В последние годы, благодаря бурному развитию технологий машинного обучения, серия специализированных чипов, представленных графическими процессорами, получила широкое признание и предпочтение в области машинного обучения благодаря своим превосходным высокопроизводительным вычислительным возможностям и все более низкой стоимости. Чипы специального назначения, такие как графические процессоры, обеспечивают огромную вычислительную мощность по низкой цене и стали основными инструментами в области машинного обучения и искусственного интеллекта, играя все более важную роль в эпоху искусственного интеллекта.
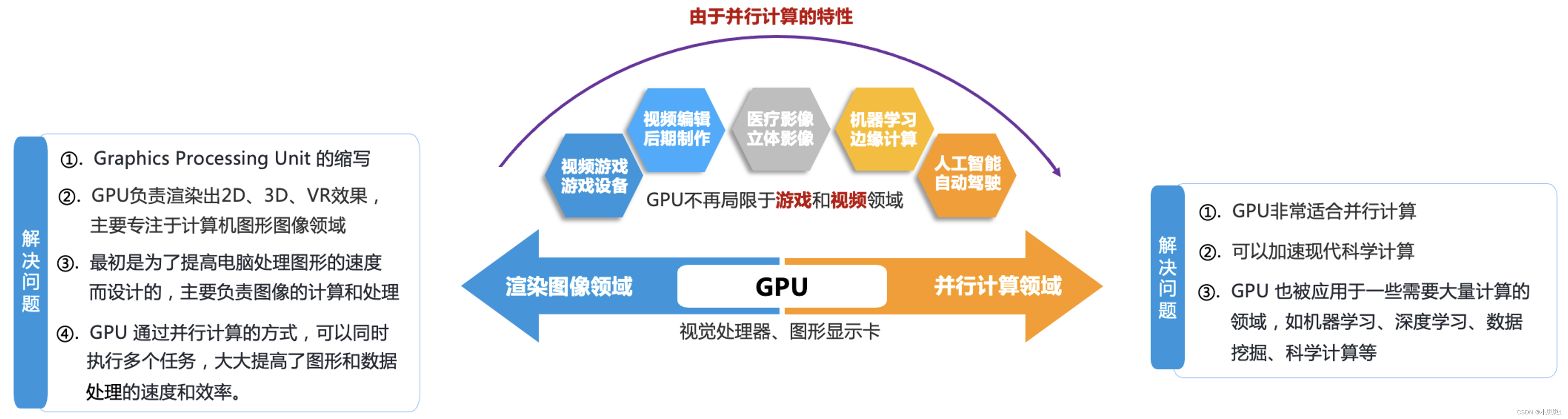
Рекомендуемая и представленная вам сегодня «Служба высокопроизводительных приложений HAI» — это продукт, который значительно снижает порог использования облачных серверов графических процессоров, оптимизирует использование продукта с разных точек зрения и может использоваться прямо из коробки. Он обладает огромной вычислительной мощностью и может использоваться прямо из коробки. Сосредоточив внимание на приложениях, он сочетает ресурсы облачных вычислений на графических процессорах, чтобы помочь малым и средним предприятиям и разработчикам быстро развертывать высокопроизводительные приложения, такие как LLM, рисование с использованием искусственного интеллекта и обработка данных.

Обсуждение того, как использовать «High Performance Application Service HAI» для расширения возможностей бизнес-сценариев, уже является проблемой, с которой в настоящее время приходится сталкиваться многим компаниям. В этой статье описывается практический процесс «Службы высокопроизводительных приложений HAI» в медицинской системе НЛП, в надежде повысить эффективность бизнеса компании с помощью решения «Служба высокопроизводительных приложений HAI».

1. Почему необходимо использовать графические процессоры в сфере искусственного интеллекта?
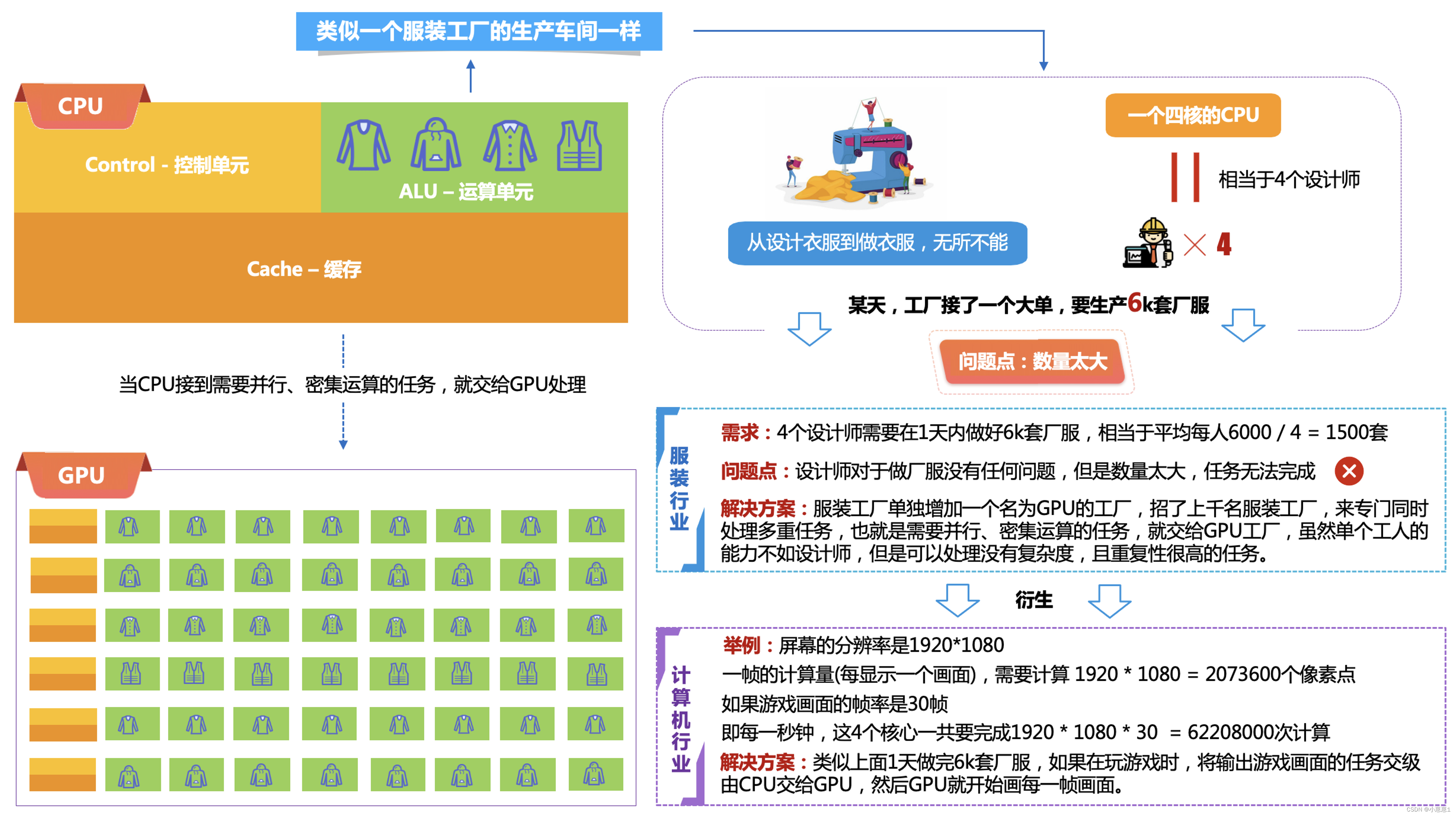
В этих областях графический процессор может ускорить выполнение ресурсоемких задач, таких как обучение моделей и обработка больших объемов данных, что значительно повышает эффективность и скорость вычислений. Поэтому графический процессор стал важной частью современных компьютеров и широко используется в различных областях.
1. Основные различия между графическим процессором и процессором отражены в следующих аспектах:
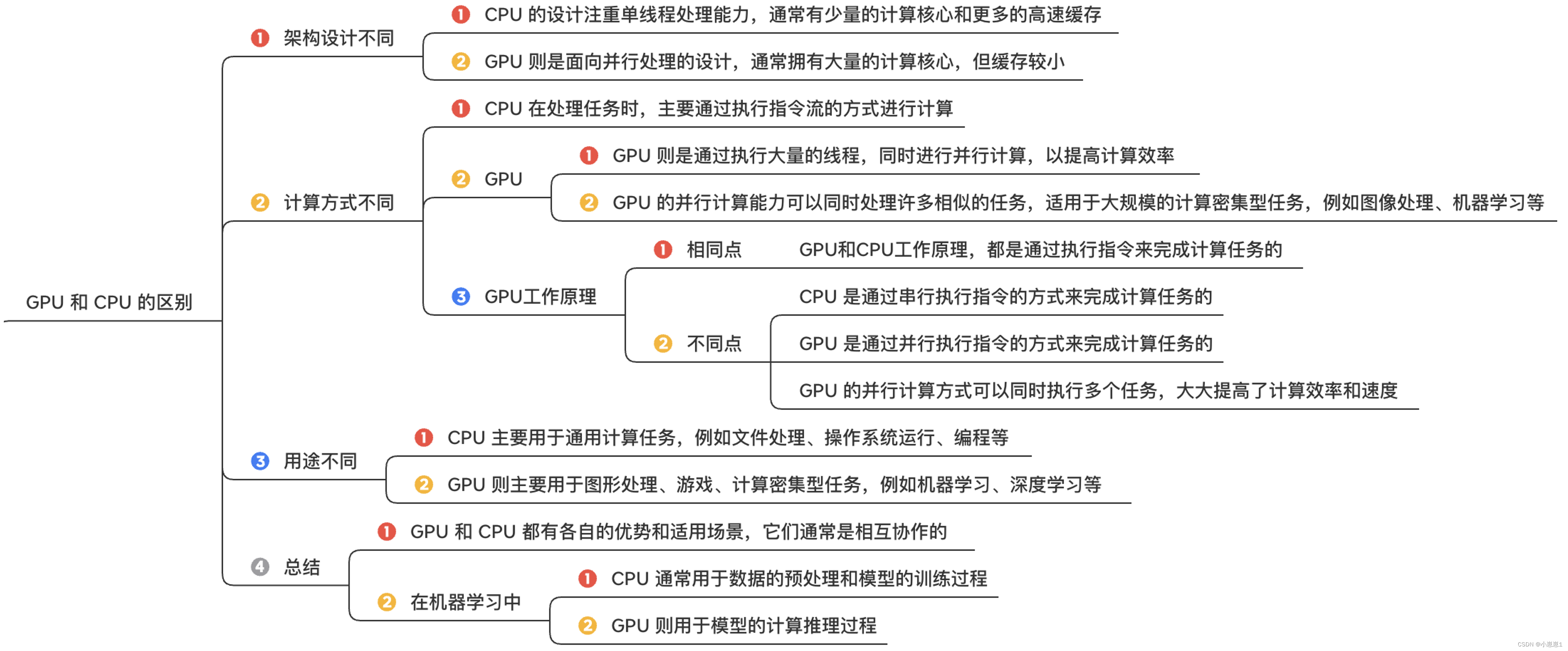
2. Как работает графический процессор:
2. Что может дать «Служба высокопроизводительных приложений HAI»?
1. Что такое ХАИ?
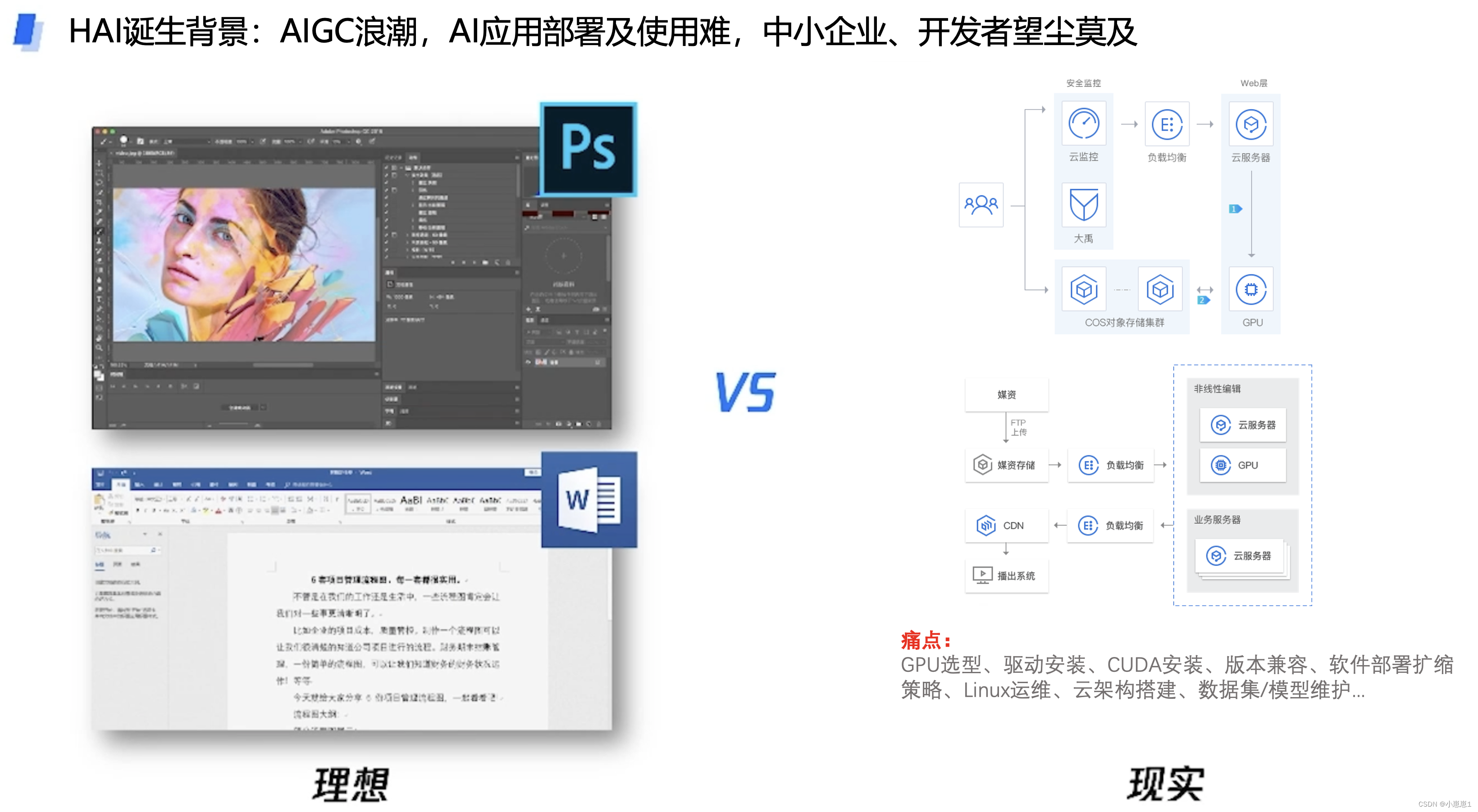
Служба высокопроизводительных приложений (Hyper Application Inventor, HAI) — это продукт службы приложений графического процессора для искусственного интеллекта и научных вычислений, обеспечивающий огромную вычислительную мощность по принципу «включай и работай» и общие среды. Он помогает малым и средним предприятиям и разработчикам быстро развертывать высокопроизводительные приложения, такие как LLM, AI-рисование и обработка данных, а также изначально интегрирует вспомогательные инструменты и компоненты разработки, что значительно повышает эффективность разработки и производства на уровне приложений.

2. Болевые точки при использовании приложений AIGC:
3. Что может позволить нам сделать высокопроизводительный сервис приложений HAI?
Рисование ИИ может выполняться с помощью модели StableDiffusion «Службы высокопроизводительных приложений HAI». Это метод рисования, в котором для создания используются алгоритмы глубокого обучения. Он широко используется в играх, цифровых медиа, фильмах, рекламном дизайне, анимации и других областях. , что позволяет дизайнерам и инженерам ускорить работу, связанную с чертежами, и постепенно переходить от «искусственного» GC к производству контента AIGC с искусственным интеллектом.

4. Результаты снижения затрат и повышения эффективности «High Performance Application Service HAI»:

5. Комплексная услуга хостинга приложений ИИ «Высокопроизводительная служба приложений HAI»:
«Служба высокопроизводительных приложений HAI» выбирает вычислительные ресурсы графического процессора на основе соответствия приложений для достижения максимальной экономической эффективности. Это инженерная платформа искусственного интеллекта для разработчиков и предприятий, обеспечивающая весь процесс, охватывающий предоставление данных, разработку моделей, обучение моделей и развертывание моделей. . Служить.
В то же время он объединяет основные компоненты облачных служб, значительно упрощает процесс настройки облачных служб и ускоряет инновации на каждом этапе разработки машинного обучения, включая:
- Автоматически создавайте среды LLM, рисования с использованием искусственного интеллекта и другие прикладные среды за считанные минуты, подходящие для разработки моделей, обучения моделей и развертывания моделей.
- Предоставляет множество предустановленных сред моделей, включая популярные модели, такие как StableDiffusion, ChatGLM и т. д.
- Он предоставляет удобный для разработчиков графический интерфейс, поддерживает несколько разъемов вычислительной мощности, таких как JupyterLab и WebUI, а также имеет сверхнизкий порог для исследований и отладки ИИ.
- Академическое ускорение дает предприятиям возможность ускорить обучение и вывод, повысить скорость, простоту использования и стабильность обучения и вывода ИИ, а также значительно повысить эффективность вычислений с использованием ИИ.

«Высокопроизводительная служба приложений HAI» основана на интегрированной технологии оптимизации программного и аппаратного обеспечения, выполняет сверхкрупномасштабные распределенные задачи глубокого обучения и обладаетвысокой производительностью и высокой эффективностью. , а также высокая степень использования и другие основные преимущества для достижения снижения затрат и повышения эффективности процесса разработки и применения ИИ.
3. По сравнению с облачными серверами с графическим процессором, высокопроизводительный сервис приложений HAI решает следующие проблемы бизнеса:
1. Подытожим преимущества и недостатки:

4. Каковы сценарии применения «Службы высокопроизводительных приложений HAI»?

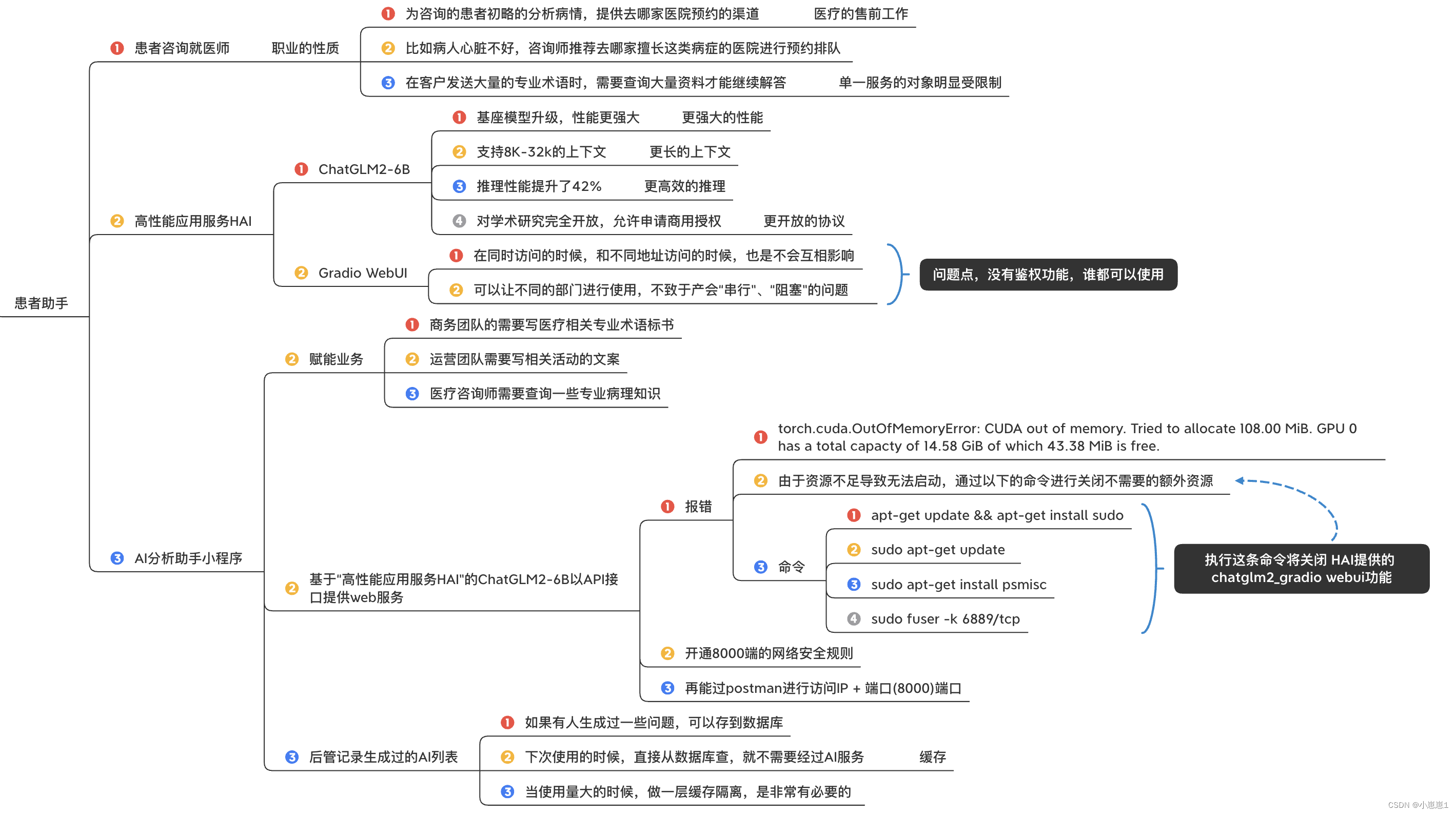
5. Внедрить интеллектуальную систему обслуживания клиентов на базе ChatGLM2-6B:
С помощью второго экспериментального руководства, предоставленного официальным лицом: Диалог будущего: HAI создает вселенную личных знаний, мы можем сделать это за 3- 5 Интеллектуальное диалоговое приложение ChatGLM2-6B с искусственным интеллектом «High Performance Application Service HAI» можно инициализировать за считанные минуты.
«Высокопроизводительная служба приложений HAI» — это приложение более высокого уровня, чем традиционное самостоятельно созданное ИИ-приложение облачной службы графического процессора, которое защищает от множества утомительных рабочих нагрузок, таких как создание среды, выбор, эксплуатация и обслуживание системы.

1. Просто опробуйте функцию разговора с искусственным интеллектом ChatGLM2-6B в «Службе высокопроизводительных приложений HAI»:
Открыв консоль, нажав «Gradio WebUI» и введя нужные нам ответы, мы можем запросить соответствующие медицинские знания.
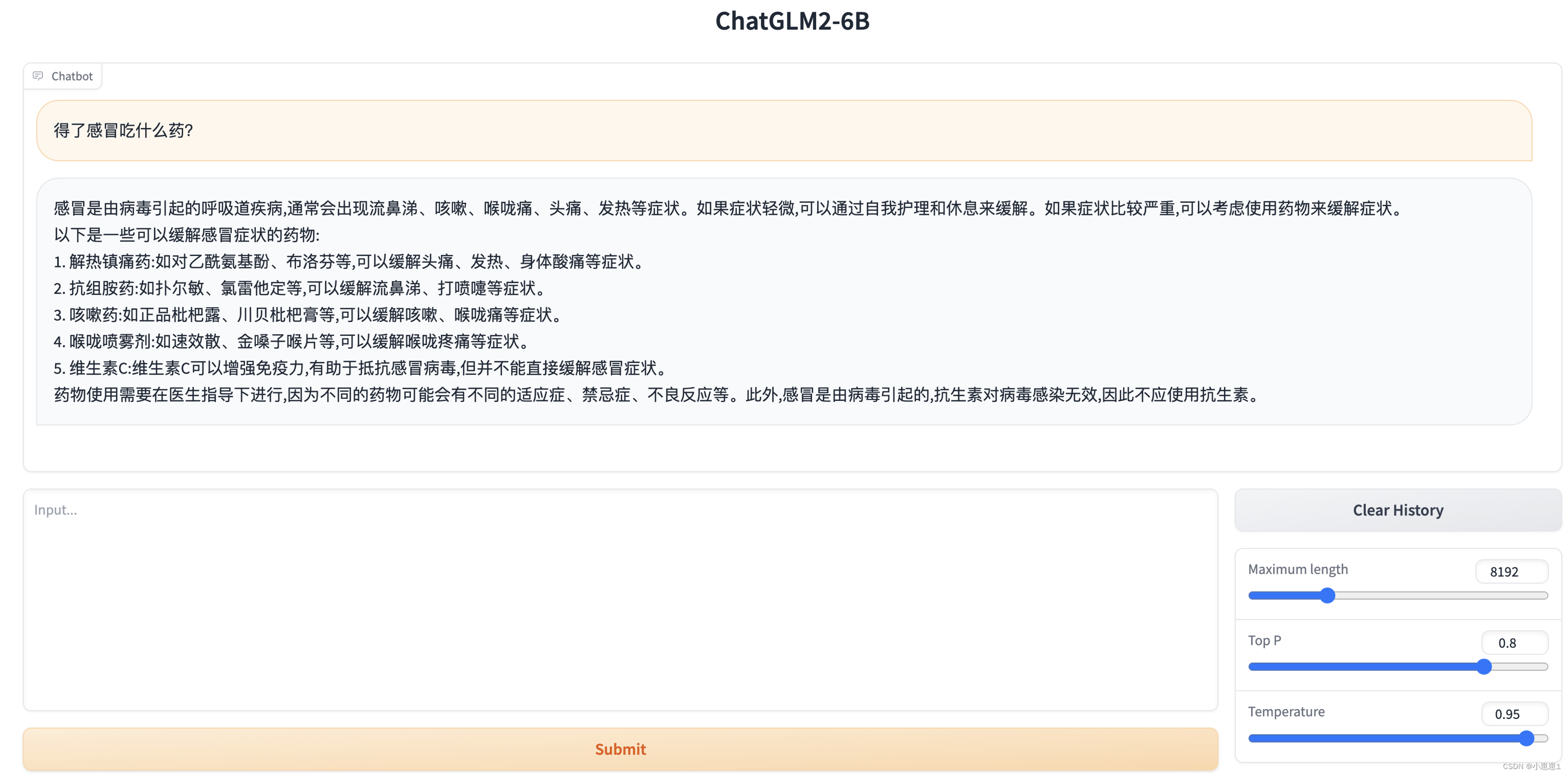
При одновременном доступе или с разных адресов они не влияют друг на друга.Они эквивалентны «отдельным лицам» и могут использоваться разными отделами, не вызывая «последовательных» или «блокирующих» проблем.
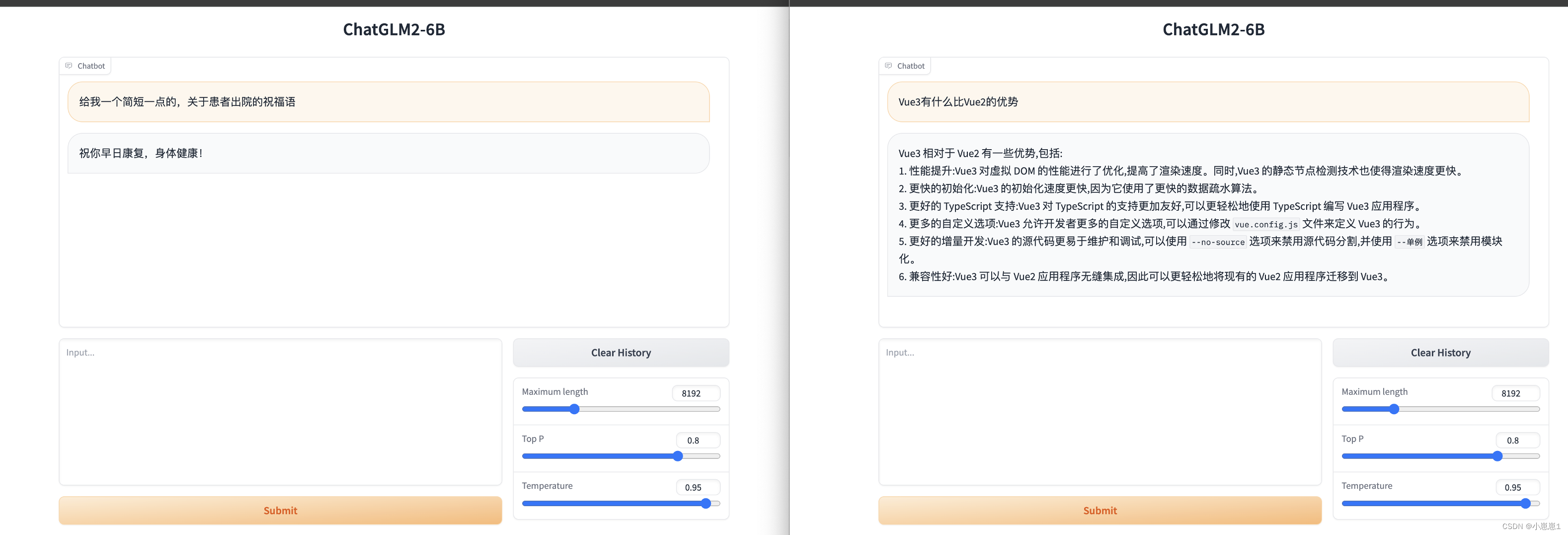
Мы можем легко запустить приведенное выше приложение для разговоров с искусственным интеллектом, которое может использоваться различными бизнес-подразделениями. для запросов. Для некоторых профессиональных знаний в области патологии неудобно использовать веб-страницу по умолчанию, и она не подлежит контролю разрешений. Вы можете использовать следующий интерфейс API для подключения к нашей собственной бизнес-платформе.
2. ChatGLM2-6B на основе «Службы высокопроизводительных приложений HAI» предоставляет веб-сервисы через интерфейс API:
Согласно официальному руководству, в скрипте есть файл api.py, который можно использовать для предоставления сервисов API, однако произошла ошибка:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.00 MiB. GPU 0 has a total capacty of 14.58 GiB of which 43.38 MiB is free. Process 10594 has 11.76 GiB memory in use. Process 12441 has 2.78 GiB memory in use. Of the allocated memory 2.68 GiB is allocated by PyTorch, and 1.85 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF

Невозможно запустить из-за недостаточности ресурсов. Используйте следующую команду, чтобы отключить ненужные дополнительные ресурсы:
apt-get update && apt-get install sudo
sudo apt-get update
sudo apt-get install psmisc
sudo fuser -k 6889/tcp #执行这条命令将关闭 HAI提供的 chatglm2_gradio webui功能
Включите правила сетевой безопасности на стороне 8000 в консоли.

Вы можете получить доступ к порту IP + (8000) через почтальона, а также можете изменить другие порты. Вам необходимо изменить скрипт /root/ChatGLM2-6B/api.py.
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda()
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
# model_path = "THUDM/chatglm2-6b"
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = load_model_on_gpus(model_path, num_gpus=2)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)

На этом этапе мы можем запустить службу в виде веб-API и предоставить почтовый интерфейс, чтобы можно было вызывать другие бизнес-платформы через доступ к интерфейсу.

3. Помощник по анализу ИИ предусмотрен в мини-программе:
В коде мини-программы ChatGLM2-6B на основе «High Performance Application Service HAI» требуется предоставлять веб-сервисы через интерфейс API, который может эффективно контролировать разрешения и предотвращать их использование внешним персоналом.
<template>
<view>
<u-sticky>
<u-notice-bar direction="row" text="" url="/pages/user/myQuestion"
linkType="navigateTo" mode="link" speed="60" bgColor="#e7f9f3" color="#1acc89">
</u-notice-bar>
</u-sticky>
<view style="width: 94%;margin: 30rpx auto;" v-if="skeletonLoading">
<u-skeleton rows="5" :loading="skeletonLoading"></u-skeleton>
</view>
<view class="container" v-if="!skeletonLoading">
<view class="pre-form">
<u-transition :show="true" mode="fade-left">
<view class="option-item">
<view class="option-content">
<view class="sd-model-item sd-model-item-after" @click="sencePopupOpen()">
<view class="sd-item">
<view style="border-radius: 6px;">
<u--image :src="chatSenceSelected.icon_full_path" radius="6" width="100rpx"
height="100rpx" :lazyLoad="false"
:customStyle="{'background-color': '#fff!important'}">
</u--image>
</view>
<view class="sd-item-context">
<view class="sd-item-title sd-item-title-weight">
{
{
chatSenceSelected.role}}
</view>
<view class="sd-item-tips">
{
{
chatSenceSelected.explain}}
</view>
</view>
</view>
</view>
</view>
</view>
<view class="option-item">
<view class="title layout">
<view class="title-item">内容需求</view>
<view class="tips-item" @click="resetExample">试试范文</view>
</view>
<view class="option-content">
<view class="sd-model-item-context">
<u--textarea v-model="chatParams.prompt"
:placeholder="chatSenceSelected.placeholder || '请输入内容需求'" count maxlength='500'
border="bottom" height="240" :customStyle="{'padding':'0'}" confirmType="done">
</u--textarea>
</view>
</view>
</view>
<u--form labelPosition="left" :labelStyle="{'font-weight':'600'}">
<u-form-item label="字数要求" labelWidth="auto" v-if="chatSenceSelected.max_output">
<template slot="right">
<u-number-box v-model="chatParams.words" :step="100" integer inputWidth="50" :min="50"
:max="chatSenceSelected.max_output">
</u-number-box>
</template>
</u-form-item>
</u--form>
</u-transition>
</view>
</view>
<u-popup :show="sencePopup" mode="left" @close="senceClose" :closeable="true" :safeAreaInsetBottom="false">
<scroll-view :scroll-top="scrollTop" scroll-y="true" :style="{height:`${systemInfo.windowHeight}px`}"
@scroll="sencePopupScroll">
<view class="popup-box" style="margin: 80rpx 30rpx 30rpx 30rpx;">
<view class="option-item popup-list" v-for="(sence,senceIndex) in chatSence" :key="senceIndex">
<view class="option-item-title">{
{
sence.case_title}}</view>
<view class="option-content option-content-flex">
<view class="sd-model-item sd-model-item-margin" v-for="(item,index) in sence.child"
:key="index" @click="setChatSence(senceIndex,index)"
:class="chatSenceSelected.id == item.id ? 'sd-model-item-selected':''">
<view class="sd-item">
<view class="sd-item-context" style="margin: 0;">
<view class="sd-item-title sd-item-font">{
{
item.role}}</view>
</view>
</view>
</view>
</view>
</view>
</view>
</scroll-view>
</u-popup>
<!-- 功能按钮区域 -->
<view class="tool">
<u-grid :border="false" col="4">
<u-grid-item @click="goAppStore">
<u-icon :name="assetUrl + 'apps.png'" size="48rpx"></u-icon>
<text class="grid-text">应用中心</text>
</u-grid-item>
<u-grid-item @click="resetQuestion">
<u-icon :name="assetUrl + 'delete.png'" size="48rpx"></u-icon>
<text class="grid-text">清空文案</text>
</u-grid-item>
<u-grid-item @click="pasteContent">
<u-icon :name="assetUrl + 'paste.png'" size="48rpx"></u-icon>
<text class="grid-text">粘贴文案</text>
</u-grid-item>
<u-grid-item @click="onSubmitGPT">
<u-icon :name="assetUrl + 'txtcheck.png'" size="48rpx"></u-icon>
<text class="grid-text grid-text-color">立即提问</text>
</u-grid-item>
</u-grid>
</view>
<!-- #ifdef MP-WEIXIN -->
<view class="ad-container" style="width: 94%;margin: 30rpx auto;">
<view class="ad-view">
<wxAdVideo />
</view>
<u-gap height="20rpx"></u-gap>
</view>
<!-- #endif -->
</view>
</template>
<script>
import wxAdVideo from '@/components/wxad/adVideo.vue';
export default {
components: {
wxAdVideo
},
data() {
return {
gptLoading: false,
chatParams: {
prompt: '',
words: 200
},
chatSence: [],
chatSenceSelected: {
},
chatSenceExample: [],
assetUrl: this.$configData.assetsUrl,
sencePopup: false,
whiteColor: '#fff',
skeletonLoading: true,
scrollTop: 0,
scrollTopOld: 0,
systemInfo: uni.getSystemInfoSync(),
};
},
onShareAppMessage(res) {
return {
title: '轻松创作,爱上文案',
path: '/pages/index/index'
}
},
onShareTimeline(res) {
return {
title: '轻松创作,爱上文案',
path: '/pages/index/index'
}
},
onLoad() {
this.getPromptList();
},
methods: {
sencePopupScroll: function(e) {
this.scrollTopOld = e.detail.scrollTop;
},
async getPromptList() {
var _data = {
provider: 1,
item_id: 17
};
var _res = await this.$http.requestApi('GET', 'agi/getCopyWritingPrompt', _data);
if (_res.status == 200) {
this.chatSence = _res.data;
this.chatSenceSelected = _res.data[0].child[0];
this.chatSenceExample = _res.data[0].child[0].example_arr;
this.skeletonLoading = false;
} else {
uni.showToast({
icon: 'none',
title: _res.msg
});
}
},
goAppStore() {
uni.navigateTo({
url: '/pages/appCenter/appCenter'
})
},
sencePopupOpen() {
this.sencePopup = true;
this.skeletonLoading = true;
this.scrollTop = 0;
this.$nextTick(function() {
this.scrollTop = this.scrollTopOld;
});
},
setChatSence(senceIndex, caseIndex) {
let that = this;
//设置文案场景
that.chatSenceSelected = that.chatSence[senceIndex].child[caseIndex];
that.chatSenceExample = that.chatSenceSelected.example_arr;
//this.sencePopup = false;
that.chatParams.words = 200;
that.resetQuestion();
},
resetExample() {
if (this.chatSenceExample.length <= 0) {
uni.showToast({
icon: 'none',
title: '暂无范文'
});
return;
}
//随机案例
let min = 0;
let max = this.chatSenceExample.length - 1;
let index = Math.ceil(Math.random() * (max - min) + min);
this.chatParams.prompt = this.chatSenceExample[index];
},
checkToken() {
const token = uni.getStorageSync('token');
if (token == '' || token == undefined) {
return false
} else {
return true
}
},
resetQuestion() {
this.chatParams.prompt = '';
},
pasteContent() {
var that = this;
uni.getClipboardData({
success: function(res) {
that.chatParams.prompt = res.data;
}
});
},
modeChange(index) {
this.modeCurrent = index;
},
imgStyleChange(type) {
this.chatParams.style = type;
},
senceClose() {
this.skeletonLoading = false;
this.sencePopup = false;
},
onSubmitGPT() {
//检测用户是否登录
let islogin = this.checkToken();
if (!islogin) {
uni.navigateTo({
url: '/pages/login/index'
});
return false;
}
this.gptLoading = true;
//已经登录,则调用后端接口数据
let postData = {
question: encodeURIComponent(this.chatParams.prompt),
words: this.chatParams.words,
sence_id: this.chatSenceSelected.id,
q_type: 0,
loginType: 1
};
this.$http.requestApi('POST', 'aigc/question/answer', postData).then(res => {
const resCode = res.status;
this.gptLoading = false;
if (resCode == 10000) {
return false;
}
if (resCode == 200) {
uni.navigateTo({
url: '/pages/detail/index?avg=' + encodeURIComponent(res.data.qaId)
});
} else {
uni.showToast({
title: res.msg,
duration: 2000,
icon: 'none'
});
}
})
}
}
}
</script>
<style lang="scss" scoped>
.container {
width: 92%;
margin: 30rpx auto;
.switch-tabbar {
margin: 30rpx 0;
}
.pre-form {
margin: 20rpx 0;
}
.diy-form {
margin: 0 auto;
z-index: 999;
.header {
margin-bottom: 30rpx;
.title {
text-align: center;
color: #fff;
margin: 30rpx 0rpx;
}
}
.panel {
padding: 30rpx;
background-color: #fff;
border-radius: 15rpx;
box-shadow: 0rpx 10rpx 10rpx #eee;
.head {
display: flex;
flex-direction: row;
justify-content: space-between;
.tips {
color: #dd6161;
}
}
.textarea {
margin-top: 30rpx;
}
.btn-group {
display: flex;
flex-direction: row;
justify-content: space-between;
margin-top: 30rpx;
.get {
width: 100%;
}
}
}
}
}
.option-item {
.title {
padding: 30rpx 0;
font-size: 30rpx;
font-weight: 600;
}
.title-padding {
padding-top: 0 !important;
}
.option-item-title {
font-size: 28rpx;
margin: 20rpx auto;
font-weight: 600;
}
.option-content-flex {
display: flex;
justify-content: space-between;
flex-wrap: wrap;
}
.option-content {
.sd-model-item {
margin-bottom: 20rpx;
background-color: #f1f2f4;
padding: 20rpx;
color: #222;
border-radius: 12rpx;
position: relative;
.sd-item {
display: flex;
.sd-item-context {
margin: 0 30rpx;
display: flex;
flex-direction: column;
justify-content: center;
line-height: 48rpx;
.sd-item-title {
font-size: 30rpx;
}
.sd-item-title-weight {
font-weight: 600;
}
.sd-item-tips {
font-size: 24rpx;
color: #999;
line-height: initial;
}
.sd-item-font {
font-size: 28rpx;
}
}
}
}
.sd-model-item-selected {
background-color: #e7f9f3;
color: #1acc89;
}
.sd-model-item-after {
.sd-item::after {
content: '';
position: absolute;
right: 30rpx;
top: calc(50% - 12rpx);
width: 20rpx;
height: 20rpx;
border-top: 4rpx solid;
border-right: 4rpx solid;
border-color: #999;
content: '';
transform: rotate(45deg);
}
}
.sd-model-item-margin {
margin-bottom: 30rpx;
width: 43%;
}
.sd-model-item-green {
background-color: #e7f9f3;
color: #1acc89;
.sd-item {
.sd-item-context {
.sd-item-tips {
color: #1acc89;
opacity: 0.5;
}
}
}
}
}
}
.sence-popup-title {
position: fixed;
width: 100%;
text-align: center;
height: 50px;
line-height: 50px;
font-size: 36rpx;
font-weight: bold;
}
.layout {
display: flex;
justify-content: space-between;
align-items: center;
.tips-item {
font-weight: 400;
font-size: 24rpx;
color: #999;
}
}
.tool {
margin: 10rpx 30rpx 20rpx 30rpx;
width: calc(100% - 60rpx);
border-radius: 100rpx;
background-color: #e7f9f3;
padding: 12rpx 0;
.u-grid {
.u-grid-item {
.grid-text {
font-size: 24rpx;
transform: scale(0.9);
color: #222;
padding-top: 12rpx;
}
.grid-text-color {
font-weight: 600;
color: #1acc89;
}
}
}
}
</style>
Его можно интегрировать с API. Сначала вам необходимо войти в мини-программу, чтобы предоставить такие сценарии, как запрос дела, создание копирайтинга и обучение ИТ-технологиям.
4. Серверная часть записывает сгенерированный список AI:
Если кто-то создал какие-то проблемы, их можно сохранить в базе данных. В следующий раз, когда вы будете использовать их, вы сможете проверить их непосредственно из базы данных, не обращаясь к службе AI. Когда использование велико, очень необходимо сделать слой изоляции кэша.Ведь на его острие используется хороший нож.
<div class="elTable" style="margin-top: 17px">
<el-table
:data="state.tableList"
border
style="width: 100%"
:header-cell-style="{ background: '#EDF3FD', color: '#333333' }"
header-align="center"
>
<el-table-column type="index" label="序号" width="60" header-align="center" align="center"/>
<el-table-column prop="batchId" label="搜索文案" header-align="center" align="center"/>
<el-table-column prop="insuredName" label="姓名" header-align="center" align="center" />
<el-table-column prop="insuredIdNum" label="证件号" header-align="center" align="center" />
<el-table-column prop="insuredPhone" label="手机号" header-align="center" align="center"/>
<el-table-column prop="insuredSex" label="查询时间" header-align="center" align="center" /> -->
</el-table>
<div class="elPagination">
<el-pagination
style="margin-top: 20px; text-align: right"
:current-page="state.pageNumber"
:page-sizes="[10, 20, 30, 40]"
layout="total, sizes, prev, pager, next, jumper"
:total="state.total"
@size-change="handleSizeChange"
@current-change="handleCurrentChange"
/>
</div>
</div>

Предоставляя веб-сервисы через интерфейс API для ChatGLM2-6B на основе «HAI High Performance Application Service», интегрируйте его в апплет, используйте API для централизованного управления и одновременно сохраняйте сгенерированные записи в базе данных или кеше. В следующий раз, если у вас будет тот же ответ, вы можете сначала напрямую использовать промежуточный сервис, не потребляя ресурсы на сервере AI, потому что на самом деле в медицинской отрасли существует много относительно распространенных вопросов.
6. Внедрить обработку естественного языка НЛП на основе PyTorch:
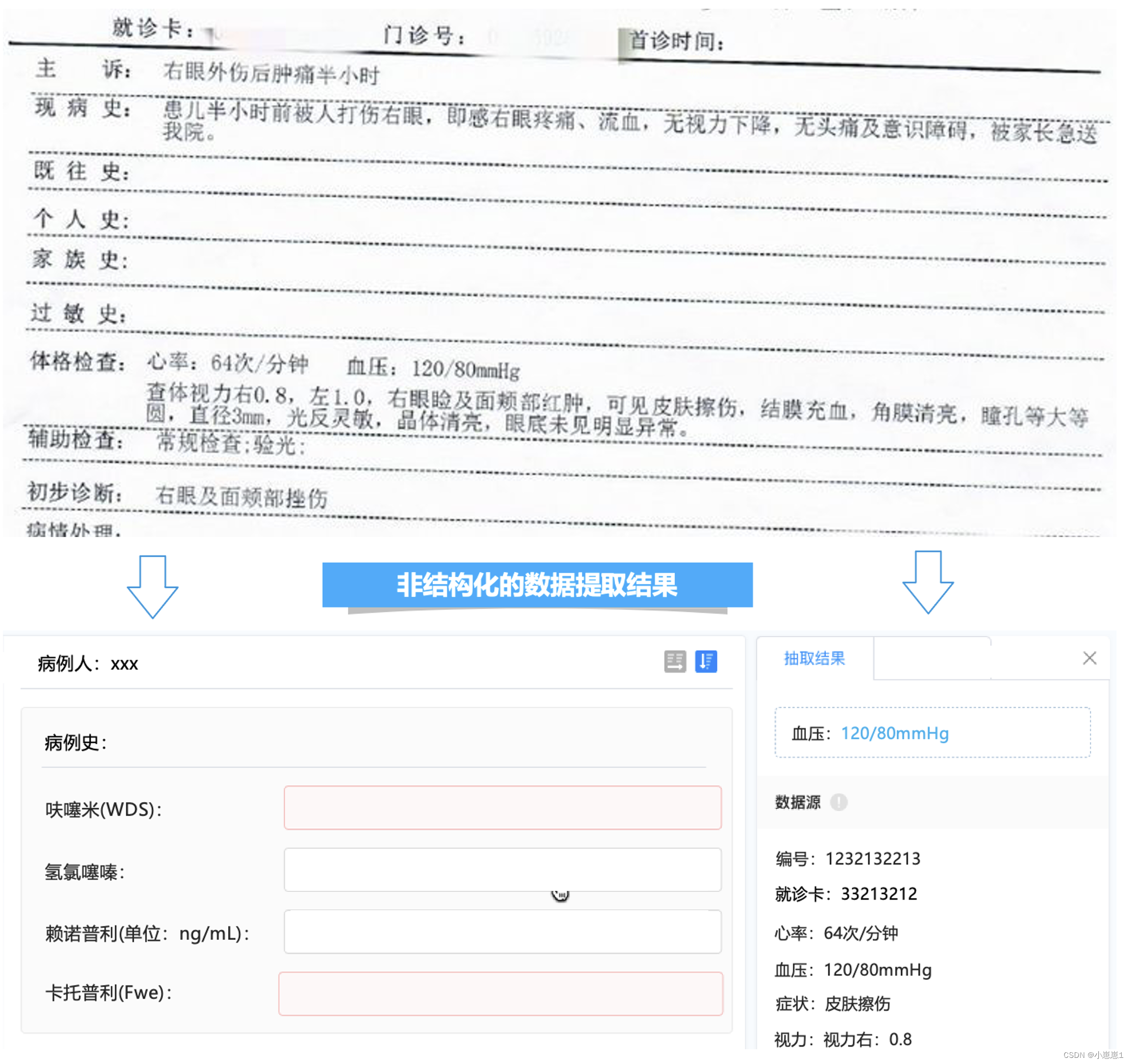
На основе НЛП и технологии обработки естественного языка медицинские документы, такие как амбулаторные/стационарные медицинские записи, отчеты об осмотрах, рецепты/назначения врача и т. д., автоматически идентифицируются и преобразуются в структурированные данные, поддерживая последующую визуализацию, статистический анализ, рассуждение и другие приложения. и может использоваться для медицинских записей, контроля качества, страховых претензий, клинических исследований и других бизнес-сценариев для получения медицинских знаний и экономии медицинских ресурсов.
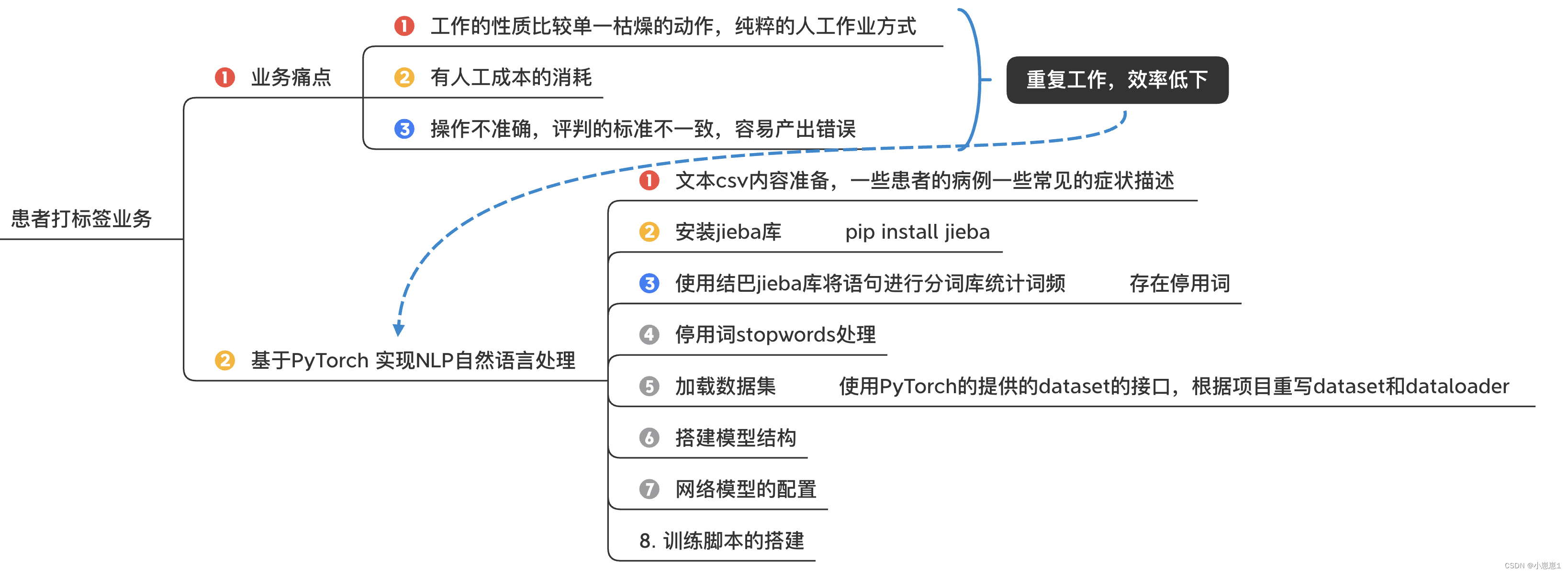
В бизнес-сценарии компании случаи пациентов необходимо целенаправленно маркировать вручную. Например, маркировка пациента с глазным заболеванием на самом деле приводит к множеству проблем:
- Характер работы относительно одиночный и скучный, чисто ручной труд.
- Существует потребление затрат на рабочую силу
- Неточная работа, непоследовательные стандарты оценки и склонность к ошибкам.
1. Подготовьте текстовое содержимое в формате CSV. Ниже приводится описание некоторых распространенных симптомов некоторых случаев заболевания.

2. Установите библиотеку jieba:

3. Используйте библиотеку jieba, чтобы разделить предложения на тезаурус и подсчитать частоту слов:
Чтобы предварительно обработать текстовые данные на китайском языке для анализа НЛП, код использует библиотеку сегментации китайских слов jieba для обработки данных пациента. Код считывает CSV-файл с данными пациента, удаляет первую строку (которая содержит метки для каждого столбца), а затем циклически перебирает каждую строку данных. Для каждой строки извлеките содержимое и используйте jieba для сегментации слов.
import jieba
data_path = "sources/data.csv"
data_list = open("data_path").readlines()[1:]
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
for seg_item in seg_list:
print(seg_item)
Вы можете видеть, что некоторые знаки препинания и некоторые слова без семантического значения также будут сопоставлены, а полученные результаты сегментации слов фильтруются для удаления любых стоп-слов (слов без значения, таких как «и» или «的»).

4. Обработка стоп-слов:
Функция стоп-слов состоит в том, чтобы отфильтровать эти общие слова во время анализа текста, тем самым уменьшая сложность обработки, повышая эффективность алгоритма, а в некоторых задачах это может улучшить качество результатов и избежать искажения результатов анализа этими словами.
В исследованиях обработки естественного языка (НЛП) стоп-слова — это слова, которые часто встречаются в тексте, но обычно не имеют большого значения. Этими словами часто являются некоторые общие служебные слова, служебные слова и даже некоторые знаки препинания, такие как предлоги, местоимения, союзы, вспомогательные глаголы и т. д., такие как «的», «是», «和», «乐», « «Погодите, «the», «is», «and», «…» и так далее по-английски.
import jieba
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
data_list = open(data_path).readlines()[1:]
stops_word = open(data_stop_path, encoding='UTF-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
print(content)
print(seg_res)

5. Загрузите набор данных:
Используйте интерфейс набора данных, предоставляемый PyTorch, чтобы переписать набор данных и загрузчик данных в соответствии с проектом.
import jieba
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
data_list = open(data_path).readlines()[1:]
stops_word = open(data_stop_path, encoding='UTF-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
voc_dict = {
}
min_seq = 1
top_n = 1000
UNK = "<UNK>"
PAD = "<PAD>"
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if seg_item in voc_dict.keys():
voc_dict[seg_item] += 1
else:
voc_dict[seg_item] = 1
voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],
key=lambda x: x[1],
reverse=True)[:top_n]
voc_dict = {
word_count[0]: idx for idx, word_count in enumerate(voc_list)}
voc_dict.update({
UNK: len(voc_dict), PAD: len(voc_dict) + 1})
print(voc_dict)
# 保存字典
ff = open("./sources/dict.txt", "w")
for item in voc_dict.keys():
ff.writelines("{},{}\n".format(item, voc_dict[item]))

6. Постройте структуру модели:
import numpy as np
import jieba
from torch.utils.data import Dataset, DataLoader
def read_dict(voc_dict_path):
voc_dict = {
}
dict_list = open(voc_dict_path).readlines()
print(dict_list[0])
for item in dict_list:
item = item.split(",")
voc_dict[item[0]] = int(item[1].strip())
return voc_dict
# 将数据集进行处理(分词,过滤...)
def load_data(data_path, data_stop_path):
data_list = open(data_path, encoding='utf-8').readlines()[1:]
stops_word = open(data_stop_path, encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
voc_dict = {
}
data = []
max_len_seq = 0
np.random.shuffle(data_list)
for item in data_list[:]:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all=False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if seg_item in voc_dict.keys():
voc_dict[seg_item] = voc_dict[seg_item] + 1
else:
voc_dict[seg_item] = 1
if len(seg_res) > max_len_seq:
max_len_seq = len(seg_res)
data.append([label, seg_res])
# print(max_len_seq)
return data, max_len_seq
# 定义Dataset
class text_CLS(Dataset):
def __init__(self, voc_dict_path, data_path, data_stop_path):
self.data_path = data_path
self.data_stop_path = data_stop_path
self.voc_dict = read_dict(voc_dict_path)
self.data, self.max_len_seq = load_data(self.data_path, self.data_stop_path)
np.random.shuffle(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, item):
data = self.data[item]
label = int(data[0])
word_list = data[1]
input_idx = []
for word in word_list:
if word in self.voc_dict.keys():
input_idx.append(self.voc_dict[word])
else:
input_idx.append(self.voc_dict["<UNK>"])
if len(input_idx) < self.max_len_seq:
input_idx += [self.voc_dict["<PAD>"] for _ in range(self.max_len_seq - len(input_idx))]
# input_idx += [1001 for _ in range(self.max_len_seq - len(input_idx))]
data = np.array(input_idx)
return label, data
# 定义DataLoader
def data_loader(data_path, data_stop_path, dict_path):
dataset = text_CLS(dict_path, data_path, data_stop_path)
return DataLoader(dataset, batch_size=10, shuffle=True)
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
dict_path = "./sources/dict.txt"
train_dataLoader = data_loader(data_path, data_stop_path, dict_path)
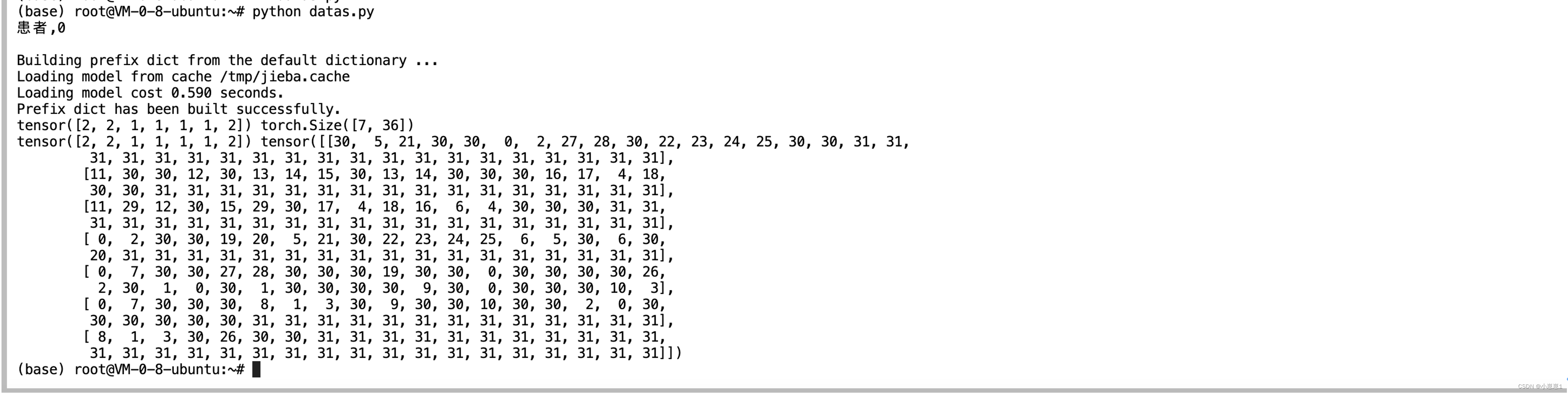
for i, batch in enumerate(train_dataLoader):
print(batch[0], batch[1].size())
print(batch[0], batch[1])
7. Конфигурация сетевой модели:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config():
def __init__(self):
'''
self.embeding = nn.Embedding(config.n_vocab,
config.embed_size,
padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed_size,
config.hidden_size,
config.num_layers,
bidirectional=True, batch_first=True,
dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size,
config.num_classes)
self.softmax = nn.Softmax(dim=1)
'''
self.n_vocab = 1002
self.embed_size = 128
self.hidden_size = 128
self.num_layers = 3
self.dropout = 0.8
self.num_classes = 2
self.pad_size = 32
self.batch_size = 128
self.is_shuffle = True
self.learn_rate = 0.001
self.num_epochs = 100
self.devices = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embeding = nn.Embedding(config.n_vocab,
padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(input_size=config.embed_size,
hidden_size=config.hidden_size,
num_layers=config.num_layers,
bidirectional=True,
batch_first=True, dropout=config.dropout)
self.maxpooling = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size, config.num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
embed = self.embeding(x)
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpooling(out).reshape(out.size()[0], -1)
out = self.fc(out)
out = self.softmax(out)
return out
# 测试网络是否正确
cfg = Config()
cfg.pad_size = 640
model_textcls = Model(config=cfg)
input_tensor = torch.tensor([i for i in range(640)]).reshape([1, 640])
out_tensor = model_textcls.forward(input_tensor)
print(out_tensor.size())
print(out_tensor)

8. Построение сценария обучения:
model_text_cls = Model(cfg)
model_text_cls.to(cfg.devices)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_text_cls.parameters(), lr=cfg.learn_rate)
for epoch in range(cfg.num_epochs):
for i, batch in enumerate(train_dataloader):
label, data = batch
# data1 = torch.tensor(data).to(cfg.devices)
# label1 = torch.tensor(label).to(cfg.devices)
data1 = data.sourceTensor.clone().detach().to(cfg.devices)
label1 = label.sourceTensor.clone().detach().to(cfg.devices)
optimizer.zero_grad()
pred = model_text_cls.forward(data1)
loss_val = loss_func(pred, label1)
print("epoch is {},ite is {},val is {}".format(epoch, i, loss_val))
loss_val.backward()
optimizer.step()
if epoch % 10 == 0:
torch.save(model_text_cls.state_dict(), "./models/{}.pth".format(epoch))

9. Резюме:
Случаи пациентов можно преобразовать в технологию искусственного интеллекта, внедрив обработку естественного языка NLP на основе PyTorch, чтобы бизнес мог быстро реализовать автоматическую маркировку, что может снизить затраты и повысить эффективность.
«Служба высокопроизводительных приложений HAI» основана на других решениях для приложений аналогичного сценария, оптимизированных с помощью PyTorch:

Подведем итог:
С быстрым развитием бизнеса проблема во всех сферах жизни заключается в том, что по мере увеличения количества сервисов модельного онлайн-вывода эти сервисы становятся все более большими, раздутыми и трудными в управлении. Такая ситуация приводит не только к пустой трате ресурсов, но и к увеличению затрат на обслуживание и модернизацию.
Чтобы решить эти «упорные проблемы», «High Performance Application Service HAI» обладает огромной вычислительной мощностью и может быть использован «из коробки». Основываясь на базовой вычислительной мощности облачного сервера Tencent Cloud GPU, он предоставляет высокопроизводительные облачные услуги. из коробки. Сосредоточив внимание на приложениях и сопоставлении ресурсов облачных вычислений на графических процессорах, он помогает малым и средним предприятиям и разработчикам быстро развертывать высокопроизводительные приложения, такие как LLM, рисование ИИ и обработка данных, сокращая эксплуатационные расходы и значительно повышая доступность услуг.Средний цикл развертывания сокращается с дней до нескольких минут, это значительно повышает эффективность итераций НИОКР, тем самым ускоряя процесс коммерческого применения и обеспечивая новый импульс роста для всех сфер жизни.
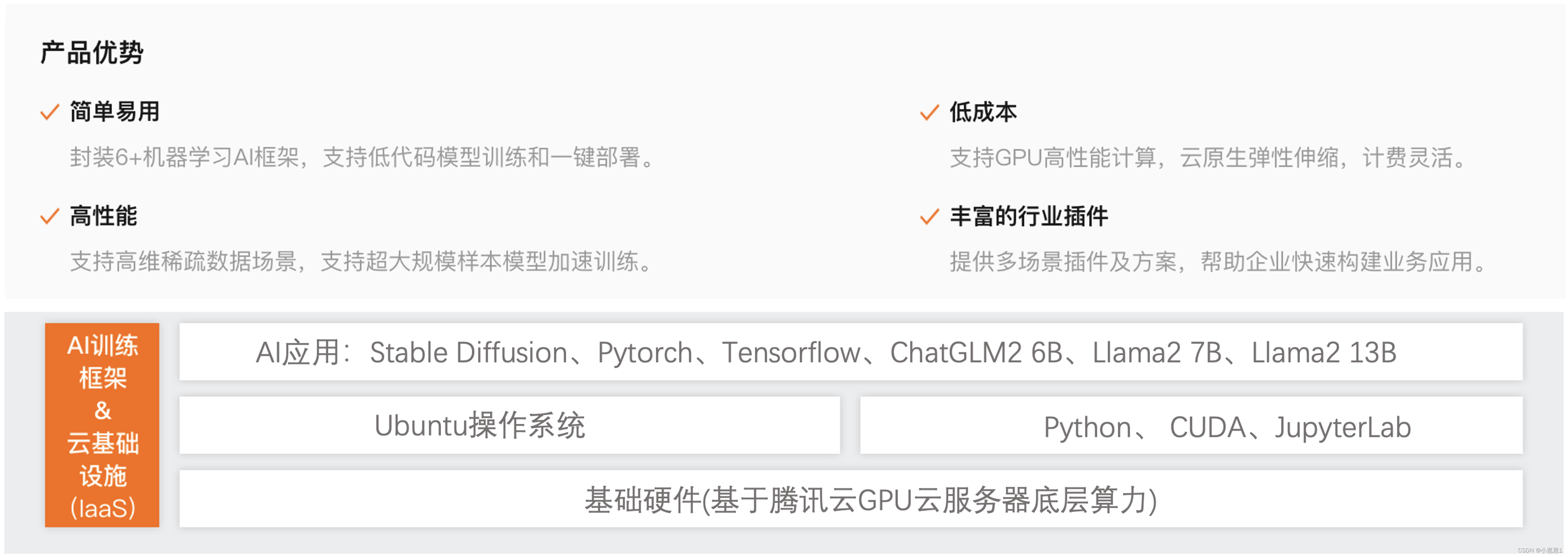
«Служба высокопроизводительных приложений HAI» — это облачная платформа машинного обучения/инжиниринга глубокого обучения для разработчиков и предприятий. Ее услуги охватывают все этапы разработки искусственного интеллекта, со встроенными более чем шестью платформами и моделями искусственного интеллекта, а также множеством отраслевых возможностей. плагины сценариев для снижения затрат.В контексте повышения эффективности «высокопроизводительный сервис приложений HAI» стал наиболее очевидным направлением внедрения приложений искусственного интеллекта.