
Эта статья основана на выступлении Шао Вэя, старшего инженера по исследованиям и разработкам Volcano Engine, на глобальной конференции по разработке программного обеспечения QCon. Спикер|Выступление Шао Вэя|QCon Гуанчжоу, май 2023 г.
1. История
Компания Byte начала трансформировать свои сервисы в облачные сервисы с 2016 года. На сегодняшний день система обслуживания Byte в основном включает четыре категории: традиционные микросервисы — это в основном веб-сервисы RPC на базе Golang, сервис поиска по рекламе — традиционный сервис C++ с более высокой производительностью; требования, кроме того, существуют также машинное обучение, большие данные и различные сервисы хранения .
Основная проблема, которую необходимо решить после облачной разработки, заключается в том, как повысить эффективность использования ресурсов кластера; на примере использования ресурсов типичного онлайн-сервиса темно-синяя часть — это объем ресурсов, фактически используемых бизнесом; , а светло-голубая часть — это буфер безопасности, предоставляемый бизнес-сферой. Даже если буферная область увеличивается, остается много ресурсов, которые были запрошены, но не используются бизнесом. Поэтому цель оптимизации заключается в максимально возможном использовании этих неиспользуемых ресурсов с архитектурной точки зрения.
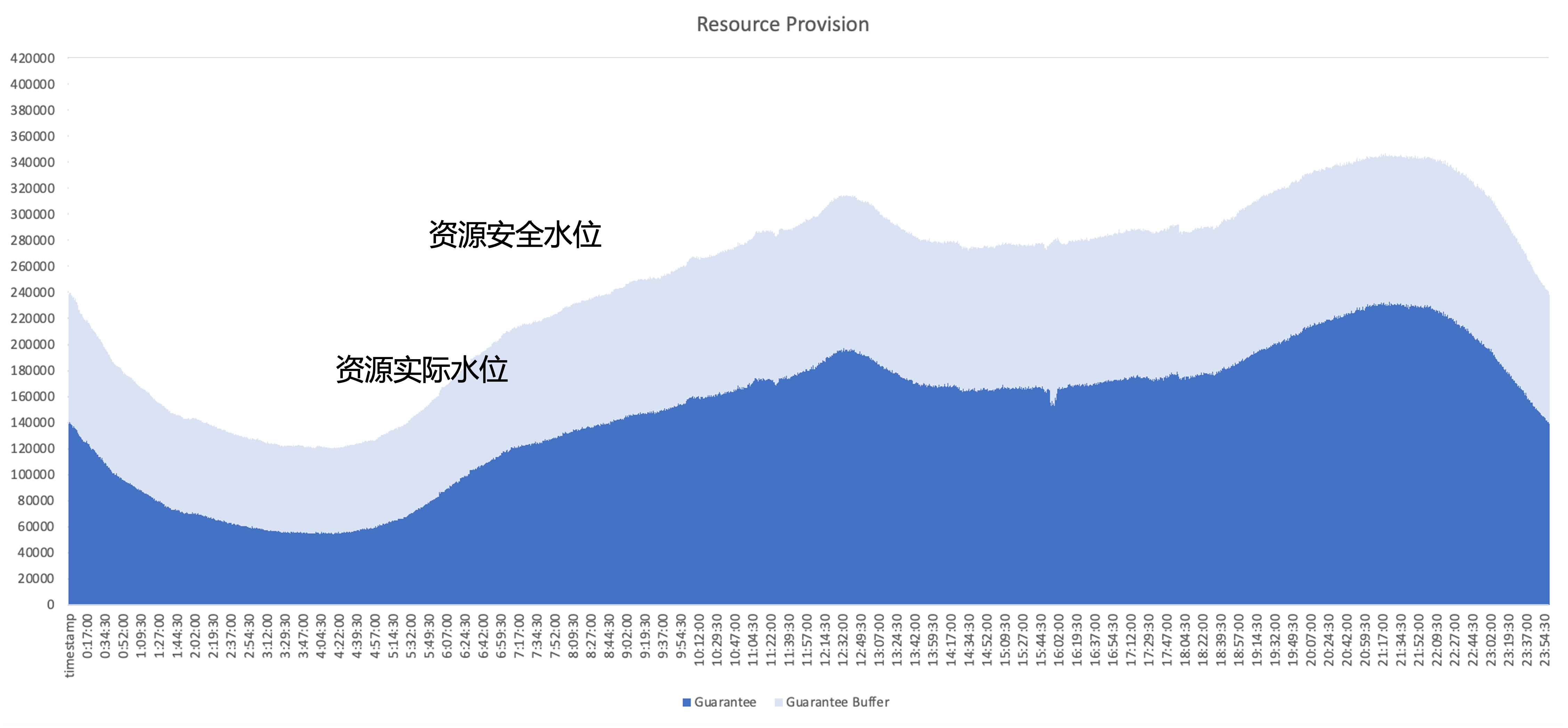
план управления ресурсами
Компания Byte опробовала несколько различных типов решений по управлению ресурсами внутри компании, в том числе
- Эксплуатация ресурсов: регулярно помогайте бизнесу контролировать состояние использования ресурсов и продвигайте управление использованием ресурсов. Проблема в том, что нагрузка на эксплуатацию и обслуживание велика, и проблема использования не может быть решена.
- Динамическое избыточное резервирование: оцените объем бизнес-ресурсов на стороне системы и заблаговременно сократите квоту. Проблема в том, что стратегия избыточного резервирования не всегда точна и может привести к риску неиспользования.
- Динамическое масштабирование. Проблема в том, что если вы ориентируетесь только на онлайн-сервисы для масштабирования, поскольку пики и спады трафика в онлайн-сервисах одинаковы, это не сможет полностью улучшить использование в течение дня.
Таким образом, в конечном итоге Byte применяет гибридное развертывание, одновременно работая онлайн и оффлайн на одном и том же узле, полностью используя взаимодополняющие характеристики онлайн- и офлайн-ресурсов для достижения лучшего использования ресурсов, в конечном итоге мы ожидаем достичь следующего эффекта: , то есть вторичные продажи происходят онлайн. Неиспользуемые ресурсы можно хорошо заполнить оффлайн-рабочими нагрузками, чтобы поддерживать эффективность использования ресурсов на высоком уровне в течение дня.
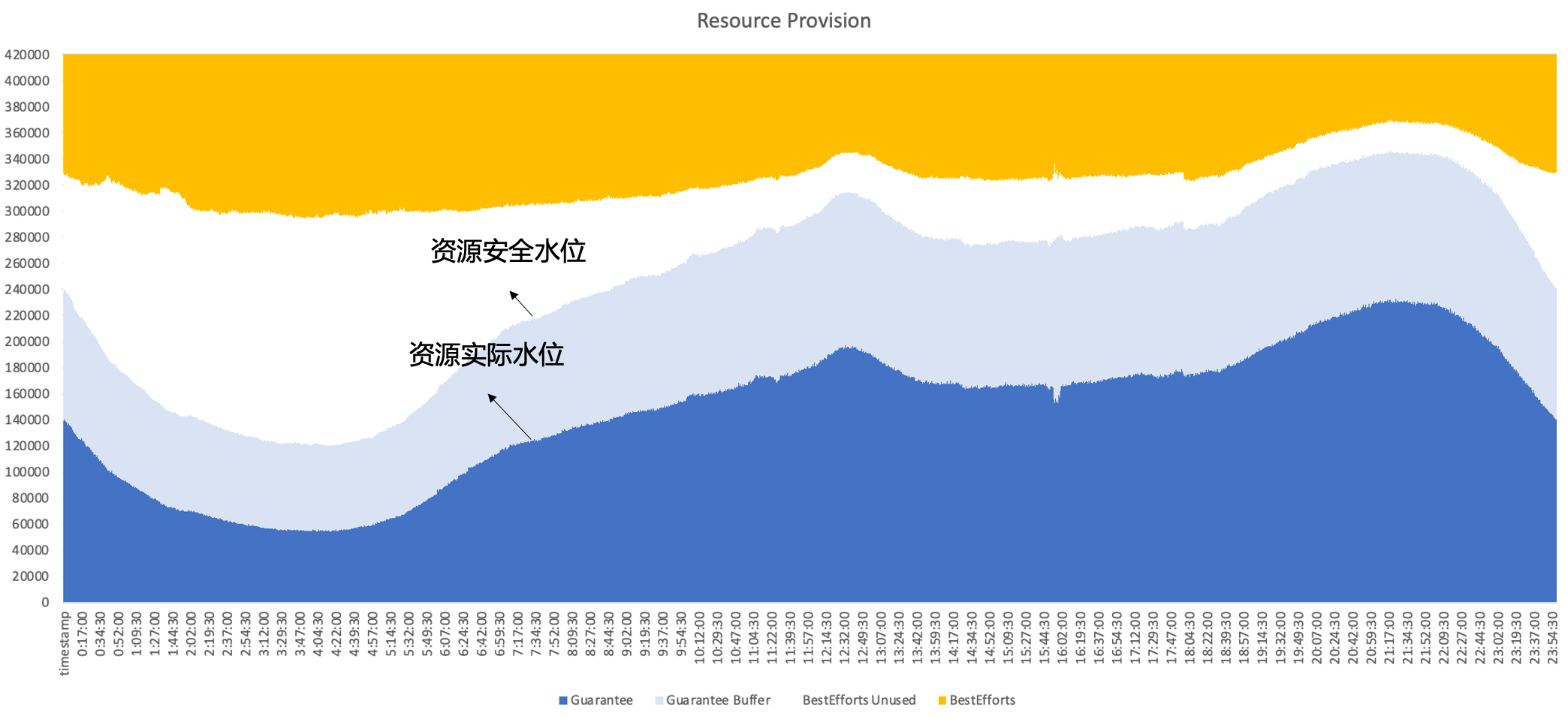
2. История развития байтового гибридного развертывания
Поскольку Byte Cloud становится родным, мы выбираем подходящие решения для гибридного развертывания, исходя из потребностей бизнеса и технических характеристик на разных этапах, и продолжаем совершенствовать нашу гибридную систему в процессе.
2.1 Этап 1. Смешанное развертывание с разделением времени в автономном режиме
Первый этап в основном включает в себя гибридное развертывание с разделением времени онлайн и оффлайн.
- Онлайн: на этом этапе мы создали платформу эластичности онлайн-сервисов. Пользователи могут настраивать правила горизонтального масштабирования на основе бизнес-показателей, например, если бизнес-трафик снижается рано утром и бизнес активно сокращает некоторые экземпляры, система будет выполнять ресурс; двойная упаковка с учетом усадки экземпляра. Это освобождает всю машину;
- Для офлайн-сервисов: на этом этапе офлайн-сервисы могут получать большое количество ресурсов спотового типа, и, поскольку их поставки нестабильны, они могут в то же время получать определенную скидку на стоимость, в то же время для онлайн-сервисов продажа неиспользованных ресурсов в офлайн-режиме может осуществляться; получить определенную скидку на стоимость.
Преимущество этого решения заключается в том, что оно не требует сложного механизма изоляции на стороне одной машины, а техническая реализация относительно невелика, однако существуют также некоторые проблемы, такие как;
- Эффективность преобразования невысока, и в процессе упаковки Bing могут возникнуть такие проблемы, как фрагментация;
- Работа в автономном режиме также может быть неудовлетворительной. Когда онлайн-трафик время от времени колеблется, офлайн-пользователь может быть принудительно убит, что приведет к сильным колебаниям ресурсов.
- Это приведет к изменениям в бизнесе. В реальных операциях бизнес обычно настраивает относительно консервативную эластичную политику, что приводит к низкому верхнему пределу улучшения ресурсов.
2.2 Этап 2: совместное развертывание Kubernetes/YARN
Чтобы решить вышеуказанные проблемы, мы перешли на второй этап и попытались запустить оффлайн и онлайн на одном узле.
Поскольку ранее онлайн-часть была изначально преобразована на основе Kubernetes, большинство офлайн-заданий по-прежнему выполняются на основе YARN. Чтобы способствовать гибридному развертыванию, мы внедряем сторонние компоненты на одну машину, чтобы определить объем ресурсов, согласованных с онлайн и оффлайн, и одновременно соединяем их с автономными компонентами, такими как Kubelet или Node Manager; Онлайн- и офлайн-рабочие нагрузки планируются для узлов, они также координируются. Компонент координации асинхронно обновляет распределение ресурсов для обеих рабочих нагрузок.
Этот план позволяет завершить накопление резерва возможностей совместного размещения и проверить реализуемость, однако остаются некоторые проблемы.
- Две системы выполняются асинхронно, так что оффлайн-контейнер может только обходить управление и контроль, а в промежуточных звеньях происходит гонка и слишком большие потери ресурсов;
- Простая абстракция автономных рабочих нагрузок не позволяет нам описывать сложные требования QoS.
- Фрагментация автономных метаданных сильно затрудняет оптимизацию и не позволяет достичь глобальной оптимизации планирования.
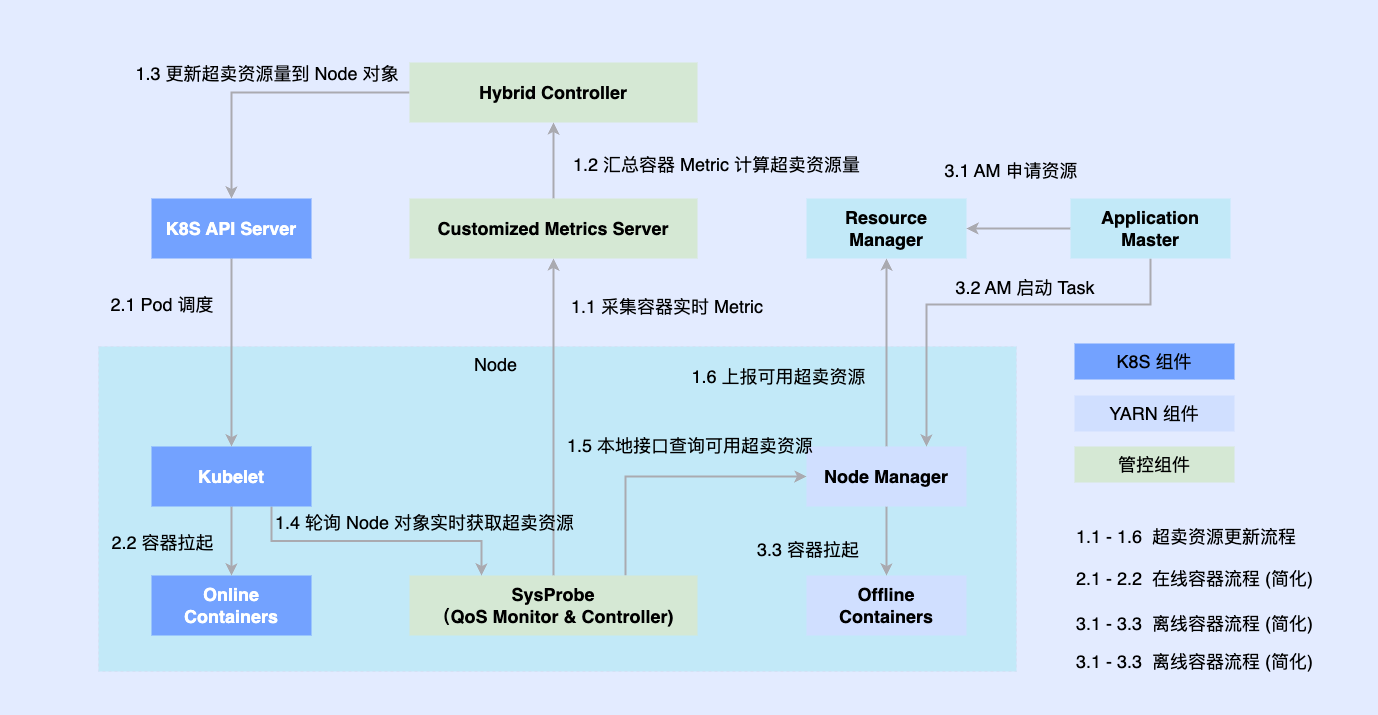
2.3 Этап 3. Единое планирование и смешанное развертывание в автономном режиме
Чтобы решить проблемы второго этапа, на третьем этапе мы полностью реализовали единое автономное гибридное развертывание.
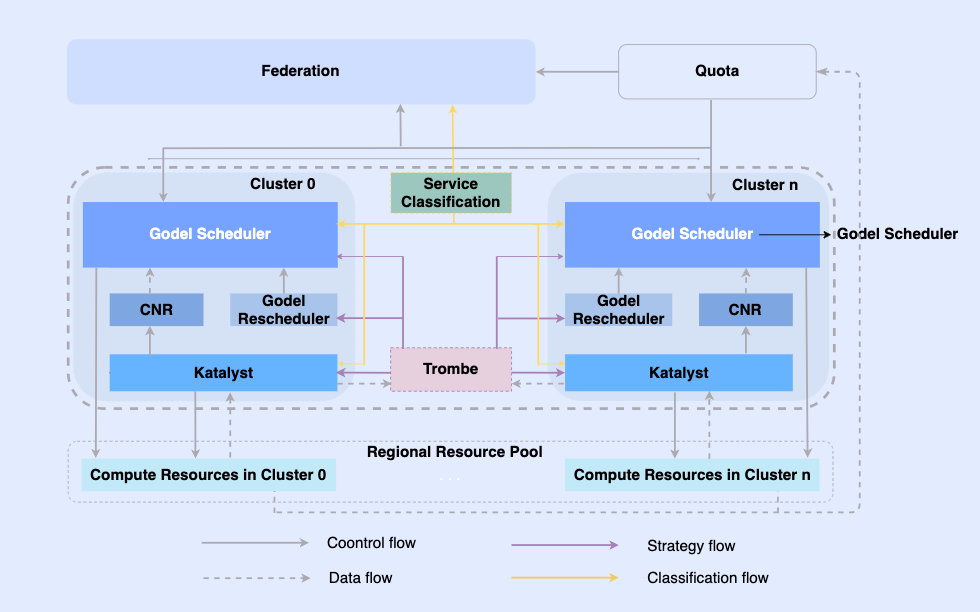
Делая офлайн-задания облачными, мы даем возможность планировать их и управлять ресурсами в одной и той же инфраструктуре. В этой системе самым верхним уровнем является унифицированное объединение ресурсов для реализации управления ресурсами нескольких кластеров. В одном кластере имеется центральный унифицированный планировщик и автономный унифицированный менеджер ресурсов. Они работают вместе для достижения возможностей автономного интегрированного управления ресурсами. .
В этой архитектуре Katalyst служит основным уровнем управления и контроля ресурсов и отвечает за реализацию и оценку ресурсов в реальном времени на стороне одной машины. Он имеет следующие характеристики.
- Стандартизация абстракции: открывайте автономные метаданные, делайте абстракцию QoS более сложной и богатой, а также лучше удовлетворяйте требованиям эффективности бизнеса;
- Синхронизация управления и контроля: политика управления и контроля выдается при запуске контейнера, чтобы избежать асинхронной коррекции настроек ресурсов после запуска, поддерживая при этом свободное расширение политики;
- Интеллектуальная стратегия. Создавая портреты услуг, вы можете заранее определить потребности в ресурсах и реализовать более разумные стратегии управления и контроля ресурсов;
- Автоматизация эксплуатации и технического обслуживания. Благодаря комплексной доставке достигается автоматизация и стандартизация эксплуатации и технического обслуживания.
3. Внедрение системы Catalyst
Katalyst происходит от английского слова Catalyst, которое изначально означает «катализатор». Первая буква изменена на K, что означает, что система может предоставлять более мощные возможности автоматического управления ресурсами для всех нагрузок, выполняемых в системе Kubernetes.
3.1 Обзор системы Catalyst
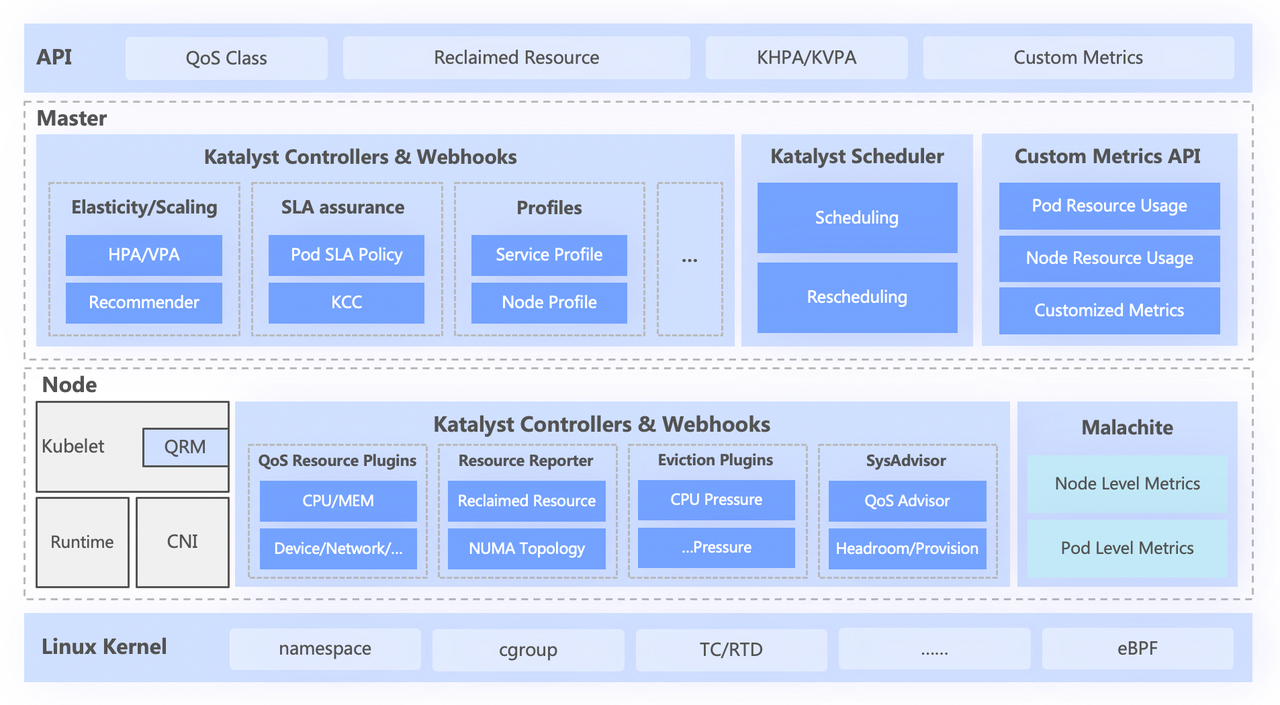
Система Katalyst условно разделена на четыре уровня, включая
- Стандартный API верхнего уровня абстрагирует различные уровни QoS для пользователей и предоставляет широкие возможности выражения ресурсов;
- Центральный уровень отвечает за базовые возможности, такие как унифицированное планирование, рекомендации по ресурсам и построение портретов сервисов;
- Автономный уровень включает в себя саморазрабатываемую систему мониторинга данных и распределитель ресурсов, отвечающий за распределение и динамическую настройку ресурсов в реальном времени;
- Нижний уровень представляет собой настроенное по байтам ядро, которое решает проблему производительности одной машины при работе в автономном режиме за счет улучшения патча ядра и базового механизма изоляции.
3.2 Абстрактная стандартизация: класс QoS
Качество обслуживания Katalyst можно интерпретировать как с макро-, так и с микро-перспективы.
- На макроуровне Katalyst определяет стандартные уровни QoS на основе основного измерения ЦП; в частности, мы делим QoS на четыре категории: эксклюзивный, общий, перезапуск и тип системы, зарезервированный для ключевых компонентов системы;
- С микроперспективы, окончательное ожидание Katalyst заключается в том, что независимо от типа рабочей нагрузки его можно будет запускать в пуле на одном узле без необходимости изолировать кластер посредством жесткой обрезки, тем самым достигая большей эффективности трафика ресурсов и их использования. эффективность.
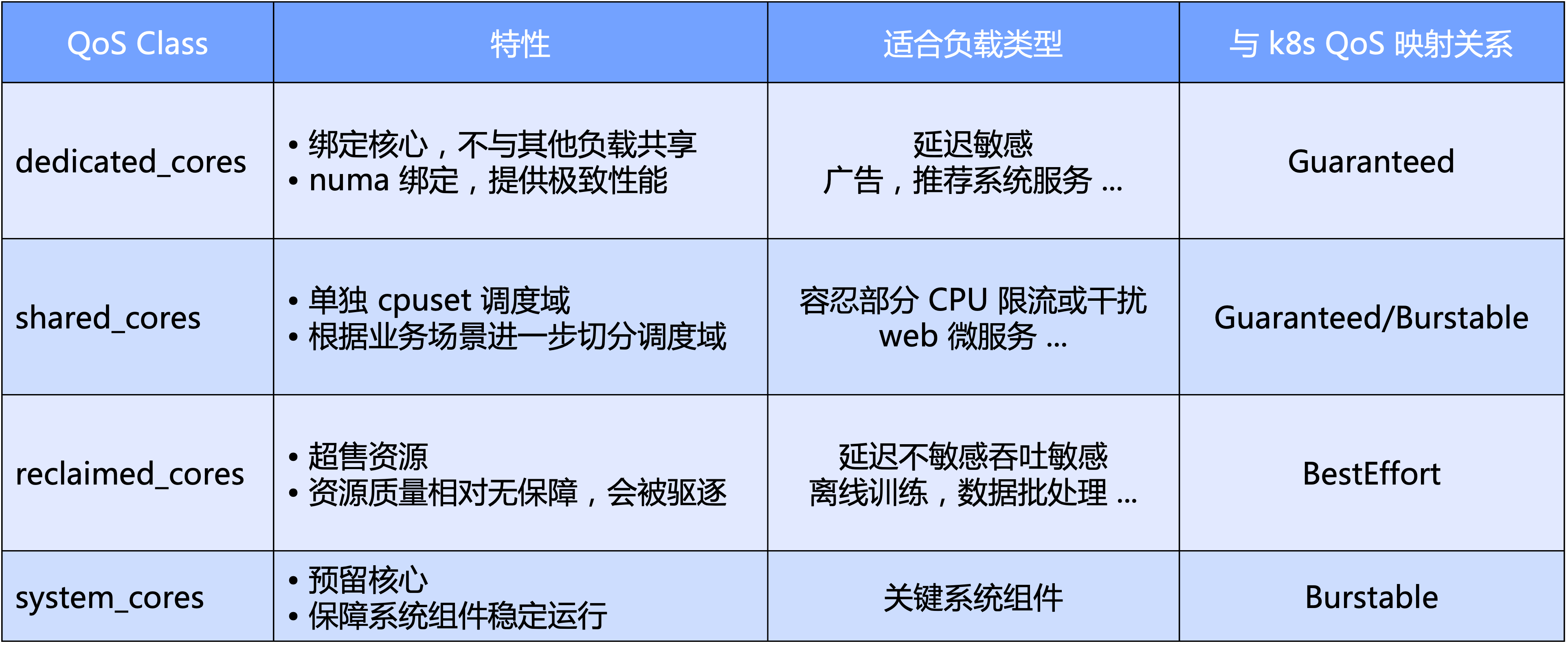
На основе QoS Katalyst также предоставляет множество улучшений расширений для выражения других требований к ресурсам в дополнение к ядрам ЦП.
- Улучшение качества обслуживания: расширенное выражение бизнес-требований к многомерным ресурсам, таким как привязка NUMA/сетевой карты, распределение пропускной способности сетевой карты, вес ввода-вывода и т. д.
- Улучшение модуля: расширяет выражение чувствительности бизнеса к различным системным показателям, таким как влияние задержки планирования ЦП на производительность бизнеса.
- Улучшение узла: выражение объединенных требований микротопологии среди нескольких измерений ресурсов путем расширения встроенной политики TopologyPolicy.
3.3 Синхронизация управления и контроля: диспетчер ресурсов QoS
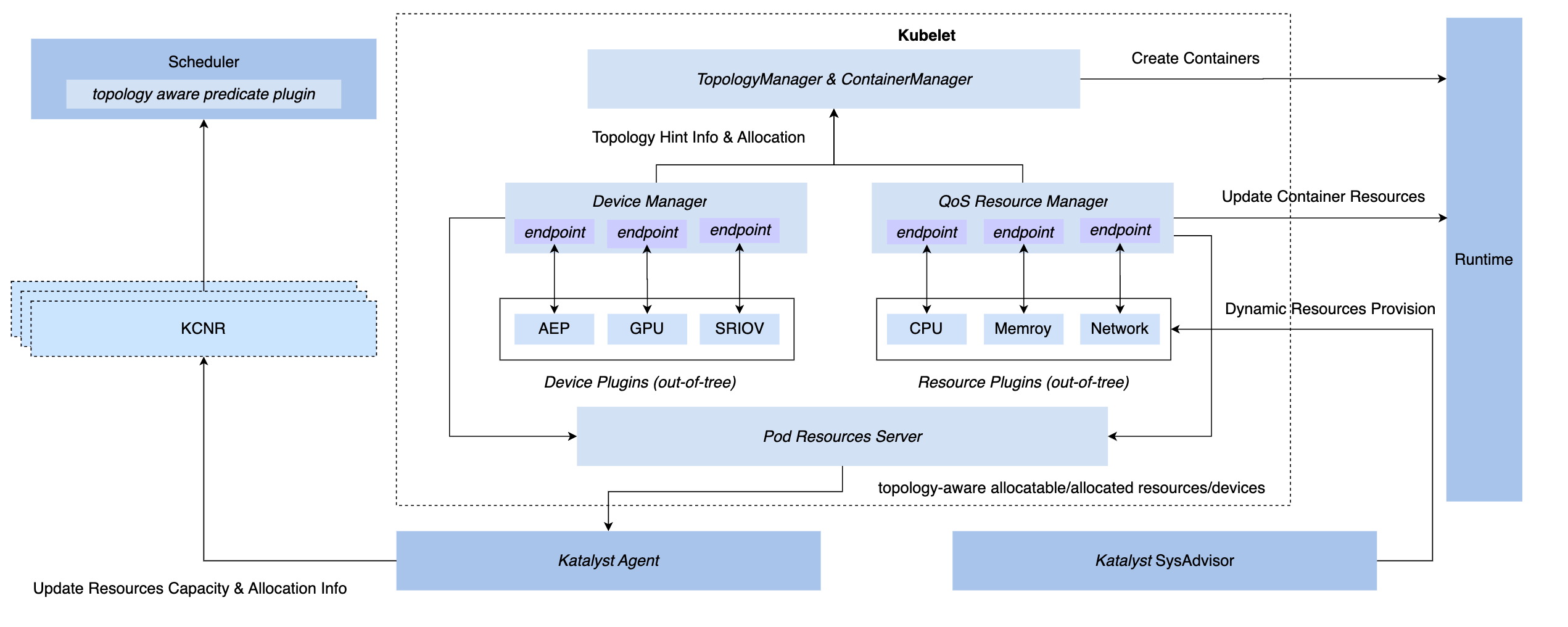
Чтобы реализовать возможности синхронного управления и контроля в системе K8s, у нас есть три метода перехвата: вставка уровня CRI, уровень OCI и уровень Kubelet. В конце концов, Katalyst решил реализовать управление и контроль на стороне Kubelet, то есть. для реализации диспетчера ресурсов QoS на том же уровне, что и собственный диспетчер устройств. Преимущества этой программы включают в себя.
- Внедрите перехват на этапе допуска, устраняя необходимость полагаться на скрытые меры для достижения контроля на последующих этапах.
- Подключайте метаданные к Kubelet, сообщайте информацию о микротопологии одной машины узлу CRD через стандартный интерфейс и реализуйте стыковку с помощью планировщика.
- На основе этой структуры можно гибко внедрять подключаемые плагины для удовлетворения индивидуальных потребностей в управлении и контроле.
3.4 Интеллектуальная стратегия: портрет сервиса и оценка ресурсов
Обычно для построения портрета услуги более интуитивно понятно использовать бизнес-индикаторы, такие как задержка услуги P99 или частота ошибок в нисходящем направлении. Но есть и некоторые проблемы. Например, по сравнению с системными индикаторами обычно сложнее получить бизнес-индикаторы; предприятия обычно интегрируют несколько структур, и значения бизнес-индикаторов, которые они производят, не совсем одинаковы. сильная зависимость от этих показателей, вся реализация контроля станет очень сложной.
Поэтому мы надеемся, что окончательный контроль ресурсов или портрет сервиса будет основан на системных показателях, а не на бизнес-показателях; наиболее важным из них является то, как найти системные показатели, которые больше всего волнуют бизнес. Наш подход заключается в использовании набора офлайн-индикаторов. конвейеры для обнаружения бизнес-показателей и системных показателей. Например, для услуги, показанной на рисунке, основным бизнес-показателем является задержка P99. В результате анализа выяснилось, что системным индикатором с наибольшей корреляцией является задержка планирования ЦП. Мы продолжим корректировать подачу ресурсов службы. его цель - как можно больше задержек в планировании процессора.
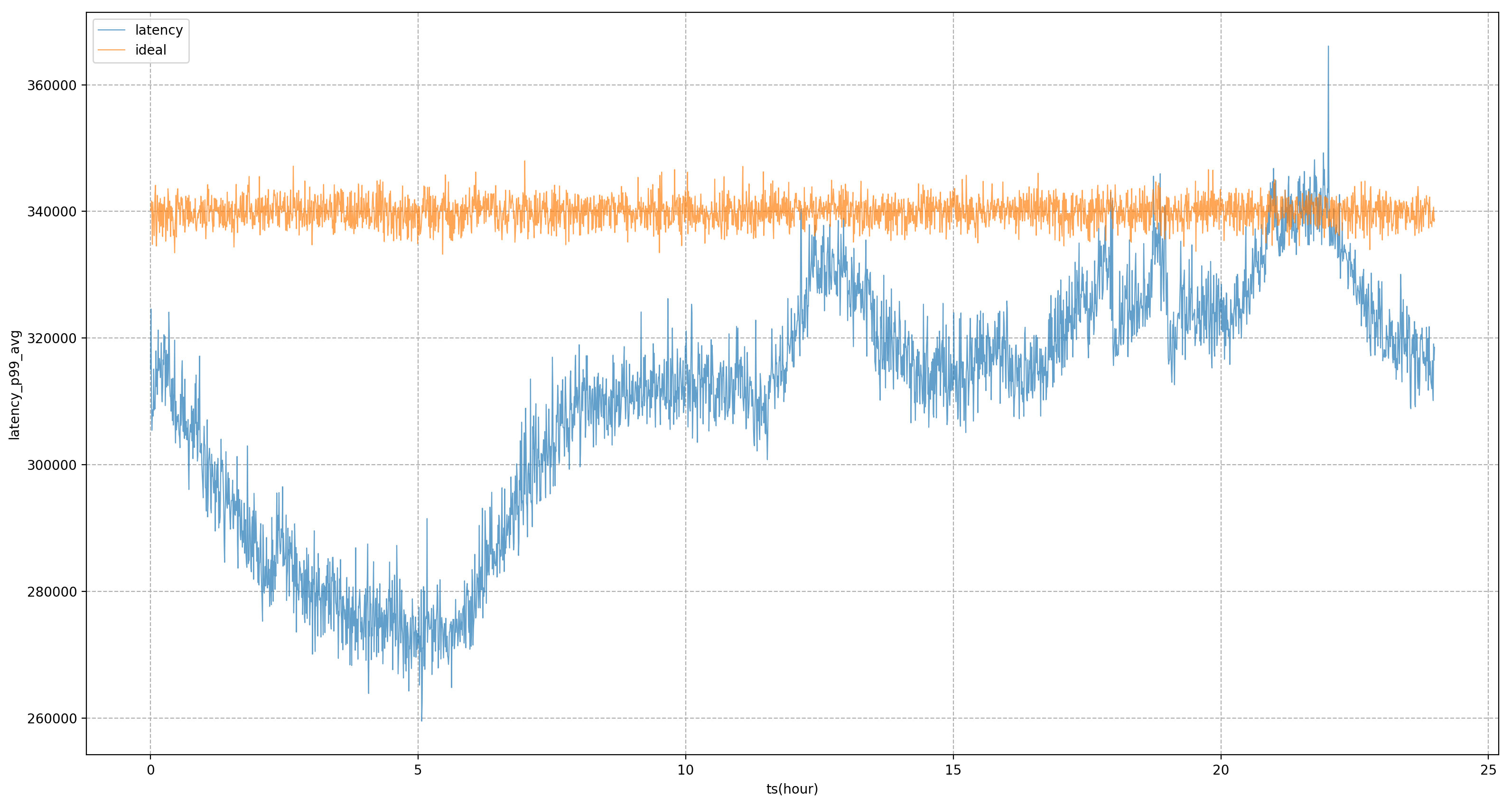
На основе портретов сервисов Katalyst предоставляет богатые механизмы изоляции для ЦП, памяти, диска и сети и при необходимости настраивает ядро для обеспечения более строгих требований к производительности, однако для различных бизнес-сценариев и типов эти средства не обязательно применимы, поэтому; Необходимо подчеркнуть, что изоляция — это скорее средство, чем цель. В процессе ведения бизнеса нам необходимо выбирать различные решения по изоляции, исходя из конкретных потребностей и сценариев.
3.5 Автоматизация эксплуатации и технического обслуживания: многомерное динамическое управление конфигурацией
Хотя мы надеемся, что все ресурсы находятся в системе пула ресурсов, в крупномасштабной производственной среде невозможно поместить все узлы в кластер, кроме того, в кластере могут быть машины как с ЦП, так и с графическим процессором, хотя плоскость управления может; быть общими, но требуется определенная изоляция на уровне данных, на уровне узла нам часто приходится изменять конфигурацию измерения узла для проверки в оттенках серого, что приводит к различиям в SLO разных сервисов, работающих на одном и том же узле.
Чтобы решить эти проблемы, нам необходимо учитывать влияние различных конфигураций узлов на сервисы во время бизнес-развертывания. С этой целью Katalyst предоставляет возможности динамического управления конфигурацией для стандартной доставки, оценки производительности и конфигурации различных узлов с помощью автоматизированных методов и выбора наиболее подходящего узла для услуги на основе этих результатов.
4. Применение совместного размещения Katalyst и анализ ситуации
В этом разделе мы поделимся некоторыми лучшими практиками, основанными на внутренних кейсах Byte.
4.1 Эффект использования
С точки зрения эффектов внедрения Katalyst, исходя из внутренней деловой практики Byte, наши ресурсы могут поддерживаться на относительно высоком уровне в течение квартального цикла в одном кластере, использование ресурсов также показывает относительно высокий уровень в различные периоды времени каждого дня. Стабильное распределение, в то же время загрузка большинства машин в кластере также относительно сконцентрирована, а наша гибридная система развертывания работает относительно стабильно на всех узлах.
| Алгоритм прогнозирования ресурсов | Коэффициент восстановления ресурсов | Средняя загрузка ЦП на уровне дня | Пиковая загрузка ЦП на уровне дня |
|---|---|---|---|
| Использование фиксированного буфера | 0,26 | 0,33 | 0,58 |
| алгоритм кластеризации k-средних | 0,35 | 0,48 | 0,6 |
| Системный индикатор ПИД-алгоритм | 0,39 | 0,54 | 0,66 |
| Оценка модели индикатора системы + алгоритм PID | 0,42 | 0,57 | 0,67 |
4.2 Практика: бессмысленный доступ в автономном режиме
После перехода на третий этап нам необходимо провести облачную трансформацию в автономном режиме. Есть два основных метода трансформации: один — для сервисов, уже находящихся в системе K8s. Мы будем напрямую подключать пул ресурсов на базе Virtual Kubelet. Второй — для сервисов под архитектурой YARN. Если сервис напрямую подключен к системе Kubernetes. Полная трансформация структуры обойдется бизнесу очень дорого и теоретически приведет к последовательному обновлению всех предприятий. Это, очевидно, не идеальное состояние.
Чтобы решить эту проблему, Байт обращается к связующему слою Yodel, то есть бизнес-доступ по-прежнему использует стандартный API Yarn, но на этом связующем уровне мы будем взаимодействовать с базовой семантикой K8s и абстрагировать запрос пользователя на ресурсы; что-то вроде Pod или Описание контейнера. Этот метод позволяет нам использовать более зрелую технологию K8s на нижнем уровне для управления ресурсами, достижения автономной облачной трансформации и в то же время обеспечивать стабильность бизнеса.
4.3 Практика: Управление эксплуатацией ресурсов
В процессе совместного размещения нам необходимо адаптировать и преобразовать структуру больших данных и обучения, а также выполнить различные повторные попытки, контрольные точки и оценки, чтобы гарантировать, что после того, как мы сократим эти большие данные и задания по обучению на весь пул ресурсов совместного размещения, Опыт их использования не так уж и плох.
В то же время нам необходимо иметь в системе полные базовые возможности в области ресурсов, классификации бизнеса, оперативного управления и управления квотами. Если операция не выполняется должным образом, уровень использования может быть очень высоким в определенные периоды пиковой нагрузки, но в другие периоды может возникнуть большой дефицит ресурсов, в результате чего уровень использования не будет соответствовать ожиданиям.
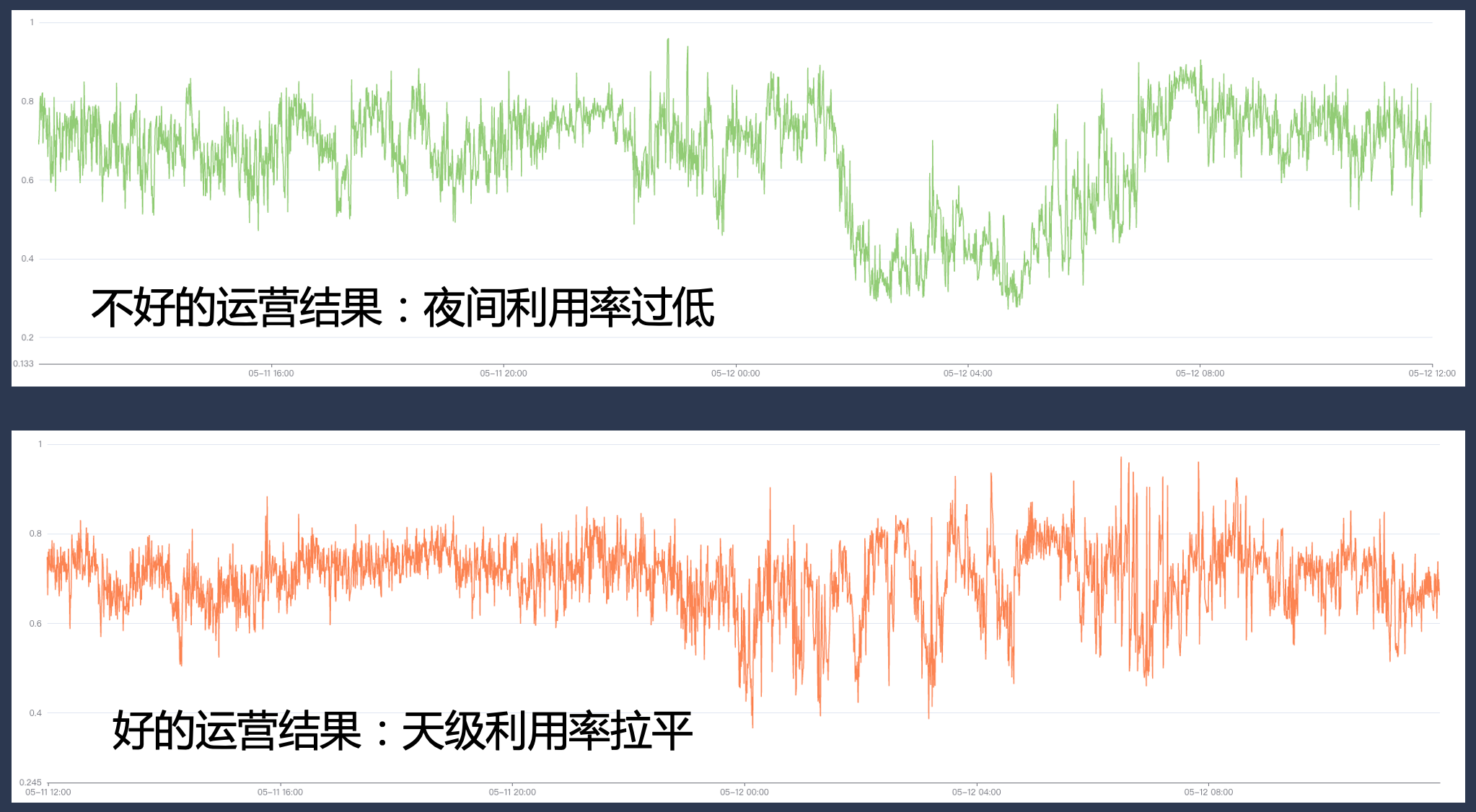
4.4 Практика: максимальное повышение эффективности использования ресурсов
При построении портретов услуг мы используем системные показатели для управления и контроля. Однако статические системные показатели, основанные на офлайн-анализе, не могут успевать за изменениями на стороне бизнеса в реальном времени. Необходимо анализировать изменения показателей бизнеса за определенный период. время для корректировки статических значений.
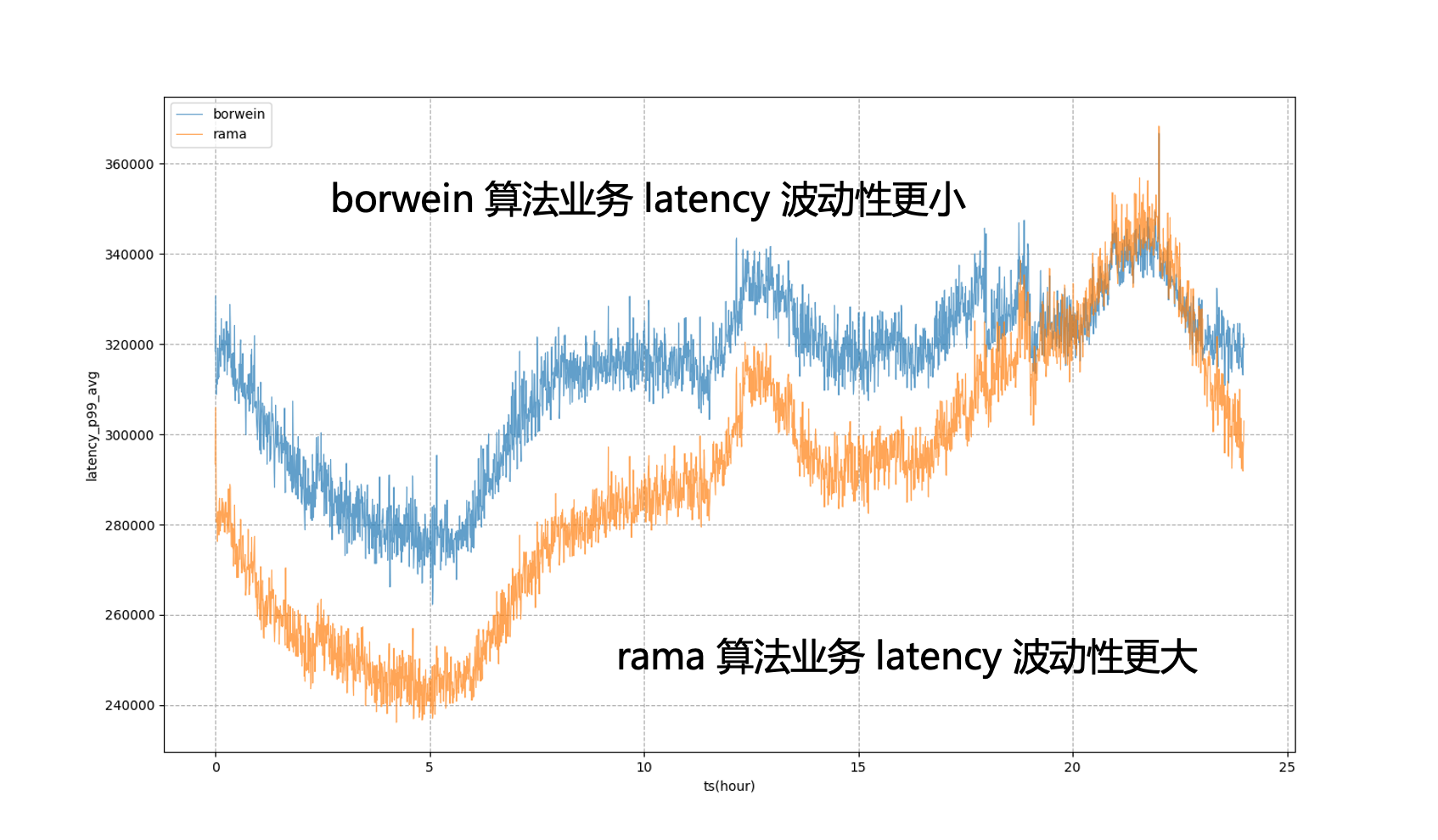
С этой целью Katalyst представляет модели для точной настройки системных показателей. Например, если мы думаем, что задержка планирования ЦП может составлять x миллисекунд, и через определенный период времени мы вычисляем с помощью модели, что задержка бизнес-цели может составлять y миллисекунд, мы можем динамически корректировать значение цели, чтобы лучше оценить бизнес выступление.
Например, как показано на рисунке ниже, если для регулирования полностью используются статические целевые показатели системы, бизнес-P99 будет находиться в состоянии серьезных колебаний, что означает, что в невечерние часы пик мы не можем сжать использование бизнес-ресурсов до более низкого уровня. экстремальное состояние, чтобы сделать его ближе к бизнесу Сумма, которую можно допустить в вечерние часы пик, после внедрения модели мы увидим, что задержка бизнеса будет более стабильной, что позволит нам выровнять производительность бизнеса до относительно стабильного уровня; в течение дня и получить ресурсную выгоду.
4.5 Практика: решение проблем с одним компьютером
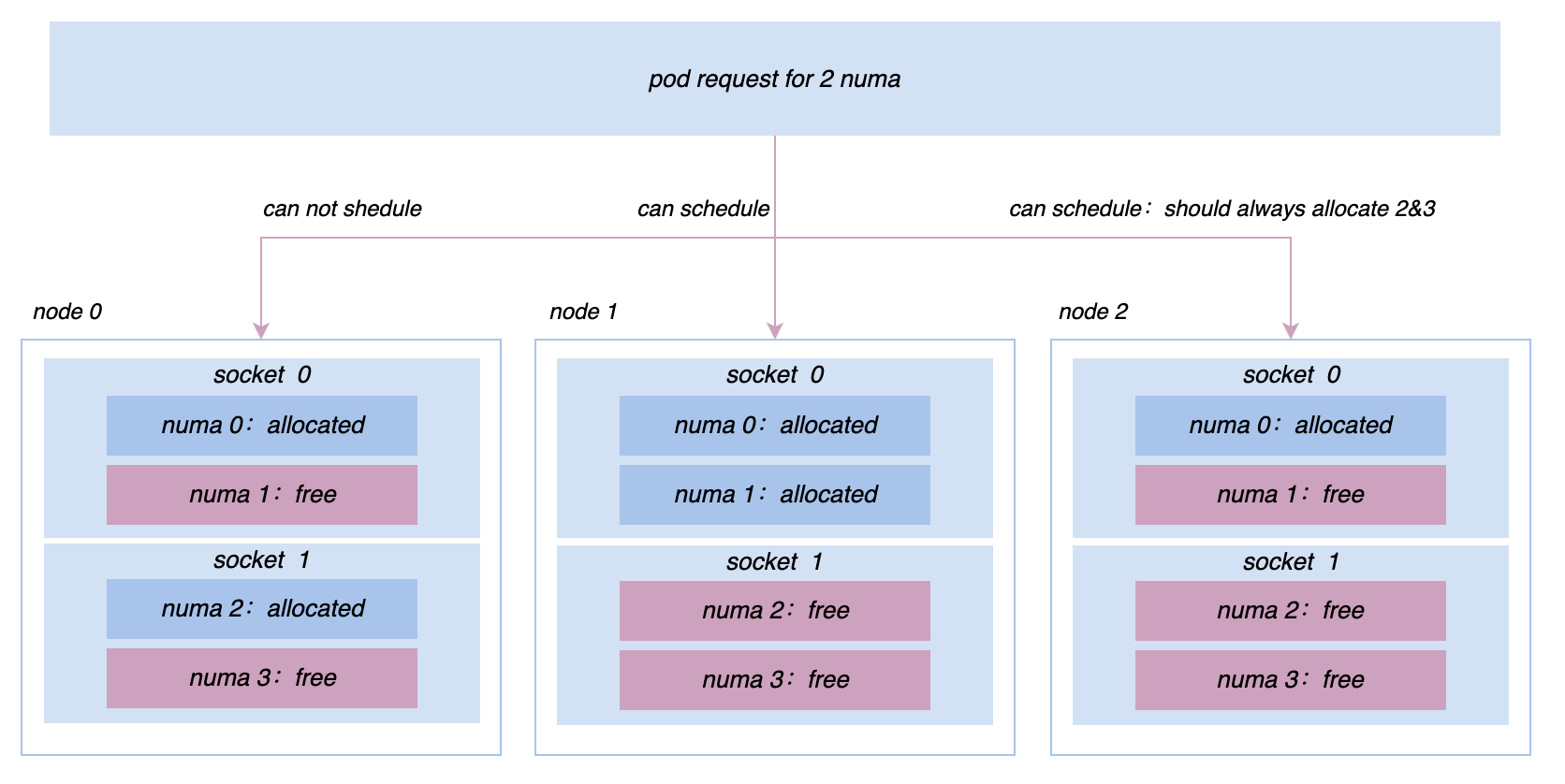
В процессе продвижения совместного размещения мы будем продолжать сталкиваться с различными проблемами онлайн- и оффлайн-производительности и требованиями к управлению микротопологией. Например, изначально все машины управлялись и контролировались на основе cgroup V1. Однако из-за структуры V1 системе необходимо перемещаться по очень глубокому дереву каталогов и потреблять много ресурсов ЦП в режиме ядра. , мы переключаем узлы во всем кластере на cgroup V1. Архитектура cgroup V2 позволяет нам более эффективно изолировать и контролировать ресурсы; для таких служб, как поиск продвижения, нам необходимо реализовать более сложную привязку. и стратегии антисродства на уровне Socket/NUMA и т. д. и т. д., эти более сложные требования к управлению ресурсами могут быть лучше реализованы в Katalyst.
5 Резюме и перспективы
Katalyst официально имеет открытый исходный код и выпустил версию v0.3.0, и сообщество продолжит вкладывать больше усилий в итерацию; сообщество будет создавать возможности и усовершенствовать систему в области изоляции ресурсов, профилирования трафика, стратегий планирования, эластичных стратегий, управления гетерогенными устройствами и т. д. , каждый может обратить внимание, поучаствовать в этом проекте и оставить отзыв.
Товарищ-цыпленок «открыл исходный код» Deepin-IDE и наконец-то добился начальной загрузки! Хороший парень, Tencent действительно превратила Switch в «мыслящую обучающуюся машину». Обзор сбоев Tencent Cloud от 8 апреля и объяснение ситуации. Реконструкция запуска удаленного рабочего стола RustDesk. Веб-клиент . Терминальная база данных с открытым исходным кодом WeChat на основе SQLite. WCDB положила начало серьезному обновлению. Апрельский список TIOBE: PHP упал до рекордно низкого уровня, Фабрис Беллард, отец FFmpeg, выпустил инструмент сжатия звука TSAC , Google выпустил большую модель кода CodeGemma , она вас убьет? Это так хорошо, что это инструмент с открытым исходным кодом - инструмент для редактирования изображений и плакатов с открытым исходным кодом.Видео с выступления на конференции: Katalyst: практика оптимизации затрат Bytedance Cloud Native QCon, Гуанчжоу, 2023 г.