однако с развитием бизнеса в ES-кластере неоднократно наблюдались скачки производительности ЦП, одно или несколько компьютерных залов одновременно были заполнены, а задержки запросов внезапно увеличивались. Однако трафик чтения и записи не сильно колеблется или изменяется. намного меньше, чем пик системы. Этот риск объясняется проблемами производительности, возникающими в кластере ES, и состоянием использования бизнеса. Мы продолжим знакомить вас с этой частью в следующей статье «Управление стабильностью поисковой системы ES».
Источник статьи Бизнес-платформа ByteDance Ван Дань